馬券を当てたかった
毎週500円ほど重賞レースに賭けているのですが、負けが続いたので予想アプリでも作ってみるかとなった。
まずは情報が必要だ
ということでJRAのサイトに下記のようなレース結果が載っているので、このデータをスクレイピングしてみました。
https://www.jra.go.jp/datafile/seiseki/replay/2021/001.html
2020年から現在までの重賞レース結果をcsvに出力します。
Rubyのバージョンは2.7.1
ソース
main.rb
require 'bundler/setup'
require 'nokogiri'
require 'open-uri'
require 'csv'
require 'pry'
require './create_url.rb'
INDEX_YEAR = [2020, 2021] # データを取得したい年
CSV_HEADER = ['日時', 'レース名', 'グレード', '着順', '馬名', '年齢', '騎手', '調教師']
def setup_doc(url)
doc = Nokogiri::HTML.parse(URI.open(url, "r:CP932").read)
doc.search('br').each { |n| n.replace("\n") }
doc
end
def scrape_data(data)
horse_data = []
# 着順
horse_data << data.children[1].text
# 馬名
horse_data << data.children[7].text
# 年齢
horse_data << data.children[9].text
# 騎手
horse_data << data.children[13].text
# 調教師
horse_data << data.children[25].text
horse_data.map(&:strip)
end
def race_info(doc)
race_info = []
# 日時
race_info << doc.xpath("//div[@class='cell date']").text.split('(').first
# レース名
race_info << doc.xpath("//span[@class='race_name']").text
# グレード
race_info << doc.xpath("//span[@class='grade_icon lg']").first.children.attribute('alt').value
race_info.map(&:strip)
end
if __FILE__ == $0
index_url_list = index_urls(INDEX_YEAR)
urls = index_url_list.map do |index_url|
index_doc = setup_doc(index_url)
create_result_urls(index_doc)
end.flatten
CSV.open('../result.csv', 'w') do |csv|
csv << CSV_HEADER
urls.each do |url|
begin
doc = setup_doc(url)
race_info_columns = race_info(doc)
table_data = doc.xpath("id('race_result')/div[@class='race_result_unit']/table[@class='basic narrow-xy striped']/tbody[1]/tr")
table_data.each do |data|
csv << race_info_columns + scrape_data(data)
end
rescue => e
p e
end
end
end
end
create_url.rb
require 'active_support/all'
# 結果ページURLの配列を生成
def create_result_urls(doc)
table_data = doc.xpath("id('contentsBody')/div[@class='scr-md']/table[@class='basic narrow-xy striped mt20']/tbody[@class='td_left']/tr")
urls = table_data.map do |data|
result_path = data&.children[15]&.children[0]&.values&.first
"https://www.jra.go.jp/#{result_path}" if result_path.present?
end
urls.compact
end
# 年から重賞ページURLの配列を生成
def index_urls(years = [])
urls = years&.map do |year|
"https://www.jra.go.jp/datafile/seiseki/replay/#{year}/jyusyo.html"
end
urls
end
Gemfile
pry-byebugはデバッグ用です。
activesupportはcreate_url.rbでpresent?を使いたかったので追加しました。
gem 'nokogiri'
gem 'pry-byebug', '~> 3.9'
gem 'activesupport'
