前に、お手元のマシンとスパコンを比較する方法と言うなんともアホっぽい記事を書いた。
ついでに、awsのg2インスタンスを使ってGPUの評価をしたらどうかという趣旨で、AWS-GPUとスパコンを比較する方法という記事を書いた。その時はg2インスタンスだったが、最近、AWSでp2インスタンスという新しいGPUインスタンスが追加された。ついでなので、こちらでも評価してみよう。
先の記事と同じように、LINPACKベンチマークをaws p2インスタンス(CUDA)で動かしてみる。
スパコンは、メモリもストレージもネットワーク性能も段違いに高性能なので、真に受けないように。
ベンチマークの内容を詳しく分かっているわけではないので、間違っているかも知れない。
多くの仕組みは、前回の記事AWS-GPUとスパコンを比較する方法を参考にしている。
AWS p2.xlargeでLINPACK ベンチマークを動かす。
という訳で、AWSで最もCPUが早そうなマシンを使って、スパコンと性能の比較をしてみる。
今回使用したマシンはこちら
p2.xlarge
| モデル | vCPU | メモリ | GPU |
|---|---|---|---|
| p2.xlarge | 4core | 62GB | 1 |
4992 NVIDIA CUDA cores with a dual-GPU design
Up to 2.91 Teraflops double-precision performance with NVIDIA GPU Boost - See more at: http://www.nvidia.com/object/tesla-k80.html#sthash.K2miMs1X.dpuf
LINPACKベンチマーク環境の構築
CUDA実行環境の構築は結構大変だ。
AWS-GPUとスパコンを比較する方法を参考にする
linpackプログラムの準備
https://devtalk.nvidia.com/default/topic/819284/linpack-benchmark-for-cuda/
こちらを参考。CUDA Registered Developer Programというのに入って、上のリンク
https://developer.nvidia.com/rdp/assets/cuda-accelerated-linpack-linux64
こちらから、hpl-2.0_FERMI_v15.tgzを手に入れる。
インスタンス立ち上げ
nvidiaが用意しているCUDAドライバーが事前に入っている環境を利用する。
AWS marketplaceで「grid」で検索すると出てくる

Amazon Linux AMI with NVIDIA GRID GPU Driverを利用する。
オレゴンにしか無かったので、AMI ID amzn-ami-graphics-hvm-2016.09.0.20161028-x86_64-ebs-d3fbf14b-243d-46e0-916c-82a8bf6955b4-ami-0d38601a.3 (ami-caf253aa) を利用。
初期設定
次のものを入れる
sudo yum groupinstall -y "Development Tools"
sudo yum install -y emacs
sudo yum install -y tmux
sudo yum install -y openmpi openmpi-devel
sudo ln -s /opt/nvidia/cuda /usr/local/cuda
INTEL MKLを利用する。
次のページからインテルのMath Libraryを取得する。ついでに利用するシリアルナンバーを用意する。
https://software.intel.com/en-us/qualify-for-free-software
登録すると、シリアルナンバーを送ってくれるのでそれを用意する。
l_mkl_2017.0.098.tgzなどが、手に入るので、展開して install.shを実行する。対話的なやり取りを(その際シリアルナンバーを打ち込む)する。シリアルナンバーを打ち込む以外は、エンターを押せばOK.展開時に、silent.cfgが展開されるのでそちらを設定してもよい。やり方はこちら。
シリアル番号は、Math Kernelのバージョンが変わると変えなければならないようだ。
デフォルトで、/opt/intel以下にインストールされる。
LINPACKベンチマークの作成
関係するものはこちら。
hpl-2.0_FERMI_v15.tgz展開
hpl-2.0_FERMI_v15.tgzを展開する。
どこでも良いが、/home/ec2-user/以下に展開する(以下、それを前提とする)。
[ec2-user@ip-xxx-xxx-xxx-xxx hpl-2.0_FERMI_v15]$ ls
bin HISTORY Make.CUDA makes setup TUNING
BUGS include Make.CUDA~ Make.top src www
COPYRIGHT INSTALL Make.CUDA.org man testing
CUDA_LINPACK_README.txt lib Makefile README TODO
環境設定の作成
~/.bashrcに以下を追加
# User specific aliases and functions
export LD_LIBRARY_PATH=/opt/intel/mkl/lib/intel64:/opt/intel/compilers_and_libra
ries/linux/lib/intel64:/home/ec2-user/hpl-2.0_FERMI_v15/src/cuda:/usr/lib64/open
mpi/lib:/opt/intel/compilers_and_libraries_2017.0.098/linux/compiler/lib/intel64
_lin
export PATH=/usr/lib64/openmpi/bin:$PATH
[ec2-user@ip-10-0-0-192 ~]$
