はじめに
kaggle のコンペ(タイタニックの生存者を予測)をロジスティック回帰分析で行います。
また、目的変数の結果(死亡 or 生存)に与える影響度(回帰係数)も確認します。
今回のソースファイルはこちら
オブジェクト指向でプログラムを書く練習も兼ねています。ソースが汚いのはご容赦下さい。
環境
- Windows 10 Pro
- Python 3.6.8 (anaconda)
- scikit-learn 0.21.1
データのダウンロード
kaggle のページよりデータをダウンロードします。
※ユーザ登録が必要です。
データの確認と前処理
学習用・テスト用のデータを確認し、欠損値を補完・外れ値を置換・性別などのカテゴリカル変数(定性データ)は One-Hot-Encoding で数値化(ベクトル化)します。
変数の説明
| 変数名 | 説明 | 値の説明 | 備考 |
|---|---|---|---|
| PassengerID | 乗客 ID | キー | |
| Survived | 生存フラグ | 0=死亡, 1=生存 | 目的変数 |
| Pclass | チケットクラス | 1=上層, 2=中層, 3=下層 | |
| Name | 氏名 | 説明変数から除外 | |
| Sex | 性別 | male=男性, female=女性 | |
| Age | 年齢 | ||
| SibSp | 同乗している兄弟や配偶者の数 | 0, 1, 2, 3, 4, 5, 8 | |
| Parch | 同乗している両親や子供の数 | 0, 1, 2, 3, 4, 5, 6, 9 | 値 9 はテスト用データのみ出現 |
| Ticket | チケット番号 | 説明変数から除外 | |
| Fare | 料金 | ||
| Cabin | 客室番号 | 説明変数から除外 | |
| Embarked | タイタニックへ乗った港 | C=Cherbourg, Q=Queenstown, S=Southampton |
データの確認(基本統計量)
学習用データとテスト用データの数値データの基本統計量を確認します。
データ確認用のソースファイルはこちら
学習用データの基本統計量
Survived Pclass Age SibSp Parch Fare
count 891.000000 891.000000 891.000000 891.000000 891.000000 891.000000
mean 0.383838 2.308642 29.361582 0.523008 0.381594 32.204208
std 0.486592 0.836071 13.019697 1.102743 0.806057 49.693429
min 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 0.000000 2.000000 22.000000 0.000000 0.000000 7.910400
50% 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 1.000000 3.000000 35.000000 1.000000 0.000000 31.000000
max 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200
テスト用データの基本統計量
PassengerId Pclass Age SibSp Parch Fare
count 418.000000 418.000000 418.000000 418.000000 418.000000 418.000000
mean 1100.500000 2.265550 29.599282 0.447368 0.392344 35.576535
std 120.810458 0.841838 12.703770 0.896760 0.981429 55.850103
min 892.000000 1.000000 0.170000 0.000000 0.000000 0.000000
25% 996.250000 1.000000 23.000000 0.000000 0.000000 7.895800
50% 1100.500000 3.000000 27.000000 0.000000 0.000000 14.454200
75% 1204.750000 3.000000 35.750000 1.000000 0.000000 31.471875
max 1309.000000 3.000000 76.000000 8.000000 9.000000 512.329200
欠損値を補完
欠損値がある Age・Cabin・Embarked・Fare を補完します。
大きさを表す数値(Age・Fare)は中央値、カテゴリカル変数(Cabin・Embarked)は最頻値を補完します。
