最近、マルチコアでの性能向上についてよく考えている。フューチャーアーキテクト(裏)アドベントカレンダーです。
マルチコアの性能向上の基本
マルチスレッドの性能向上というと、アムダールの法則というのが有名で、なにかと引用される。僕の本の「Goならわかるシステムプログラミング」でも引用させていただいた。
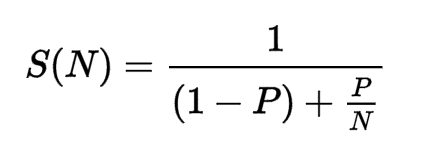
P は並列化できる仕事の割合、N は並列数です。ある仕事のうち 50% の部分が並列化 可能だとすると、N を無限大にしても(分母の右側の項がゼロになる)、パフォーマン スは 2 倍にしかなりません。90% が並列化可能だとすると、最大で 10 倍になります。 並列化の恩恵がどれだけあるかは、並列化できる仕事の割合によって変わるのです。
アムダールの法則によると、並列化して効率がどれだけ改善できるかは P にかかっ ているといえます。P を改善するには、逐次処理をなるべく分解して、同じ粒度のシ ンプルなたくさんのジョブに分ける必要があります。(Goならわかるシステムプログラミング P263より)
高速化できない部分と、並列化数というのが変数となっていて、パフォーマンスの限界値を表す式である。並列化できない部分以外はきれいにすべて並列化されており、並列数を無限に増やせば他の部分のスループットが最大化されて・・・みたいな、理想の世界の式であり、あくまでも「限界値」を表すものであって現実世界とは少し異なる。現実の問題を考えながら、どういったことがシステム全体のスループットを向上させるのに必要なのか考えてみたい。
まず並列化できるところといっても、例えば1000個に分割できる仕事があって、それぞれが1秒かかるとすると、1000コアのCPUでうまく分散しても1秒までは高速化できるが、2000個にしてもスループットは変わらないわけだ。
→ 1: タスクが分割できる個数以上の高速化はできない
実際にはタスクのサイズが平均化されているということはない。また、タスクの複雑度もまちまちであることが多いだろう。999個の仕事は1秒で終わるが、残り一個の仕事が1000秒かかるとすると、1000コアで実行しようと、2コアで実行しようと最終的な終了時間は変わらないわけだ。
→ 2: なるべく細かく分割して多重化しようとしても、時間のかかるタスクがあると最大パフォーマンスが得られるコア数が減ってしまう
今までの紹介は、ジョブキューに大量にジョブが並んでいて、すでに生成済みのスレッドプールが独立したタスクをガンガン取っていくというモデルであった。実際には完全に並列にできないケースがあって、2つのコアでお互いに仕事をする必要があって、そこのコードブロックだけは並列化の寄与度が低いなどである。お互いの相互作用が多かったりすると、その分お互いのパフォーマンスの全力が出せずに、待ちが発生してしまう。
→ **3: 相互作用が多ければ多いほど待ちのロスが増える
前の項目まではジョブキューにタスクがあって、これを淡々とこなすという前提であった。とはいえ、最初からすべての仕事が分かっていて、これだけをやればいい、というわけにはなかなかいかない。何かタスクを実行したら、新しいタスクが現れる、というのはよくある。N+1クエリーみたいなものがそうだ。これは並列で処理をするための、タスク発見のためのタスクを実行したと言えるし、それにより動的に優先度を制御しないといけなくなる。つまり、管理が必要になってくる。どのぐらい労力をかけてこの管理タスクをやり遂げればいいのか、というのが問題になる。
まずタスクを全部洗い出してしまって、その後は必要なリソースを管理して一気にやり遂げるという方法はその1つである。もちろん、アムダールの法則そのものであるが、この洗い出すタスクそのものは並列化はしにくいので、全体のスループットは落ちる(ただし実行フェーズに関しては最速)。今時であればクラウドなどでガンガンコア数を増やして最速でやりきる方法もある。
もうひとつは、後続で処理を行うコアのジョブキューが空にならない程度のスループットでタスクの洗い出しをする方法もある。これらの選択肢はどちらかのみ、というわけではなくこの両者の間で、最適なポイントを見つける必要がある。このどちらが最適かは状況次第である。
→ 4: タスクを洗い出すタスクという並列化できないタスクもありえる
NUMAと、ヘテロジーニアスマルチコア
これまでの話は、コアの性能が同等という前提で話をしてきた。また、タスクが置いてあるメモリへのアクセスも平等という前提だった。しかし、必ずしもそうではない。
詳解Linuxカーネルの8.1.2の不均等メモリアクセスアーキテクチャ(NUMA)というのがその1つである。この記事を読んでいるPCはメモリとしては1つのブロックで、その上にいくつかのCPUコアが載っているという構成だろう。しかし、超大規模なコンピュータだと必ずしもそうはいかない。
例えば、8000コアのスーパーコンピューターがあって、全部のコアから等距離な場所にメモリを配置、というのは不可能である。いくつかのコアとメモリを搭載した基盤を作り、これをたくさんならべ、基盤ごとを高速なバスで接続する、というのが一般的だろう。この場合、メモリブロックの場所によってCPUからの距離が大きく変わってくる。これをNUMA(不均等メモリアクセスアーキテクチャ)と呼ぶ。
僕自身はこのような環境での最適化をしたことはないが、おそらく、高速アクセスできる単位でタスクを振り分け、遠い基盤とのアクセスを減らすということが必要になってくるだろう。
→ 5: コア数が増えてくると、メモリアクセスの時間が不均等になるため、高速アクセスできる単位で大きくタスクを割り振る
