初めに
「kubernetes the hard way を PC でやってみる」の13回目、「Pod Network」についてです。( 目次 )
各ノード上で稼働する Pod は、各ノードの POD CIDR から IP アドレスが割り振られていきます。
それらの間での通信ができるように CNI (に相当するもの)を構成します。
一般的には kubernetes のネットワークを構成する場合、
flannel や calico などで提供される CNI プラグインを利用しますが
kubernetes the hard way ではその代わりにルーティング設定で代替しています。
そのため、kubernetes the hard way で構築したクラスターでは、CNI が持つ Network Policy については利用できません。
この回は非常にハマりました、一見うまくいっているように見えて疎通はできない、という事象になり
さんざん調べてようやく解決した時に振り返って考えると、いかに自分が NW 構成を理解していないかを痛感しました。
ハマった内容については例によって末尾に記載します。。。 まぁまだ間違っているかもしれませんが…
やることは以下の通りです。 今回は ワーカーノードで実施しています
- ルーティングの追加
なんとこれだけですね。なのに私は全くうまくいかなかったという。。。
ルーティングの追加
kubernetes the hard way では、 google cloud のコマンドを使ってルーティングを追加しているようですが、
私には全くわかりませんでした。。。
オンプレ ubuntu でルーティングを追加する場合、(いろいろやり方はあるのでしょうが)
netplan を使って追加するという手段があるようです。 NetworkManager 派なので知りませんでした。
さて、肝心の追加内容は以下の通りです。 (図の赤矢印は k8sworker0 について記載しており、
k8sworker1,2 もそれぞれ自分の POD_CIDR 以外は他のノードにルーティングするように設定します。)
※ 細かく追えるように、IP アドレスも記入していますが、 要は赤い矢印についてだな、ぐらいの認識で OK です)
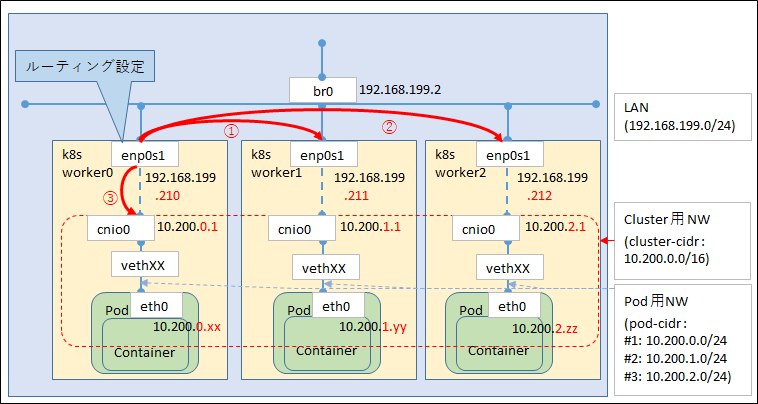
ルーティング設定内容
表のデータ部1行目を例にとって説明すると、
k8sworker0 ( 192.168.199.210 ) が持っている POD_CIDR (10.200.0.0/24) への外部からの通信は、
k8sworker0 の IP にルーティングを行うように、 k8sworker1,2 に登録する、ということです。
逆の見方をすると、 自ノードが持つ POD_CIDR 向けは IPtables が転送してくれるのでルーティングテーブルとして登録しない、とも言えます。
(※ 自ノードの POD_CIDR 向けは POD 作成時に cnio0 向けとして自動的に作成されるようです)
| ターゲットNW | ルーティング先 | k8sworker0 | k8sworker1 | k8sworker2 | 図 |
|---|---|---|---|---|---|
| 10.200.0.0/24 | 192.168.199.210 | 〇 | 〇 | ||
| 10.200.1.0/24 | 192.168.199.211 | 〇 | 〇 | ① | |
| 10.200.2.0/24 | 192.168.199.212 | 〇 | 〇 | ② |
ルーティング設定方法
netplan でのルーティング設定方法は
/etc/netplan/*.conf を修正して、 netplan apply を実行します。
(以下は k8sworker0 の例で、 routes: 部分を追記しています。
k8sworker0 に不要な部分はコメントアウトしています。
k8sworker1,2 ではコメントアウトする部分が変わってきます)
# cd /etc/netplan/
# ls
00-installer-config.yaml
# vi 00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
enp1s0:
addresses:
- 192.168.199.210/24
gateway4: 192.168.199.254
nameservers:
addresses:
- 192.168.199.254
routes:
# - to: 10.200.0.0/24
# via: 192.168.199.210
- to: 10.200.1.0/24
via: 192.168.199.211
