はじめまして。
マインドツリーを使って自問自答することで考えを深めたり、周囲の人に質問してもらうことで答えのない問いを問いていくサービスQ&Qを作っているあどにゃーです。
#ショートサマリ
今回は、Vue.js+CloudFunctionsでOGP対応したら
・TwitterやSlackには任意の動的画像を表示することができるようになった(OK)
・Googleクローラは真っ白で何も読み込まなくなった(NG)
ので対策したよという内容です。

#前知識
SPA(Single Page Application)のVue.jsでは、各ページのOGP(Open Graph Protocol)を動的に返せない問題があります。理由は、botがjavascriptを解釈しないからです。でも、TwitterやSlackにリンクを貼る時に全部同じOGP画像というのはイケてない。。
この解決策としては、
・SSR(サーバサイドレンダリング) → 開発量が大きく腰が思い![]()
・Pre-rendering → 動的ページがたくさんある場合向いてない![]()
・CloudFunctions → 一番手軽にOGP生成できる![]()
があると思います。簡単なCloudFunctionsで解決したい!
そこで、ゆきさんの『SNS映えするWebアプリを...!FirebaseとVue.jsでSPAのOGP画像の動的生成をやってみたら案外楽だった』を参考に、CloudFunction+Vue.jsでOGPを生成しました。丁寧な神解説で非常に助かりました。
簡単に処理の流れを書くとこんな感じです。
- 動的にOGPを生成したいPathでcloud functionsを発動
- BotはJavaScriptを理解できずfunctionsで生成したhtmlを読み取って終了
- UserはJavaScriptを理解するのでリダイレクトされた本来のhtmlに飛んで通常のコンポーネントがマウントされて終了
#Google検索が壊滅...
OGP対策してめでたしめでたし![]() だったのですが、Googleからの検索が一切なくなっている。。おかしいなと思って、varidationサイトで検証してみるとGoogleはなんと真っ白。。。松崎しげるの歯より白い。一方で、Twitterの検索ではOGPも生成されており、metaデータも正しく読み込めています。一体何が起きているのでしょうか。
だったのですが、Googleからの検索が一切なくなっている。。おかしいなと思って、varidationサイトで検証してみるとGoogleはなんと真っ白。。。松崎しげるの歯より白い。一方で、Twitterの検索ではOGPも生成されており、metaデータも正しく読み込めています。一体何が起きているのでしょうか。
元TreeのURL
https://qnqtree.com/tree/iLNP7RAY2KpLNlGFiSQE
Googleの検証用URL
https://search.google.com/test/mobile-friendly
