Large Language Model Is All You Need
昨今の生成AI、特にLLM の発展は目覚ましいですね。本記事では社内で発表した内容を一部抜粋し、大規模言語モデルの簡単な紹介をいたします。
- 1. Large Language Model Is All You Need
1. Introduction
1.1. 本記事の背景
- 2010年代におけるニューラルネットワークによるAI関連の盛り上がりは第3次AIブームであると考えられ、また冬の時代が来ると予測する研究者がいた。
- しかし、昨年末のChatGPTの出現により、AIを取り巻く環境・雰囲気は劇的に変わった。これは単なるトレンド・流行ではなく、ほとんどのサービスにAIが使われる時期に入ったと私は考えている。
- ChatGPTなどでは情報が秘匿されている部分が多いが、Llama2など公開されているモデルがある。今後、より高度化し個人にチューンされた必要十分なモデルが現れる可能性が高い。
1.2. 本記事の目的
まずはLLM(大規模原言語モデル)の基礎として、DS企業の一員として知っておくべきLLMの背景、自然言語処理の発展の経緯を共有する。
人類の文明の発展に関する私の私信を共有し、LLMの発展を含めた将来に思いを馳せていただきたい。
2. 自然言語処理の歴史
2.1. 自然言語処理の大まかな歴史
サーベイ論文のイントロ部分 やすえつぐさんのブログ記事 によると、自然言語処理の発展は統計的アプローチ、ニューラルネットワークによるアプローチ、Transformer モデルによるアプローチの3つの時代に大きく分けられる。
 自然言語処理の大まかな歴史。
自然言語処理の大まかな歴史。
2.2. これまでのAIブーム
AIブームはこれまでに2度あり、2010年代からのニューラルネットワークによるAI分野の盛り上がりは第3次ブームで以前は収束するものと考える研究者もいた(私の研究室にセミナーで来られた機械学習の教授もまたブームだから終わるよと言っておりました)。
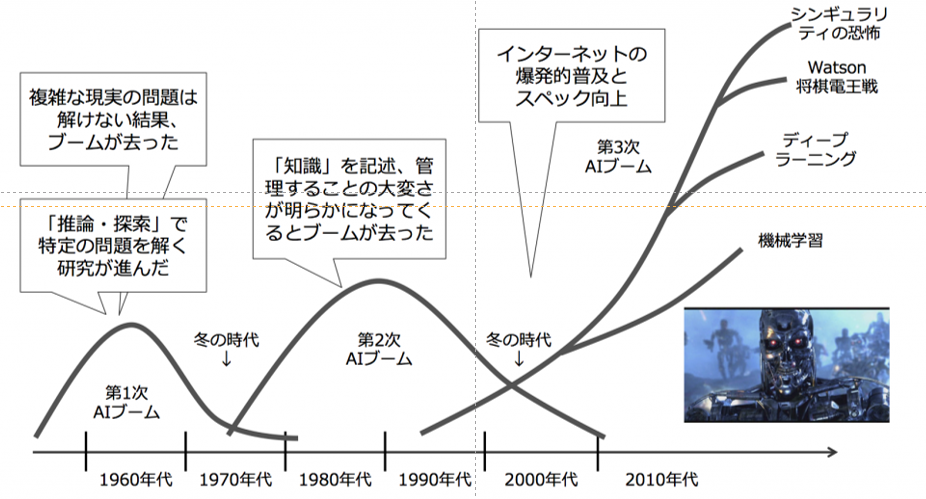 松尾豊氏著の「人工知能は人間を超えるか」から引用させていただいております。面白いので是非読んでみてください。
松尾豊氏著の「人工知能は人間を超えるか」から引用させていただいております。面白いので是非読んでみてください。
2.3. Transformer の登場
Transformer と呼ばれるアーキテクチャの登場(Google の社員らによる原論文:Attention Is All You Need)により、並列処理による学習が可能になり機械学習モデルの性能は劇的に向上した(第4次AIブームの到来? [Ref])。岡谷貴之氏(東北大学教授、理研チームリーダー) による「深層学習(改訂第2版)」では、通説を覆す「ちゃぶ台返し」の論文と表現されている。
松尾氏によると、LLMについてはTransformerと自己教師あり学習を理解すれば概略を掴める!らしい[Ref]。
Transformer の中身については、概略を知りたいなら末次さんの記事が、詳しく知りたいなら「大規模言語モデル入門」(山田育矢 (監修)、鈴木正敏、山田康輔、李凌寒)がおすすめ。

Transformer の構造(原論文:Attention Is All You Needより引用)。
2.4. 自己教師あり学習