- to: 10.200.2.0/24
via: 192.168.199.212
version: 2
適用します。
# netplan apply
# ip route
default via 192.168.199.254 dev enp1s0 proto static
10.200.1.0/24 via 192.168.199.211 dev enp1s0 proto static
10.200.2.0/24 via 192.168.199.212 dev enp1s0 proto static
192.168.199.0/24 dev enp1s0 proto kernel scope link src 192.168.199.210
10.200.1.0/24, 10.200.2.0/24 が追加されていることがわかります。
作業は以上で終了です。 以下は細かい補足なので興味があればどうぞ。
インターフェース/ルーティングテーブル関連の補足
ルーティング追加は上記でよいですが、 POD を作成するとどう変わるかを見ておきましょう。
k8sworker0 に上記ルーティング設定をした後の インターフェースの状況は以下のようになっています。
# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:a9:a0:82 brd ff:ff:ff:ff:ff:ff
inet 192.168.199.210/24 brd 192.168.199.255 scope global enp1s0
valid_lft forever preferred_lft forever
ループバックを除くと enp1s0 のみです。
ここで、k8sworker0 上で POD ができたときにどうなるかを見てみます。
busybox の Pod を立ててみました。
(手順略... deployment で replica 3 に指定すれば多分どの worker にも乗るでしょう的な...まぁ手抜きです。)
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-c44c795b6-kqx5v 1/1 Running 0 14m 10.200.1.141 k8sworker1 <none> <none>
busybox-c44c795b6-r2qk9 1/1 Running 0 14m 10.200.0.3 k8sworker0 <none> <none>
busybox-c44c795b6-vsmpb 1/1 Running 0 14m 10.200.2.216 k8sworker2 <none> <none>
さて、 インターフェースですが、以下のように cnio0 と vethXX ができています。
なお、 cnio0 は POD から接続される bridge で、1個だけですが、 vethXX は POD ごとに1個作成されます。
POD削除時には、vethXX は消えますが、POD をすべて消しても cnio0 は残るようです。
# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:a9:a0:82 brd ff:ff:ff:ff:ff:ff
inet 192.168.199.210/24 brd 192.168.199.255 scope global enp1s0
valid_lft forever preferred_lft forever
3: cnio0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ba:a2:c1:d2:ec:ad brd ff:ff:ff:ff:ff:ff
inet 10.200.0.1/24 brd 10.200.0.255 scope global cnio0
valid_lft forever preferred_lft forever
8: vethda1293e1@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP group default
link/ether d2:4a:ce:16:16:67 brd ff:ff:ff:ff:ff:ff link-netns cni-9b15f61b-eca0-0ded-9dd3-19ac3306daba
ルーティングテーブル上には、 k8sworker0 の POD_CIDR (10.200.0.0/24) が cnio0 に行くようになっています。
これが図でいう③の部分に該当します。
実際には iptables で NAT されているようなのですが、ここでは割愛します。
余力があれば別途確認しま。。。す。。 かもしれない?
