はじめに
青空文庫にある宮沢賢治の小説データ(銀河鉄道の夜・風の又三郎・注文の多い料理店)を RNN(リカレントニューラルネットワーク)で学習し、新たな文章を作成します。
今回のソースファイルはこちら
環境
- Windows 10 Pro
- Python 3.6.8 (anaconda)
- TensorFlow 1.13.1
- Keras 2.2.4
- Janome 0.3.9
概要(おおまかな処理の流れ)
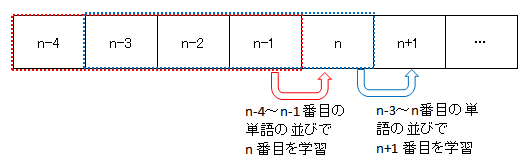
小説データを単語単位に分割(わかち書き)し、その分割したデータを以下の手順で学習します。
- 次に来る単語を直前の4つの単語の並びより学習。
- その次の単語は、その単語の直前の4つの単語(先ほど予測した単語も含む)より学習。
- 小説データの最後の単語まで1.2.を繰り返す。
- 1.2.3.を指定した回数(今回は100回)繰り返す。
小説データのダウンロードと前処理
小説データを読み込み、ベクトル化(One-Hot-Encoding)します。
小説データのダウンロード
Keras のユーティリティ utils.get_file でカレントディレクトリにダウンロードし、解凍します。
## 青空文庫よりデータをダウンロード
path = keras.utils.get_file(
url.split('/')[-1],
origin=url,
cache_dir='./')
## ダウンロードしたデータを同じディレクトリに解凍(展開)
zip = zipfile.ZipFile(path, 'r')
file_name = zip.namelist()[0]
zip.extractall(os.path.dirname(path))
zip.close()
小説データのわかち書き
ダウンロードしたファイルを読み込み、Janome を用いてわかち書き。
単語単位で配列に格納します。
from janome.tokenizer import Tokenizer
## わかち書き
t = Tokenizer()
words = []
for i in text_array:
for token in t.tokenize(i):
words.append(token.surface)
文字列のベクトル化
小説データを4単語の文字列(シーケンス)に分割します。
また、小説データの単語をベクトル化(One-Hot-Encoding)します。
## 文字列のベクトル化
maxlen = 4 ## 4単語のシーケンスを抽出
step = 1 ## 1単語おきに新しいシーケンスをサンプリング
sentences = [] ## 抽出されたシーケンスを保持
next_word = [] ## 目的値(次に来る単語)を保持
## 4単語のシーケンスを作成
for i in range(0, len(words) - maxlen, step):
sentences.append(' '.join(words[i: i + maxlen]))
next_word.append(words[i + maxlen])
print('シーケンス数 : ', len(sentences))
## 小説データのユニークな単語リスト
unique_words = sorted(list(set(words)))
print('ユニーク単語数 : ', len(unique_words))
## ユニークな単語リスト unique_words をインデックスとするディクショナリ
word_indices = dict((word, unique_words.index(word))
for word in unique_words)
## 単語をベクトル化(One-Hot-Encoding)
print('ベクトル化...')
x = np.zeros((len(sentences), maxlen, len(unique_words)), dtype=np.bool)
y = np.zeros((len(sentences), len(unique_words)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, word in enumerate(sentence.split(' ')):
x[i, t, word_indices[word]] = 1
y[i, word_indices[next_word[i]]] = 1
RNN の予測モデル
ベクトル化した文字列より次の単語を予測するモデルを RNN(LSTM)で作成します。
直前の4単語から次ぎに来る単語を生成します。今回は最初の単語を生成するため、テキストの始めの4単語を事前に指定し、その後の100単語を生成します。
テキストの始めの4単語を「今日の天気は」とします。
予測モデルを構築
予測モデルは、入力層(単一の LSTM 層)と出力層の2層のニューラルネットワークです。
また、目的値は One-Hot-Encoding で表現されるカテゴリカルであるため、損失関数は categorical_crossentropy を使用しています。
## 次の文字を予測する単層 LSTM モデル
from keras import layers
model = keras.models.Sequential()
model.add(layers.LSTM(128, input_shape=(maxlen, len(unique_words))))
model.add(layers.Dense(len(unique_words), activation='softmax'))
## モデルのコンパイル設定
optimizer = keras.optimizers.RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
テキストを生成
訓練毎にテキストを生成します。今回は訓練回数を100回とし、1回目と50回目、100回目で生成されたテキストを比較します。
## モデルの予測に基づいて次の単語をサンプリングする関数
## スコアが最も高い単語を単純に選択するのではなく、ある程度のスコアからランダムに選択
## temperature が大きいと選択の幅が広がり、小さいと狭まる
def sample(preds, temperature=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
## テキスト生成ループ
for epoch in range(1, epochs+1):
print('学習回数 : ', epoch)
## 訓練毎にモデルを作成
model.fit(x, y,
batch_size=128,
epochs=1)
generated_text = first_sentences
sys.stdout.write(generated_text.replace(' ', ''))
## generate_count 個の単語を生成
for i in range(generate_count):
sampled = np.zeros((1, maxlen, len(unique_words)))
for t, word in enumerate(generated_text.split(' ')):
sampled[0, t, word_indices[word]] = 1.
preds = model.predict(sampled, verbose=0)[0]
next_index = sample(preds, temperature)
next_word = unique_words[next_index]
generated_text += ' ' + next_word
generated_text = ' '.join(generated_text.split(' ')[1:])
sys.stdout.write(next_word)
sys.stdout.flush()
## 改行
print()
生成したテキスト
以下は、学習回数別(1回・50回・100回)に生成したテキストとなります。
学習回数が100回と1回では大差はなさそう。
学習回数 1回
今日の天気はもうさ。五も云うの南の方が、高く持って乗って行ってやっぱりありました。「そう鳥。いま一中を今年たと窓のように、よりも行くんです声又コップと思って行ってしていますだっ」なけ人も、日から、どんどん五か切符」、そうようにまたぁいけないからもうになって、大きなちまうれてこっちへも思いました。そしてすぐは手をすきとおってはじ
学習回数 50回
今日の天気はくるたちのままからだ何三なら来て、「いて……。」がたがたがたがたふるへだして、もうばかりだで、二もういきなり海からいるのさよなら。まったくすると中から巨通ってたの前の行った、僕にもいくらでもいいおさああってお僕の海から手にわかに」カムパネルラはところが着たそっと大もうこの「いように思いました。あれでかけとこなったのかいのジョバンニはつくもっと
学習回数 100回
今日の天気は東京をはから鳴りなって俄傘にああお前たちのお父さんとやのインデアンのは又せなそらを少し見てううなって、いつもの栗だから鷺向うの室と中犬書いてありました。ジョバンニは、そら窓だまっ下のにわかにや天の川の岸ましたが、大循環は、ステーションまるで、は来る僕たちは二二三耕一次の僕一生けん命八たずつもなら、もう少しほんとうに見てある
今後(精度向上に向けて)
小説3冊で学習回数が100回くらいでは、まともな日本語にはほど遠い結果となっています。
Wikipediaなど大量のテキストを学習すると、日本語らしくなるかもしれません。