1. はじめに
読んでいただきありがとうございます!
最近、点群データに対する生成モデルの手法を学んでいます。その中で、“VAE with VampPrior”という論文を読みました。
MoG-VAE(Mixture of Gaussians-VAE)が標準的なVAEと比較してどのように性能が異なるのか興味があったため、この記事を書きました。
なお、この記事の英語版はこちら
2. VAEとMoG-VAEの違い
VAE(Variational Autoencoder)
VAEでは、事前分布 $ p(z) $ は単純なガウス分布として仮定されます。
$$
p(z) = \mathcal{N}(0, I) \tag1
$$
潜在空間は標準正規分布に従う。
連続的でスムーズな空間が得られるが、柔軟性に欠ける。
MoG-VAE(ガウス混合モデルVAE)
MoG-VAEでは、事前分布 $ p(z) $ はガウス混合分布(Mixture of Gaussians, MoG) になります。
$$
p(z) = \sum_{k=1}^{K} \pi_k \mathcal{N}(z | \mu_k, \Sigma_k) \tag2
$$
ここで
- $ K $ はガウス分布の成分数。
- $ \pi_k $ は混合係数($ \sum_{k=1}^{K} \pi_k = 1 $)。
- $ \mu_k, \Sigma_k $ はそれぞれ平均と分散。
この違いにより、MoG-VAEの潜在空間はより柔軟で多様性のある表現が可能になります。
潜在空間の違い
VAE: 1つのガウス分布 → 単純な構造しか学習できない。
MoG-VAE: 複数のガウス分布 → より複雑な潜在表現を学習できる。
3. VAEとMoG-VAEのKLダイバージェンス
VAEとMoG-VAEでは、損失関数に含まれるKLダイバージェンスの計算が異なります。
3-1. VAE(標準ガウス分布)
VAEでは、$ p(z) $ が標準正規分布 $ \mathcal{N}(0, I) $ なので、コーディングで実装できるKLダイバージェンスは,以下の通り変形できることが知られている。
$$
\text{KL}(q(z|x) \parallel p(z)) = \frac{1}{2} \sum_{i=1}^{z} \left( 1 + \log(\sigma_i^2) - \mu_i^2 - \sigma_i^2 \right) \tag3
$$
ここで,
$z$は潜在変数の次元数
3-2. MoG-VAE(ガウス混合分布)
MoG-VAEでは、$p(z)$ が複数のガウス分布を混合した分布となるため、KLダイバージェンスは先述の式 (3)(標準正規分布を仮定した場合)とは異なる形をとります。
