はじめに
日本語JPOPの音声と歌詞のアライメントを試行錯誤しています(シリーズ一覧)。
上記シリーズのその1では、2022年10月時点のtorchaudioのチュートリアルに従い、wav2vec2を用いたforced-alignmentを行いました。しかし、2024年11月現在、forced-align用のより簡単なハイレベルAPIが提供されていることに気づきました。そこで、最近のtorchaudioを使って再度forced-alignmentを試してみます。
forced-align用のハイレベルAPIには、torchaudio.pipelines.Wav2Vec2FABundleとtorchaudio.functional.forced_align()の2種類があります。本記事では、前者のチュートリアルを実行してみます。
以下では、基本的にチュートリアルに沿って進めますが、スムーズに実行できなかった部分や理解が難しかった部分については、補足を加えます。
環境構築
ハードは以下です。
- M1 macOS 14.5
仮想環境の作成にuvを使用します。uvを使わない方はuv addの部分をpipに置き換えるなどしてください。
# プロジェクトの作成と初期化。pythonバージョンは3.12を使用。
uv init forced-alignment -p 3.12
# プロジェクトルートに移動
cd forced-alignment
# パッケージのインストール
uv add "torch<2.3" # 2.3以上のtorchをuv addすると失敗する
uv add torchaudio
uv add "numpy<2" # torchがnumpy v1にしか対応してなさそう?
uv add --dev ipykernel matplotlib # notebook上でtutorialするため
以下に補足を示します。
- torchとPythonのバージョンの互換性はシビアな印象があります。今回はPython 3.12を使用しました。
- uvを用いてtorchをインストールするのは難しい場合があります。macOSかLinuxによっても異なるようです。macOSではtorch>=2.4のインストールに成功した例もありますが、自分の環境ではうまくいかず、最終的に2.2を使用することにしました。
- uv add torchではなくuv pip install torchを使用すると、2.5のインストールに成功します。pyproject.tomlに情報を残すことにこだわらない場合は、uv pip installでも良いと思います。
- numpyもtorchをインストールするとv2が入ってしまいますが、エラーが発生するため、v1を再インストールしました。
最終的なpyproject.tomlは以下です。
[project]
name = "forced-alignment"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
authors = [
{ name = "GitHub Actions", email = "actions@github.com" }
]
requires-python = ">=3.12"
dependencies = [
"numpy<2",
"torch<2.3",
"torchaudio>=2.2.2",
]
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[dependency-groups]
dev = [
"ipykernel>=6.29.5",
"matplotlib>=3.8.1",
]
チュートリアル
以下、jupyter notebook上での実行を前提とします。kernelにuvで作成した.venvを指定してください。
ライブラリのインストール
torchとtorchaudioをimportして、バージョンと利用可能なデバイスを確認します。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2.2.2
2.2.2
cpu
チュートリアルでは2.5.0, 2.5.0, cudaでしたが、今回の環境では上記でした。
続いてグラフ表示用のライブラリをimportします。
from typing import List
import IPython
import matplotlib.pyplot as plt
音響モデルとトーカナイザの読み込み
forced-alignmentのプロセスは次のステップで構成されています。
- 音響モデルを使って、音声波形(wav)をトークン(音素)の確率分布リストに変換します。
- トーカナイザを使って、テキストをトークンのリストに正規化します。
- alignerを使って、2で得たトークンのタイムスタンプを1の出力に基づいて決定します。
(図: チュートリアルより引用)

音響モデルとトーカナイザは同じトークン集合を扱う必要があります。つまり、この2つはセットである必要があります。torchaudio.pipelinesでは、Wav2Vec2FABundleというクラスでこの音響モデルとトーカナイザのセットを扱えます。MMS_FAはWav2Vec2FABundleの具体的なインスタンスの一つです。MMS_FAの音響モデルは、1100種類以上の言語からなる23000時間の音声で訓練されています。これをインポートします。
from torchaudio.pipelines import MMS_FA as bundle
model = bundle.get_model()
model.to(device)
tokenizer = bundle.get_tokenizer()
aligner = bundle.get_aligner()
MMS_FAが扱うtokenの辞書を確認してみます。
print(bundle.get_dict())
{'-': 0, 'a': 1, 'i': 2, 'e': 3, 'n': 4, 'o': 5, 'u': 6, 't': 7, 's': 8, 'r': 9, 'm': 10, 'k': 11, 'l': 12, 'd': 13, 'g': 14, 'h': 15, 'y': 16, 'b': 17, 'p': 18, 'w': 19, 'c': 20, 'v': 21, 'j': 22, 'z': 23, 'f': 24, "'": 25, 'q': 26, 'x': 27, '*': 28}
