本記事では有名LLM が公開されたときにどのようなベンチマークが評価に使われているかを紹介していきます。
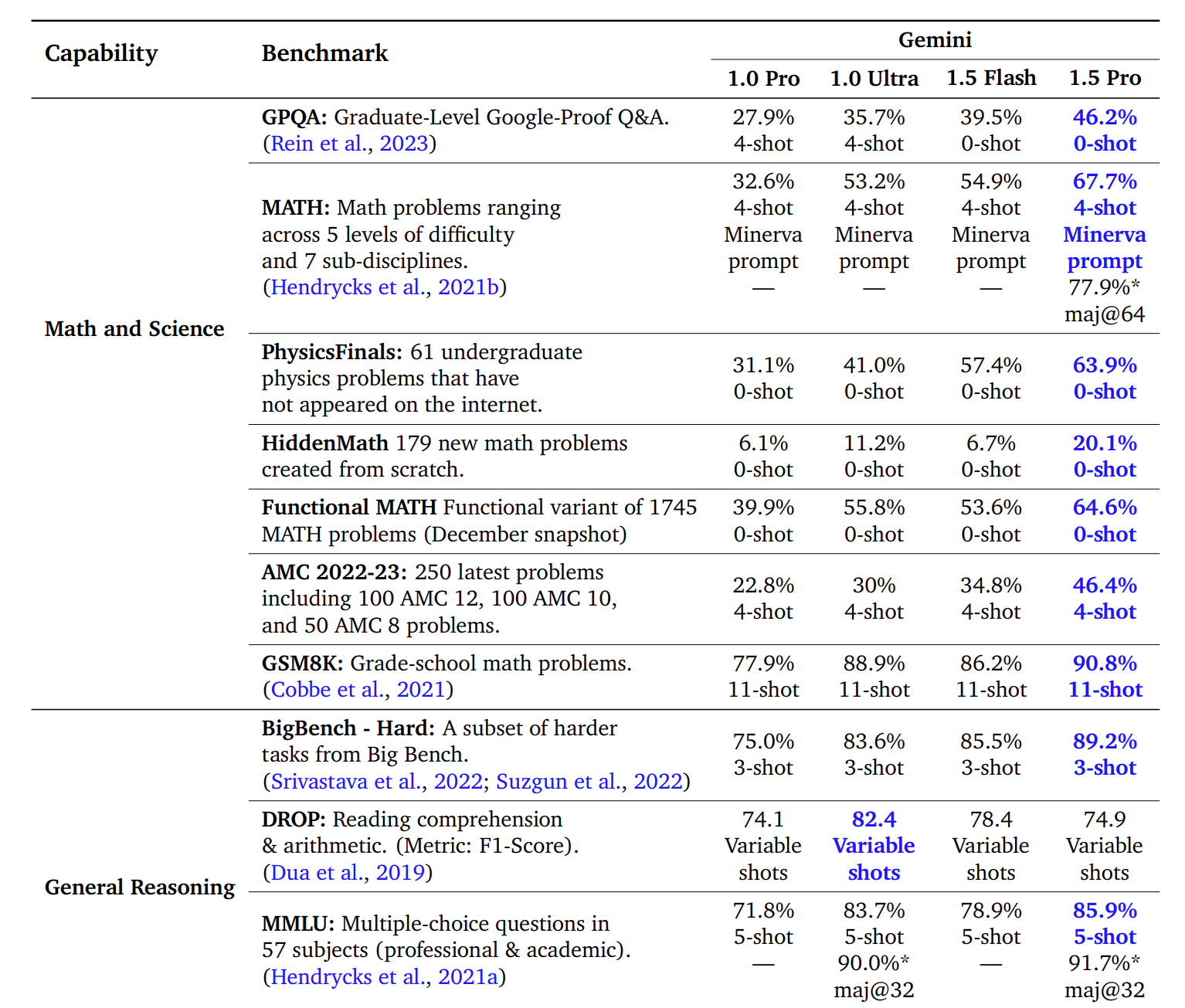
上記画像はGemini 1.5: Unlocking multimodal understanding across millions of tokens of context から引用したものです。
目次
背景と目的
背景
新しいLLM が公開されるときには、「こんな優れた能力があります!根拠はこれらの評価ベンチマークのスコアです」のような書き方がよくされるものの、ベンチマークの中身を知らないと「本当に?」となりますよね。
目的
本記事では、新しいLLM が公開されたときにLLM の能力を適切に読み取れるように、複数のLLM のテクニカルレポートなどからどのような評価ベンチマークが使われているかを整理し、その中身を簡単に解説します。
有名LLM 発表で使われている評価ベンチマーク
本記事では以下のモデルとページを参考に評価ベンチマークをまとめました。
| 分類 | LLMベンチマーク | OpenAI o1 | GPT-4 | Claude 3.5 Sonnet | Gemini1.5 | Llama3 | Phi3 |
|---|---|---|---|---|---|---|---|
| general | MMLU | ○ | ○ | ○ | ○ | ○ | ○ |
| general | GPQA | ○ | ○ | ○ | |||
| general | BIG-Bench-Hard | ○ | ○ | ○ | |||
| general | HellaSwag | ○ | ○ | ○ | |||
| general | WinoGrande | ○ | ○ | ||||
| general | DROP | ○ | ○ | ||||
| math | GSM-8K | ○ | ○ | ○ | ○ | ||
| math | MATH | ○ | ○ | ○ | ○ | ○ | |
| math | MGSM | ○ | ○ | ○ |
【LLM と参考ページ】
- OpenAI o1
- GPT-4
- Claude 3.5 Sonnet
- Gemini 1.5
- Lllama3
- Phi3
※注意点として、分類はgeneral(広い領域での評価)とmath(数学能力)に絞っていること、また適切な比較ができるように複数のLLM で使用されているベンチマークに限定しています。
評価ベンチマークの紹介
MMLU
参考文献:Measuring Massive Multitask Language Understanding
- MMLUは「Massive Multitask Language Understanding」の略。
- AIモデルのマルチタスク性能を評価するためのテスト。
- 57のタスク(初等数学、コンピュータサイエンス、法学など)をカバー。
- モデルの知識や問題解決能力を測定。
- 推定される専門家レベルの正確さはおよそ89.8%。これが専門家レベルをLLM が超えたかの基準になっている。
- 15908 個の質問が含まれ、14079 個の質問がテストセットに含まれる。それぞれの科目に対し最低でも100 個の質問がある。
- オンラインの無料で利用可能なソースから手動で収集。
MMLU の問題の例は以下のようになっています。