たとえば、潜在変数 $z$ が1次元である簡単な場合には、次式のように書けます。
$$
\text{KL}\bigl(q(z|x) \parallel p(z)\bigr)= \frac{1}{2}\sum_{k=1}^{K}\pi_k\bigl(\mu_k^2 + \sigma_k^2 - \log(\sigma_k^2) - 1
\bigr)\tag{4}
$$
ここで、$K$ はガウス成分数を表し、(\pi_k) は混合係数です。ガウス混合モデルにおける混合係数 (\pi_k) は、しばしば次のソフトマックス関数で与えられます。
$$
\pi_k = \frac{\exp(\alpha_k)}{\displaystyle \sum_{j=1}^{K} \exp(\alpha_j)} \tag{5}
$$
学習や推論の過程では、上式のKLダイバージェンスをモンテカルロサンプリングによって近似計算する手法が一般的に用いられています。
事前分布をガウス混合モデルに拡張することで、単一の標準正規分布を仮定する場合と比べ、潜在空間に複数のモードを持たせることが可能になります。その結果、VAEよりも複雑なデータ分布をより柔軟に捉えられるとされています。
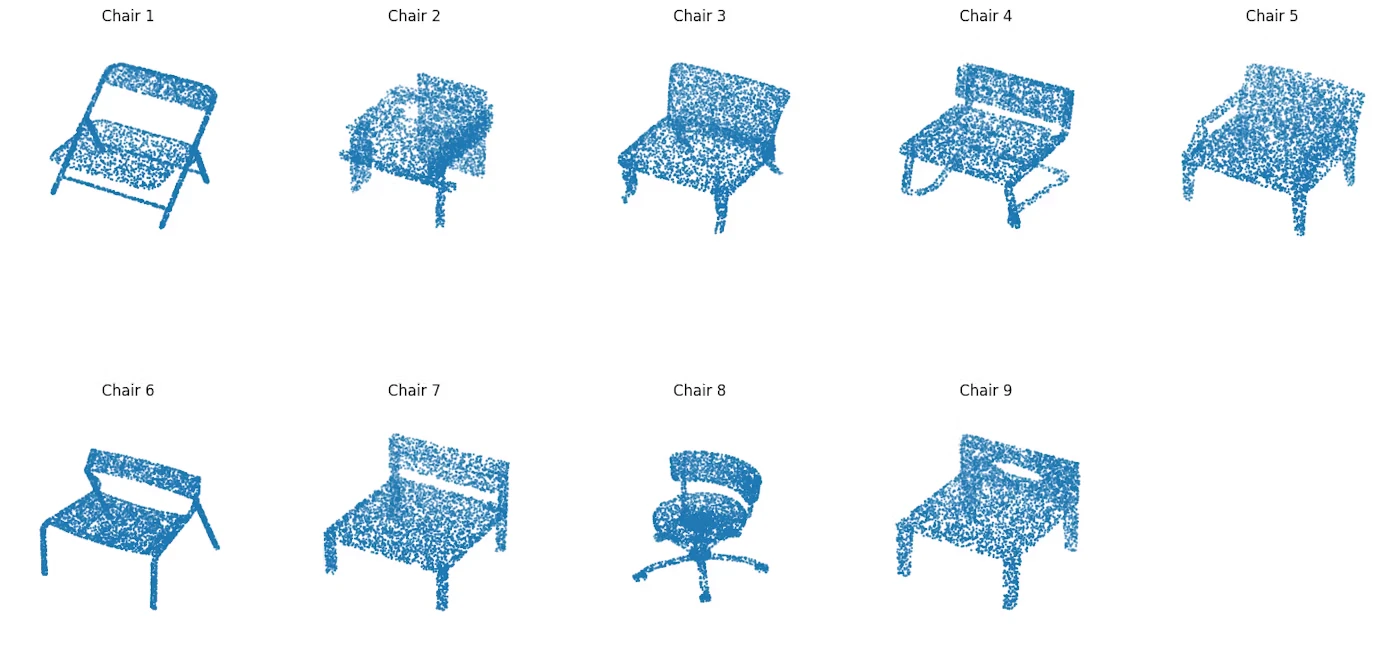
4. 使用したデータセット
ModelNetの椅子データセットを使用。
各点群は5000点で構成。
すべての形状を0〜1の範囲に正規化。
5. 訓練設定
5-1. VAEの設定
潜在次元 $ z $: 3
学習率: 1.0e-5
最適化手法: Adam
損失関数:式(6)に示す通り
$$
L_\text{total} = \frac{1}{N} \sum_{i=1}^{N} | x_i - x_i^\text{reconst} |^2 + \frac{1}{2} \sum_{i=1}^{z} \left( 1 + \log(\sigma_i^2) - \mu_i^2 - \sigma_i^2 \right) \tag6
$$
5-2. MoG-VAEの設定
ガウス成分数 $ K $: 2
潜在次元 $ z $: 3
学習率: 1.0e-5
最適化手法: Adam
損失関数:式(7)に示す通り
$$
L_\text{total} = \frac{1}{N} \sum_{i=1}^{N} | x_i - x_i^\text{reconst} |^2 + \frac{1}{2} \sum_{k=1}^{K} \pi_k \left( \mu_k^2 + \sigma_k^2 - \log \sigma_k^2 - 1 \right) \tag7
$$