スター("*")については、詳細を理解できていませんが、おそらく「その他」に該当するトークンです。使用を避けたい場合は、bundle.get_modelの引数にwith_star=Falseを指定します。今回はスターを含める設定にします。
便利関数の実装
いくつかの便利な関数を定義します。
まず、forced-alignmentのプロセスを一括で実行する関数を作成します。このプロセスは前述の通り、以下のステップで構成されます:
- 音響モデルを使用して、音声波形(wav)をトークン(音素)の確率分布リストに変換します。
- トーカナイザを使用して、テキストをトークンのリストに正規化します。
- alignerを使用して、2で得たトークンのタイムスタンプを1の出力に基づいて決定します。
関数の入力は音声波形のテンソルとトランスクリプトです。トランスクリプトは分かち書きされた単語のリストで、各単語はローマ字に正規化されています。出力は、音響モデルが音声波形を解析した結果の確率分布(emission)とalignerによるアラインメントの結果(token_spans)です。token_spansはトランスクリプトの各文字に対応する開始と終了のフレーム番号と、確信度を示すスコアを含みます。emissionは描画のために返されますが、forced-alignmentの結果を得るだけならtoken_spansだけで十分です。なお、token_spansを計算するためのalignerは、内部的にtorchaudio.functional.forced_align()を使用しているようです。
def compute_alignments(waveform: torch.Tensor, transcript: List[str]):
with torch.inference_mode():
emission, _ = model(waveform.to(device))
token_spans = aligner(emission[0], tokenizer(transcript))
return emission, token_spans
グラフを出力するための便利関数を続けて定義しています。グラフを出力することに興味がなければ必ずしも必要ではありません。
# Compute average score weighted by the span length
def _score(spans):
return sum(s.score * len(s) for s in spans) / sum(len(s) for s in spans)
def plot_alignments(waveform, token_spans, emission, transcript, sample_rate=bundle.sample_rate):
ratio = waveform.size(1) / emission.size(1) / sample_rate
fig, axes = plt.subplots(2, 1)
axes[0].imshow(emission[0].detach().cpu().T, aspect="auto")
axes[0].set_title("Emission")
axes[0].set_xticks([])
axes[1].specgram(waveform[0], Fs=sample_rate)
for t_spans, chars in zip(token_spans, transcript):
t0, t1 = t_spans[0].start, t_spans[-1].end
axes[0].axvspan(t0 - 0.5, t1 - 0.5, facecolor="None", hatch="/", edgecolor="white")
axes[1].axvspan(ratio * t0, ratio * t1, facecolor="None", hatch="/", edgecolor="white")
axes[1].annotate(f"{_score(t_spans):.2f}", (ratio * t0, sample_rate * 0.51), annotation_clip=False)
for span, char in zip(t_spans, chars):
t0 = span.start * ratio
axes[1].annotate(char, (t0, sample_rate * 0.55), annotation_clip=False)
axes[1].set_xlabel("time [second]")
fig.tight_layout()
preview_wordは、アラインメント結果を確認するための関数です。単語に対応するspansを入力として受け取り、それをwavの時間に変換して切り取り、notebookのUI上で再生可能なコンポーネントを出力します。
def preview_word(waveform, spans, num_frames, transcript, sample_rate=bundle.sample_rate):
ratio = waveform.size(1) / num_frames
x0 = int(ratio * spans[0].start)
x1 = int(ratio * spans[-1].end)
print(f"{transcript} ({_score(spans):.2f}): {x0 / sample_rate:.3f} - {x1 / sample_rate:.3f} sec")
segment = waveform[:, x0:x1]
return IPython.display.Audio(segment.numpy(), rate=sample_rate)
トランスクリプトの正規化
アライメントを行うためには、英語以外の言語の場合は、ローマ字表記に変換(正規化)する必要があります。