# ip route
default via 192.168.199.254 dev enp1s0 proto static
10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1
10.200.1.0/24 via 192.168.199.211 dev enp1s0 proto static
10.200.2.0/24 via 192.168.199.212 dev enp1s0 proto static
192.168.199.0/24 dev enp1s0 proto kernel scope link src 192.168.199.210
さらにさらに、 作成した POD の中のインターフェースを見てみると
eth0@if8 となっています。 この if8 が、 ワーカーノード上の ip addr で表示される番号と対応しています。
また、 8: vethda1293e1@if3 の if3 が 3: cnio0 とつながっている、という感じで追いかけることができます。
(なぜ 8 なの、という話ですが、 POD を作った際に次の番号がどんどんふられていき、
POD を消すとインターフェースもきえるため歯抜けになっていくんですね。
簡単に POD を立てます、とか言いつつ、 4-7 は失敗してやり直したわけだな、と思われてしまうわけですね)
# kubectl exec -it busybox-c44c795b6-r2qk9 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 4e:46:66:bd:b5:7f brd ff:ff:ff:ff:ff:ff
inet 10.200.0.3/24 brd 10.200.0.255 scope global eth0
valid_lft forever preferred_lft forever
ネットワークについても少しはイメージがわきましたね。わいたはずです。わいたことにしてください。
エラー・並びに調査・対応方法
さて、恒例の 黒歴史 トラブル内容紹介です。
先に何を間違えたのかを記載しておくと
- そもそもマスターでやっていた(論外)
- ルーティング設定で自分の POD_CIDR も 自分の NIC に転送するよう設定した
1点は、後から考えるとおバカだな、ぐらいの話しではありますが
実際にやっている最中はなかなか気づきません(と言い訳させてください)
2点目です。
ネットワークの設定完了後、疎通できるかどうかを確認すると思います。その途中で NW 疎通ができないことがわかりました。
調査の実施内容は以下の通りです。
結果を見ると、かなり遠回りしている印象ですが、実際の障害の時はそんなものかな、という気もします。
NW 疎通がおかしいなら、 自分が実施した NW 設定(ここではルーティング)がおかしい、と
考えることができれば早かったかもしれません。
(ただ、kubernetes the hard way を見ると、3つのルーティング設定が同列に扱われているように見えるので
オンプレでのルーティング設定もそうなんだろうとの思い込みがありました。。。)
- 各ノードへのPOD の配置 (deployment の作成)
- POD 内から別ノード上のPOD への ping 疎通 (異常の確認)
- POD 内から POD のデフォルトゲートウェイへの疎通確認
- POD 外から別ノード上の cnio0 (POD_CIDR のGW IP)への疎通確認
疎通ができないことがわかれば、あとはどこまで届いているのかを1つずつ確認していくことになりますが
その際に、上図のような構成が頭にないと分からない、ということになります。
POD の準備
3ノードの上にそれぞれ busybox の POD を立てて、疎通を確認しますが、
簡単に実施するのであれば deployment を作成し、 replica 数を増やせば各ノードに配置されると思います。
作成方法は kubectl apply -f ファイル名 で。
なお、 v1.16 であれば、 kubectl run busybox --image=busybox --restart=Always --replicas=3 -o yaml --dry-run --command -- sleep 3600 で yaml ファイルを生成できます(というか、--dry-run を外せば作成される)が、 v1.18 ではこのコマンドは使えず、 kubectl create deployment をベースとして yaml ファイルを作成する必要があります。
ここは面倒なところですね。
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
run: busybox
name: busybox
spec:
replicas: 3
selector:
matchLabels:
run: busybox
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
run: busybox
spec:
containers:
- command:
- sleep
- "3600"
image: busybox
name: busybox
resources: {}
status: {}
Pod が出来たら、 kubectl get pods -o wide で、調べたいノード上の POD を確認します。(IPも出ています)
# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-c44c795b6-5rg4h 1/1 Running 0 10s 10.200.2.218 k8sworker2 <none> <none>
busybox-c44c795b6-btf4v 1/1 Running 0 10s 10.200.1.143 k8sworker1 <none> <none>
busybox-c44c795b6-wh2cw 1/1 Running 0 10s 10.200.0.5 k8sworker0 <none> <none>
Pod 内からの確認
これは定番なので覚えておきましょう。
# kubectl exec -it busybox-c44c795b6-wh2cw /bin/sh
/ #
IP / route を確認します。
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether aa:f3:e9:62:35:2c brd ff:ff:ff:ff:ff:ff
inet 10.200.0.5/24 brd 10.200.0.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ip route
default via 10.200.0.1 dev eth0
10.200.0.0/24 dev eth0 scope link src 10.200.0.5
/ #
自分自身への ping 確認(記載省略)ののち、 デフォルトゲートウェイへの ping を行います。
/ # ping 10.200.0.1
PING 10.200.0.1 (10.200.0.1): 56 data bytes
^C
--- 10.200.0.1 ping statistics ---
5 packets transmitted, 0 packets received, 100% packet loss
飛んでいません。 いろいろと調べてわからない状態が続くと、
「もしかしてコンテナの世界ではデフォルトゲートウェイには ping が飛ばないのが普通なのでは?」などという
妄想がわいてきますがそんなことはありません。
疲れているとおかしなことを考えてしまうものです。そういう時は休みましょう。
デフォルトゲートウェイへの ping が飛ばない状態ですが、
コンテナ内の ip addr や ip route にそんなにおかしいようには思えない。
そのため、一旦コンテナの中には問題ないと仮定して、外からの確認に移ります。
POD 外からの確認
k8sworker0 の OS 上から他のノードの POD にアクセスできるかを確認します。
k8sworker0 から k8sworker1,2 の cni0 (それぞれ 10.200.1.1, 10.200.2.1 ) に ping し、応答があります。
root@k8sworker01:/etc/cni/net.d# ping 10.200.1.1
PING 10.200.1.1 (10.200.1.1) 56(84) bytes of data.
