実行環境
Windows11
python 3.11.7
matplotlib 3.8.2
pandas 2.2.0
numpy 1.26.4
はじめに
2次元の pd.DataFrame の何行目の何列目に最大値があるのかを調べます。
少し詳しく書いています。
ケーススタディとして、matplotlib の imshow() でヒートマップをつくり、最大値をアノテーション表示してみます。
ゴールのイメージです。
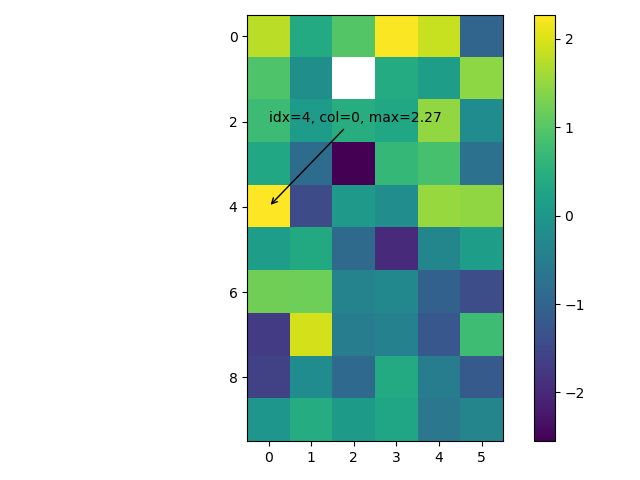
こちらのコードで出力しています。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(0)
df = pd.DataFrame(np.random.randn(10, 6))
# サンプルとして意図的に欠損値を混ぜています
df.iloc[1, 2] = np.nan
# 最大値の行番号と列番号を取得
idx, col = np.unravel_index(
indices=df.fillna(-np.inf).values.argmax(),
shape=df.shape
)
# 最大値を取得
max_df = df.iloc[idx, col]
# ヒートマップ
fig, ax = plt.subplots(tight_layout=True)
im = ax.imshow(df)
ax.annotate(
f'idx={idx}, col={col}, max={round(max_df, 3)}',
xy=(col, idx),
xytext=(col, idx - 2),
arrowprops={'arrowstyle': '->'}
)
fig.colorbar(im)
fig.savefig('heatmap.png')
本記事では、位置、インデクス、何行目、何列目という言葉は 0 始まりの数え方で使っています。
pandas だけで処理する場合
pd.DataFrame の処理なので pandas で完結させたいのですが、pandas には専用の関数やメソッドはないみたいです。
df.idxmax() というメソッドを使うと最大値が属する行を特定できますが、この処理は各列に対してそれぞれ働きます。
つまり、行列の中での最大値の位置を知りたいのに、各列の最大値の位置までしか取得できないということです。
とはいえ、たとえば以下のようにすることで、df.idxmax() でも最大値の属する列名と行名を取得することはできます。
col_name = df[df == df.max()].max().idxmax()
idx_name = df.T[df.T == df.T.max()].max().idxmax()
確認用コードです。
import numpy as np
import pandas as pd
np.random.seed(0)
df = pd.DataFrame(np.random.randn(10, 6))
col_name = df[df == df.max()].max().idxmax()
idx_name = df.T[df.T == df.T.max()].max().idxmax()
max_df = df.loc[idx_name, col_name]
print(f'idx={idx_name}, col={col_name}, max={round(max_df, 3)}')
# idx=4, col=10, max=2.27
慣れている人はこれでもいいかもしれないし、もっと簡潔な書き方があるかもしれません。
チェインメソッドを分解して関数化することで、より明確に意図を伝えられるコードになるかもしれません。
ただ少なくとも私の場合は、これだと一見して何をしているかが分かりにくく、分解するにしてもやや回りくどく思いました。
ということで、pandas だけでなんとかするよりも、他の方法を探すことにしました。
np.unravel_index()
numpy の unravel_index() という関数を使う方法がポピュラーなようです。
numpy.unravel_index(indices, shape, order='C')
1次元配列に対するインデクスを、多次元配列での位置に変換してくれる関数です。
今回のケースでいうと、ヒートマップにする2次元配列を仮に1次元に平坦化したとき、最大値が1次元配列のなかの何番目にあるかを指定すれば、もとの2次元配列だと何行目何列目になるかが調べられます。
np.ravel() という関数があって、これは配列を1次元に平坦化する関数ですが、np.unravel_index() は逆方向の多次元化の処理になります。
このようにとらえて関数名を日本語にすると、インデクスを多次元化する、となりイメージどおりです。
引数は3つです。
引数 indices : array_like
index の複数形 indices が引数名になっています。
平坦化した配列で考えたときのインデクスを指定します。