チュートリアルではuromanというモジュールを使ってローマ字化する方法を紹介しています。
uromanは日本語にも対応していますが、分かち書きは行わないため、日本語の場合はuromanではなく、mecabとjaconvを組み合わせる方法も考えられます。
ここでは、チュートリアルに従ってuromanを使用します。
チュートリアルでは、uroman.plスクリプトをダウンロードして実行する方法が紹介されていますが、pipでもインストール可能です。ここではpip(uvではuv add)を使用します。
uv add --dev uroman
echo "des événements d'actualité qui se sont produits durant l'année 1882" > text.txt
cat text.txt | uv run uroman > text_romanized.txt
cat text_romanized.txt
des evenements d'actualite qui se sont produits durant l'annee 1882
uromanの出力では大文字は大文字のままになっていたり、記号が残ったりする可能性があるため、それらをalignできるように正規化する関数も別途定義しておくと良さそうです。
import re
def normalize_uroman(text):
text = text.lower()
text = text.replace("’", "'")
text = re.sub("([^a-z' ])", " ", text)
text = re.sub(' +', ' ', text)
return text.strip()
with open("text_romanized.txt", "r") as f:
for line in f:
text_normalized = normalize_uroman(line)
print(text_normalized)
冒頭で述べたように、日本語の場合はuromanにこだわる必要はありません。
次の節では、正規化された文章はハードコーディングで提供されるため、上記の関数はチュートリアルでは使用しません。
アライメントの実行
これまでに準備した関数を使ってアライメントを実行します。
ドイツ語で試してみます。
ドイツ語の生テキストと正規化されたテキストを用意しますが、使用するのは正規化されたテキストのみです。
また、サンプル音源をダウンロードし、torchaudioでロードします。
ロード時にframe_offsetを使用して冒頭0.5秒をカットし、num_framesの指定で2.5秒間だけ取得します。
text_raw = "aber seit ich bei ihnen das brot hole"
text_normalized = "aber seit ich bei ihnen das brot hole"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/10349_8674_000087.flac"
waveform, sample_rate = torchaudio.load(
url, frame_offset=int(0.5 * bundle.sample_rate), num_frames=int(2.5 * bundle.sample_rate)
)
音源のサンプルレートが音響モデルが想定するフレームレートと等しいことを保証しておきます。ここが異なる場合、音源のフレームレートを変更する必要があります。
assert sample_rate == bundle.sample_rate
アライメントを実行します。
transcript = text_normalized.split()
tokens = tokenizer(transcript)
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
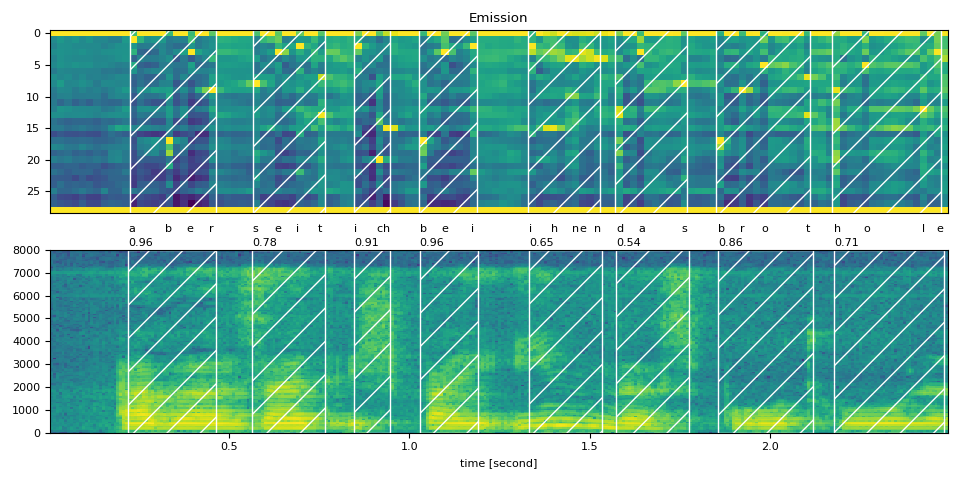
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
うまく行けば、単語ごとのタイムスタンプ区間が網掛けされた音声波形グラフがnotebook上に表示されます。以下はチュートリアルページにある図です。
補足
チュートリアルには含まれていませんが、理解を深めるためにいくつか手を動かします。
変数の確認
理解を深めるために変数の中身を確認します。
transcriptは正規化された単語のリストです。
print(transcript)
['aber', 'seit', 'ich', 'bei', 'ihnen', 'das', 'brot', 'hole']
tokenizerはtranscriptの文字をtoken_idに変換します。
# tokens = tokenizer(transcript)
print(tokens)
[[1, 17, 3, 9], [8, 3, 2, 7], [2, 20, 15], [17, 3, 2], [2, 15, 4, 3, 4], [13, 1, 8], [17, 9, 5, 7], [15, 5, 12, 3]]
waveformは音声波形のテンソルで、その長さはサンプル数を表します。今回の例では、音声は2.5秒分で、サンプリングレート(bundle.sample_rate)は16000です。したがって、サンプル数は16000 x 2.5 = 40000となります。
emissionは各フレームごとのtokenの確率を示すもので、今回は124フレームあります。40000サンプルを124フレームで割ると、1フレームはおおよそ322サンプルに相当します。最後の29はtokenの種類数を示しています。
# emission, token_spans = compute_alignments(waveform, transcript)
# num_frames = emission.size(1)
print(waveform.shape)
print(emission.shape)
torch.Size([1, 40000])
torch.Size([1, 124, 29])
