はじめに
CPUのメニーコア化が止まらない。CPUクロックを上げての性能向上が難しくなったので、各CPUメーカは、メニーコア化で性能を上げる方向を模索している。
ARMはそのような競争のフロントランナーを務めている。
例えば、64coreのserver用ARMプロセッサーなどが出てきている。
そのような中で、Packetという会社が、東京リージョンで、ARM 96コアのクラウドサービスを始めたので、実際メニーコアがどのような性能が出るか試してみた。今までも、東京リージョン以外でARM coreを利用したクラウドサービスはあったが、ヨーロッパなどで、レイテンシが大きくて、使いにくかった。
使用マシン
今回使用したのは、Packetという会社のARMサーバクラウドサービス。ベアメタルで、96コアのマシンを一時間0.5ドルで利用できる。
サーバの性能はこんな感じだ
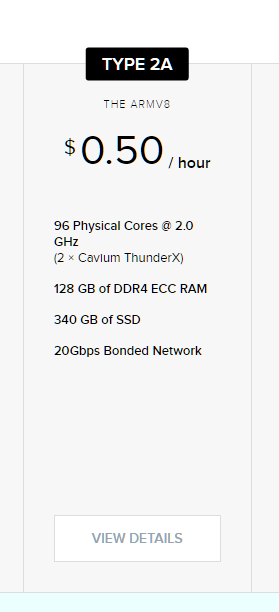
ARMv8 96core 128GB RAM 340GB SSD 20Gbps
という性能だ。
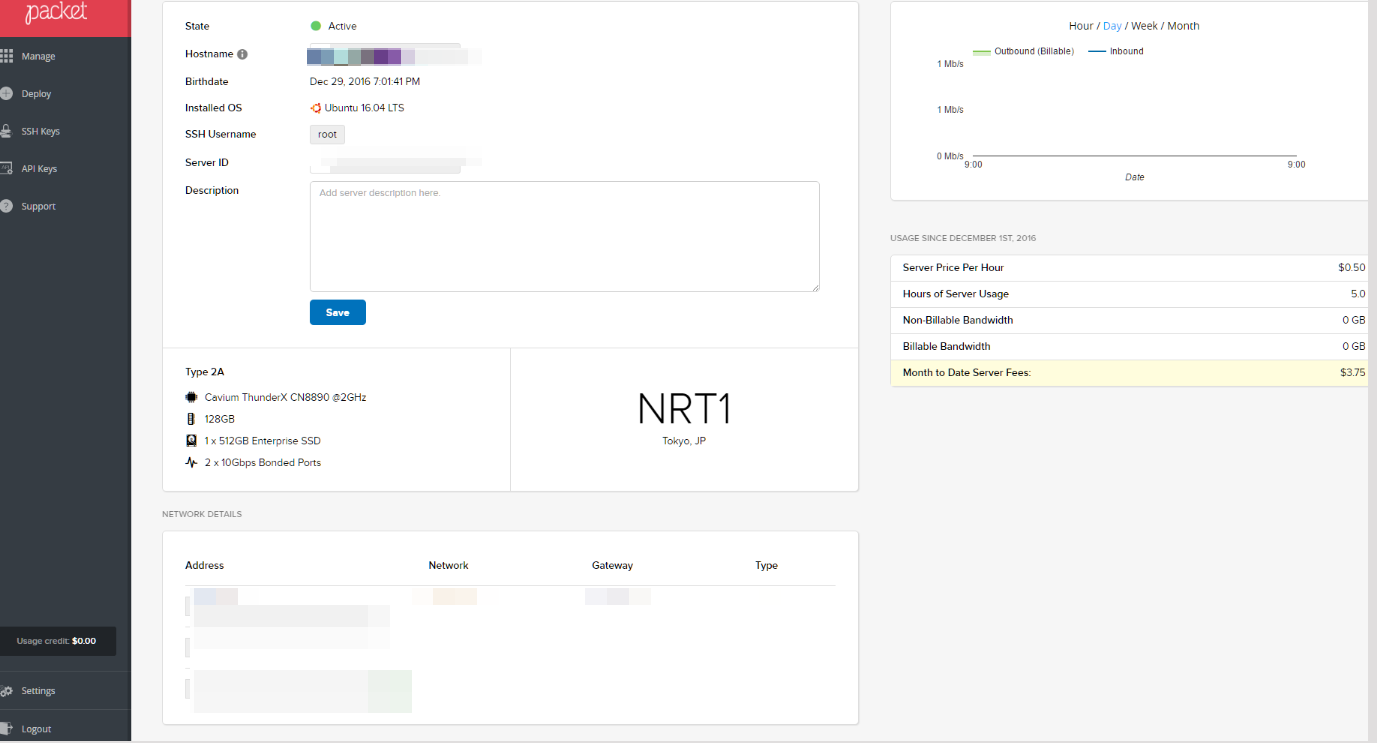
マシンをデプロイする
マシンをデプロイする。server typeはType2Aを選ぶ。deployして暫く待つと、使えるようになる。rootでのログインにはssh-keyが必要で、公開鍵をセットする。
FFMPEGで性能を試してみる。
メニーコアの性能を測るのに、重めの処理が良いだろうと思って、ffmpegで性能を測ってみる。
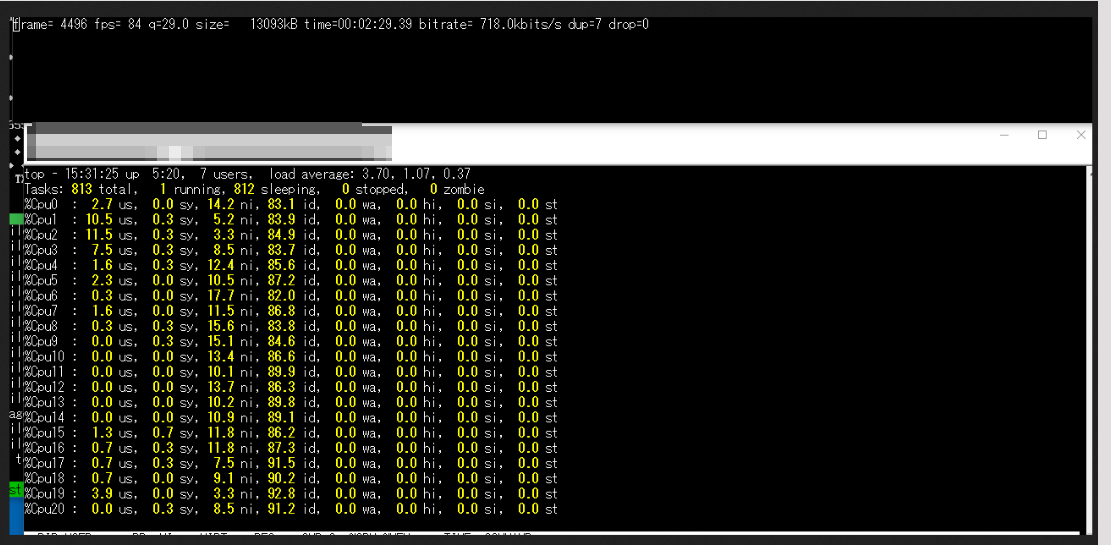
96コアあるので、threadsを96にしてみた。
ffmpeg -i input.wmv -threads 96 -movflags faststart -vcodec libx264 -strict -2 output.mp4
しかし、あまり効率的に処理してくれていないようだ。fpsは81後半。29フレームが一秒なので、大体3倍速程度の速度だ。
UnixBenchを動かしてみる
ざっくり性能を見るため、UnixBenchを動かしてみる。
UnixBenchに関してはこちらが詳しい。
BYTE UNIX Benchmarks (Version 5.1.3)
System: test-armcpu.local.lan: GNU/Linux
OS: GNU/Linux -- 4.4.0-38-generic -- #57-Ubuntu SMP Wed Sep 7 10:19:14 UTC 2016
Machine: aarch64 (aarch64)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
05:03:55 up 18:53, 1 user, load average: 0.29, 0.08, 0.02; runlevel 2016-12-29
------------------------------------------------------------------------
Benchmark Run: Fri Dec 30 2016 05:03:55 - 05:32:01
96 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 8682902.1 lps (10.0 s, 7 samples)
Double-Precision Whetstone 1781.5 MWIPS (10.1 s, 7 samples)
Execl Throughput 1332.9 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 241588.1 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 64547.6 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 624856.5 KBps (30.0 s, 2 samples)
Pipe Throughput 465766.8 lps (10.0 s, 7 samples)
Pipe-based Context Switching 89913.6 lps (10.0 s, 7 samples)
Process Creation 2217.6 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 3348.3 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1426.2 lpm (60.0 s, 2 samples)
System Call Overhead 1042283.3 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 8682902.1 744.0
Double-Precision Whetstone 55.0 1781.5 323.9
Execl Throughput 43.0 1332.9 310.0
File Copy 1024 bufsize 2000 maxblocks 3960.0 241588.1 610.1
File Copy 256 bufsize 500 maxblocks 1655.0 64547.6 390.0
File Copy 4096 bufsize 8000 maxblocks 5800.0 624856.5 1077.3
Pipe Throughput 12440.0 465766.8 374.4
Pipe-based Context Switching 4000.0 89913.6 224.8
Process Creation 126.0 2217.6 176.0
Shell Scripts (1 concurrent) 42.4 3348.3 789.7
