以下のテキストでは、AIを用いた画像認識により対象物を分類し、ロボットアームにより仕分けを行っています。
・DOBOT Magician AIx画像認識xロボットアーム制御
分類した結果として、最も該当している(それらしい、確率が高い)ラベルが出力されるため、ぎりぎり該当したようなものも学習したいずれかのラベルに分類されてしまいます。そのような状態を回避したい場合、学習データをもっと集めて、より良いモデルを学習させる方法もありますが、今回の記事では、該当している確率が低いものは無視するようにプログラムを修正したいと思います。
修正前
classifer.py
# 分類する(3-10)
result = model.predict_classes(image)
proba = model.predict_proba(image)
result_num = int(result[0])
修正前は、似ている対象物が異なるラベルとして出力されることがあります。
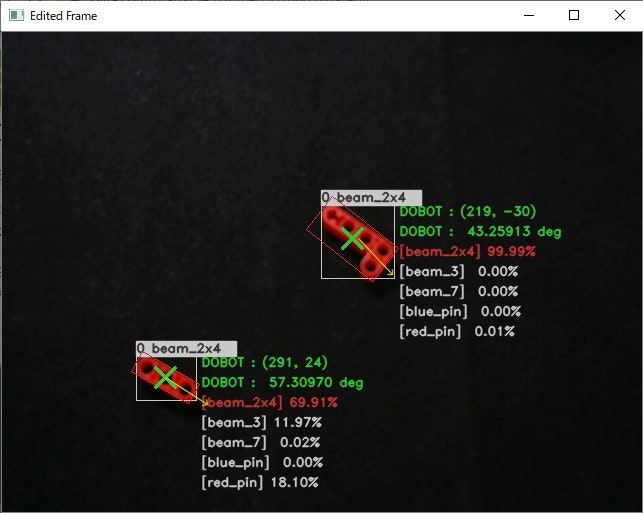
以下の画像では、左下のパーツは本来「beam_3」が正しいラベルとして学習していますが、「beam_2x4」という別のパーツとして認識しています。
修正後
classifer.py
# 分類する(3-10)
result = model.predict_classes(image)
proba = model.predict_proba(image)
proba_check = False
for p in proba[0]:
if p >= 0.95: # 確率が95%以上の場合、フラグを立てる
proba_check = True
if proba_check != True: # 95%以上のものがなければcontinueする
continue
result_num = int(result[0])
分類結果として出力されているそれぞれのラベルである確率を順番に確認し、95%以上のものがなければ以降の処理をスキップするように修正しています。
以下の画像のように95%に満たないものは判別結果として表示されません。