token_spansはTokenSpanというデータクラスのリストのリストです。
各tokenの開始と終了フレーム、スコアが定義されています。
# emission, token_spans = compute_alignments(waveform, transcript)
for t_spans in token_spans:
print(t_spans)
[TokenSpan(token=1, start=11, end=12, score=0.990403413772583), TokenSpan(token=17, start=16, end=17, score=0.8990433812141418), TokenSpan(token=3, start=19, end=20, score=0.9892619252204895), TokenSpan(token=9, start=22, end=23, score=0.9785513281822205)]
[TokenSpan(token=8, start=28, end=29, score=0.9856530427932739), TokenSpan(token=3, start=31, end=32, score=0.9621726274490356), TokenSpan(token=2, start=34, end=35, score=0.9627020359039307), TokenSpan(token=7, start=37, end=38, score=0.20485366880893707)]
[TokenSpan(token=2, start=42, end=43, score=0.9471160769462585), TokenSpan(token=20, start=45, end=46, score=0.9715177416801453), TokenSpan(token=15, start=46, end=47, score=0.8045649528503418)]
[TokenSpan(token=17, start=51, end=52, score=0.9538814425468445), TokenSpan(token=3, start=54, end=55, score=0.9583628177642822), TokenSpan(token=2, start=58, end=59, score=0.9552607536315918)]
[TokenSpan(token=2, start=66, end=67, score=0.8190246224403381), TokenSpan(token=15, start=69, end=70, score=0.6312776207923889), TokenSpan(token=4, start=72, end=73, score=0.5811408162117004), TokenSpan(token=3, start=73, end=74, score=0.4887586236000061), TokenSpan(token=4, start=75, end=76, score=0.7397038340568542)]
[TokenSpan(token=13, start=78, end=79, score=0.5646494030952454), TokenSpan(token=1, start=81, end=82, score=0.07793847471475601), TokenSpan(token=8, start=87, end=88, score=0.9740920662879944)]
[TokenSpan(token=17, start=92, end=93, score=0.9077357053756714), TokenSpan(token=9, start=95, end=96, score=0.9911946058273315), TokenSpan(token=5, start=98, end=99, score=0.9639144539833069), TokenSpan(token=7, start=104, end=105, score=0.5597028732299805)]
[TokenSpan(token=15, start=108, end=109, score=0.08412634581327438), TokenSpan(token=5, start=112, end=113, score=0.9327074885368347), TokenSpan(token=12, start=120, end=121, score=0.9227502346038818), TokenSpan(token=3, start=122, end=123, score=0.8997696042060852)]
TokenSpanを現実世界の値に変換する方法
TokenSpanのtokenを文字に変換し、startとendを時刻(秒)に変換するには、例えば、以下のようにします。
def convert_tokenspan(tokenspan):
token_list = bundle.get_labels()
ratio = waveform.size(1) / emission.size(1) / bundle.sample_rate
token_dict = {"token_char": token_list[tokenspan.token],
"start": tokenspan.start * ratio,
"end": tokenspan.end * ratio,
"score": tokenspan.score}
return token_dict
print(token_spans[0][0])
print(convert_tokenspan(token_spans[0][0]))
TokenSpan(token=1, start=11, end=12, score=0.990403413772583)
{'token_char': 'a', 'start': 0.2217741935483871, 'end': 0.24193548387096775, 'score': 0.990403413772583}