前回との違いは、/opt/intel/compilers_and_libraries_2017.0.098/linux/compiler/lib/intel64_linを追加したことだ。
source ~/.bashrc
Make.CUDAの編集
殆どはMake.CUDAの編集をすれば良い
サンプルはこちら
上を編集して、前回との違いは、
LAMP5dir= /opt/intel/compilers_and_libraries_2017.0.098/linux/compiler/lib/intel64_lin
を追加したことにある。
make
を実行すれば、bin/CUDAにxhplが出来上がる.lddでsoへのパスが通っているか確認してください。
run_linpackの編集
bin/CUDA以下にあるrun_linpackの編集を行なう
# location of HPL
HPL_DIR=/home/ec2-user/hpl-2.0_FERMI_v15
と
CPU_CORES_PER_GPU=4
にする。GPUが一つで、CPUが4つなので4を指定する。
HPL.datの編集
ベンチマークはHPL.datの編集を行なう。そのままでは動かない。PsとQsを1に指定する。
サンプルはこちらにある
2 # of problems sizes (N)
65536 81920 100000 110000 160000 180000 39007 39000 20960 364160 359424 276480 138240 115200 23040 354432 236160 95040 9600 20737 16129 16128 Ns
2 # of NBs
768 1536 640 768 896 960 1024 1152 1280 384 640 960 768 640 256 960 512 768 11\52 NBs
上の2は、65536 81920までやるという意味っぽい
4は768 1536までやるという意味だ。
最適な場所を探すと、GFlopsの最適値がわかると思う。
LINPACKベンチ実行
mpirun -np 1 -host localhost ./run_linpack
と実行すれば、ベンチマークが走る
実行結果
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 65536 768 1 1 242.50 7.738e+02
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0038208 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 65536 1536 1 1 235.32 7.975e+02
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0043131 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 81920 768 1 1 449.06 8.162e+02
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0040796 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 81920 1536 1 1 454.85 8.058e+02
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0047358 ...... PASSED
================================================================================
長いので省略した。全部の結果はこちらのgistにある .
結果を見ると、800GFlops位になりそうだ。実際のところGPUには余力がありそうだが、Nが8万を超えたあたりで、メインメモリーが、パンクしてしまった。理論値では、2.91TFlopsまで行くはずなので、メモリが許せばまだ性能が出るとおもわれる。
ちなみに、その時にGPUの使用率はこんなもん。nvidea-smiで状態を把握する。
$nvidia-smi -q -d UTILIZATION -l
CPUだけの場合
GPUを使わず、CPUだけの場合どの程度のGFlopsが出るのか?
run_linpackで次の設定をする。CUDA_DGEMM_SPLITで0.0を設定する。
# hint: for 2050 or 2070 card
# try 350/(350 + MKL_NUM_THREADS*4*cpu frequency in GHz)
export CUDA_DGEMM_SPLIT=0.00
# hint: try CUDA_DGEMM_SPLIT - 0.10
export CUDA_DTRSM_SPLIT=0.00
実行結果
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 32032 512 1 1 307.91 7.117e+01
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0046919 ...... PASSED
================================================================================
CPUだけだと。71GFlops
p2.xlargeのcpuはIntel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHzが4coreだ。
E5-2686そのものの資料は無いが、こちらの資料より大体、理論値では211GFlopsあることになる。計測値では、71GFlopsなので大体33%程度だと思われる。

追記、p2.8xlargeでも試してみる
上の例では、p2.xlargeで試した。そちらはGPUはⅠつだ。GPUを増やしてみたらどうなるか試した。
p2インスタンスは、p2.xlargeの他にp2.8xlarge(8GPU),p2.16xlarge(16GPU)のインスタンスがある。p2.8xlargeで試してみた。