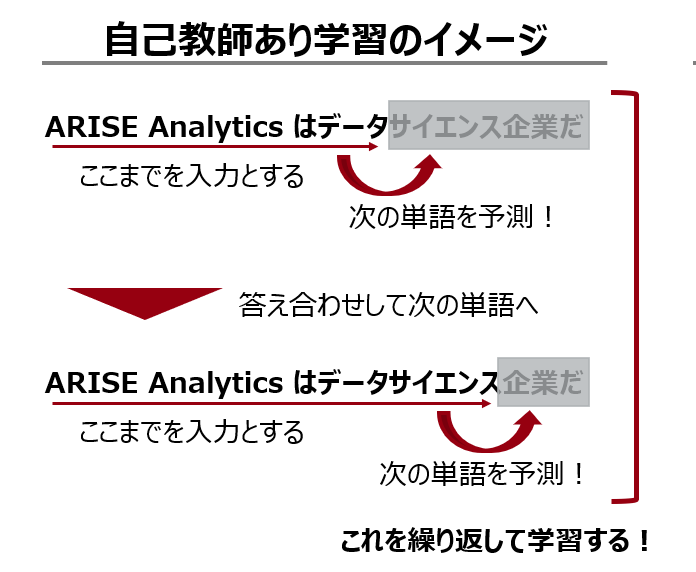
前出の「LLMについてはTransformerと自己教師あり学習を理解すれば概略を掴める!」と言われている通り、Transformer と自己教師あり学習を組み合わせることで、従来より簡単に大規模なデータを学習させることができるようになった。
自己教師あり学習では、文章の途中までを読み込ませて次の単語を予測させることで、人間が正解ラベルを用意しなくてもモデルの学習ができる。
3. LLMについての動向
3.1. LLM(大規模言語モデル)とは?
パラメータが10~100億以上の言語モデルのことである(Ref. A Survey of Large Language Models)。小さいモデルとは異なる性質(創発的能力)を持つために区別されている。
 言語モデルのパラメータサイズの変遷(https://www.assemblyai.com/blog/the-full-story-of-large-language-models-and-rlhf/ から引用したものにコメントを加えた
)。視覚的に分かりやすくまとめられているので、是非見てみてください。
言語モデルのパラメータサイズの変遷(https://www.assemblyai.com/blog/the-full-story-of-large-language-models-and-rlhf/ から引用したものにコメントを加えた
)。視覚的に分かりやすくまとめられているので、是非見てみてください。
3.2. なぜモデルは大規模になったのか?
モデルのパフォーマンスと3つの因子(トレーニング計算量、モデルサイズ、データセットサイズ)にpower-law(べき乗則) 関係、スケーリング則があることが指摘されたため。
従来の機械学習モデルでは、闇雲にパラメータを増やしても精度は上がらなかった。なぜTransformer モデルではスケーリング則が生まれるかは分かっていない。
OpenAI の社員によって提示された以下のグラフ(Ref. Scaling Laws for Neural Language Models)を見ると、綺麗にfitting 出来ていることが分かる。注意したいのは、fitting している式を見ると、べき乗の中身が定数で割られていることである。そのため、その定数を超えるとfitting の式としては減少から増加に転じる。無限にモデルサイズを大きくすれば精度が上がるというわけでは無さそうである。上記論文Scaling Laws for Neural Language Modelsでは、3つの因子(トレーニング計算量、モデルサイズ、データセットサイズ)の中でパラメータサイズを大きくすることが最も効率的と主張されている。
 モデルのパフォーマンスと3つの因子(トレーニング計算量、モデルサイズ、データセットサイズ)にpower-law(べき乗則) 関係がある [Ref. Jared et al. (‘20) [arXiv:2001.08361]]。
モデルのパフォーマンスと3つの因子(トレーニング計算量、モデルサイズ、データセットサイズ)にpower-law(べき乗則) 関係がある [Ref. Jared et al. (‘20) [arXiv:2001.08361]]。
3.3. 小さいモデルとの違い:創発的能力
これがLLM をLLM たらしめる所以!