日本語のアライメント
JVSコーパスのサンプル sample_jvs001を使ってアライメントを試みます。このコーパスのテキストはCC-BY-SAで提供されており、音声データは個人利用が許可されています。
まず、サンプルファイルjvs001_VOICEACTRESS100_001.wavをダウンロードし、notebookと同じディレクトリに保存します。音声を聞き取り、テキストを書き起こします。その後、テキストをローマ字に変換します。プログラムで自動化することも可能ですが、今回は一つのサンプルなので手動で行いました。
次に、torchaudioを使用してファイルをロードします。frame_offsetやnum_framesは指定せず、全体を読み込みます。
ja_text_raw = "またとうじのようにごだいみょうおうとよばれるしゅようなみょうおうのちゅうおうにはいされることもおおい"
ja_text_normalized = "mata toujino youni godai myououto yobareru shuyouna myououno chuuouni haisareru kotomo ooi"
ja_filepath = "jvs001_VOICEACTRESS100_001.wav"
ja_waveform, ja_sample_rate = torchaudio.load(
ja_filepath
)
サンプルレートを確認します。
assert ja_sample_rate == bundle.sample_rate
{
"name": "AssertionError",
"message": "",
"stack": "---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In[32], line 1
----> 1 assert ja_sample_rate == bundle.sample_rate
AssertionError: "
}
エラーが発生したのは、wavファイルのサンプルレートがbundleの期待するサンプルレートと異なるためです。これを解決するために、waveformをbundleのサンプルレートにリサンプリングします。
import torchaudio.transforms as T
# サンプルレートをbundle.sample_rateと同じにするためのリサンプリング
resampler = T.Resample(orig_freq=ja_sample_rate, new_freq=bundle.sample_rate)
ja_waveform_resampled = resampler(ja_waveform)
リサンプルしたwaveformでアライメントします。
ja_transcript = ja_text_normalized.split()
ja_tokens = tokenizer(ja_transcript)
ja_emission, ja_token_spans = compute_alignments(ja_waveform_resampled, ja_transcript)
ja_num_frames = ja_emission.size(1)
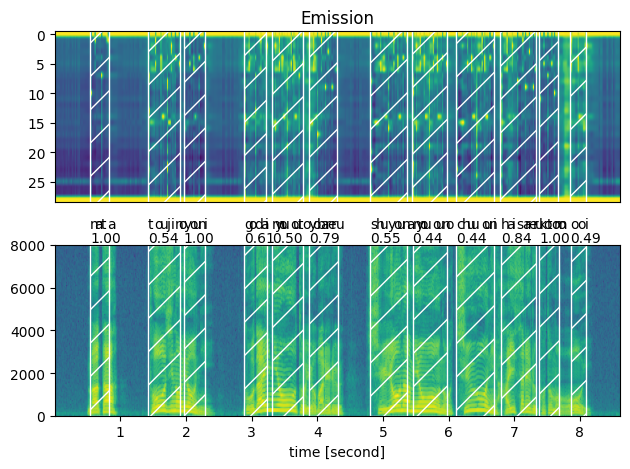
plot_alignments(ja_waveform_resampled, ja_token_spans, ja_emission, ja_transcript)
print("Raw Transcript: ", ja_text_raw)
print("Normalized Transcript: ", ja_text_normalized)
IPython.display.Audio(ja_waveform_resampled, rate=ja_sample_rate)
以下のようなグラフが出力されます。発話部分と思われる波形のうえに網掛けできており、成功してそうです。
spanが正しいか耳で聞いて判断します。preview_word関数を使います。
waveformとsample_rateはリサンプル前のものにします。リサンプル語のものだとピッチが変になります。
preview_word(ja_waveform, ja_token_spans[0], ja_num_frames, ja_transcript, ja_sample_rate)
ja_token_spansのindexを0,1,2,3と聞いてみましたが正しくalignできていそうでした。
おわりに
最近、torchaudioに追加されたforced-align用のAPIを使って、forced-alignmentを行いました。以前試したときよりも、コードがシンプルでわかりやすくなっており、非常に良かったです。torchaudio.pipelines.Wav2Vec2FABundleとtorchaudio.functional.forced_align()の2つのAPIがありますが、前者の中で後者が使用されているため、特に複雑なことをしない限り、前者を使うのが簡単と思われます。
今後、気が向いたら、Wav2VecFABundleでオリジナルの音響モデルとtokenizerを使用する方法についても検討してみたいと思います。
参考サイト
- Forced alignment for multilingual data
- CTC forced alignment API tutorial
- 無償入手可能な音声コーパス/音声データベースの一覧
- JVS (Japanese versatile speech) corpus
- uvだけでPythonプロジェクトを管理する
- How to solve the pytorch RuntimeError: Numpy is not available without upgrading numpy to the latest version because of other dependencies
- uvでPyTorchをインストールする方法の試行
- uvでPyTorchのCPU / CUDAバージョンを環境ごとに管理する