p2.8xlargeのスペックはこちら。
| モデル | vCPU | メモリ | GPU | GPUメモリ |
|---|---|---|---|---|
| p2.8xlarge | 32core | 488GB | 8 | 96GB |
4992 NVIDIA CUDA cores with a dual-GPU design
Up to 2.91 Teraflops double-precision performance with NVIDIA GPU Boost - See more at: http://www.nvidia.com/object/tesla-k80.html#sthash.K2miMs1X.dpuf
とのことなので、2.91*8=24TFlopsが最大なのかしら。
p2.xlargeと変更した点
processが一つだと、1つのGPUしか使わない。また、HPLのPsとQsも1x1と指定しなければならなかった。しかし、今回は8つのGPUがあるので次のように指定した。
mpirun -np 8 -host localhost ./run_linpack
プロセス数は8にした。また、HPL.datは以下のように変更
0 PMAP process mapping (0=Row-,1=Column-major)
1 # of process grids (P x Q)
2 Ps
4 Qs
16.0 threshold
Ps=2 x Qs=4 => 8 なのでmpirun -np 8 を指定すれば、8つのGPUに分割して計算してくれるようだ。
8つのGPUが動いているのはnvidia-smi -l を見ると、きちんと動いているのがわかる。
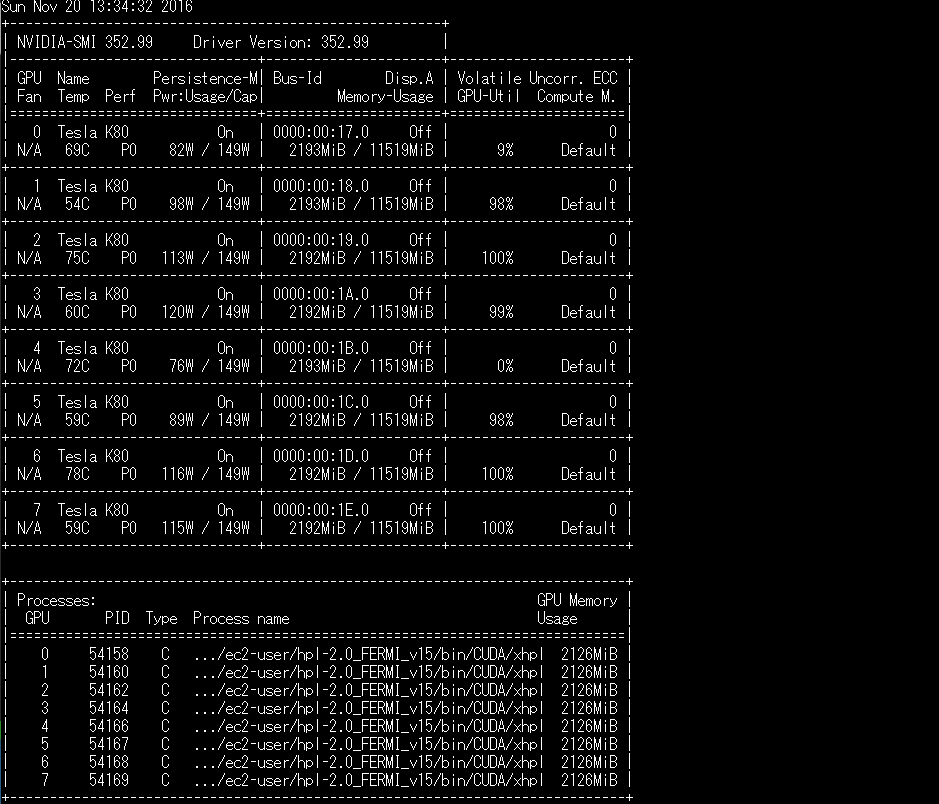
p2.8xlargeでのLinpackを動かした結果
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 65536 768 2 4 126.13 1.488e+03
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0030666 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 65536 1536 2 4 106.63 1.760e+03
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0033980 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 65536 2048 2 4 90.45 2.075e+03
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0032682 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 81920 768 2 4 231.72 1.582e+03
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0029593 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 81920 1536 2 4 184.96 1.982e+03
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0031443 ...... PASSED
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR10L2L4 81920 2048 2 4 151.98 2.412e+03
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0030877 ...... PASSED
================================================================================
ついに、2,412GFlops = 2.4TeraFlopsになった。2TFlopsを超えると、なんかスパコン感ある。ちなみに、macbookでやったときには、37GFlopsなので、GPUを活用することでおよそ65倍位早くなる。
benchmarkの詳細はこちら。
16年前のスパコンと肩を並べる
上の例で、Linpackのベンチマークで、2412GFlopsが出た。これは何かと比較可能だろうか?スーパーコンピュータの世界では、半年に一度、top500と言って、スパコンの早い順位500位までリスト化している。調べてみたら、ちょうど2000年の6月のリストの1位が、Sandia National Laboratories(US)で、システムが、ASCI Redで、その時の計算スピードが、2375GFlopsで大体近いのではないかと思った。つまり、大体16年前のスパコンレベルの計算能力をアマゾンでも借りることが出来るようになったのだろう(あくまでCUDAとかGPUを使ってそのくらいの演算性能になったというだけで、メモリとかストレージとかその他の信頼性はぜんぜん違うので、あまりまにうけないように)。
NBs(BlockSize)について
NBsを大きくしていったら早くなったので、欲をかいて、NBsを4096まで行けないか試してみた。
| N | NBs | GFlops |
|---|---|---|
| 65536 | 4096 | 1437 |
| 65536 | 3072 | 1993 |
| 65536 | 2048 | 2162 |
| 65536 | 1536 | 2079 |
| 65536 | 768 | 1482 |
となり、NBsの値は、2048が一番成績が良かった。なんでも欲をかくとだめですね。
関連エントリー
AWSとスパコンを比較する方法-スパコン用ベンチマークソフトを動かしてみる
お手元のマシンとスパコンを比較する方法-スパコン用ベンチマークソフトを動かしてみる
AWS-GPUとスパコンを比較する方法