Shell Scripts (8 concurrent) 6.0 1426.2 2377.0
System Call Overhead 15000.0 1042283.3 694.9
========
System Benchmarks Index Score 517.6
------------------------------------------------------------------------
Benchmark Run: Fri Dec 30 2016 05:32:01 - 06:03:57
96 CPUs in system; running 96 parallel copies of tests
Dhrystone 2 using register variables 827115140.6 lps (10.0 s, 7 samples)
Double-Precision Whetstone 170085.3 MWIPS (10.2 s, 7 samples)
Execl Throughput 9013.4 lps (29.7 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 394697.2 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 99702.0 KBps (30.1 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1377211.3 KBps (30.0 s, 2 samples)
Pipe Throughput 41446654.1 lps (10.0 s, 7 samples)
Pipe-based Context Switching 1015846.3 lps (10.0 s, 7 samples)
Process Creation 13796.1 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 30894.5 lpm (60.1 s, 2 samples)
Shell Scripts (8 concurrent) 4049.4 lpm (60.5 s, 2 samples)
System Call Overhead 822014.2 lps (10.1 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 827115140.6 70875.3
Double-Precision Whetstone 55.0 170085.3 30924.6
Execl Throughput 43.0 9013.4 2096.1
File Copy 1024 bufsize 2000 maxblocks 3960.0 394697.2 996.7
File Copy 256 bufsize 500 maxblocks 1655.0 99702.0 602.4
File Copy 4096 bufsize 8000 maxblocks 5800.0 1377211.3 2374.5
Pipe Throughput 12440.0 41446654.1 33317.2
Pipe-based Context Switching 4000.0 1015846.3 2539.6
Process Creation 126.0 13796.1 1094.9
Shell Scripts (1 concurrent) 42.4 30894.5 7286.4
Shell Scripts (8 concurrent) 6.0 4049.4 6749.1
System Call Overhead 15000.0 822014.2 548.0
========
System Benchmarks Index Score 3991.5
EC2と比較してみる。
armサーバの実力を図るためにEC2の各マシンと比較した。
EC2はarmサーバがないので、コア数の多いxeonサーバや、価格帯の近いサーバと比較してみる。
64core xeon(x86_64)と比較した。
EC2のマシンと比較した。
比較マシンは、
m4.16xlarge
スペックは
| マシン名 | cpu core | ECU | memory(GBi) | HDD | 価格 |
|---|---|---|---|---|---|
| m4.16xlarge | 64 | 188 | 256 | 8GB/SDD | $4.45 /1 時間 |
となる。ec2では、最もCPUが多いマシンを選んだ。
ffmpegで比較する
大体10倍速程度で、エンコードしている。
ffmpegはCPUがボトルネックになっているわけではなさそうだ。
少なくとも、マルチコアを全て使い切るようなことはなかった。
spframe=174885 fps=308 q=29.0 size= 590515kB time=01:37:14.57 bitrate= 829.1kbits/s dup=418 drop=0 speed=10.3x
unix benchで測った
=======================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: ip-10-0-0-100: GNU/Linux
OS: GNU/Linux -- 4.4.0-53-generic -- #74-Ubuntu SMP Fri Dec 2 15:59:10 UTC 2016
Machine: x86_64 (x86_64)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