main.rb解説
定数
INDEX_YEAR = [2020, 2021] # データを取得したい年
CSV_HEADER = ['日時', 'レース名', 'グレード', '着順', '馬名', '年齢', '騎手', '調教師']
INDEX_YEARの配列に取得したいデータの年を入れます。
例えば2019を追加すれば、3年分のデータが取得できるようになります。
CSV_HEADERはまんま、ヘッダーです。とりあえずこの項目を取得することにしました。
馬体重やタイムなど欲しい情報が増えてきたら追加しようかなと思います。
パース
def setup_doc(url)
doc = Nokogiri::HTML.parse(URI.open(url, "r:CP932").read)
doc.search('br').each { |n| n.replace("\n") }
doc
end
HTMLをパースしている箇所です。
open(url, "r:CP932")とするとwarningが出るため、URI.open()としています。
またそのままだと日本語が文字化けしてしまうのですが、r:CP932をセットすることで解決しました。
データ取得
def scrape_data(data)
horse_data = []
# 着順
horse_data << data.children[1].text
# 馬名
horse_data << data.children[7].text
# 年齢
horse_data << data.children[9].text
# 騎手
horse_data << data.children[13].text
# 調教師
horse_data << data.children[25].text
horse_data.map(&:strip)
end
def race_info(doc)
race_info = []
# 日時
race_info << doc.xpath("//div[@class='cell date']").text.split('(').first
# レース名
race_info << doc.xpath("//span[@class='race_name']").text
# グレード
race_info << doc.xpath("//span[@class='grade_icon lg']").first.children.attribute('alt').value
race_info.map(&:strip)
end
scrape_dataではそのレースの馬の情報を配列にして返します。
race_infoはそのレースの情報を配列にして返します。
また最後のmap(&:strip)で不要な改行や空白をまとめて削除しています。
実行箇所
if __FILE__ == $0
index_url_list = index_urls(INDEX_YEAR)
urls = index_url_list.map do |index_url|
index_doc = setup_doc(index_url)
create_result_urls(index_doc)
end.flatten
CSV.open('../result.csv', 'w') do |csv|
csv << CSV_HEADER
urls.each do |url|
begin
doc = setup_doc(url)
race_info_columns = race_info(doc)
table_data = doc.xpath("id('race_result')/div[@class='race_result_unit']/table[@class='basic narrow-xy striped']/tbody[1]/tr")
table_data.each do |data|
csv << race_info_columns + scrape_data(data)
end
rescue => e
p e
end
end
end
end
まずindex_urlsメソッドでデータが欲しい年のレース結果一覧URLの配列を取得します。
続いてそれをmapし、create_result_urlsメソッドで各レース結果のURLを取得します。
この辺はcreate_url.rbに定義しているものです。
結果ページURLの準備ができたらCSVに書き込みます。
まずはcsv << CSV_HEADERで項目を入れ、結果ページURLを回してレース情報と馬情報を書き込みます。
途中、変数table_dataがありますが、中身はパースされたテーブルのhtmlです。
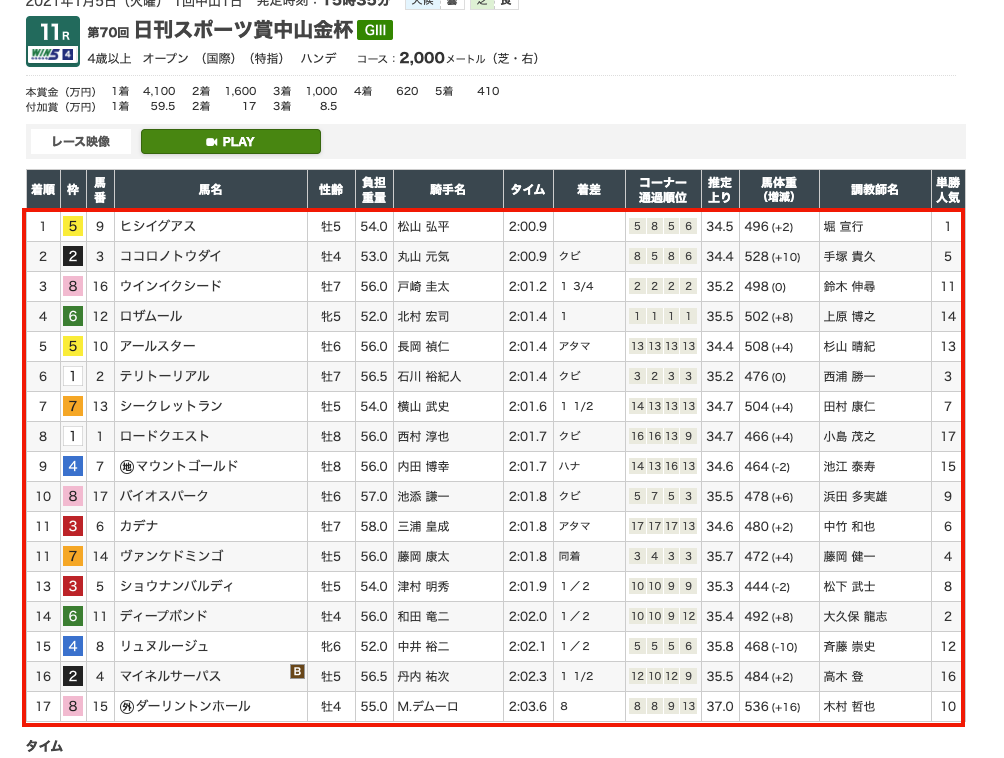
これをeachで回して各行の情報を取得しています。
実行
ターミナルにて
$ ruby main.rb
ターンッ
結果
2020~2021年現在までの重賞レースのデータを抽出することに成功しました🎉
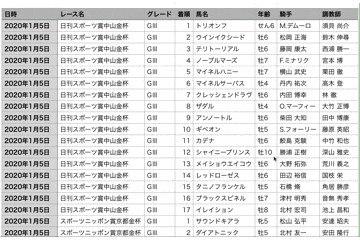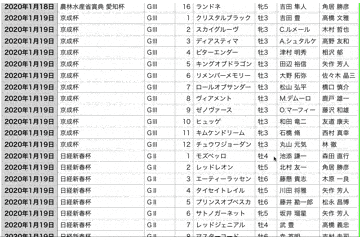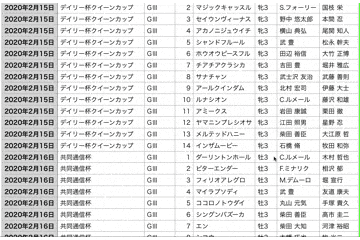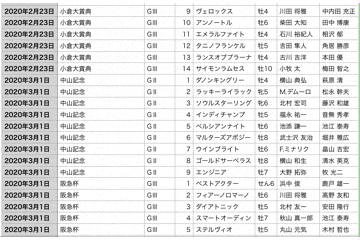
あとがき
人生初スクレイピングでしたがとても楽しかったです。
思い通りに出力できた時はおーすげーとなりました。
あとはこのデータを駆使するのみ。
勝ちたい。以上です。