概要
LINEの投稿文字数(など)をカウントするプログラムを書きました。
筆者の過去記事とやろうとしていることは同じですが、以下の改良を加えました。
- 正規表現を使って生データの分割処理を簡潔かつ厳密にした
- ノート作成や動画投稿など過去記事でスルーしていたアクションの回数も取得できるようにした
- グラフ化(可視化)するコードを書いた
方針
LINEのトーク履歴のログはアプリの設定から出力可能です
ログの中身は以下のような感じです。
[LINE] 投稿者2 とのトーク履歴
保存日時:2020/03/19 11:26
2014/10/13(月)
13:47 投稿者1 こんにちは
13:48 投稿者2 [スタンプ]
13:48 投稿者1 "コンドルが!!!!
壁に!!!!
めり込んどる!!!!!"
13:48 メッセージの送信を取り消しました
13:48 投稿者1 [スタンプ]
13:48 投稿者1 [写真]
13:48 投稿者2 [スタンプ]
2014/10/14(火)
23:34 投稿者1 ☎ 通話時間 0:07
23:34 投稿者1 [ノート] 後輩のおすすめ
https://food.com/tokyo/A1234
23:35 投稿者2 ☎ 通話をキャンセルしました
23:34 投稿者2 おやすみ
日付のフォーマットはOSによって変わるようなので注意してください。
上記はiOSで出力したログです。
ログから最終的に投稿ごとの以下の情報を抽出することを目指します。
(key, valueと書いていますが、pandasのDateFrame型に格納する想定です)
| key | value |
|---|---|
| datestr | 日付の未加工の文字列データ |
| timestr | 時刻の未加工の文字列データ |
| name | 投稿者名 |
| content | 投稿文字列 |
| send_type | 投稿の種類 |
| year | 投稿年 |
| month | 投稿月 |
| day | 投稿日 |
| weekday | 投稿曜日 |
| hour | 投稿時 |
| minute | 投稿分 |
| length | contentの字数 |
| param0_key | 0番目の汎用パラメータのkey |
| param0_value | 0番目の汎用パラメータのvalue |
| param1_key | 1番目の汎用パラメータのkey |
| param1_value | 1番目の汎用パラメータのvalue |
補足として、send_typeはスタンプ、写真、アルバム等のvalueが入る想定です。通常のテキスト投稿以外のアクションを区別することが目的です。
ログの構造は例外がありますが、概ね以下のようになっています。
[header]
[header]
[投稿日]
[投稿時刻]\t[投稿者名]\t[投稿文字列]
[投稿時刻]\t[投稿者名]\t[投稿文字列]
[投稿時刻]\t[投稿者名]\t[投稿文字列]
...
[投稿日]
[投稿時刻]\t[投稿者名]\t[投稿文字列]
[投稿時刻]\t[投稿者名]\t[投稿文字列]
[投稿時刻]\t[投稿者名]\t[投稿文字列]
...
そこで大きく以下の方針で処理をします。
- 投稿日と投稿日の間の文字列(Aとする)を、その直前に書かれた投稿日とセットで取得する
- Aのうち、投稿時刻と投稿時刻の間の文字列(Bとする)を、その直前の投稿時刻とセットで取得する
- Bをタブ区切りして0番目の要素を投稿者名として、1番目以降の文字列を投稿内容(Cとする)として取得する
- Cを分析して投稿の種類などを決定する。
コード
データフレーム化
lineのトーク履歴を解析してDateFrameに格納するプログラムを以下に示します。
import re
import os
import pandas as pd
# 日付行で分割
def get_date_content(text):
# 日付行(YYYY/MM/DD(W))で囲まれた領域をその直前の日付行とセットで取得する正規表現
# contentが多くの場合、複数行に渡るので, DOTALLで改行を含む行を検出
re_date = re.compile(r"\n((\d{4})/(\d{2})/(\d{2})\(([月火水木金土日])\))(\n\d{2}:\d{2}\t.+?)(?=\n\d{4}/\d{2}/\d{2}\([月火水木金土日]\)\n\d{2}:\d{2}\t)", re.DOTALL)
# 最初と最後の要素をfindallできるように日付業を末尾で足す
text = "\n{}\n1900/01/01(月)\n00:00\t".format(text)
# 正規表現にマッチする要素を抽出
contents = re_date.findall(text)
logs = []
for datestr, year, month, day, weekday, content in contents:
# 各マッチ要素を辞書に変換
obj = {
"datestr": datestr,
"year": year,
"month": month,
"day": day,
"weekday": weekday,
"content": content
}
logs.append(obj)
