はじめに
この記事では強化学習の手法のひとつである方策勾配法をTensorflowを使って実装し、AIにFlappyBirdをプレイさせます。以下は実際に学習を行わせた後のプレイ動画です。学習を簡単にさせるために上下のパイプ同士のギャップを広くしていますが、何回もパイプを通過することが出来ています。

この記事のインタラクティブバージョンは以下のColaboratoryで公開しています。
https://colab.research.google.com/drive/1GpnaWSZAumB5UBvstCht5ADBbQ8-ry73#scrollTo=vyJSDCY8umdg
強化学習
強化学習では、エージェントが環境と相互作用を行い、その過程で得られる報酬を最大化することを目指します。
環境の定式化としてよく用いられているのはマルコフ決定過程(Markov Decision Process; MDP) であり、次の4つ組$(S, A, P, R)$で定義されます。
- $S$ : 取りうる状態の集合
- $A$ : 取りうる行動の集合
- $P(s'|s,a)$ : 状態 $s \in S$ で行動 $a \in A$ を選択した時の次の状態 $s' \in S$ への遷移確率
- $R(s,a)$ : 状態 $s$ で行動 $a$ を選択した時の報酬 $r \in \mathbb{R}$ を与える関数
エージェントは環境の状態を観測し行動を選択します。状態 $s$ が与えられた時にエージェントがある行動 $a$ を選択する確率を与える関数 $\pi(s,a)$ を方策と呼びます。
初期状態 $s_0$ から初めて終了状態 $s_T$ で終わるまでの環境とエージェントとの相互作用で得られる系列 $\tau = (s_0, a_0, r_0, s_1, a_1, r_1, ... ,a_{T-1}, r_{T-1}, s_T)$をエピソードと呼びます。エピソードによって得られる割引き累積報酬 $G(\tau)$ はリターンと呼ばれます:
$$ G(\tau) = \sum_{t=0}^{T_{\tau}-1} \gamma^{t} r_t $$
ただし $\gamma \in (0,1]$ は割引き率と呼ばれ、将来の報酬と比べて現在の報酬をどれだけ優先するかを示します。
強化学習の目的はリターンの期待値 $J$ を最大化することです:
$$ J(\pi) = \mathbb{E}_{\tau}[ G(\tau) ]$$
方策勾配法
方策 $\pi$ のパラメタを $\theta$ とします。
方策勾配法では、期待リターンの $\theta$ に関する勾配の推定量を求め、確率的勾配降下法などの勾配ベースの最適化アルゴリズムによって$\theta$ を更新していきます。期待リターンの勾配の導出は数式が煩雑になるので省きますが、最終的に得られる更新則は以下の通りです($\alpha$ は学習率)。
$$ \theta \leftarrow \theta + \alpha \sum_{t=0}^{T_{\tau} - 1} \nabla_\theta log\pi_\theta(a_{t} | s_{ t}) \sum_{t'=t}^{T_{\tau} -1} \gamma^{t'-t} r_{t'}$$
環境
ここから、実装の詳細を説明していきます。
強化学習の環境はPyGame Learning Environment (PLE) で提供されているFlappyBirdに基づきます。
エージェントは適切に上方向に加速することでパイプの間を通り抜けて行かなければなりません。
以下は環境を表すクラスです。
最も重要なメソッドは環境の状態を得るgetStateと行動を起こして報酬を得るactであり、この2つを交互に繰り返すことでエピソードが進行します。エピソードの終了はis_endメソッドで検知します。
class Environment:
def __init__(self):
# FlappyBird環境を初期化する。
# 学習を容易にするため、上下のパイプ同士の幅をデフォルト100から150に変える。
# また、一回行動を行うごとにフレームを2つ遷移させるように設定することで、エピソードの時系列幅を半分にする。
self.game = flappybird.FlappyBird(pipe_gap=150)
self.game_height = self.game.height
self.game_width = self.game.width
self.frame_skip = 2
self.environment = PLE(self.game, display_screen=False, force_fps=True, frame_skip=self.frame_skip, reward_values={'win': 1.0, 'loss': -1.0, 'negative': 0.0},)
self.environment.init()
def getStateDim(self):
# 状態は8次元
return 8
def getActionDim(self):
# 行動は上に加速するか、何もしないかの2種類
return 2
def getScreenRGB(self):
# ゲームの画面を得る
return self.environment.getScreenRGB()
def getState(self):
# ゲームの状態を得る
# 画面の高さと幅で割ることで8次元ベクトルをスケーリングする
state_dict = self.game.getGameState()
state = np.array([
state_dict['next_pipe_top_y'] / self.game_height,
state_dict['next_pipe_bottom_y'] / self.game_height,
state_dict['next_pipe_dist_to_player']/ self.game_width,
state_dict['next_next_pipe_top_y'] / self.game_height,
state_dict['next_next_pipe_bottom_y']/ self.game_height,
state_dict['next_next_pipe_dist_to_player']/ self.game_width,
state_dict['player_vel'] / self.game_height,
state_dict['player_y'] / self.game_height,
], dtype=np.float32)
return state
def act(self,action):
# 行動は0ならば何もしない、1ならば上に加速する。
# 行動の結果として状態が更新され、報酬が出される。
# 報酬はパイプを通り抜ける度に+1、地面やパイプに衝突した場合は-1。
assert(action in [0,1])
_action = {0:'None',1:119}[action]
reward = self.environment.act(_action)
return reward