不均衡なのはメモリだけではなく、コアの方にもある。これを読んでいる方のスマートフォンのbig.LITTLEアーキテクチャがそうだ。性能が低いけど電力効率の良いコアと、電力効率は低いが性能が高いコアを切り替えることで、省電力とパワーを両立させるARMの技術だ。なお、実際に使っているスマホがあるかはわからないが、両方を動かす方式もいちおうあることになっている。
big.LITTLEは同じ命令セットを使えるコア同士の協調動作であったが、別の命令セットを使うコア同士の協調動作もありえる。有名なのはPS3に搭載されたCellである。また、CPUとGPUの組み合わせでGPGPUもヘテロジーニアスマルチコアという扱いになる。一応後者は、mesaなどを使って、CPUを使ってソフトウェアでシェーダーをエミュレーションというのはあるが、もちろんパフォーマンス上の劣化は著しい。もちろん、そのハードウェアを持っていないためにタスクが完了しない、というのと比べれば遅くてもできた方がまし、というところもある。また、GPUを使ってCPUのエミュレーションは不可能である。
→ 6: コア同士の性能は一定ではなく、また得意なタスク、一応できるが著しく効率が落ちるタスク、不可能なタスクというのもある
リカバリーとモニタリング
並列で一斉にタスクをこなすにしても、正常ケースばかりではない。Erlang/OTPのモデルは、親が子を監視して、問題があれば再起動する、というモデルである。タスクが十分に小さく、リカバリーが容易であればパフォーマンスの劣化は少ないだろう。もちろん、システム自体が問題があって、解決できないタスクであれば根本に手を入れる必要はあるが、ちょっとしたネットワークの疎通がたまたまうまくいかない、タイミングの問題だったり、メモリがたりないみたいなことも十分にあるのでこれでカバーできることも少なくはない。
→ 7: タスクが細ければ、うまくいかなかったら、再度そのタスクをゼロからリトライするのが一番カンタンである
タスクが大きくなってくると、失敗時に失うリスクが大きくなってくる。最近のゲームは、失敗しても即座に直前に戻れるというデザインになっていることが多い。そのようなチェックポイントを多数用意するのがリカバリーの速度を上げて、スループットを落とさないことにつながる。永続化機能付きのMQを使ったり、というのもあるが、そもそものタスクを小さくしておく、というのももちろん有効だろう。
→ 8: 大きなタスクは小さくし、チェックポイントを用意しておく
では問題の検知をどするのがよいだろうか。もちろん、すでにErlang/OTPのような、確実に動作する監視ツリーがあるのであれば、親が子供を監視する、というのが妥当である。現在はログを収集し、それを検知するというシステムが一般的になっている。この場合は、きちんと現状をつねにログを残すことで、問題の発見と対応を早くして、パフォーマンスのロスを減らせるだろう。
→ 9: 細かくログを残し、問題の発見と検知を早くする
分散システムになると、一貫性が問題になってくることがある。ネットワークで分断された2つのシステムがお互いにバージョンを勧めてしまって、データベースの一貫性が取れなくなるというものである。Split Brainと呼ばれる。分散で合意するということは、通らなかった方のタスク処理は無駄だったということになる。全体のスループットは大きく下がることになってしまうため、そもそもネットワークが分断されてあとから折衝が必要な状態にならないようにする必要があるだろう。完全に別のタスクをするのであればお互いの結果が干渉することはなくなる。
→ 10: 分散してあとから調整が必要な事態はなるべく避ける
まとめ
アムダールの法則を出発点にして、さまざまな事象について思いを馳せてきた。特に、これといった銀の弾丸の解を出してきたわけではないし、コンテキスト依存なので、とりうる手の中で最善を尽くさなければならないというのだけが明確な答えである。ただ、このエントリーのようにモデル化して、取りうる選択肢を羅列することで、より最適な選択肢が選びやすくなる、ということは期待したい。
現実問題に落としていこうとすると管理しなければならないものがかなり大量に増えてきてしまう。Goのデザインがよくできているのはgoroutine間に差がなく、優先度を設定する項目もなく、IDもない、というところにある。機能が足りないと思っていたこともあったが、逆に複雑度を増やしてしまうという誘惑にかられることがない。
1番から6番に数値が大きくなって行くに従って、どんどん管理のコストは増えていくため、管理側として意識することはなるべく前者になるように意識していくのが大事だ。統一的なジョブキューがあって、自律的に動くワーカースレッドがそこから仕事を取って完了していく。「管理」というコストがゼロになるので、こういったところがやはり目指すべき姿ということになるのだろう。スクラムではなくて、エクストリーム・プログラミングの方が理想系ということになる。
最後に
なお、このエントリーはポエムです。チームのマネジメントのお話をメタファーで書いたものです。システム=チーム、コア=チームメンバー、クラウド=外注、ログ=Slackなどのチャットとかと置き換えてお読みください。
システム開発のスキルとマネジメントのスキルは別物だ、出世すると管理職になるキャリアデザインは間違っている、的な話はよく見かけますが、マネジメントもテクニックであるなら、システム開発に長けている人ならではのマネジメントもあるのではないか、と考えています。
もちろん、マネジメントといっても、方向性を決めるディレクション、タスク管理、チーミングなどいろいろなスキルセットがあるわけで、今回はタスク管理だけしかカバーしてません。