57 のタスクの全量は以下のようになっています。
MMLU はGemini Ultra が専門家を超えたと主張されたときに使われました(参考リンク)。

GPQA
参考文献:GPQA: A Graduate-Level Google-Proof Q&A Benchmark
- GPQAは、448問の選択式問題からなる難易度の高いデータセット。
- 生物学、物理学、化学の専門家によって作成された高品質な問題を収録。
- 博士号取得者や博士課程の専門家でも正答率は65%、明らかなミスを除外しても74%にとどまる。
- 熟練した非専門家がウェブに無制限にアクセスしても正答率は34%(Google検索では解けない問題)。
- 発表当時のGPT-4ベースのLLMでも正答率は39%にとどまる。
GPQA の問題の例は以下のようになっています。

main、extended、experts、diamond というレベルが用意されれているらしく、o1 で使われていたのは、diamond レベルだったようです(参考リンク)。人間の専門家のスコアは69.7% のようでした。

BIG-Bench-Hard
参考文献:Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
- BIG-Bench-Hard は、BIG-Benchの中でも特に難しい23のタスクを集めた評価ベンチマーク。
- 以前の言語モデル評価で平均的な人間評価者のパフォーマンスを超えられなかったタスクで構成。
- 多くのBBHタスクは多段階の推論が必要。
- Chain of Thought(CoT)を使わない数ショットプロンプトでは、言語モデルの能力が過小評価される可能性がある。
※そもそもBIG-Bench は132の機関から450人の著者によって提供された204のタスクで構成されており、言語学、児童発達、数学、常識推論、生物学、物理学、社会的バイアス、ソフトウェア開発などに多岐にわたるようです(参考リンク)。
BIG-Bench-Hard の問題の例は以下のようになっています。