ある程度モデルが大きくなると、創発的能力とよばれる様々な能力を獲得する。これにより、シングルタスクでなく(教えていないのに)マルチタスクをLLMはできることが発見された(今でも初めてChatGPT-3 を触ったときのことは忘れられません。文章生成も翻訳もコード生成もできるやん!すごすぎる!ってなりました)
 LLM の創発的能力のまとめ(Webサイト[https://lifearchitect.ai/models/] から引用、LLMに関するいろんなグラフが載っているので面白いです!)。
LLM の創発的能力のまとめ(Webサイト[https://lifearchitect.ai/models/] から引用、LLMに関するいろんなグラフが載っているので面白いです!)。
3.4. LLM作成の基本的な流れ
大規模なコーパスを用いて事前学習を行いモデルを作成する。その後、人間の要望に応えられるようにファインチューニングを行う。
 LLM の作成手順(Llama2 [Hugo et al. (‘23) [arXiv:2307.09288]] の論文より引用)。
LLM の作成手順(Llama2 [Hugo et al. (‘23) [arXiv:2307.09288]] の論文より引用)。
3.5. アライメントの必要性
ただ大規模なコーパスを学習させただけでは、LLMは人が望んだ挙動はしない。望んだ挙動をするようにアライメント(教育)する必要がある。
- 役立つこと(helpful)
人間の要望意図を理解し、適切な答えを返す。 - 正直であること(honest)
虚偽の生成を行わない(虚偽の生成を行う性質のことを幻覚、hallucination と呼ぶ)。 - 無害であること(harmless)
