0. 動機
オンライン講義をはじめ、大学教育業務にもデジタル化の流れが急速にきており、ICTを利活用した教育スキルが大学教員に必須となる時代の到来を予感させる。
そこで、Google classroom上で学生から提出されたレポートを自然言語処理にかけて、類似性の高いレポート(コピペに近いレポート)を少ない労力で抽出できるか検討しようと考えた。
しかし、後先考えずにclassroom上で公開したレポート提出様式をgoogleドキュメントファイル(.gdoc)で配布したので、gdocファイルからplain textを抽出しなくてはいけない。
ワードファイルであれば、python-docxで簡単にテキスト抽出が出来るようだが、gdocファイルからpythonへ一発でテキスト抽出出来る方法を見つけることが出来なかった(もしご存知の方は教えて下さい!)。
なお、提出課題のgdocファイルは、学生が一時保存したファイルを含めて設問ごとに同一フォルダに保存される仕様になっているようだ。
2020/5/31 追記
レポートを学生に返却すると提出ファイルの編集ができるようなので、返却前にテキスト抽出を行うべきかもしれない。
1. 目的
本稿では、GoogleAppsScript (GAS)を使ってgoogle drive上にある特定のフォルダにある全てのgdocファイルからplain textを抽出するための作業記録を記す。
具体的には、全てのgdocファイルから、学籍番号と本文を抽出し、2列のcsvファイルとして保存するスクリプトを作成した過程を記載する。
2. テストファイル準備・説明
特定フォルダのID取得
ブラウザでGoogleドライブ上のフォルダを開いた際、アドレスバーは以下のような表示となっている。
https://drive.google.com/drive/folders/*****ID*****
folders/以下の長い英数字羅列がそのフォルダに対応するIDである。
フォルダ内のテストファイル
今回テストするフォルダには、2つのgdocファイルを用意した。レポート形式は1行目にタイトル、2行目に学籍番号と氏名、本文開始は4行目としている。
* レポートテスト.gdoc(のスクリーンショット)
 |
|---|
* レポートテスト2.gdoc(のスクリーンショット)
 |
|---|
3. 新規GASファイル作成
ブラウザでGoogleドライブを開き、新規作成->その他->Google Apps Scriptとする。
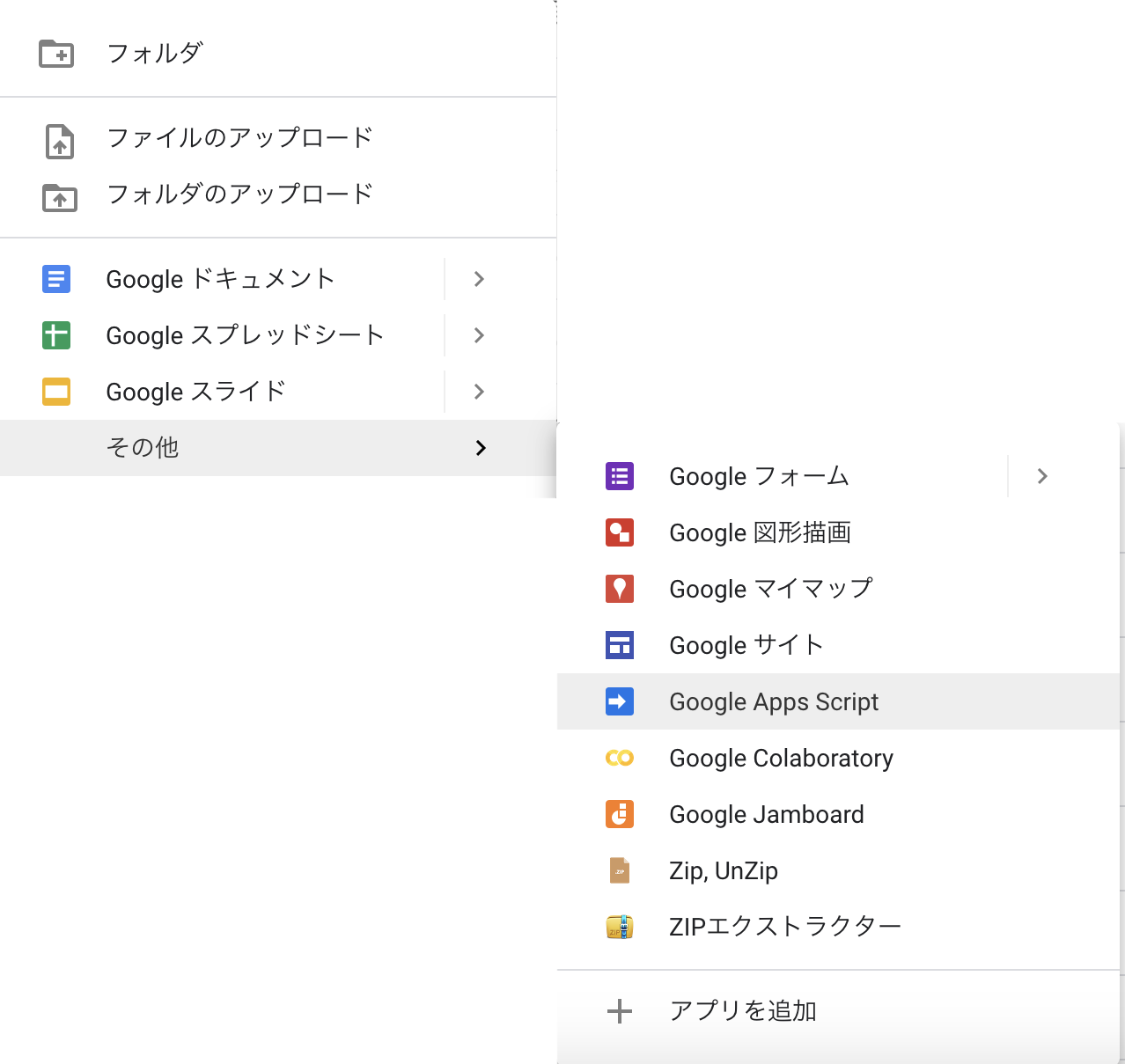 |
|---|
今回作成したコードは以下の通り。
const FOLDER_ID = '*****ID*****'
var outFileName = "Report_from_gdoc.csv"
var contentType = "text/csv";
