つい最近までの私は、正規表現に苦手意識があり、ワイルドカードとの違いも正確に理解しないまま、grepやfindを持ち合わせの知識の中で使うだけだった。

そんな中、自社勉強会で正規表現を学習し、学習サイトも紹介してもらったのをきっかけに、現場で正規表現を活用できるようになってきた。
そこで、同じように躓いている方向けに、少しでも参考になればと思い、私の得た知識と活用場面を載せることにした。
これまで
まず、私が正規表現に苦手意識を持ったのは、自身で調べて学ぼうとした際のサイト選びが悪かった事。
なんだか、記号がたくさんあるし、活用場面がよく分からないし、現場では、なかなか使わないだろうなぁという後ろ向きな考えになり、そこから出来ない状態の自分に蓋をしてしまっていた。
その当時、作業で使っていた知識は以下になる
[Linux]
find / -name *.conf
grep -r 'abc' *
[サクラエディタ]
置換
置き換え前のインプットボックスに、空白(ブランク)を入れ、置き換え後を入力せず実行し、ファイル内の空白削除
同じ要領でタブ削除なども。
この程度の知識でも、それまではなんとか業務は行えていた。
しかし、ソースの調査・修正や仕様書作成で編集内容が増えてきて、だんだん苦しくなってきていた・・・
そして、勉強会を迎えた。
自社勉強会
以下に、私が学習した内容を載せる。
1.find,grepの違い
| コマンド | 検索方法 |
|---|---|
| find | ワイルドカード |
| grep | 正規表現 |
| egrep | 拡張正規表現 |
grepで正規表現を使えるといっても使用できないものもある。その場合は、拡張正規表現の使えるegrepを使用。
■ワイルドカード
*(0文字以上の任意の文字)と?(任意の1文字)を使い、以下のような検索が出来る。
# ls
abc.txt abcd.txt abcde.txt abcdef.txt
?(任意の1文字)で検索した場合
# find ./ -name 'ab?.txt'
./abc.txt
*(0文字以上の任意の文字)
# find ./ -name 'ab*.txt'
./abc.txt
./abcd.txt
./abcde.txt
./abcdef.txt
■grep
grepでの検索では、正規表現が使用されるので、知識がないと意図した検索結果にならない場合がある。
以下のような内容のファイルを検索する例で見ていく。
# cat abc.txt
System.log
System3log
abc.log
test.log
# grep 'System.log' abc.txt
System.log
System3log