人を傷つける発言をしない。LLMが学習する訓練コーパスはWebから大規模に収集されたものが使われることが多い。そのため、LLMは性的、暴力的、非倫理的な内容を学んでしまう。また、訓練コーパスに偏りがある(ある国、属性の情報が多い)と、そのバイアス(たとえば、職業と性別のステレオタイプなど)をそのまま反映してしまう。
3.6. LLM の発展
カンブリア爆発のようにLLMの種類は増え続けている。

LLM の系統樹(サイト[https://github.com/Mooler0410/LLMsPracticalGuide] から引用、網羅的にLLM についてまとめられているので是非見てみてください)。
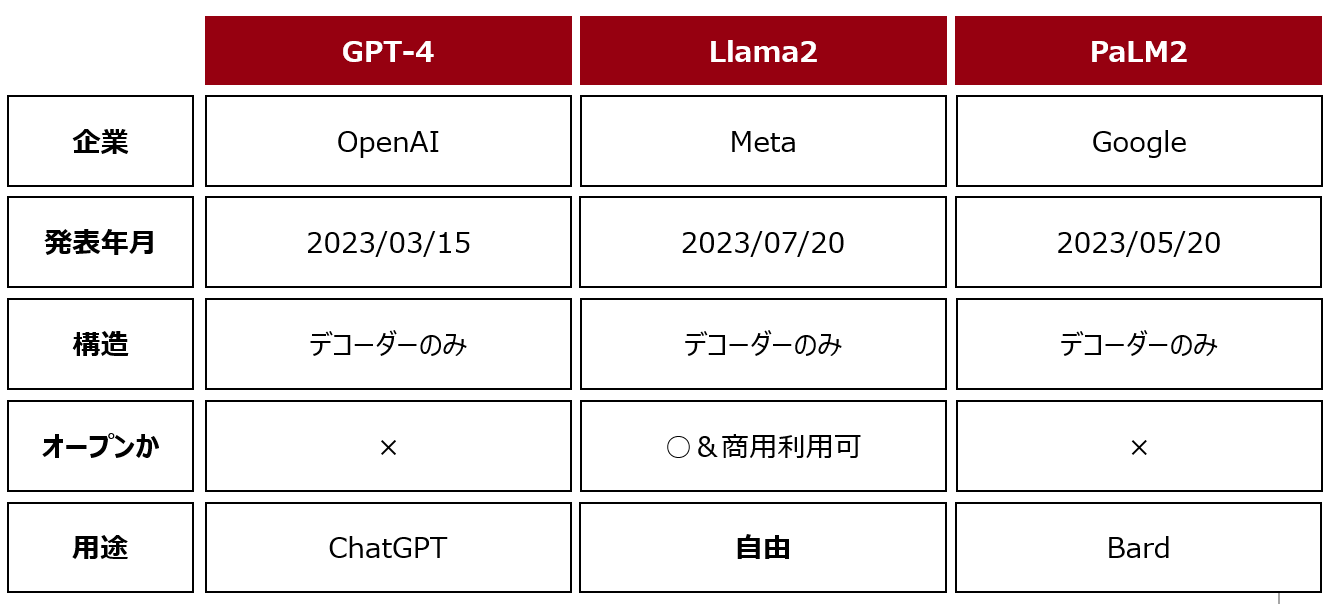
3.7. 特に有名なLLM(2023/11版)
OpenAI によるGPT-4、Meta によるLlama2、Google によるPaLM2が特に有名である(GPT-5 は詳細は分かりませんが、DevDay の質疑応答によると科学的な問題に直面しているらしいですね)。
4. LLMはどのように進化する?
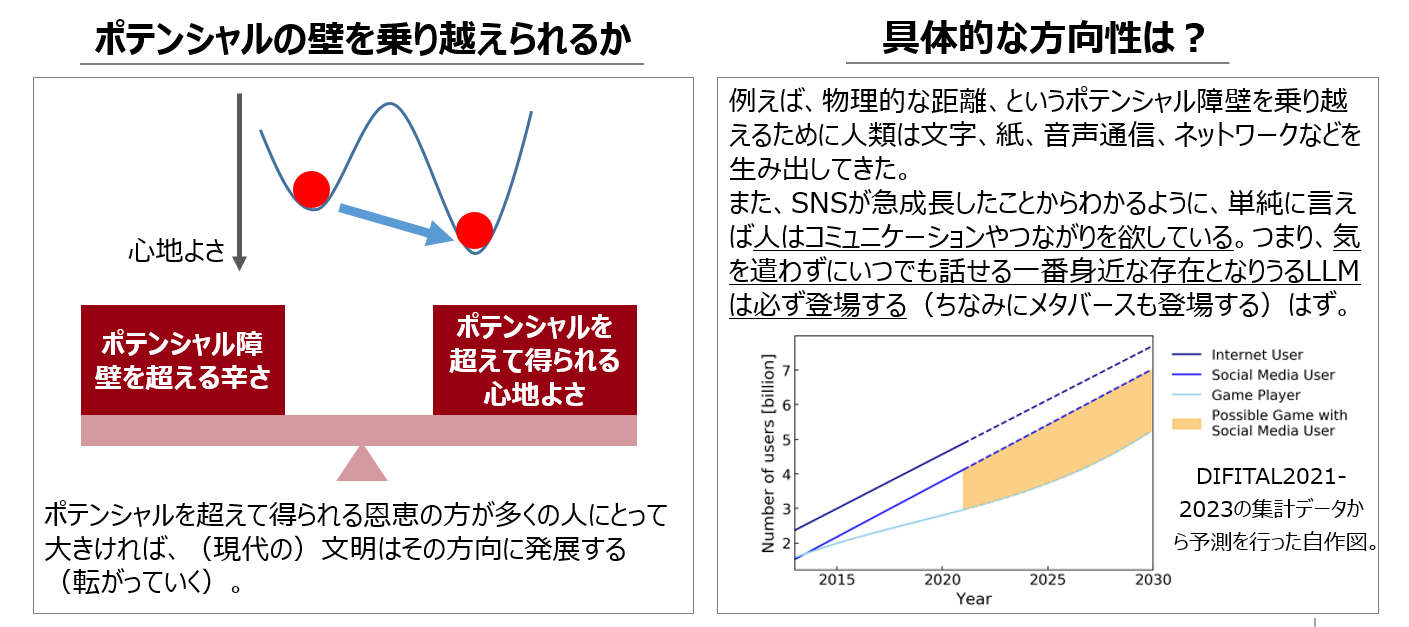
4.1. 文明が発展する方向とは(私見)
完全な私見だが、現代における文明の発展は、どれだけ多くの人が心地よく感じられるかによって方向性が決まっている。
4.2. LLMはすべてのサービスの入り口となる
これも私見だが、LLMは汎用性が高いため、すべてのサービスの受け口になる可能性が高い。Llama2については専用のスマホに載せられる計画が進んでいる。
 LLMはすべてのサービスの入り口となる、のイメージ図。
LLMはすべてのサービスの入り口となる、のイメージ図。
4.3. 汎用人工知能(AGI)の出現
人よりも賢い汎用人工知能が出現すれば、人類は最良の伴侶を得られるかもしれない。
ホモ・サピエンス以外の知的思考体の爆誕?