return logs
# 時刻で分割
def get_time_content(text):
# 時刻(hh:mm)で囲まれた領域をその直前の時刻とセットで取得する正規表現
# contentが複数行に渡る可能性を考慮し, DOTALLで改行を含む行を検出
re_time = re.compile(r"(?<=\n)((\d{2}):(\d{2}))\t(.+?)(?=\n\d{2}:\d{2}\t)", re.DOTALL)
# 最初と最後の要素をfindallできるように時刻から始まる行を足す
text = "\n{}\n00:00\t".format(text)
# 正規表現にマッチする要素を抽出
contents = re_time.findall(text)
logs = []
for timestr, hour, minute, content in contents:
# 各マッチ要素を辞書に変換
obj = {
"timestr": timestr,
"hour": hour,
"minute": minute,
"content": content
}
logs.append(obj)
return logs
# 時刻に紐づくcontentから名前と投稿文字列を取得
def get_name_and_post(text):
post = text.split("\t")
# postは基本的に要素数が2以上だが、nameに相当する要素がなく、要素数が1のケースがある。
# 要素数が1のケースは原則システムメッセージであるため、
# 要素数が1の場合はシステムメッセージとみなし、投稿者名を"system"とする
if len(post) == 1:
name = "system"
content = post[0] #2つめの要素をcontentとして取得
else: #要素数が2より大きいとき、1つめの要素を投稿者名として取得
name = post[0] if post[0] else "system"
content = "\t".join(post[1:]) # 3つ目以降をcontentとして取得
return {
"name": name,
"content": content
}
# 投稿の種類を決定し、必要な情報と合わせて返す
def parse_post(content):
# urlを抽出する正規表現
re_url = re.compile(r"(https?|ftp)(:\/\/[-_\.!~*\'()a-zA-Z0-9;\/?:\@&=\+$,%#]+)")
# 汎用的なパラメータ用のキーを追加
log = {
"param0_key": "",
"param0_val": "",
"param1_key": "",
"param1_val": ""
}
# send_typeを判定
# ファイル、スタンプ、写真、動画、ボイスメッセージ、連絡先、プレゼントの判定
if re.fullmatch(r"\[(?:ファイル|スタンプ|写真|動画|ボイスメッセージ|連絡先|プレゼント)\]", content):
log["send_type"] = content[1:-1]
# アルバムの判定
elif content == "[アルバム] (null)":
log["send_type"] = "アルバム"
# 位置情報の判定
elif content.startswith("[位置情報]"):
log["send_type"] = "位置情報"
# ノートの判定
elif content.startswith("[ノート] "):
log["send_type"] = "ノート"
# 通話開始の判定
elif re.fullmatch(r"☎ 通話時間 \d+:\d+",content):
phone_time = content.split(" ")[-1].split(":")
phone_sec = int(phone_time[0]) * 60 + int(phone_time[1])
log.update({
"send_type":"phone_start",
"param0_key": "phone_sec",
"param0_val": phone_sec
})
# 通話終了の判定
elif content == "☎ 通話をキャンセルしました":
log.update({
"send_type":"phone_cancel"
})
# 上記のいずれでもないとき、テキスト投稿とみなす
else:
# urlを取得
urls = re_url.findall(content)
log.update({
"send_type":"text",
"param0_key": "url_num", # 投稿に含まれるurlの数
"param0_val": len(urls),
"param1_key": "url_remove_length", # urlをまとめて1文字とみなしたときの投稿の文字数
"param1_val": len(content) + len(urls) - sum([len(url) for url in urls])# urlを1文字としてカウント
})
# 投稿の長さを取得
log["length"] = len(content)