CPU 0: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 1: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 2: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 3: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 4: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 5: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 6: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 7: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 8: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 9: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 10: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
CPU 11: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz (4600.1 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
..中略
------------------------------------------------------------------------
Benchmark Run: Fri Dec 30 2016 06:47:26 - 07:15:32
64 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 31339027.4 lps (10.0 s, 7 samples)
Double-Precision Whetstone 3854.6 MWIPS (9.8 s, 7 samples)
Execl Throughput 2149.6 lps (29.7 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 1070566.1 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 285762.6 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 3329653.8 KBps (30.0 s, 2 samples)
Pipe Throughput 2092745.4 lps (10.0 s, 7 samples)
Pipe-based Context Switching 55210.1 lps (10.0 s, 7 samples)
Process Creation 3169.1 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 8362.3 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 5731.3 lpm (60.0 s, 2 samples)
System Call Overhead 3320152.8 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 31339027.4 2685.4
Double-Precision Whetstone 55.0 3854.6 700.8
Execl Throughput 43.0 2149.6 499.9
File Copy 1024 bufsize 2000 maxblocks 3960.0 1070566.1 2703.4
File Copy 256 bufsize 500 maxblocks 1655.0 285762.6 1726.7
File Copy 4096 bufsize 8000 maxblocks 5800.0 3329653.8 5740.8
Pipe Throughput 12440.0 2092745.4 1682.3
Pipe-based Context Switching 4000.0 55210.1 138.0
Process Creation 126.0 3169.1 251.5
Shell Scripts (1 concurrent) 42.4 8362.3 1972.2
Shell Scripts (8 concurrent) 6.0 5731.3 9552.2
System Call Overhead 15000.0 3320152.8 2213.4
========
System Benchmarks Index Score 1409.3
------------------------------------------------------------------------
Benchmark Run: Fri Dec 30 2016 07:15:32 - 07:44:01
64 CPUs in system; running 64 parallel copies of tests
Dhrystone 2 using register variables 1221091536.5 lps (10.0 s, 7 samples)
Double-Precision Whetstone 216598.1 MWIPS (10.0 s, 7 samples)
Execl Throughput 35869.1 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 573922.7 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 136692.2 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1854326.6 KBps (30.0 s, 2 samples)