def is_end(self):
# 地面やパイプに当たったらゲームオーバーでエピソードが終了する。
return self.environment.game_over()
def reset(self):
# ゲームをやり直す(スコアや状態が初期化される)
self.environment.reset_game()
def score(self):
# ゲームのスコアを表示する
return self.environment.score()
エージェント
次にエージェントのクラスを説明します。 方策はフィードフォワードニューラルネットワークによって実装します。 状態に基づいて方策から行動を選択するのはstepメソッドにより行います。 エピソード終了時にend_episodeメソッドでリターンを計算します。 update_policyで方策勾配法の更新則を実行します。
class Agent:
def __init__(self, state_dim, action_dim, gamma = 0.95, learning_rate = 2e-4, seed = 123):
# 初期化では状態と行動の次元数を設定する。
# 割引率γや学習率を設定し、エピソードの状態、行動、報酬、リターンの系列を初期化する
self.state_dim = state_dim
self.action_dim = action_dim
self.gamma = gamma
self.learning_rate = learning_rate
self.episode_states = []
self.episode_actions = []
self.episode_rewards = []
self.episode_returns = []
# 方策関数は、入力が状態の次元数であり、出力が行動の次元数であるフィードフォワードニューラルネットワーク
self.policy_network = tf.keras.Sequential([
tf.keras.layers.Dense(50, input_shape=[self.state_dim], activation=tf.nn.relu, kernel_initializer=tf.truncated_normal_initializer(seed=seed)),
tf.keras.layers.Dense(self.action_dim, activation='softmax')
])
# 最適化アルゴリズムはRMSPropを用いる
self.optimizer = tf.train.RMSPropOptimizer(learning_rate=self.learning_rate)
self.step_counter = tf.train.get_or_create_global_step()
def policy(self,state):
# 状態ベクトルを受け取り、現在の方策の下での行動の確率を出力する
layer_input = tf.expand_dims(state,axis=0)
action_distribution = self.policy_network(layer_input)
action_distribution = tf.squeeze(action_distribution, axis=0)
return action_distribution
def step(self,state,reward):
# 状態と報酬を受け取り、行動の確率に基づいて行動をサンプリングし、出力する
# 状態、行動、報酬は系列に保存する
action_distribution = self.policy(state)
action = np.random.choice(range(self.action_dim), p=action_distribution.numpy())
self.episode_states.append(state)
self.episode_actions.append(action)
self.episode_rewards.append(reward)
return action
def end_episode(self,final_reward):
# 最終的な報酬を受け取ってエピソードを終了する
# このとき、各時点を基準としてエピソードのリターンを計算する
n = len(self.episode_rewards)
self.episode_returns = [0. for i in range(n)]
self.episode_returns[-1] = final_reward
for i in range(n-2,-1,-1):
self.episode_returns[i] = self.episode_rewards[i] + self.gamma * self.episode_returns[i+1]
def reset(self):
# エピソードの系列をリセットする
self.episode_states = []
self.episode_actions = []
self.episode_rewards = []
self.episode_returns = []
def update_policy(self):
# 方策勾配法の更新則を適用してパラメタを更新
with tf.GradientTape() as tape:
actions_one_hot = np.array([[ 1 if i == a else 0 for i in range(self.action_dim)] for a in self.episode_actions])
action_distributions = self.policy_network(np.array(self.episode_states))
action_log_probabilities = tf.log(tf.reduce_sum(action_distributions * actions_one_hot,reduction_indices = 1))
loss = tf.reduce_mean(- action_log_probabilities * self.episode_returns)
grads = tape.gradient(loss, self.policy_network.variables)
self.optimizer.apply_gradients(zip(grads, self.policy_network.variables), global_step=self.step_counter)
便利関数
学習の進行具合をトラッキングしたり、アニメーション/グラフを作る便利関数を定義しておきます。
def progress(value, max=100, message=''):
# プログレスバー
return display.HTML("""
<progress
value='{value}'
max='{max}',
style='width: 100%'
>
{value}
</progress>
<p>{message}</p>
""".format(value=value, max=max, message=message))