return log
# lineのトーク履歴から各投稿の情報を抽出する
def parse_linelog(textdata):
logs = []
# 日付行の間の文字列を取得
for date_content_info in get_date_content(textdata):
# 文字列と日付情報に分ける
date_content = date_content_info.pop("content")
date_info = {
"year": date_content_info.pop("year"),
"month": date_content_info.pop("month"),
"day": date_content_info.pop("day"),
"weekday": date_content_info.pop("weekday"),
"datestr": date_content_info.pop("datestr")
}
# 日付の間の文字列のうち時刻の間の文字列を取得
for time_content_info in get_time_content(date_content):
# 文字列と時刻情報を分ける
time_content = time_content_info.pop("content")
time_info = {
"hour": time_content_info.pop("hour"),
"minute": time_content_info.pop("minute"),
"timestr": time_content_info.pop("timestr")
}
# 投稿者名と投稿内容を取得
name_and_post_info = get_name_and_post(time_content)
name = name_and_post_info.pop("name")
post = name_and_post_info.pop("content")
# 投稿のsend_typeの情報などを取得
postinfo = parse_post(post)
# 投稿から改行、タブを取り除いた文字列を取得
post_no_tab_and_br = "<br>".join(post.replace("\t", "<tab>").splitlines())
# 日付、時刻、投稿内容の情報をすべて含んだ辞書を作成
log = {}
log.update(date_info)
log.update(time_info)
log.update({
"name": name,
"content": post,
"send_type": postinfo.pop("send_type"),
"length": postinfo.pop("length"),
"content_no_tab_and_br": post_no_tab_and_br,
"param0_key": postinfo.pop("param0_key"),
"param0_val": postinfo.pop("param0_val"),
"param1_key": postinfo.pop("param1_key"),
"param1_val": postinfo.pop("param1_val")
})
logs.append(log)
return logs
PATH = "sample.txt"
textdata = ""
with open(PATH, "r") as f:
textdata = f.read()
# dfに情報として含める列名を定義
header = ["datestr","timestr","name","content_no_tab_and_br","send_type","year","month","day","weekday","hour","minute","length","param0_key","param0_val","param1_key","param1_val"]
# lineのトーク履歴のパース結果を取得
logs = parse_linelog(textdata)
# dfに変換
df = pd.DataFrame({k: [v.get(k,"") for v in logs] for k in header})
# 改行、タブなしの投稿文字列をcontentとして取得
df = df.rename(columns = {"content_no_tab_and_br":"content"})
# 保存
df.to_csv("log.tsv", sep="\t", index=False, header=True)
datestr timestr name content send_type year month day weekday hour minute length param0_key param0_val param1_key param1_val
2014/10/13(月) 13:47 投稿者1 こんにちは text 2014 10 13 月 13 47 5 url_num 0 url_remove_length 5
2014/10/13(月) 13:47 投稿者1 ? text 2014 10 13 月 13 47 1 url_num 0 url_remove_length 1
