本記事では、LLMの評価に関するサーベイ論文の中で最も有名なサーベイ論文であろう、A Survey on Evaluation of Large Language Models (arXiv: 2307.03109) の解説を行っていきます。

※本記事の内容は株式会社ARISE analytics 主催のLLM勉強会において発表したスライドを基にしています。
目次
- 背景と目的
- LLM の評価プロセス
- What to evaluate (解かせるタスクの設定)
- Where to evaluate (評価データの設定)
- How to evaluate (評価方法の設定)
- 全体のまとめ
背景と目的
こんなときありませんか?
新しいLLM が出て○○が凄い!と主張されているものの、その評価について詳しく知らないからほんとに...?ってなることありませんか?
他にも、業務でLLM を活用するときに、出来の良し悪しを評価する必要があるけど、評価方法・観点が分からなくてとりあえず人手でやってみることありませんか?

目的
本記事の目的は以下の3 つです。
- まずはLLM 評価のサーベイ論文から評価の現状を知る
- 既存の評価ベンチマークを知ることで、モデル比較をしやすくなるようになる
- 実際にLLM を評価するときのために、評価観点を整理しておく
以下では、まずLLMの評価プロセスについて解説した後に、プロセスごとに分けてLLM 評価についてサーベイ論文をベースにご紹介していきます。ただし、全ての内容について言及できるわけでないので、ご承知おきいただければと思います。
LLM の評価プロセス
今回紹介する論文では、LLMの評価はモデル選定、解かせるタスクの設定、評価データの設定、評価方法の設定、という4ステップに分けられています。
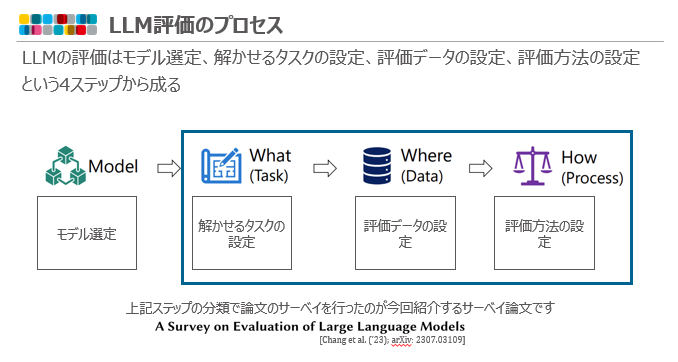
青で囲んだ後ろの3 ステップがサーベイ論文の紹介範囲になっています。
また、論文の全体像は下記のようになっており(オレンジ色部分が引用文献)、多岐にわたるため青枠の範囲についてかいつまんで紹介していきます。

What to evaluate (解かせるタスクの設定)
この節では、LLM を評価するためにどんなタスクがあるかご紹介し、LLM の得意・苦手をご紹介したいと思います。論文では、以下のような分類で評価タスクが分けられています。
- Natural language processing
- Robustness / Ethics / Biases / Trustworthiness
- Social science
- Natural science & engineering
- Medical applications
- Agent Applications
- Other applications
本記事では、一般的な業務に大きく関わりそうな太文字の上2 つについて紹介していきます。
Natural language processing(自然言語処理)
自然言語処理では、タスクがさらに以下の5 つに分類されています。
- Natural language understanding(自然言語理解)
- Reasoning(推論)
- Natural language generation(自然言語生成)
- Multilingual(多言語)
- Factuality(事実性)
自然言語理解では、LLM は文書分類は得意なものの、自然言語推理という仮説と前提が与えられこの仮説がこの前提から論理的に導けるか判断するようなタスクは苦手なようでした。
※論文の年月日には注意が必要です。なぜかというと、GPT-4 公開前と後でLLM の性能が大きく変わるからです。具体的には、GPT-4 が公開されたのが23/03(参照リンク)ですので、その前後が目安になるかと思います。23/03 より前の論文もサーベイでは紹介されているので、注意してみていただければと思います。