検索したかったのは、「System.log」だけのつもりが、正規表現では、「.(ドット)」は、任意の一文字になるので、「System3log」も検索されてしまった。「System.log」だけを検索したいのであれば、以下のように次の一文字を文字として扱う「¥(\)」を使う。
# grep 'System\.log' abc.txt
System.log
grepを使った検索例にはこんなものもある。
psコマンドと合わせてgrepを使用した際、最後の行にgrepしたhttpdも検索されてしまっている。
# ps -ef |grep 'httpd'
root 1038 1 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1104 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1105 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1106 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1108 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1109 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
root 1565 1413 0 19:49 pts/0 00:00:00 grep --color=auto httpd
下記の例では'd'だけ正規表現として検索をしている。検索内容に正規表現が含まれると、検索順序が文字マッチしてから正規表現を加えるようになっているようでgrepはヒットしなくなる
# ps -ef |grep 'http[d]'
root 1038 1 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1104 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1105 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1106 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1108 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
apache 1109 1038 0 19:23 ? 00:00:00 /usr/sbin/httpd -DFOREGROUND
2.正規表現の学習
上記サイトを確認しながら勉強会を進めていった。知識を覚えるだけでなく、問題に回答していくクイズ形式のサイトになっているので、アウトプットが出来て、理解が進むサイトになっている。
学習をした中での例を、いくつか紹介する。