df['Age'] = df['Age'].fillna(df['Age'].median()) ## 中央値
df['Cabin'] = df['Cabin'].fillna(df['Cabin'].mode()) ## 最頻値
df['Embarked'] = df['Embarked'].fillna(df['Embarked'].mode()) ## 最頻値
df['Fare'] = df['Fare'].fillna(df['Fare'].median()) ## 中央値
外れ値を置換
Parch の値 9 はテスト用データのみ出現するので、学習用データの最大値 6 に置換します。
(学習用データとテスト用データをそれぞれ One-Hot-Encoding すると、学習用とテスト用で変数の数が違い、テスト用データの予測時にエラーとなるため)
df['Parch'] = np.where(df['Parch']==9, 6, df['Parch'])
One-Hot-Encoding
カテゴリカル変数(Sex・Pclass・SibSp・Parch・Embarked)を数値(ベクトル化)します。
df_dummies = pd.get_dummies(df, columns=['Sex', 'Pclass', 'SibSp', 'Parch', 'Embarked'])
データを標準化
連続値の Age・Fare を標準化(平均 0・分散 1)し、新しい列(Age_scale・Fare_scale)に保存します。
scaler = StandardScaler()
df_dummies['Age_scale'] = scaler.fit_transform(df_dummies.loc[:, ['Age']])
df_dummies['Fare_scale'] = scaler.fit_transform(df_dummies.loc[:, ['Fare']])
ロジスティック回帰の予測モデル
学習用データを訓練用と検証用に分割し、訓練用データで予測モデルを作成します。
予測モデルを作成
正則化のパラメータ C はデフォルト 1.0、最適なパラメータの探索方法 solver はデフォルト liblinear を指定します。
c = 1.0 ## 正則化のパラメータ(デフォルト 1.0)
## ロジスティック回帰のモデル
self.clf = linear_model.LogisticRegression(C=c, solver='liblinear', random_state=0)
## 予測モデルを作成
titanic.model(X_train, y_train)
予測モデルの精度
検証用データを予測した正解率(Accuracy)は 0.82 となり、なかなかの精度です。
Accuracy =(TP + TN)/(TP + FP + FN + TN)
= (97+ 49)/(97 + 20 + 13 + 49)
= 0.82
混同行列(検証用データ)
[[97 13]
[20 49]]
分類レポート(検証用データ)
precision recall f1-score support
死亡 0.83 0.88 0.85 110
生存 0.79 0.71 0.75 69
accuracy 0.82 179
macro avg 0.81 0.80 0.80 179
weighted avg 0.81 0.82 0.81 179
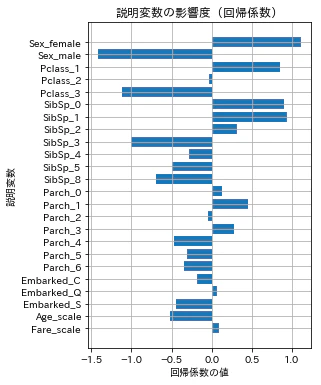
説明変数の影響度(回帰係数)を確認
予測モデルの目的変数の結果(死亡 or 生存)に与える各説明変数の影響度(回帰係数)を確認します。
回帰係数がプラスは目的変数 1(生存)へ、マイナスは目的変数 0(死亡)へ影響します。
また、回帰係数の絶対値が大きいほど、影響は大きくなります。
予測を実施
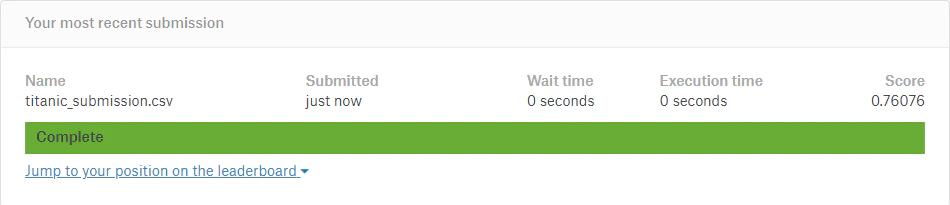
予測モデルでテスト用データを予測し、kaggle のコンペへ投稿します。
kaggle への投稿結果
kaggle のスコアは 0.76076、順位は 9066位(2019年7月26日 13:23 JST 現在)でした。
さらに精度を上げるには#
kaggle コンペの順位は微妙な順位(よくない順位)となっており、よい順位を獲得するにはさらなる精度の向上が必要です。
そのためには、以下を検討します。
- 学習用データ全体で予測モデルを訓練
- 正則化パラメータ C の調整
- 連続値 Age・Fare をビニング処理
- 今回使用しなかった変数(Ticket・Cabin)を利用
追記
学習用データ全体で予測モデルを訓練した場合(その他の条件は変更なし)、
kaggle のスコアは 0.77033、順位は 6759位(2019年7月26日 13:40 JST 現在)でした。