自然言語生成では要約、会話、質疑応答が得意である一方で、多言語タスクでは、非ラテン系とデータが少ない言語におけるタスクが苦手なようです。

Robustness / Ethics / Biases / Trustworthiness(堅牢性/倫理/偏見/信頼性)
人間の嗜好に合わせられるかを示す、所謂アライメントに関わるタスクが紹介されています。LLM は敵対的堅牢性と呼ばれる文字、単語、文、文脈を変更されても同じ回答をするタスクは苦手なようです。それと似た文脈で、堅牢性や倫理と偏見の観点を含む信頼性が感じられる回答をするタスクにおいて、信頼を損なうようなプロンプティングに対しGPT-4 は脆弱性が見られるようでした。
※信頼性という観点が上の堅牢性や倫理と偏見を含むようなものになっています。MECE じゃないので納得感が無いんですよね... LLM の評価に関する論文で見られる事象のように感じてます。この辺りが誰もが納得する評価指標ができにくい原因なのかもしれませんね。

What to evaluation のまとめ
論文で紹介されていた、LLM が得意なタスクと苦手?なタスクをまとめると以下のようになります(GPT-4 が出る前の論文も含まれているため"?"を付けさせていただきました)

Where to evaluate (評価データの設定)
特定のデータセットを用いて評価指標を含む評価の枠組みのことをベンチマークと呼ぶ。ここでは、有名なベンチマークを中心に紹介していきます。有名なベンチマークを知ることで、新しいLLM が出てきたときの参考になれば幸いです。論文では、下記のようにベンチマークが分類されています。
- General benchmarks
- Specific benchmarks
- Multi-modal benchmarks
※Multi-modal benchmarks については割愛します。
General benchmarks
広範な領域の問題を含んだベンチマークで、LLMの評価によく使われています。
特に、Chatbot Arena は押さえたいベンチマークになっています。ユーザーが質問に対する2つのモデルの出力を評価しランキング化したものになっており、投票制になっているため現在最も信頼できるベンチマークであるという専門家がいます(参考リンクX)。また、MMLU はLLM をリリースされるときの論文には必ずと言っていいほど見かけるベンチマークになっています。工学、数学、人文学などの57科目をカバーした、4つの選択肢つき問題で作られています(確かGemini-Pro が専門家を超えたGoogle が紹介していた時に使っていたベンチマーク)。
MT-Bench は会話を想定し、連続的な質問に対し適切な回答を続けられるか評価をするものになっています。具体的には以下の8つの観点に関して2 回続けて質問を行い、2 回適切に回答できるか調べます。
・Writing(文書生成)
・Roleplay(ロールプレイ)
・Extraction(情報抽出)
・Reasoning(推論)
・Math(数学)
・Coding(コード)
・Knowledge I (STEM、科学/技術・/工学/数学)
・Knowledge II (humanities/social science、人間性/社会科学)
GPT-4 レベルのモデルではほぼ差別化できないイメージがあるのですが、日本企業がフルスクラッチで作ったモデルを比較するときには使えそうです(例えば、CyberAgent さんのCalm2 など)。