行頭を表す正規表現は「^」。行頭に指定文字があるかを探す場合
例では、行の先頭にsmがつくものを検索
# grep '^sm' /etc/services
行末の指定文字検索は最後に「$」を入れる
# grep 'er$' /etc/services
先頭がabcまたはtestで始まる文字。
「^」は行頭から。「()」は○○または△△。パイプが「または」の役割。
# grep -E '^(abc|test)' abc.txt
文字列検索なら()
例 (sato|suzuki)
だが、一文字なら[]を使う。
例 [abc]
aかbかc
大文字小文字のアルファベットか0から9の数字どれかが当てはまるもの
# grep '[A-z0-9]' abc.txt
System.log
System3log
abc.log
test.log
行頭がabcのどれか
^[abc]
abcじゃない(否定系)
[^abc]
※否定形の場合は、カッコ内に入れる。
行が英大文字3文字のみを検索
# grep '^[A-Z][A-Z][A-Z]$' abc.txt
ABC
DDD
※^$を加えることで3文字だけのものに制限できる
1文字だけの行を検索
# grep '^.$' abc.txt
o
a
i
z
勉強会後の現場での活用
正規表現を学んだことで、以下のように作業方法が変わっていった。
・コメントになっている値のある行を検索
[root@xxxx ~]# grep '^#.*[0-9]' /etc/httpd/conf/httpd.conf
# Listen 12.34.56.78:80
# ServerName www.example.com:80
・行末にsoが含まれる行
[root@xxxx ~]# grep 'so$' /etc/httpd/conf/httpd.conf
# LoadModule foo_module modules/mod_foo.so
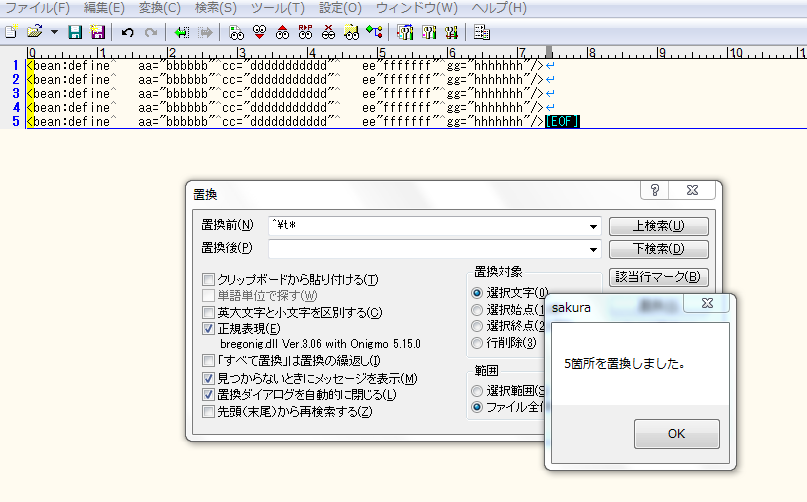
・不揃いのタブを削除
実行前
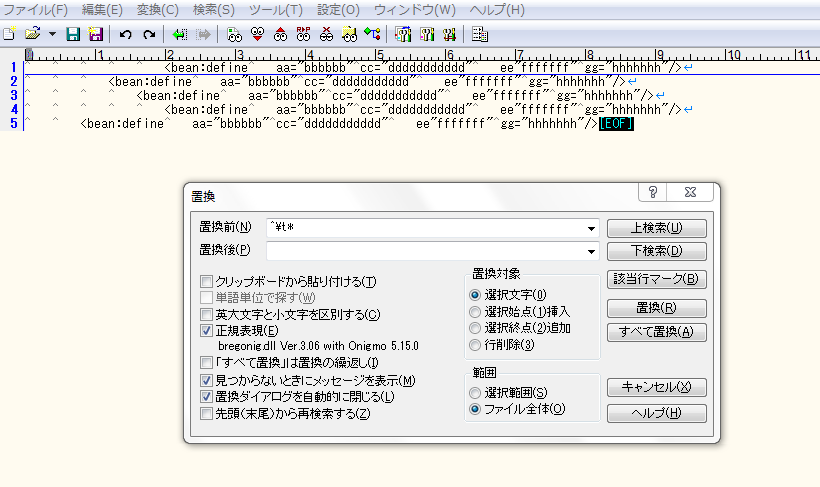
実行後
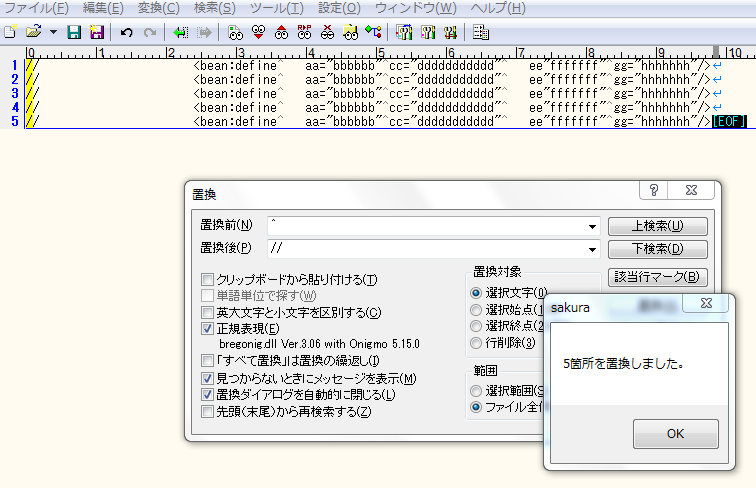
・行頭にコメント挿入
実行前
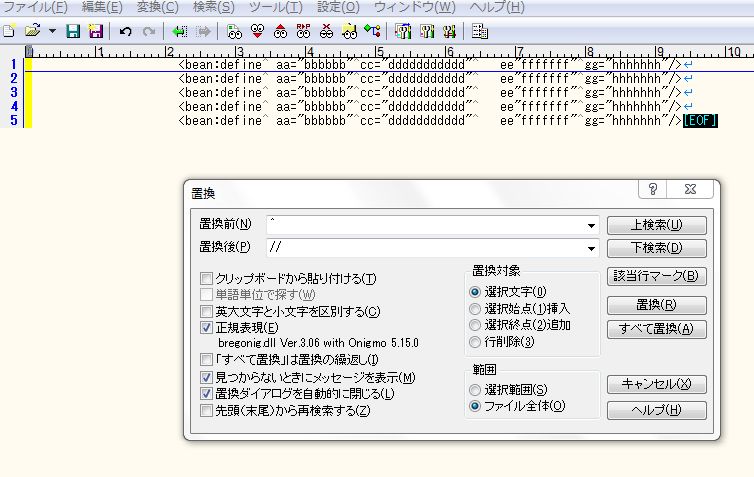
実行後
・不揃いの行末に;を挿入
実行前
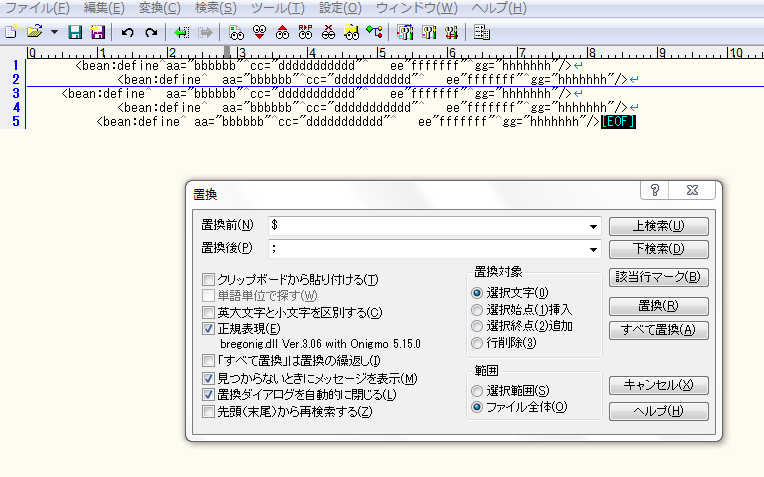
実行後
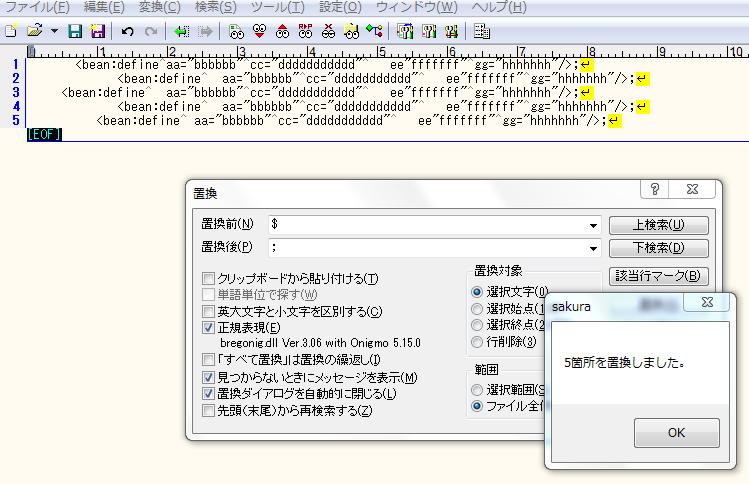
一番大きな収穫は、サクラエディタでの置換によって、作業効率が上がったことだ。
正規表現を活用できていない方は、是非、参考サイトで学習をしてみて欲しい。