調べるインデクスが1つのときは、値を直接指定できます。
今回は、最大値の位置を、平坦化した配列のインデクスで指定することになります。
もし最大だけでなくトップ5も調べたいのであれば、平坦化した配列でのトップ1から5までの位置のインデクスをリスト等で指定することになります。
numpy 1.6.0 以前は、1つのインデクスの指定しか受け付けない仕様となっています。
後述しますが、2次元配列を1次元配列に平坦化してその中の最大値のインデクスを取得するためには、np.ndarray.argmax() メソッドを使います。
引数 shape : tuple of ints
もとの配列の形状を指定します。
numpy 1.16.0 以前は、dims という引数名です。
引数 order : {'C', 'F'}, optional
Fortran スタイルで行列のインデクスを指定したい場合に 'F' を指定できます。
numpy 1.6.0 で導入されました。
戻り値 unraveled_coords : tuple of ndarray
多次元にしたときの座標、つまり各軸でのインデクスが返ってきます。
もとの2次元配列のなかの1点を indices に指定した場合は、行番号と列番号が返ります。
indices に5つの点を指定した場合は、行番号を5つ格納した ndarray と、列番号を5つ格納した ndarrayが返ります。
np.ndarray.argmax()
先述の np.unravel_index() の引数 indices の指定に使います。
numpy.argmax(a, axis=None, out=None, *, keepdims=)
関数とメソッドの両方があります。
ndarray の最大値の位置を取得できます。
Examples のところに、多次元配列のなかの最大値の位置の求め方が np.unravel_index() を使う形でずばり載ってます。
引数は4つですが、メソッドとして使う分には引数指定なしでも使えます。
引数 a : array_like
関数として使う場合は、ここに配列を指定します。
引数 axis : int, optional
各軸に対してそれぞれ処理したいときに指定します。
指定しない場合は、配列は1次元に平坦化されます。
引数 out : array, optional
結果を置き換えたい場合は、ここにその器となる配列を指定します。
配列の形状が一致している必要があります。
引数 keepdims : bool, optional
出力の次元を入力の次元と揃えたいときは True を指定します。
numpy 1.22.0 で導入されました。
戻り値 index_array : ndarray of ints
axis を指定しなかった場合は、平坦化した配列での最大値のインデクスが返ります。
axis を指定した場合は、軸に対して集約処理をしたということで、その分の次元が減った配列に各軸の最大値のインデクスが格納されて返ります。
keepdims が True のときは、次元が維持されます。
注意点
1つ目は、リファレンスの Notes にあるとおり、最大値が複数あるときは最初にヒットした要素だけで処理されます。
それ以降の最大値タイのインデクスを取得したいときは、何かしら別の工夫が必要です。
2つ目は、リファレンスに直接載ってないですが、配列の中に欠損値が含まれる場合、最大値ではなく最初の欠損値がヒットします。
df.idxmax() の skipna のような指定はできません。
エラーや警告も出ません。
したがって、あらかじめ配列内の欠損値は -np.inf などに置換処理をしておく必要があります。
コードのおさらい
上記を踏まえ、今回のケーススタディでの該当部分をおさらいします。
# 最大値の行番号と列番号を取得
idx, col = np.unravel_index(
indices=df.fillna(-np.inf).values.argmax(),
shape=df.shape
)
np.unravel_index() の第1引数 indices は一息で書いていますが、
1 .fillna(-np.inf) で欠損値の置換
2 .values で np.array に変換
3 .argmax() で平坦化 + 最大値のインデクス取得
という処理になっています。
第2引数 shape は、配列の shape 属性をそのまま指定しています。
おわりに
2次元の pd.DataFrame の何行目の何列目に最大値があるのか、その取得方法を掘り下げて調べました。
argmax() の注意点として書きましたが、複数の最大値を気にする場合や欠損値がある場合は気を付けください。
なお、ここでは最大値を取り上げていますが、np.ndarray.argmin() という関数(とメソッド)もあるので、最小値も同様の方法で処理できます。(ただし欠損値は np.inf 等で置換)
中央値の場合や四分位数の場合はどうするかとか、画像処理系のライブラリを使うとどうかとか、また機会があれば調べてみようと思います。