def plot_rolling_returns(rolling_returns):
# リターンの移動平均をプロットする
sns.tsplot(rolling_returns)
plt.title('Rolling Returns')
plt.xlabel('# Epsiodes')
plt.ylabel('Rolling Return')
def make_animation(images, fps=20):
# アニメーションを作る
duration = len(images) / fps
def make_frame(t):
try:
x = images[int(len(images) / duration * t)]
except:
x = images[-1]
return x.astype(np.uint8)
clip = mpy.VideoClip(make_frame, duration=duration)
clip.fps = fps
return clip
def show_movie(agent,environment,num_episodes=1):
# エージェントと環境のインスタンスを受け取り、エージェントがプレイする様子のアニメーションを表示する
frames = []
for episode in range(num_episodes):
reward = 0
environment.reset()
while not environment.is_end():
frames.append(environment.getScreenRGB())
state = environment.getState()
action = agent.step(state,reward)
reward = environment.act(action)
agent.end_episode(reward)
clip = make_animation(frames, fps=30).rotate(-90)
display.display(clip.ipython_display(fps=30, center=False, autoplay=False, loop=False, height=320, width=240, max_duration=300000))
agent.reset()
学習
いよいよ学習を行います。 学習は関数run_episodeでエピソードを回し、パラメタ更新する処理をループで繰り返すことで行います。学習の様子は上で定義した便利関数でトラッキングします。
def run_episode(agent,environment):
# エピソードを1回走らせる
reward = 0
counter = 0 # パイプを通過した回数を管理
environment.reset()
while not environment.is_end() and counter < 30: # ゲームオーバー又はパイプを30回以上通過したら終了
state = environment.getState() # 状態を観測
counter += reward
action = agent.step(state,reward) # 行動を選択
reward = environment.act(action) # 行動に基づいて状態を更新し、報酬を獲得する
agent.end_episode(reward) # エピソードを終了
return reward
def run_loop(seed,num_episodes=1000,rolling_return_frequency=100,record_every = 100):
progress_out = display.display(progress(0, num_episodes), display_id=True) # プログレスバーを初期化
tf.set_random_seed(seed) # シードを設定
np.random.seed(seed) # シードを設定
env = Environment() # 環境を初期化
agent = Agent(state_dim=env.getStateDim(), action_dim=env.getActionDim(), gamma = 0.95, seed = seed) # エージェントを初期化
windowed_return = deque() # 直近のリターンを保持
rolling_returns = [] # リターンの移動平均を保持
for episode in range(num_episodes):
final_reward = run_episode(agent,env) # エピソードを回す
agent.update_policy() # 方策勾配法の更新則を実行
agent.reset() # エピソードごとにエピソード系列をリセット
# 便利関数を色々実行
windowed_return.append(env.score())
if len(windowed_return) > rolling_return_frequency:
windowed_return.popleft()
rolling_return = sum(windowed_return) / len(windowed_return)
rolling_returns.append(rolling_return)
message = 'Episode {}/{} ended with score {}, Rolling Return: {}'.format(episode+1, num_episodes, env.score(), rolling_return)
progress_out.update(progress(episode+1, num_episodes, message))
if episode % record_every == 0 and episode > 0: # 一定の間隔でアニメーションを表示
show_movie(agent,env,num_episodes=5)
return rolling_returns, agent, env
# メイン処理
rolling_returns, agent, env = run_loop(seed=np.random.randint(100000),num_episodes = 10000, record_every=2000)
plot_rolling_returns(rolling_returns)
結果
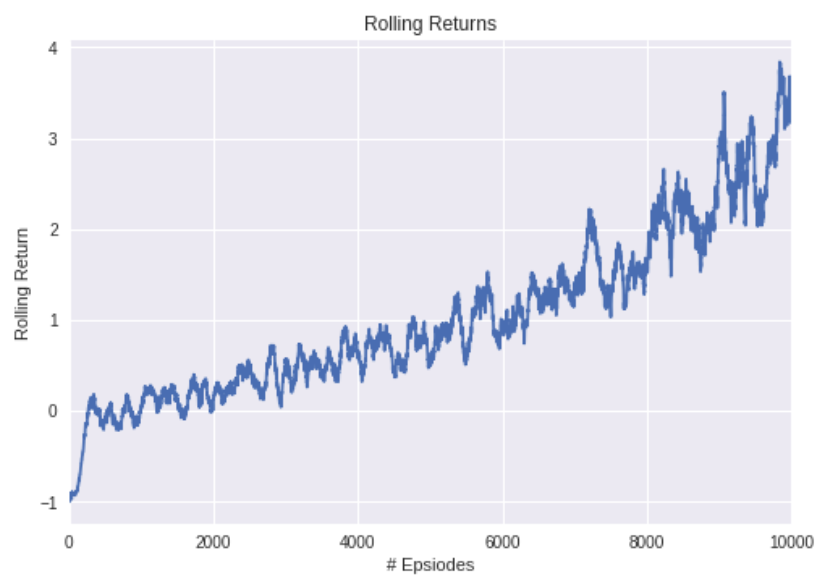
1万エピソード分学習させたところ、平均して5回ほどパイプを通過できるくらいにプレイが上手くなりました。以下が学習曲線です。若干振動していますが、進行とともに実力がどんどん上達していっていることがわかります。1万回で打ち消していますがエピソードの数を増やせば実力は上がり続けるはずです。
まとめ
この記事では強化学習の手法の一つである勾配効果法を使ってFlappyBirdを学習させました。簡単なアルゴリズムであるにも関わらず上手くプレイできるようになるのが面白いと思います。