近年の株や為替の取引でアルゴリズムトレードを導入するプレイヤーが多くなってきました。有料ツールで誰でもアルゴリズムトレードをすることはできるのですがそう簡単に勝つことはできませんし、プログラミングや数学、機械学習、データ分析などのエンジニアスキルを学ぶ必要がなくなります。
自動売買を実装する上でどんなデータを取得するか、蓄積するか、どんなアルゴリズムを組むか、どんな銘柄を攻めるかなどの全体設計が非常に大事になります。特にデータの選び方は一般的に知られているデータだと他社のアルゴリズムでも学習している情報の可能性もありますし、個人投資家でも当然理解している指標の可能性もありますので、蓄積・学習しても勝てないということはよくあります。
今回は個人投資家がなかなか取得できない日中の板の動きをログとして蓄積する方法を紹介します。
板とは
これがHYPER SBIで閲覧できる板になります。エムスリーの取引の様子です。

HYPER SBIにはこのような録画機能はついておらず、この録画はPythonライブラリpillowのImageGrab
(https://pillow.readthedocs.io/en/3.0.x/reference/ImageGrab.html)
を使って自作しました。ソースコードはこちらにあります。
https://github.com/shiibashi/board_monitor/blob/master/script/prod_1_with_predictor.py
特に難しい処理をしているわけでなくImageGrabのドキュメントを読めば簡単にこの状態にできるはずです。5倍速で録画しているのは私が日中の動きを振り返るときに1倍だと時間がかかるためで、それ以外の意味はありません。
この板の数字の動きは他社アルゴリズムや自分以外の人間が注文を出していることによって生じているもので、いつ買うべきかいつ売るべきかをアルゴリズムで判断するのが私の研究テーマになります。研究のためにこれらのデータを解析できるように変換を試みます。
OCR
板の情報を読み取るためにOCR技術を利用します。はじめgoogle cloudのocr apiを検討しましたが、100%の精度が出なかったため自作しました。機械学習に100%の精度を求めるというのは強欲ですが、本番運用では読み取った数字の変化をもとに自動売買を行うため誤認識による売買が行われると勝率を下げかねないということで100%の精度を実現する必要があります。
教師データ作成
VGG Image Annotator
(http://www.robots.ox.ac.uk/~vgg/software/via/)
を使いました。これはhtmlで開くだけでアノテーションできるため使いやすいツールです。MNISTの問題設定に落とし込むのをイメージして以下のようにすべての数字をアノテーションしていきました。

アノテーションした結果のデータセットは以下に保存していますので誰でも利用できます。
https://github.com/shiibashi/board_ocr/tree/master/annotation_data
画像を切り出して分割して保存
アノテーションした矩形から画像の切り出しを行って、以下のように数字の書かれた画像に分割して保存します。

ここまでいけばMNISTのチュートリアルと同じ問題設定になりましたので今更説明をする必要はないでしょう。
学習
MNISTと違って手書き文字ではないため学習するのは簡単です。実装方法に工夫はないため省略します。ソースコードはこちらです。(https://github.com/shiibashi/board_ocr/blob/master/train.py)
学習結果
画像枚数3537枚400epochでこうなりました。
Epoch 400/400
loss: 4.5010e-04 - accuracy: 1.0000 - val_loss: 0.0195 - val_accuracy: 0.9958
Using TensorFlow backend.
0.9957865168539326
100%に近い精度が出ました。過学習ではなくデジタルな数字のためちゃんと学習されればこのくらい出て当然です。誤認識があるのは気になりますが、本記事ではこれでいいものとします。
学習済みモデルは以下にありますのでどなたでも再利用できます。
https://github.com/shiibashi/board_monitor/blob/master/script/model/model.hdf5
動画にOCRを使ってデータを抽出する
gifで張り付けた画像の各フレームごとに、先ほどのOCRモデルで推論をかけていきます。一般的なOCRとは違い、読み取りたい場所は常に同じ場所であるため、推論時間を短縮できるし、学習時の精度くらいの精度で抽出ができます。今回は以下の画像で赤で囲った3か所の数字を読み取ってみます。
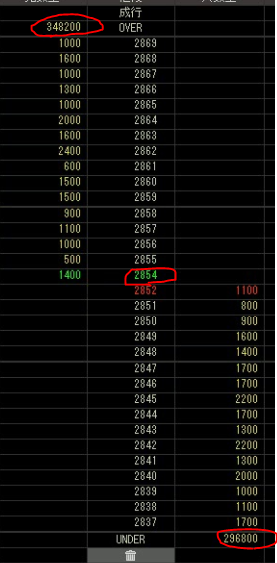
ソースコードを抜粋すると以下のように実装しました。(全体はhttps://github.com/shiibashi/board_monitor/blob/master/script/mp4_to_csv.py
)
opencvで録画した動画を1枚ずつ読み込んで機械学習モデルに画像を入れて予測結果を返しています。
ocr = predict.OCR("model/model.hdf5")
data_list = []
mp4_filepath = "video_2020-03-30_small.mp4"
cap = cv2.VideoCapture(mp4_filepath)
digit = len(str(int(cap.get(cv2.CAP_PROP_FRAME_COUNT))))
before_frame = None
n = 0
while True:
n += 1
ret, frame = cap.read()
if ret:
png = Image.fromarray(frame)
over_value, under_value, upper_price_value = ocr.predict(png)
data = [n, over_value, under_value, upper_price_value]
data_list.append(data)
else:
break
df = pandas.DataFrame(data_list, columns=["time", "over", "under", "upper_price"])
df.to_csv("log.csv", index=False)
出力されるlog.csvが抽出データで、以下のようにしっかりover/underと成り買いする場合の株価を取得できました。
time,over,under,upper_price
1,222300,128600,2925
2,222300,128600,2925
3,222300,128600,2925
4,222300,128600,2925
・・・・
34,222300,128600,2925
35,222300,128600,2925
36,222300,128600,2925
37,222700,127900,2924
38,222700,127900,2924
39,222700,127900,2924
本番運用時はmp4に出力してからOCRをかけるのではなく、録画時にOCRを動かしデータを取得し、売買判断のアルゴリズムで買い売りの判定をするプログラムも走らせます。
まとめ
今回作ったソースコードは以下になります。
https://github.com/shiibashi/board_monitor
https://github.com/shiibashi/board_ocr
board_monitorでは板を録画しますが、録画する位置は実行するPCによって座標が異なりますのでそのままクローンしても使えない可能性があります。本記事は事例の紹介が主でソースコードは参考程度に考えておいてください。
自動売買の研究をしているとデータの取得から考えさせられて、なんでもかんでも機械学習という選択肢ではなくドメイン知識を集めることの重要性、地道なデータ分析による知見獲得、システムを動かすための最低限のインフラ構築など、さまざまなスキルを要するためスキルアップするのもいいことだと思います。また、目的が定まっているため継続して勉強していけます。興味のある方はぜひチャンレジしていただきたいです。