HellaSwag
参考文献:HellaSwag: Can a Machine Really Finish Your Sentence?
- HellaSwagは、常識的な自然言語推論に挑戦するためのデータセット。
- 人間には簡単な問題(95%以上の正答率)である一方、2019 年当時最先端のモデルは48%未満の正答率。人間にはばかばかしく見えるが、モデルは誤分類しやすい問題。
- データ収集手法としてAdversarial Filtering(AF)を使用。
- AFでは、複数の識別器が機械生成の誤答を段階的に選び、難易度を上げていく。
- ゴルディロックスゾーンを目指し、データセットの長さと複雑さを調整。
HellaSwag の問題の例は以下のようになっています。

DROP
参考文献:DROP: A Reading Comprehension Benchmark
Requiring Discrete Reasoning Over Paragraphs
- DROPは、英語の読解ベンチマークで、パラグラフの内容に対する離散的な推論を必要とする。
- クラウドソーシングで作成され、96,000問の質問を含む。
- システムは、質問内の参照を解決し、複数の入力箇所に対応して、加算、カウント、ソートなどの離散的な操作を行う必要がある。
- 従来のデータセットよりも、パラグラフの内容をより深く理解することが求められる。
- 人間の専門家は96.4%のF1スコア。
DROP の問題の例は以下のようになっています。

GSM-8K
参考文献:Training Verifiers to Solve Math Word Problems
- GSM-8Kは、8,500件の高品質な小学校レベルの数学の文章題を集めたデータセット。
- 言語的に多様な問題を含み、多段階の数学的推論に焦点を当てている。
- 概念的にはシンプルな問題であるにもかかわらず、当時の大規模なトランスフォーマーモデルでも高いテストパフォーマンスを達成できない。
GSM-8K の問題の例は以下のようになっています。

MATH
参考文献:Measuring Mathematical Problem Solving With the MATH Dataset
- MATHは、12,500問の難解な競技数学の問題を含むデータセット。
- 各問題にステップバイステップの解答が付いており、モデルに解答の導出や説明を学習させることが可能。
- 当時の大規模なトランスフォーマーモデルを使用しても、精度は比較的低いままである。
- 予算やモデルのパラメータ数を単に増やすだけでは、強力な数学的推論の達成は現実的ではない。
- →確かにOpenAI o1 では単純なモデルによる向上だけではなく、CoT を使った推論などで数学能力が向上してますよね(参考リンク)
MATH の問題の例は以下のようになっています。

MGSM
参考文献:LANGUAGE MODELS ARE MULTILINGUAL CHAIN-OF-THOUGHT REASONERS
- MGSMは、多言語環境における推論能力を評価するためのベンチマーク。
- GSM8Kデータセットの小学校レベルの数学問題250問を10の異なる言語に手動で翻訳。
- CoT プロンプトを用いることで、モデルの規模が大きくなるにつれ、問題解決能力が向上。
- ベンガル語やスワヒリ語などの少数言語でも、モデルは驚くほど強力な推論能力を発揮。
MGSM の問題の例は以下のようになっています。

MMLU-Pro
参考文献:MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Llama3 でしか使用されていなかったものの、紹介しておきます。
- MMLU-Proは、MMLUベンチマークを拡張したデータセット。
- MMLUに比べ、より推論に重点を置いた質問を導入。
- 選択肢の数を4つから10に拡大。
- MMLUに存在する平易でノイズの多い質問を排除。
- 正確性が16%~33%低下し、難易度が大幅に上昇。
- 24種類のプロンプトスタイルでテストし、プロンプトによる結果の変動が減少(4~5%から2%に)。
- Chain of Thought(CoT)推論を利用したモデルが、MMLU-Proでより良いパフォーマンスを発揮。
MMLU-Pro の問題の例は以下のようになっています。

評価ベンチマークの動向としては、LLM の精度が向上してきているのでより難しくしようというのが潮流という気がしています。
まとめ
本記事では有名LLM が発表されるときに使われている評価ベンチマークについて紹介してきました。
様々な評価ベンチマークが提案されているものの、共通して使われているものはMMLU のような広い領域のベンチマークやHellaSwag のような2019 年に公開された古いものなど実績があるもののようでした。特に最近は数学や推論が得意なOpenAI o1 が出てきており、MATH んど数学能力の測る評価ベンチマークも重要です。
モデル横断的にどのような評価がされているかを調べた記事はあまりないような気がするので、どなたかのお役に立てれば幸いです。