2014/10/13(月) 13:47 投稿者1 [スタンプ] スタンプ 2014 10 13 月 13 47 6
2014/10/13(月) 13:48 投稿者2 [スタンプ] スタンプ 2014 10 13 月 13 48 6
2014/10/13(月) 13:48 投稿者1 """コンドルが!!!!<br>壁に!!!!<br>めり込んどる!!!!!""" text 2014 10 13 月 13 48 30 url_num 0 url_remove_length 30
2014/10/13(月) 13:48 system メッセージの送信を取り消しました text 2014 10 13 月 13 48 16 url_num 0 url_remove_length 16
2014/10/13(月) 13:48 投稿者1 [スタンプ] スタンプ 2014 10 13 月 13 48 6
2014/10/13(月) 13:48 投稿者1 [写真] 写真 2014 10 13 月 13 48 4
2014/10/13(月) 13:48 投稿者2 [スタンプ] スタンプ 2014 10 13 月 13 48 6
2014/10/14(火) 23:34 投稿者1 ☎ 通話時間 0:07 phone_start 2014 10 14 火 23 34 11 phone_sec 7
2014/10/14(火) 23:34 投稿者1 [ノート] 後輩のおすすめ<br>https://food.com/tokyo/A1234 ノート 2014 10 14 火 23 34 42
2014/10/14(火) 23:35 投稿者2 ☎ 通話をキャンセルしました phone_cancel 2014 10 14 火 23 35 14
2014/10/14(火) 23:34 投稿者2 おやすみ text 2014 10 14 火 23 34 4 url_num 0 url_remove_length 4
概ね上手くいっていそうです。(厳密にはsample.txtだけではテストとして不十分ですが)
実はこのコードでは、テキスト投稿やノートでトーク履歴と紛らわしい入力をされた場合に、間違った分割をする可能性があります。ただ、起こる可能性が(故意でない限りは)低いのと、仮に起こったとしても影響が狭い範囲にとどまるので、妥協しています。
可視化
作成したデータフレームの情報をもとに、送信回数や文字数をグラフ化してみます。
先ほど作成したデータフレームを読み込みます。
import pandas as pd
# データフレームの読み込み
PATH = "log.tsv"
df = pd.read_csv(os.path.join(PATH), sep="\t")
matplotlibでグラフ化します。テキスト投稿の回数を投稿者1と投稿者2(今回は夫婦のトークルームなのでそれぞれ、夫と妻)で比較します。
なおグラフは(見栄えを良くするために)、sample.txtではなく、実データから作っています。
import matplotlib.pyplot as plt
import datetime
import matplotlib.dates as mdates
# year, month, name, send_typeごとの投稿数を取得。カウント対象の行はなんでもよいのでdatestrとしておく
df_summary = df.groupby(["year","month","name","send_type"],as_index=False)["datestr"].count()
# わかりやすさのためdatestr列をcount列に変更
df_summary = df_summary.rename(columns = {"datestr":"count"})
# 横軸ラベルの定義をするため、yearとmonthの情報からなるdateオブジェクトの列を追加
df_summary["date"] = df_summary.apply(lambda x: datetime.date(int(x["year"]),int(x["month"]),1), axis=1)
# df_summaryのうち、send_typeのcount列を折れ線グラフ化
def show_plot(df_summary, send_type
,*
,figsize=(40,5)
,interval=1
,ylabel="count"
, start_date=None
, end_date=None):
# 投稿者名を定義。今回は夫婦のトークなので、wife, husbandという変数名にしている。
wife,husband = "島谷 紫織", "島谷二郎"
# df_summaryのうちsend_typeが与えられたものと一致する行のみ抽出し、name列に関してpivotする
df_summary = df_summary.query("send_type=='{}'".format(send_type)).pivot_table(index="date",columns="name",values="count")
# グラフの描画オブジェクトを取得
fig, ax = plt.subplots(figsize=figsize)