映画(her 世界でひとつの彼女) の世界観が現実になるかも。
個々人に寄り添うAIが開発されれば、LLMとしかコミュニケーションを取らないという人が現れるかもしれない。
→ “Large Language Model Is All You Need”
4.4. OpenAI のミッション
OpenAIはAGIを作ることをミッションに掲げ、LLMの開発に取り組んでいる。
サム・アルトマン氏は過去のインタビューでGPT-4は最初期のモデルで出来ないことが多い、という内容を述べている。現在使われているLLM はまだ序の口。以下はOpenAI のHP からの引用。
Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.
First, as we create successively more powerful systems, we want to deploy them and gain experience with operating them in the real world.
4.5. AGI はいつ出現する?
ラフな計算によれば、2025年にはAGIが出現するかも??
以下のグラフはAI Timelines via Cumulative Optimization Power: Less Long, More Short から引用している。
 人工的ニューラルネットワークと生物学的ニューラルネットワークの比較。非常にラフな計算だと、2025年にはAGI(人間に匹敵または超える能力を持つAI)が出現するかもしれない(Web記事 AI Timelines via Cumulative Optimization Power: Less Long, More Short から引用、結構ラフな計算ですがネタとして面白いので是非見てみてください)。記事では2032年には75%の確率でAGIが生まれると主張している。
人工的ニューラルネットワークと生物学的ニューラルネットワークの比較。非常にラフな計算だと、2025年にはAGI(人間に匹敵または超える能力を持つAI)が出現するかもしれない(Web記事 AI Timelines via Cumulative Optimization Power: Less Long, More Short から引用、結構ラフな計算ですがネタとして面白いので是非見てみてください)。記事では2032年には75%の確率でAGIが生まれると主張している。
4.6. でも…最後にはAll We Need Is Love?
一時的にはAI だけで十分だ!という人が出るかもしれない。しかし、人間は社会的動物でありAIを含めてやっぱり(Beatles の) All We Need Is Love に戻るんじゃないかと個人的には思っている。

ハーバード大学における724人を75年間追った研究から分かったのは、幸せの条件は「良い(人間)関係を持っている」こと(参考文献のGeorge E. Vaillant著のTriumphs of Experience: The Men of the Harvard Grant Study の表紙を引用。長年にわたる調査からファクトベースで人生で大事なことを考察している有用な書籍なので、是非読んでみてください)。
5. まとめ
-
自然言語処理の発展のステップはざっくり、言語的・統計学的モデル→ニューラルネットワークモデル→Transformer モデル、という流れだった。
-
Transformer モデルの登場で以前のモデルにはなかった、スケーリング則、創発的能力が発現した。これらの能力により、高精度かつ汎用的なモデルが爆誕した。創発的能力は大規模なモデルで発現するため、それらは大規模言語モデル(LLM)と区別されるようになった。
-
このままLLMが発展していけば、人類は最大の伴侶を得、それによりコミュニケーション様式・社会構造が大きく変わるかもしれない。
以上、読んでくださりありがとうございました!ご意見・訂正などあればご連絡いただければ幸いです。