64 bytes from 10.200.1.1: icmp_seq=1 ttl=64 time=0.762 ms
64 bytes from 10.200.1.1: icmp_seq=2 ttl=64 time=0.294 ms
64 bytes from 10.200.1.1: icmp_seq=3 ttl=64 time=0.324 ms
^C
--- 10.200.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2047ms
rtt min/avg/max/mdev = 0.294/0.460/0.762/0.213 ms
root@k8sworker01:/etc/cni/net.d# ping 10.200.2.1
PING 10.200.2.1 (10.200.2.1) 56(84) bytes of data.
64 bytes from 10.200.2.1: icmp_seq=1 ttl=64 time=0.516 ms
64 bytes from 10.200.2.1: icmp_seq=2 ttl=64 time=0.408 ms
64 bytes from 10.200.2.1: icmp_seq=3 ttl=64 time=0.252 ms
^C
--- 10.200.2.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2031ms
rtt min/avg/max/mdev = 0.252/0.392/0.516/0.108 ms
ここまでで、 他のノードに関する通信は問題が無いことがわかります。
他のノードへの通信が問題なく、自ノード(のコンテナ)のみに疎通異常がある、ということで
その転送を行っている iptables を疑うわけですが、、、
- そもそも iptables がおかしい (kubernetes による iptables のコントロールがおかしい) などということがあるだろうか?
と考え、それよりも自分の設定がおかしいと考えるほうが可能性が高い、と思い、ルーティングテーブルを確認しました。
root@k8sworker01:# ip route show
default via 192.168.199.254 dev enp1s0 proto static
10.200.0.0/24 via 192.168.199.211 dev enp1s0 proto static
10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1
10.200.1.0/24 via 192.168.199.212 dev enp1s0 proto static
10.200.2.0/24 via 192.168.199.213 dev enp1s0 proto static
192.168.199.0/24 dev enp1s0 proto kernel scope link src 192.168.199.211
10.200.0.0/24 (自ノードの POD_CIDR) へのルートが重複していますね。
ここがおかしいのではないか?となります。
(なお、最初に POD を起動するまでは、 cnio0 に関するルートが無い、下記のような状態なので気づきませんでした
kubernetes the hard way の Provisioning Pod Network Routes を見ると、
下記のようなルーティングテーブルもなんとなく正しく思えます。。。
※間違い
# ip route show
default via 192.168.199.254 dev enp1s0 proto static
10.200.0.0/24 via 192.168.199.211 dev enp1s0 proto static
10.200.1.0/24 via 192.168.199.212 dev enp1s0 proto static
10.200.2.0/24 via 192.168.199.213 dev enp1s0 proto static
192.168.199.0/24 dev enp1s0 proto kernel scope link src 192.168.199.211
間違いに気づけば、あとは netplan のルーティング設定を見直して修正し、
問題解消を確認しました。
( 設定ファイルで 3台分入れて、自ノード分をコメントアウトしているのは
効率を考えたわけではなく、最初は3つ設定していた、ということなんですね。。。)
今回はここまでとして、次回は CoreDNS の部分を実施します。
← 12.kubectl
↑ 目次
→ 14.CoreDNS