Twitterの検証用URL
https://cards-dev.twitter.com/validator
#何が起こっている?
Vue.jsでCloud Functionsを使ってOGPを動的に生成したのは、BotがJS(javascript)を解釈できないからでした。
一方でGoogleの検索クローラはJSを解釈します。解釈するため、リダイレクト先に飛び、ロードされたVue本来のindex.htmlを読み取りに来ます。
しかし、Vue側でFirestoreからデータを取得してコンポーネントを更新している場合、検索クローラはその処理を待ってくれません。結果的に、クローラはFirestoreからデータを取得する前の真っ白な画面を取得して帰っていきます![]() 。。。
。。。
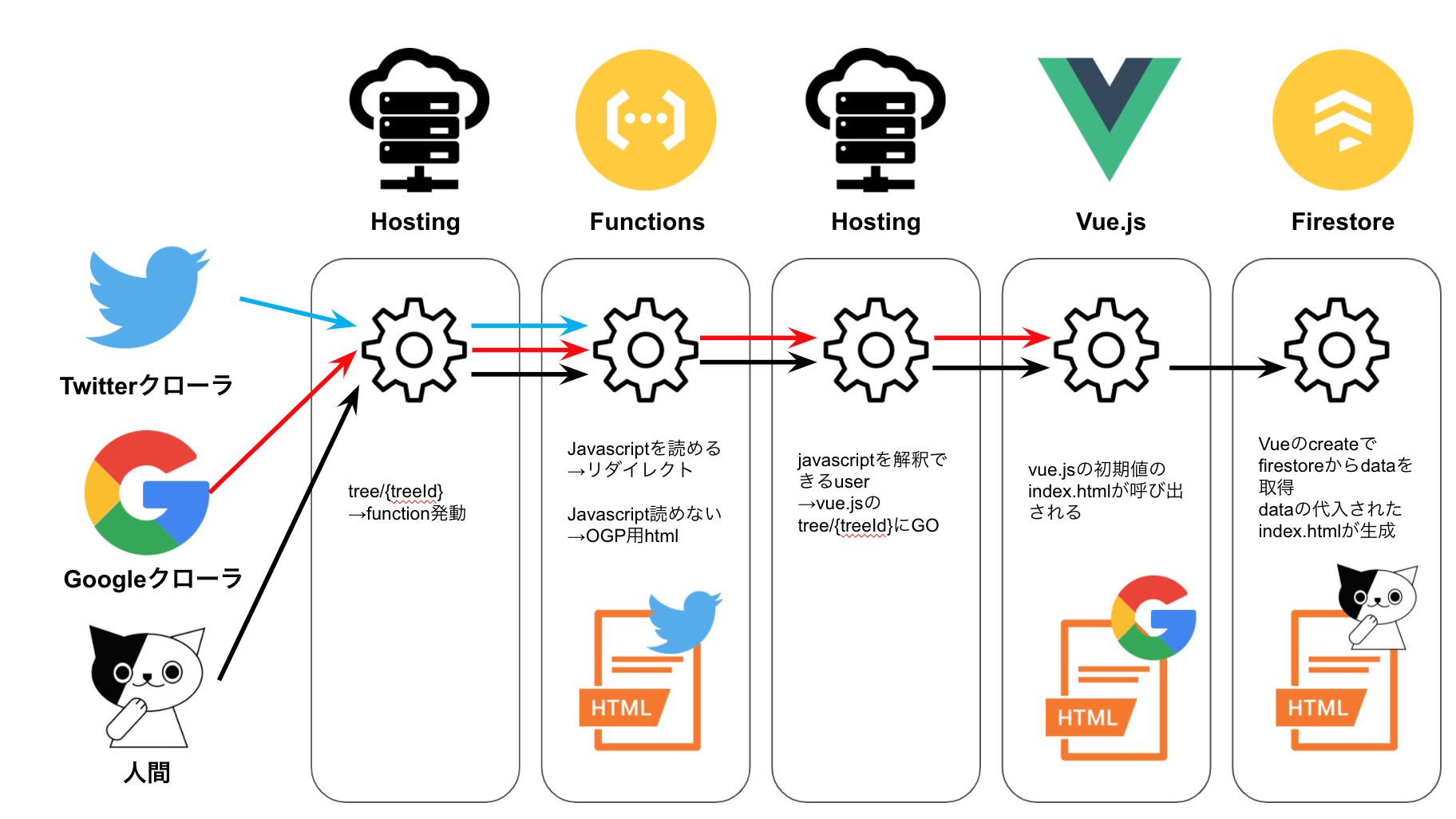
流れを書くと下記になります。
- 動的にOGPを生成したいPathでcloud functionsを発動
- JSを理解できないBOTはfunctionsで生成したhtmlを読み取って終了(Twitter Bot)
- JSを理解できるBOTはリダイレクト先まで飛ぶが、firestoreからのデータ取得を待たずに終了(Google Bot)
- JSを理解できるUserは、firestoreからデータ取得後の更新されたhtmlを取得して終了(Browser)
#回避策
JSを中途半端に解釈するBOTと解釈しないBOTの存在が混乱の元なので、BOTの登録をして、BOTの場合は明示的にリダイレクトしないように変更します。存在するBOT全部を登録できるわけではないので漏れが発生しますが、暫定的な対策としてはワークすると思います。
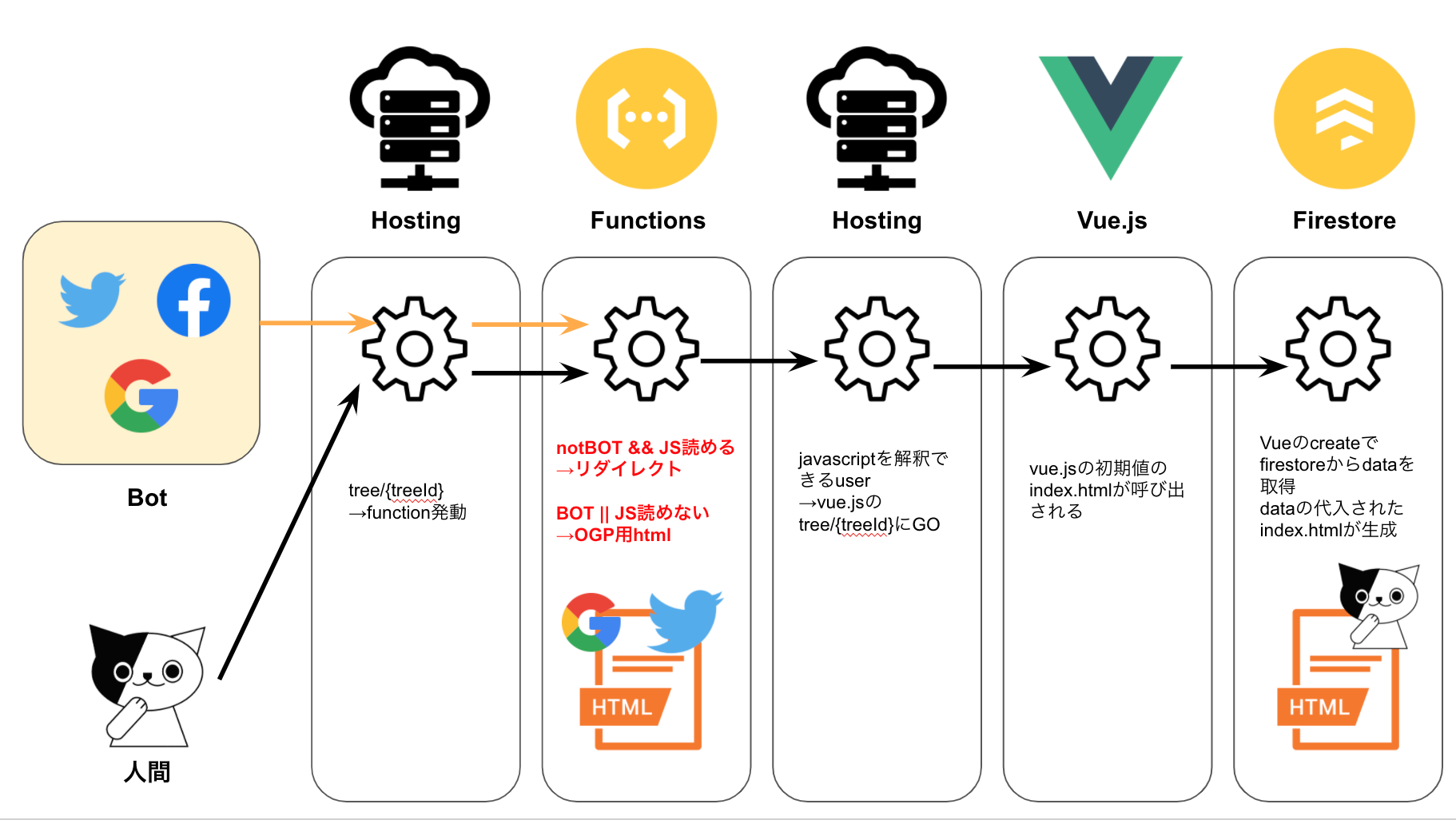
コードはこんな感じで、Botを明示的に記述しています。
exports.ogp = functions.https.onRequest(async (req, res) => {
// botの判定
const userAgent = req.headers['user-agent'].toLowerCase()
const isBot = userAgent.includes('googlebot') ||
userAgent.includes('yahoou') ||
userAgent.includes('bingbot') ||
userAgent.includes('baiduspider') ||
userAgent.includes('yandex') ||
userAgent.includes('yeti') ||
userAgent.includes('yodaobot') ||
userAgent.includes('gigabot') ||
userAgent.includes('ia_archiver') ||
userAgent.includes('facebookexternalhit') ||