# 夫の折れ線グラフを表示
# 横軸をdate (=df_summaryのindex)とする。
ax.plot(df_summary.index,df_summary[husband],label="husband")
# 妻の折れ線グラフを表示
ax.plot(df_summary.index,df_summary[wife],label="wife")
# 縦軸のタイトルを定義
ax.set_ylabel(ylabel)
# 凡例を表示
plt.legend(loc=2)
# 横軸のラベルを30度回転する
plt.xticks(rotation=30)
# 横軸ラベルの日付フォーマットを指定
Minute_fmt = mdates.DateFormatter('%y/%m') # yy/mmの形式
ax.xaxis.set_major_formatter(Minute_fmt)
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=interval))# 横軸ラベルをintervalの間隔で表示
# 横軸の範囲を指定
start_date = start_date or df_summary.index[0]
end_date = end_date or df_summary.index[-1]
ax.set_xlim([start_date,end_date])
# df_summaryのsend_type=textの投稿回数をグラフ化
show_plot(df_summary, "text", figsize=(14,5),interval=4,ylabel="count"
,start_date=datetime.date(2015,8,1),end_date=datetime.date(2023,3,31)
)
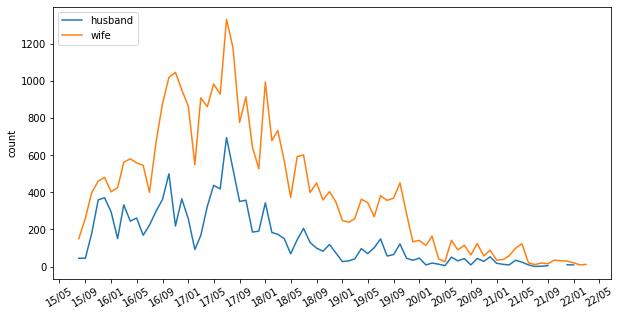
スタンプの投稿回数を可視化したいときは以下です。
show_plot(df_summary, "スタンプ",figsize=(10,5),interval=4)
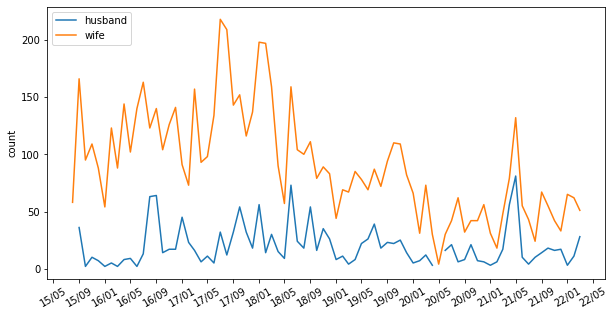
写真(画像)の投稿回数を可視化したいときは以下です。
show_plot(df_summary, "写真",figsize=(10,5),interval=4)
回数ではなく文字数を可視化したいときには、df_summaryのcount列を置き換えます。
# year, month, name, send_typeごとに、param1_valの合計値を取得(send_type=textの場合、param1_valにはurlを除いた文字数が入る)
df_summary = df.groupby(["year","month","name","send_type"],as_index=False)["param1_val"].sum()
# param1_valの列名をcountに変更(関数show_plotがcount列をグラフ化する用に作られているため)
df_summary = df_summary.rename(columns = {"param1_val":"count"})
# yearとmonthの情報からなるdateオブジェクトの列を追加
df_summary["date"] = df_summary.apply(lambda x: datetime.date(int(x["year"]),int(x["month"]),1), axis=1)
# 月および投稿者ごとのparam1_val(send_type=textの場合はurlを除いた文字数)の合計値を折れ線グラフ化
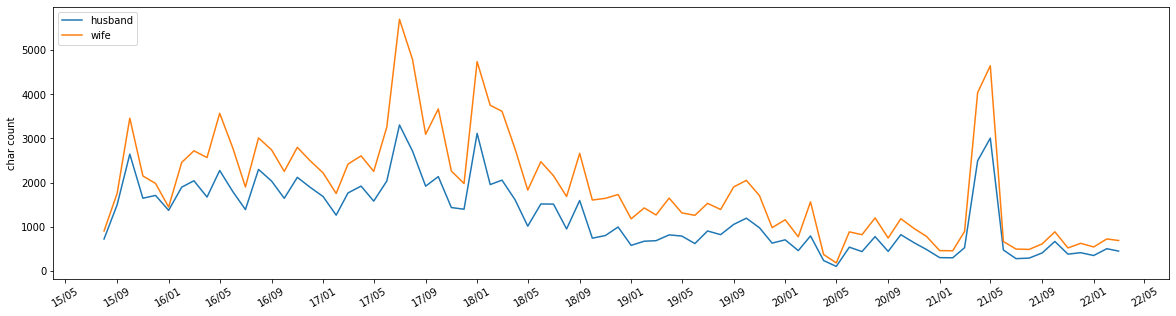
show_plot(df_summary, "text",figsize=(10,5),interval=4,ylabel="char count")
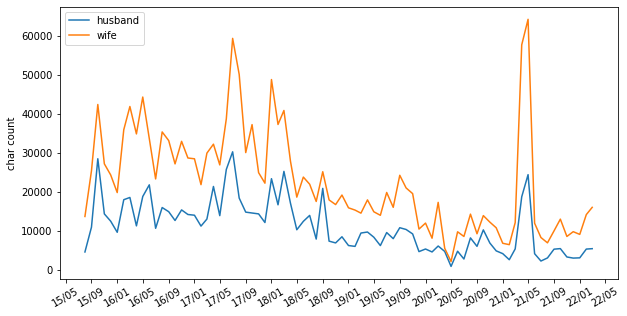
2つのグラフを比較のために縦に並べたくなるかもしれません。
そのときは以下です。
import matplotlib.pyplot as plt
import datetime
import matplotlib.dates as mdates
# 1つ目のグラフ用のdf_summaryを作成
df_summary = df.groupby(["year","month","name","send_type"],as_index=False)["datestr"].count()
df_summary = df_summary.rename(columns = {"datestr":"count"})
df_summary["date"] = df_summary.apply(lambda x: datetime.date(int(x["year"]),int(x["month"]),1), axis=1)
# 2つめのグラフ用のdf_summaryを必要に応じて作成(df_summaryと兼ねられる場合もある)
df_summary2 = df.groupby(["year","month","name","send_type"],as_index=False)["param1_val"].sum()