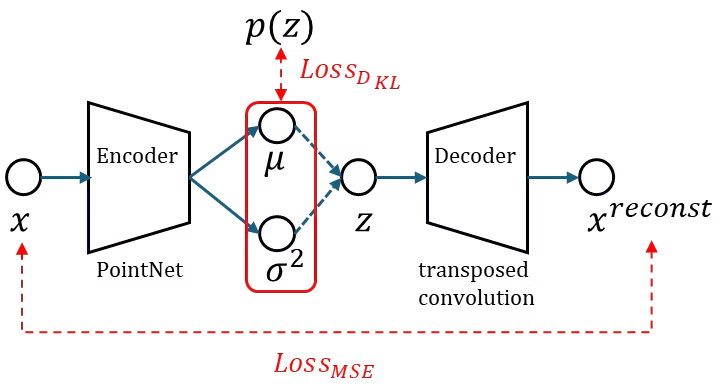
7. アーキテクチャ
エンコーダーにはPointNet(Pointwise convolution + max pooling)、デコーダーには転置畳み込みを採用。
6. 検証
MoG-VAEとVAEの性能を比較するため、再構成品質をChamfer距離(CD)とEarth Mover's Distance(EMD)で評価しました。なお、Chamfer距離は式(8)、EMDは式(9)の通り
$$
\text{CD}(P, Q) = \frac{1}{|P|} \sum_{p \in P} \min_{q \in Q} | p - q |^2 + \frac{1}{|Q|} \sum_{q \in Q} \min_{p \in P} | q - p |^2 \tag8
$$
- $ P $ and $ Q $ are two point sets
- $ p $ and $ q $ are points from sets $ P $ and $ Q $ respectively
- $ | \cdot | $ denotes the Euclidean distance
- $|P|$ and $|Q|$ are the total number of points in sets $ P $ and $ Q $
$$
\text{EMD}(P, Q) = \min_{\gamma \in \Gamma(P, Q)} \sum_{(p, q) \in P \times Q} \gamma(p, q) | p - q | \tag{9}
$$
Where:
- $ P $ and $ Q $ are two distributions or point sets.
- $ | p - q | $ represents the distance (typically Euclidean) between points $ p \in P $ and $ q \in Q $.
- $ \Gamma(P, Q) $ is the set of all valid transportation plans (flow functions) between distributions $ P $ and $ Q $.
- $ \gamma(p, q) $ is the amount of "mass" moved from $ p $ to $ q $.
6-1. 検証結果

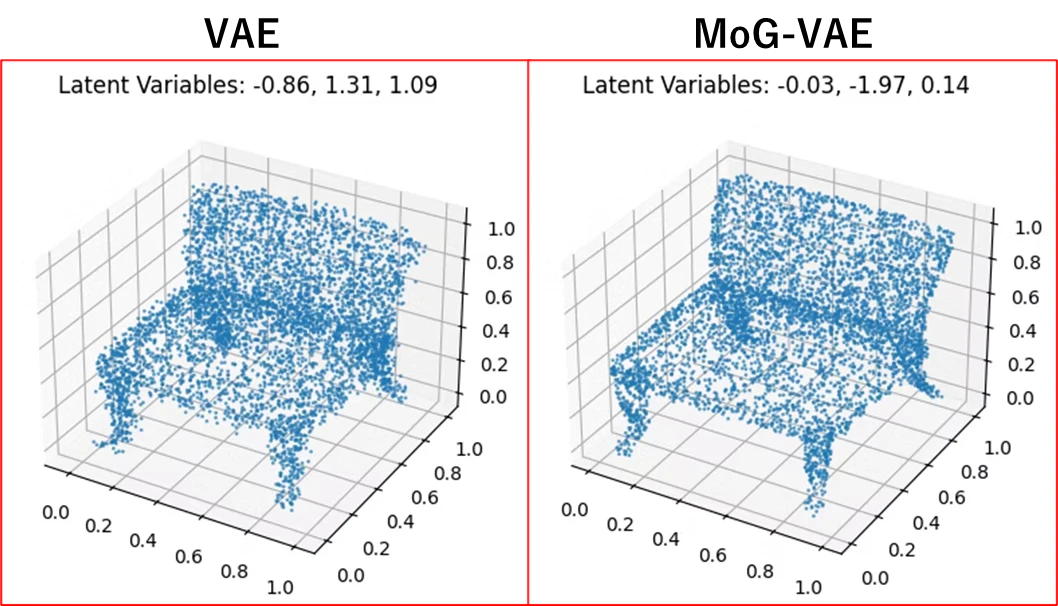
これを見る限り、MoG-VAEの方がしっかりと再構成できていることがわかる!