userAgent.includes('twitterbot') ||
userAgent.includes('developers.google.com') ? true : false
// Botならリダイレクトしない, Botじゃなければリダイレクト
if (isBot) {
res.status(200).send(
`<!doctype html>
<head>
// 更新するmeta dataを記述
</head>
<body>
// リダイレクトしない
<header>${TITLE}</header>
<main>${DESCRIPTION}</main>
</body>
</html>`
)
} else {
`<!doctype html>
<head>
// 更新するmeta dataを記述
</head>
<body>
<script>
// クローラーにはメタタグを解釈させて、人間は任意のページに飛ばす
location.href = '${SITEURL}/_tree/${treeId}'
</script>
</body>
</html>`
}
###注意
動的pathの先のdataにユーザ権限がある場合は注意が必要です。例えば、筆者のサービスの場合、tree/{treeId}は各ユーザの設定で非公開と公開のデータがあります。 cloud functionsは管理者権限で実行するため、非公開のデータもOGPやmeta用のデータを取得しようとします。
このように権限がある場合は、dataが非公開か、公開かを判定して、cloud functionsでhtmlを更新するかどうかの判断ロジックも追加が必要です。
#まとめ
BOTを判定してリダイレクトしないようにしたので、Googleのクローラも内容を読み込むことができるようになりました![]() 。下図を参照ください。これで検索クローラも各Treeの内容が読み込めるようになったので、SEO的にもまったく検索に引っかからないということはなくなったと思います。
。下図を参照ください。これで検索クローラも各Treeの内容が読み込めるようになったので、SEO的にもまったく検索に引っかからないということはなくなったと思います。

しばらくこれでQnQにGoogle検索から流れてくる人がいるか様子を見てみます。
###ちょろっとQnQの紹介
ちなみにQnQはふと感じた疑問や感情を深堀りするサービスです。なぜこの映画を面白いとおもうのか、なぜこの料理が嫌いなのか、といったことを考えることで自分の価値観に気づいて脱マニュアル人間化することを目的にしています。興味があったら使ってみてください![]()
https://qnqtree.com/about
#おわりに
最終的にはSSR(Server Side Rendering)をするのが王道かと思いますが開発がヘビーなので暫定でcloud functionsで対策をしました。
もっと良い解決策がありましたらコメントいただけると幸いです。
ご拝読ありがとうございました。