df_summary2 = df_summary2.rename(columns = {"param1_val":"count"})
df_summary2["date"] = df_summary2.apply(lambda x: datetime.date(int(x["year"]),int(x["month"]),1), axis=1)
# 折れ線グラフを立てに並べて表示
def show_double_plot(df_summary, send_type,df_summary2,send_type2
, *
, figsize=(40,5)
,interval=1
, start_date: datetime.date = None
, end_date: datetime.date = None):
# start_date, end_dateを指定しない場合は、df_summaryの最初と最後の日付を指定
start_date = start_date or df_summary.index[0]
end_date = end_date or df_summary.index[-1]
# グラフの間を開ける
wife,husband = "島谷 紫織", "島谷二郎"
df_summary = df_summary.query("send_type=='{}'".format(send_type)).pivot_table(index="date",columns="name",values="count")
df_summary2 = df_summary2.query("send_type=='{}'".format(send_type2)).pivot_table(index="date",columns="name",values="count")
#df_summary = df_summary[["島谷 紫織", "島谷二郎"]]
# グラフの描画オブジェクトを取得。2行1列のグラフを作成
fig, ax = plt.subplots(2,1,figsize=figsize)
# 上下のグラフが重ならないように間隔を設定
fig.tight_layout()
# 1つ目のグラフにhusbandの値を描画
ax[0].plot(df_summary.index,df_summary[husband],label="husband")
# 1つ目のグラフにwifeの値を描画
ax[0].plot(df_summary.index,df_summary[wife],label="wife")
# 1つ目のグラフの横軸ラベルを設定
Minute_fmt = mdates.DateFormatter('%y/%m')
ax[0].xaxis.set_major_formatter(Minute_fmt)
ax[0].xaxis.set_major_locator(mdates.MonthLocator(interval=interval))
ax[0].legend(loc=2)
ax[0].xaxis.set_tick_params(rotation=30)
# 横軸の範囲を指定
ax[0].set_xlim(start_date,end_date)
# 縦軸グラフの設定(不要な場合はコメントアウト)
#ax[0].set_ylabel("text length")
# 2つ目のグラフにhusbandの値を描画
ax[1].plot(df_summary2.index,df_summary2[husband],label="husband")
# 2つ目のグラフにwifeの値を描画
ax[1].plot(df_summary2.index,df_summary2[wife],label="wife")
# 2つ目のグラフの横軸ラベルを設定
Minute_fmt = mdates.DateFormatter('%y/%m')
ax[1].xaxis.set_major_formatter(Minute_fmt)
ax[1].xaxis.set_major_locator(mdates.MonthLocator(interval=interval))
ax[1].legend(loc=2)
ax[1].xaxis.set_tick_params(rotation=30)
# 横軸の範囲を指定
ax[1].set_xlim([start_date, end_date])
# 縦軸グラフの設定(不要な場合はコメントアウト)
#ax[1].set_ylabel("stamp count")
# テキスト投稿の文字数と写真の投稿数の比較グラフを作成
show_double_plot(df_summary2, "text",df_summary, "写真",figsize=(10,5),interval=4)
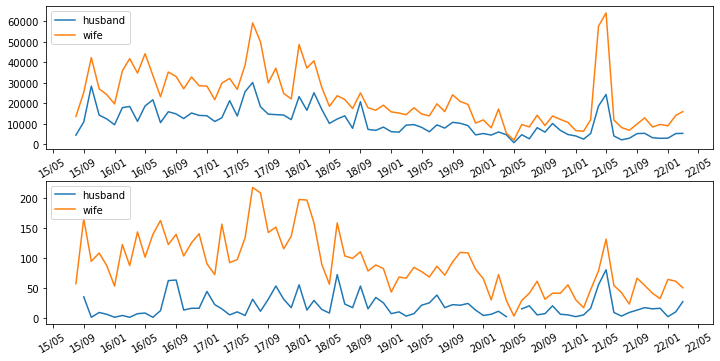
おわりに
LINEのトーク履歴を解析して可視化する方法について記載しました。
Tipsや実装意図はなるべくコード中のコメントとして残していますが、コードに現れていない試行錯誤もあったので、機会があれば追記か別記事で補足したいと思います。