以下のテキストを使用する際、カメラのセッティング等で上手くいかない場合があるので、解決方法を記載します。
DOBOT Magician AIx画像認識xロボットアーム制御
測定マット上の色を読み取れない
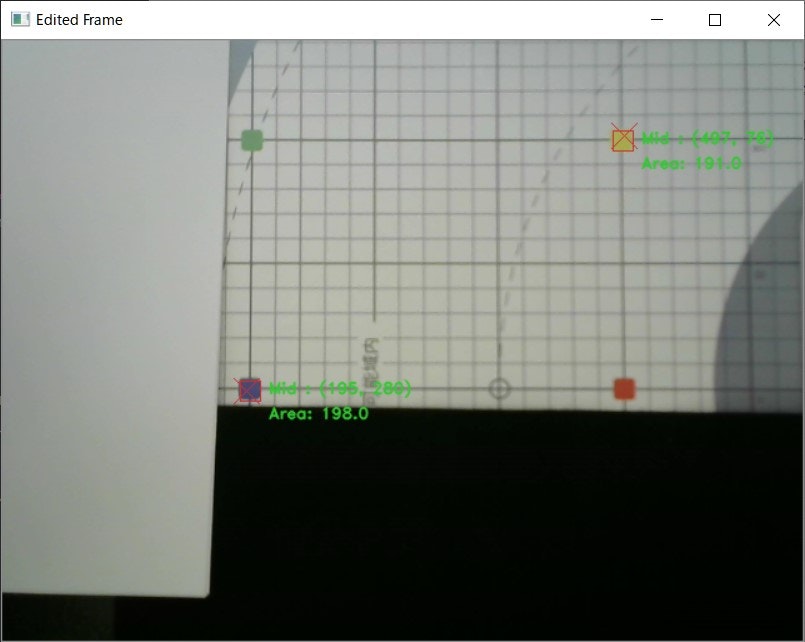
カメラの座標からロボットアームの座標へ変換するために測定マット上の4色の座標を読み取り、変換マトリックスを生成するステップがあります。その際、4色の座標だけを上手く読み取れないことがあります。
例えば、以下の画像の場合、黄色の座標は読み取れていますが、それ以外の色は読み取れていません。
また、灰色の部分を誤認識しています。

対策:余計な部分を隠す
余計な部分を認識する場合は、誤認識する部分を隠すのが簡単な解決方法だと思います。
対策:認識するサイズを調整する
認識してほしいところを認識しない場合は、領域抽出用のサイズを調整すると正しく認識するようになることがあります。ソースコード上の以下の箇所の最小サイズ、最大サイズの値を調整します。
opencv_setting.py
# 領域抽出用の最小/最大サイズ
MIN_AREA_SIZE = 80
MAX_AREA_SIZE = 200
↓ 変更後
opencv_setting.py
# 領域抽出用の最小/最大サイズ
MIN_AREA_SIZE = 150
MAX_AREA_SIZE = 400

判別対象が認識しない
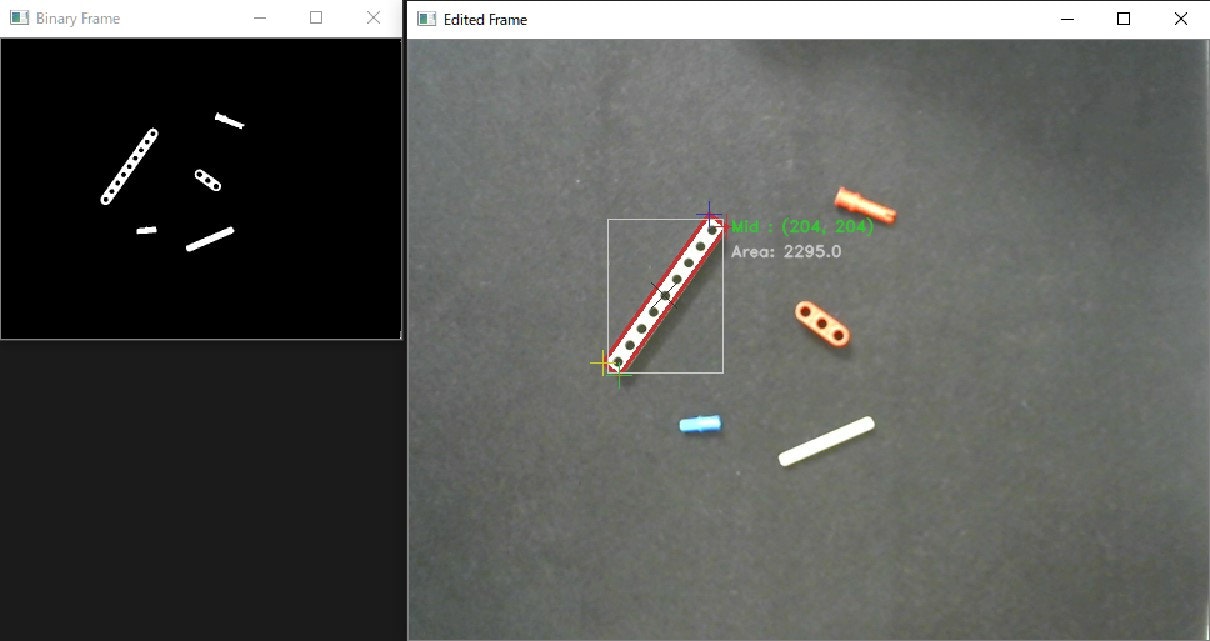
AIによる対象物の判別をするために学習データを集めます。その際、判別対象を認識しないことがあります。
対策:認識するサイズを調整する
以下の画像のようにバイナリー化(2値化)した画像で物体がくっきり見えている場合は、前述した領域抽出用のサイズを変更することで認識するようになります。
opencv_setting.py
# 領域抽出用の最小/最大サイズ
MIN_AREA_SIZE = 1.5e3 # 1500
MAX_AREA_SIZE = 1e4 # 10000
↓ 変更後
opencv_setting.py
# 領域抽出用の最小/最大サイズ
MIN_AREA_SIZE = 250
MAX_AREA_SIZE = 3000