Pipe Throughput 75118109.6 lps (10.0 s, 7 samples)
Pipe-based Context Switching 5722744.1 lps (10.0 s, 7 samples)
Process Creation 45984.7 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 143643.6 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 19149.4 lpm (60.1 s, 2 samples)
System Call Overhead 3478749.7 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 1221091536.5 104635.1
Double-Precision Whetstone 55.0 216598.1 39381.5
Execl Throughput 43.0 35869.1 8341.7
File Copy 1024 bufsize 2000 maxblocks 3960.0 573922.7 1449.3
File Copy 256 bufsize 500 maxblocks 1655.0 136692.2 825.9
File Copy 4096 bufsize 8000 maxblocks 5800.0 1854326.6 3197.1
Pipe Throughput 12440.0 75118109.6 60384.3
Pipe-based Context Switching 4000.0 5722744.1 14306.9
Process Creation 126.0 45984.7 3649.6
Shell Scripts (1 concurrent) 42.4 143643.6 33878.2
Shell Scripts (8 concurrent) 6.0 19149.4 31915.6
System Call Overhead 15000.0 3478749.7 2319.2
========
System Benchmarks Index Score 10032.8
同じ価格帯のEC2のマシンと比較した。
比較マシンは、
c4.2xlarge
スペックは
| マシン名 | cpu core | ECU | memory(GBi) | HDD | 価格 |
|---|---|---|---|---|---|
| c4.2xlarge | 8 | 31 | 15 | 20GB/SDD | $0.504 /1 時間 |
となる。ec2では、packetのtype2aと同じ価格帯で比較してみた。
ffmpegで比較した
大体8倍速くらいの速度が出ている。
上に書いたようにFFMPEGはCPUがボトルネックにはなっていない。
frame=17502 fps=251 q=29.0 size= 49055kB time=00:09:43.47 bitrate= 688.7kbits/s dup=7 drop=0 speed=8.37x
unixbenchで比較した。
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: ip-10-0-0-199: GNU/Linux
OS: GNU/Linux -- 4.4.0-53-generic -- #74-Ubuntu SMP Fri Dec 2 15:59:10 UTC 2016
Machine: x86_64 (x86_64)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
CPU 0: Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz (5800.2 bogomips)
CPU 7: Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz (5800.2 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET
07:07:41 up 25 min, 2 users, load average: 0.14, 0.06, 0.02; runlevel 2016-12-30
------------------------------------------------------------------------
Benchmark Run: Fri Dec 30 2016 07:07:41 - 07:35:48
8 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 37937899.2 lps (10.0 s, 7 samples)
Double-Precision Whetstone 4028.9 MWIPS (9.9 s, 7 samples)
Execl Throughput 4760.6 lps (30.0 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 1235666.5 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 324666.9 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 2811474.4 KBps (30.0 s, 2 samples)
Pipe Throughput 2522248.3 lps (10.0 s, 7 samples)