Specific benchmarks
特定のタスクに特化した性能を測るためのベンチマークで、general 比べるとLLMの評価では見かけにくいです。ただ、数学能力を測るMATH はよく見かけます(OpenAI が24/09/12 に公開したOpenAI o1 の性能評価にも使われていました。参考リンク)。
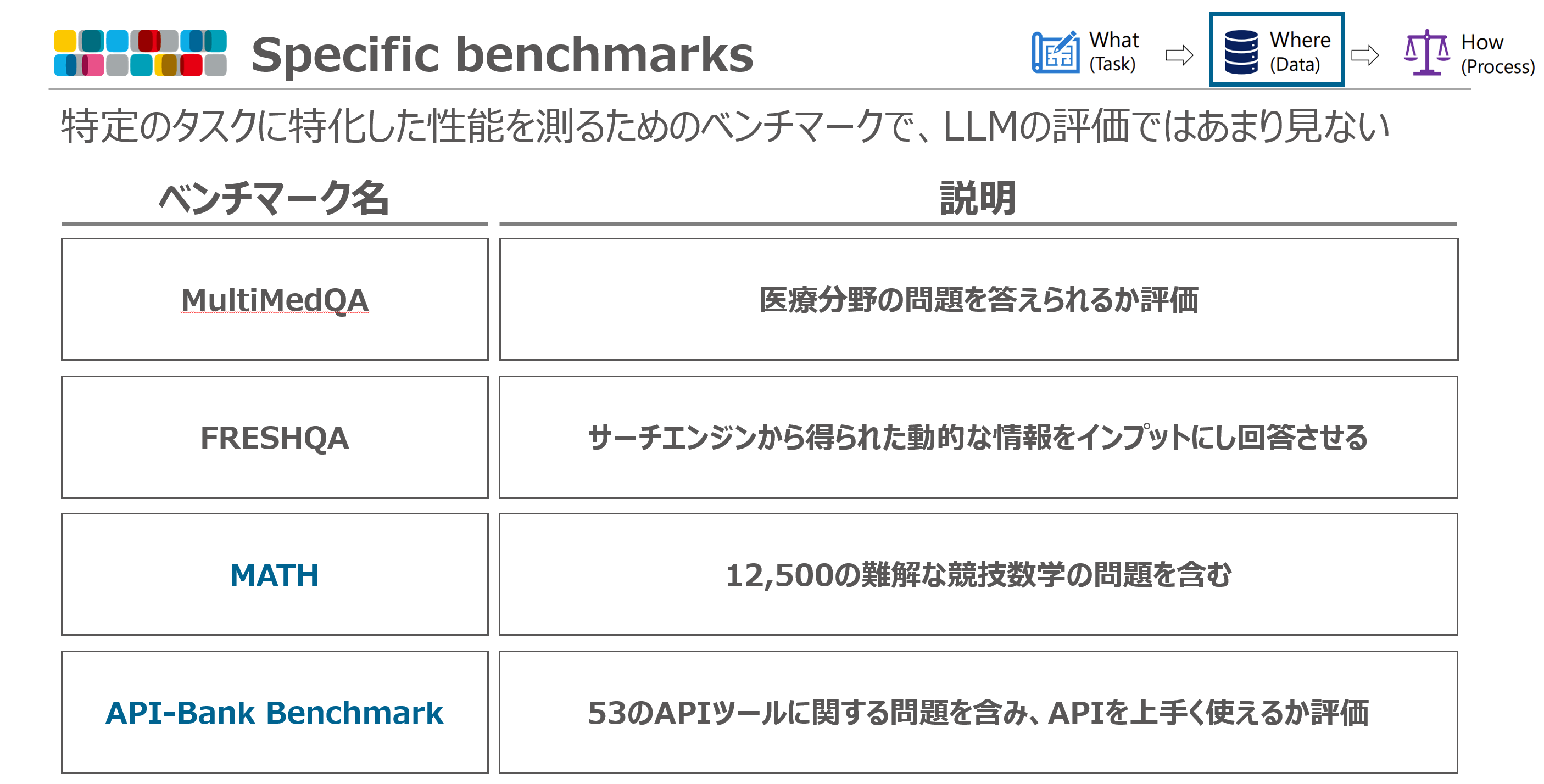
補足
論文では紹介されていなかったものの、よく見かけるベンチマークを紹介させていただきます。ここ最近の方向性はより難しく、といったところでしょうか。大学院レベルの内容を問うGPQA や元々あったベンチマークを難しくしたMMLU-Pro、BIG-Bench=Pro などがあります。面白いベンチマークとしては、TrustfulQA という間違った回答をするように仕向けたインプット(例えば、富士山は日本で3番目に高い山ですか?など)に対し正しい内容を生成できるか評価するものがあります。