また、CDとEMDの定量評価では・・・
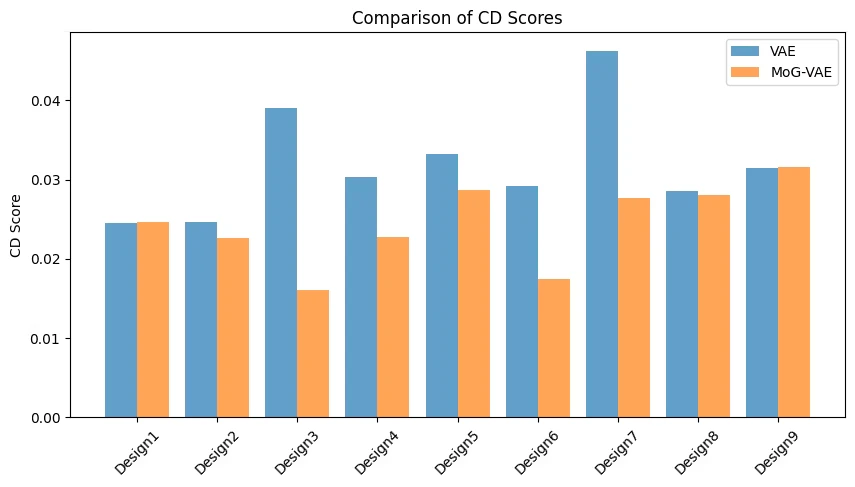
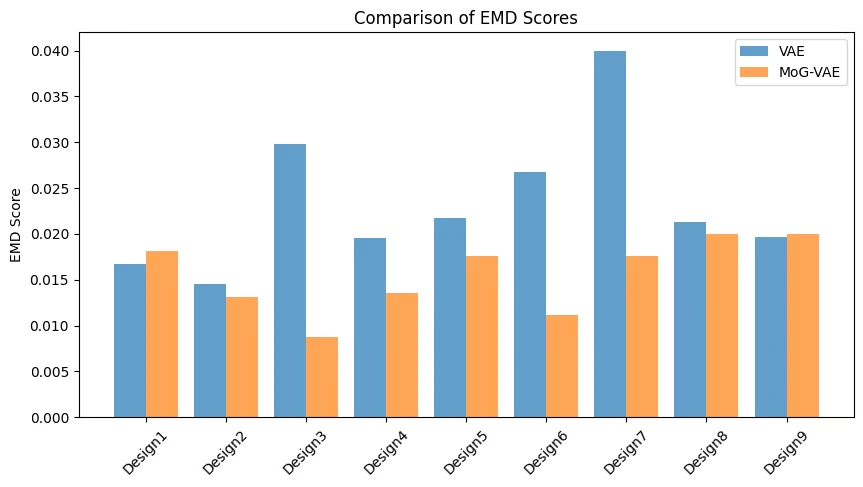
MoG-VAEの方がVAEよりも両距離関数が小さい点から、優れた再構成性能であることを確認できる。
7. まとめ
MoG-VAEはVAEよりも潜在表現が豊かで、より良い再構成品質を得ることができると感じました。
Flowだと事前分布がより多様になるのでもっと精度が高まるかもしれませんね!
次回は損失関数をMSEからCDに変更し、さらなる改善を試みます!
ありがとうございました!