var charset = 'utf-8';
function myFunction() {
// 指定IDのフォルダ
const folder = DriveApp.getFolderById(FOLDER_ID);
// フォルダ内のgdocファイルを全て取得
var files_gdoc = folder.getFilesByType(MimeType.GOOGLE_DOCS);
// plain textを格納するファイルを作成
// csv出力なのでカンマ区切りと改行コードを入れておく
var list = '学籍番号,本文\n';
while (files_gdoc.hasNext()) {
// ファイルを一つずつID取得->開く
var file = files_gdoc.next();
var gdoc_ID = file.getId();
var docFile = DocumentApp.openById(gdoc_ID);
// 本文取得して改行位置で分割
var txtSplit = docFile.getBody().getText().split('\n');
// 学籍番号は2行目の連続数字
var number = txtSplit[1].match(/\d+/);
if (number != null){
var stuNumber = number[0]
} else {
var stuNumber = "" //null処理
}
// レポート本文は4行目から。今回は参考文献まで抽出
// 出力csv内で改行されないように改行コードをエスケープしておく
var txtMainRef = txtSplit.slice(3).join("\\n");
// 学籍番号と本文を結合し、listに加える
var setROW = stuNumber + "," + txtMainRef + "\n"
list += setROW;
Logger.log(file.getName() + 'の取り込み完了');
}
// Blob を作成する
var blob = Utilities.newBlob("", contentType, outFileName)
.setDataFromString(list, charset);
// ファイルに保存
folder.createFile(blob);
}
4. 実行
画面左上の実行ボタンをクリック。
⌘+Enterでログ確認。
 |
|---|
指定フォルダにReport_from_gdoc.csvが作成される。

5. 終わりに
テストの結果、本文中に半角カンマが使われているとcsv出力時に別の列とみなされてしまうことに気づく。
実用の際は、カンマをエスケープするか、タブ区切りテキストにすることを検討する。
将来的には抽出した文章の類似度をDoc2Vecで見てみたいと思います。