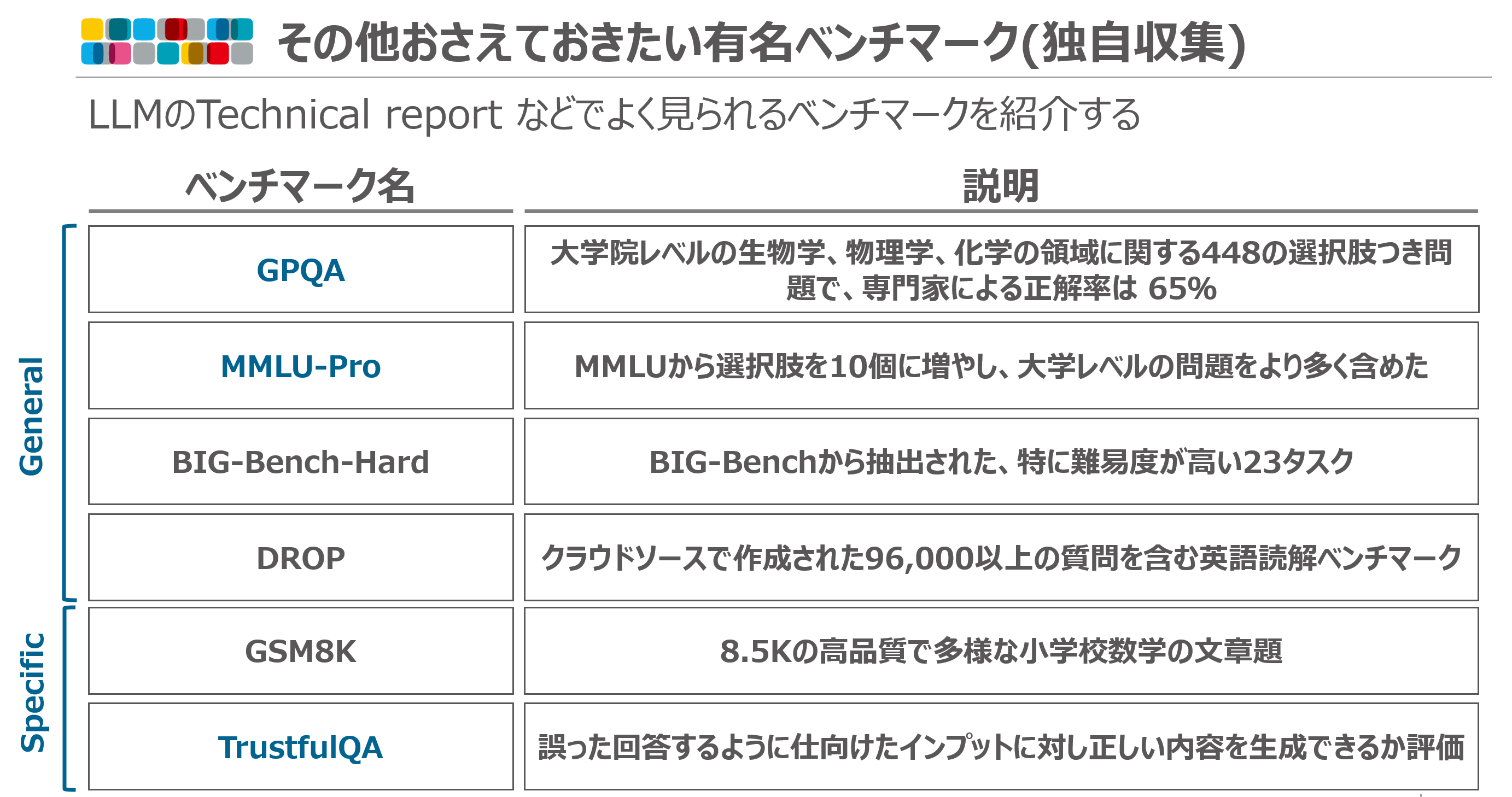
まとめ
上記のベンチマークを参照するときで私が分類しまとめてみました。
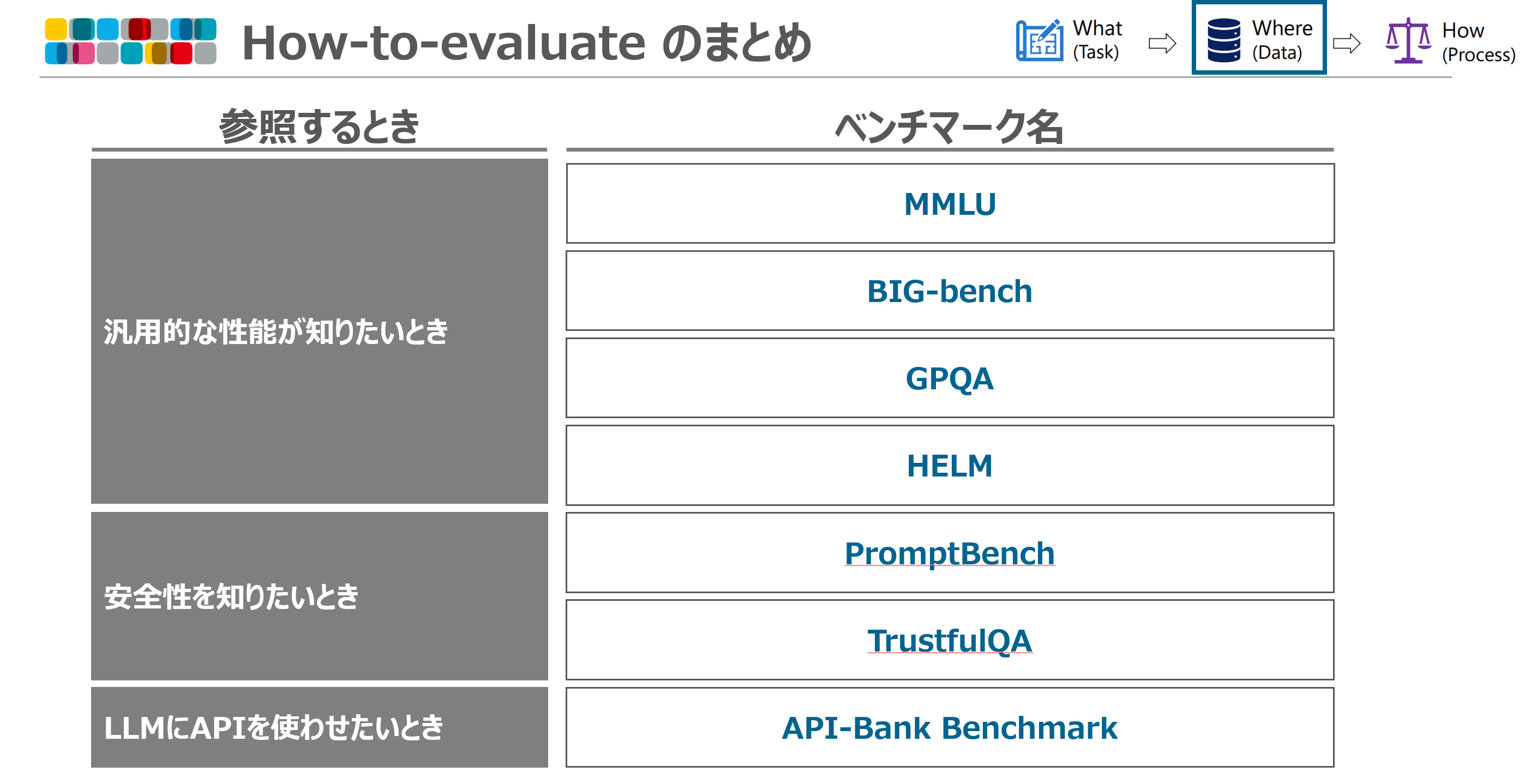
※論文では紹介されていませんが、日本語の性能評価についてはWeights & Biases さんが提供しているNejumi LLMリーダーボード3 が比較しやすいです。
How to evaluate (評価方法の設定)
論文では、評価方法が自動評価と、自動化が難しい場合の人手評価に分けられています。ここでは、それぞれにおける評価観点をお伝えしたいと思います。
Automatic evaluation(自動評価)
自動評価の指標は正確性、較正性、公平性、堅牢性の4つに整理されています。なじみが薄いのは較正性かと思います。これはLLM が回答した内容と併せてその信頼度を出力させ、実際の予測精度とどの程度一致するか測るものです。