Pipe-based Context Switching 50076.1 lps (10.0 s, 7 s[33/162]
Process Creation 11259.3 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 13532.2 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 5102.8 lpm (60.0 s, 2 samples)
System Call Overhead 3961884.2 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 37937899.2 3250.9
Double-Precision Whetstone 55.0 4028.9 732.5
Execl Throughput 43.0 4760.6 1107.1
File Copy 1024 bufsize 2000 maxblocks 3960.0 1235666.5 3120.4
File Copy 256 bufsize 500 maxblocks 1655.0 324666.9 1961.7
File Copy 4096 bufsize 8000 maxblocks 5800.0 2811474.4 4847.4
Pipe Throughput 12440.0 2522248.3 2027.5
Pipe-based Context Switching 4000.0 50076.1 125.2
Process Creation 126.0 11259.3 893.6
Shell Scripts (1 concurrent) 42.4 13532.2 3191.6
Shell Scripts (8 concurrent) 6.0 5102.8 8504.6
System Call Overhead 15000.0 3961884.2 2641.3
========
System Benchmarks Index Score 1814.3
------------------------------------------------------------------------
Benchmark Run: Fri Dec 30 2016 07:35:48 - 08:04:03
8 CPUs in system; running 8 parallel copies of tests
Dhrystone 2 using register variables 181957395.9 lps (10.0 s, 7 samples)
Double-Precision Whetstone 28834.7 MWIPS (10.1 s, 7 samples)
Execl Throughput 24877.1 lps (30.0 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 1017540.2 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 262280.2 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 3001543.0 KBps (30.0 s, 2 samples)
Pipe Throughput 11182536.5 lps (10.0 s, 7 samples)
Pipe-based Context Switching 1433581.8 lps (10.0 s, 7 samples)
Process Creation 51219.6 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 52181.9 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 6904.3 lpm (60.0 s, 2 samples)
System Call Overhead 9072987.3 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 181957395.9 15591.9
Double-Precision Whetstone 55.0 28834.7 5242.7
Execl Throughput 43.0 24877.1 5785.4
File Copy 1024 bufsize 2000 maxblocks 3960.0 1017540.2 2569.5
File Copy 256 bufsize 500 maxblocks 1655.0 262280.2 1584.8
File Copy 4096 bufsize 8000 maxblocks 5800.0 3001543.0 5175.1
Pipe Throughput 12440.0 11182536.5 8989.2
Pipe-based Context Switching 4000.0 1433581.8 3584.0
Process Creation 126.0 51219.6 4065.0
Shell Scripts (1 concurrent) 42.4 52181.9 12307.1
Shell Scripts (8 concurrent) 6.0 6904.3 11507.2
System Call Overhead 15000.0 9072987.3 6048.7
========
System Benchmarks Index Score 5675.9
まとめ
armのメニーコアを試用して、EC2のマシンと比較してみた。
xeonのマシンよりは少し遅いような気がしたが、それでもメニーコア(96コア)は魅力的なギミックだ。
手軽にメニーコアを試せる環境が東京にあるのは良いと感じた。