autokerasは雑に言うとディープラーニングの自動化ライブラリです。今回はそれを使って特徴量抽出器を作ります。
ソースコード
autokerasそのままではうまくいかず、ソースコードを書き換えてmyautokerasとしてインストールしました。
https://github.com/shiibashi/myautokeras
変更したのはここ↓
https://github.com/shiibashi/myautokeras/commit/4d4d9d9fff58f2f1c88f16d4972b61f46250dcb6
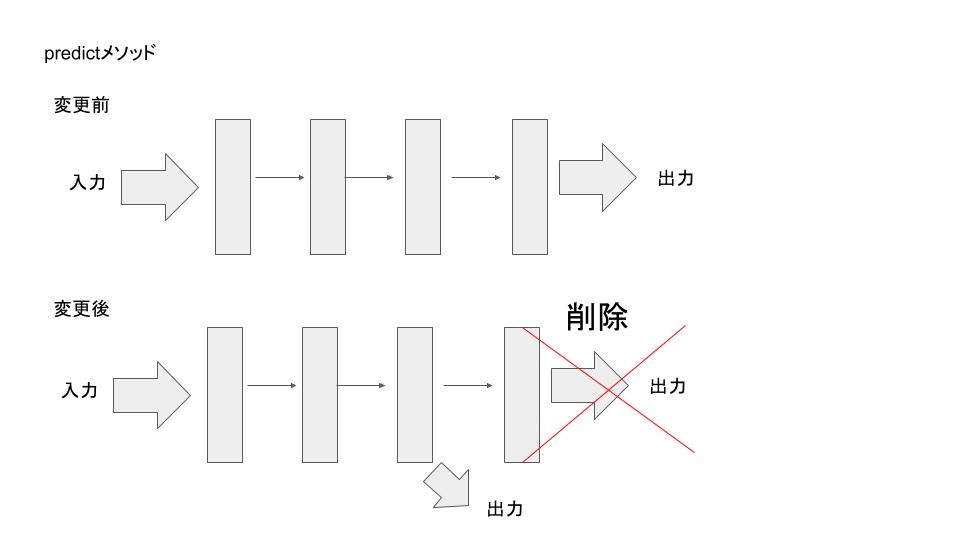
変更イメージはこんな感じ↓
途中まで計算した結果を出力するように書き換えました。
autokeras↑を使って特徴量抽出器を作るまでのスクリプトはここ↓
https://github.com/shiibashi/qiita/blob/master/7/autokeras_2vec.ipynb
以下はこのソースコードについて補足的な説明を書いていきます。
pythonのバージョンは3.6.7
データ
数字の0と1の手書き画像を用意しました。0か1かに分類するタスクを学習し、分類の特徴ベクトルを抽出します。
学習
前回の記事にまとめました。
超簡単なautokerasの使い方
https://qiita.com/shiibass/items/28ffcaa9aec2799d5691
学習後
学習したモデルをそのまま使うのならこんな風にpredictで0か1かの予測を行います。
model.predict(test_X[0:3]) # array([0, 0, 0])
今回は特徴ベクトルを抽出したいのでまだ続きます。まず学習したモデルを保存しておきます。
# save
path = "model.hdf5"
model.export_autokeras_model(path)
モデルのロード
学習したモデルを読み込みます。保存してすぐ読み込んでいて不自然ですが、学習バッチと予測バッチを切り離して運用することを想定しています。
output_model = autokeras.utils.pickle_from_file(path)
predict
内部ではニューラルネットワークの計算結果がリストに保存されているのでその何番目の結果を取り出すかという引数を追加しました。output_index=-1(リストの最後の要素)もしくは、引数を与えなければ従来通りの0か1かの予測ラベルを返します。最後から一つ前ならoutput_index=-2とします。
vec_train_X = output_model.predict(train_X, output_index=-2)
vec_test_X = output_model.predict(test_X, output_index=-2)
確かめるために特徴ベクトルを出力してみます。
pandas.DataFrame(vec_train_X).head(2)
512次元のベクトルが得られたようです。あえて日本語で解釈をするとすれば、0か1を分類するために必要な512要素ということになります。

512次元が特徴抽出器として機能するかどうか確認
一応以下のコードで高い精度が出ますので特徴抽出器として多少は使えそうな気がしますね。これでautokerasを使って特徴ベクトルを得られました。これをベースにすれば〇〇2vecを簡単に生産できそうです。
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(solver="lbfgs")
lr.fit(vec_test_X, test_Y)
lr.score(vec_test_X, test_Y) # 0.9978378378378379
特徴ベクトルを得られたけどどう使うのか
そもそもなぜこんなことをする必要があるのかという話になります。〇〇2vecはベクトル空間にマッピングしているので、例えば類似データの検索に使えそうで、近似近傍探索のようなワードで調べればレコメンドエンジンを作れますね。あとはデータ分析時の特徴量として使うこともできそうです。画像や音声、テキストなどの厄介なデータ構造に対して使いにくい手法(ロジスティック回帰とか)もベクトルに変換できれば分析しやすくなります。