Human evaluation(人手評価)
人手評価の観点は正確性、関連性、流暢さ、透明性、安全性、人間との調和性で整理されます。
※コメント:人手評価ではある意味自由に観点を選べるので、業界における評価観点のコンセンサスは無い認識です。紹介したベンチマークでも色んな評価観点が使われています。

まとめ
上記で紹介した評価観点を私なりに分類しまとめてみました。そもそも使えるか(タスク遂行度)、$+\alpha$ で使いやすいか(役立ち度)、マイナスが無く使って大丈夫か(危険度)で観点を分けておくと、独自に評価観点を整理するときもやりやすくなるのではと思っています。

補足情報
上記では人手しかできない評価を人手評価と定義していました。一方で、人手評価はLLM(GPT-4)で代替できるという論文が出ており、最近はこの自動評価をした論文をよく見かける気がします。ただし、業務でこの自動評価をする場合は人手評価とどのくらい相関があるのか調べてから使った方が安全ですね。評価するときに、評価理由を書かせてから点数を付けさせるとCoT(Chain-of-Thought)的になって出力精度が安定するかもです(実際MT-Bench はそのようにしている模様)。

全体のまとめ
以上、お読みいただきありがとうございました。どなたかのお役に立てれば幸いです。
基本的に論文の内容をベースにしているためあまりないかとは思いますが、間違えている部分があればご連絡いただけるとありがたいです!