1.はじめに
投資botを作成する際、多くの方が価格(+出来高)のみを用いているかと思います。しかし利用できるデータはこれらだけではありません。例えば注文状況や保有ポジションの状況などが考えられます。
今回はFX取引所のoandaから注文やポジションのデータ(オーダーブック・ポジションブック)を取り出し、加工するツールを作成したので共有しておきます。
2.オーダーブック・ポジションブックとは
オーダーブックとはまだ約定していない注文がレートごとにどの程度あるかを示すもの(株における板)であり、
オープンポジションは現在保有されているポジションがどのレートにどれくらいあるかを示すものです。
細かいところはリンクからoandaのサイトに飛んで確認してください。
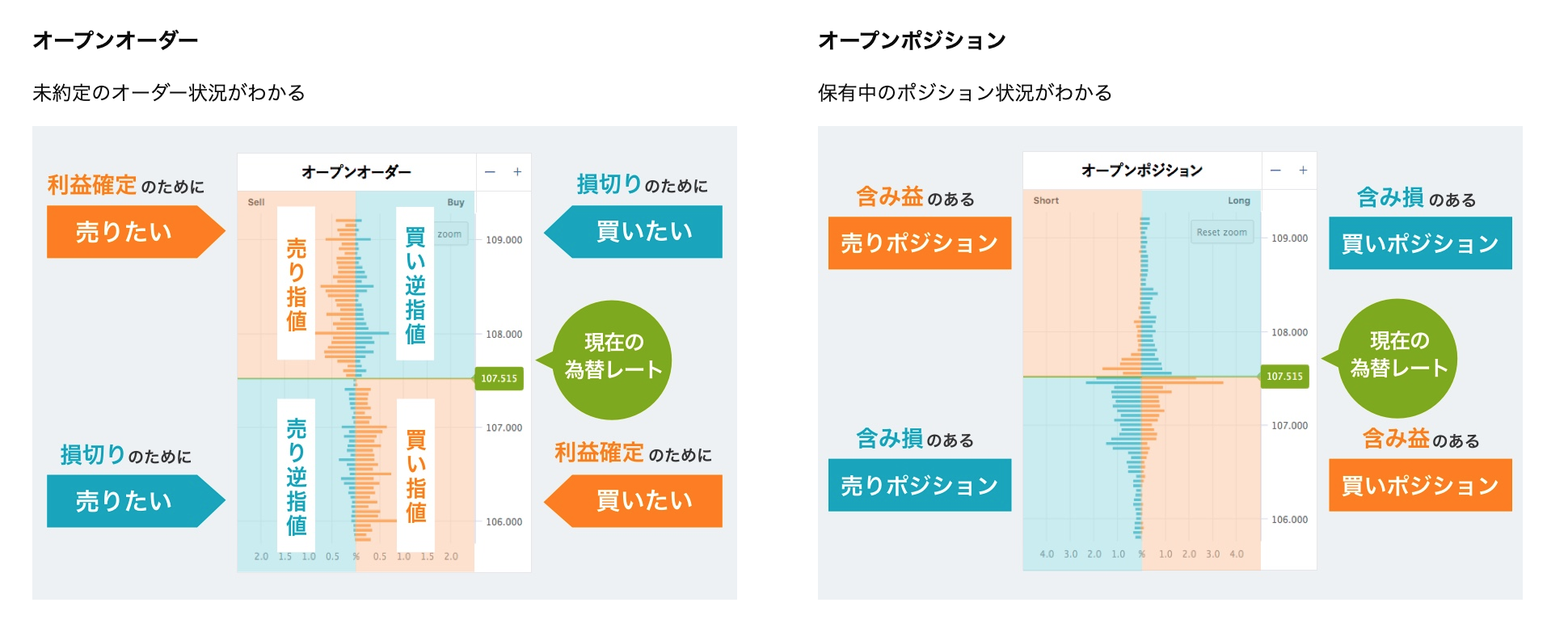
( https://www.oanda.jp/lab-education/oanda_lab/oanda_rab/open_position/ )
3.oandaのブックについて
oandaでは直近の1ヶ月以内で50万ドル以上の取引を行うことで、オーダーブック・ポジションブックともに5分に1回の更新になります。この頻度はwebで見る際もapiで取得する際も変わりません。
ただ単に口座を作っただけだと更新頻度は20分に1回と更新頻度は落ちてしまいます。とはいえ高頻度のトレードをしないのであれば十分な更新頻度だと思います。
なおここでは口座の開設やapi keyの取得については解説しません。
4.本体
oandaのサイトで見るオープンオーダーはそのオープンオーダーのスナップショットが作成された時刻のレートを中心に、一定幅ごとに(ドル円なら0.05円ごと)に広がっているのが見えるかと思います。
しかしapiによって得られたデータはそのようにはなっていません。オーダーブックには広範なレートの情報が含まれており、1ドル=0円から1ドル=200円のように現実にはあり得ないような情報まで含まれています。またオープンオーダーの中心にあるレートは絶えず変動します。そのため得られたデータをそのまま分析しようとしても、各レートがオープンオーダーが作成された際のレートからどれだけ離れているのかがわかりません。
そこで今回は以下のように、中心となるレートとそこからどれだけ離れているかを直感的に把握できるようにデータを収集、加工できるコードを用意しました。
accountIDとaccess_tokenはご自身のものに書き換えてご利用ください。
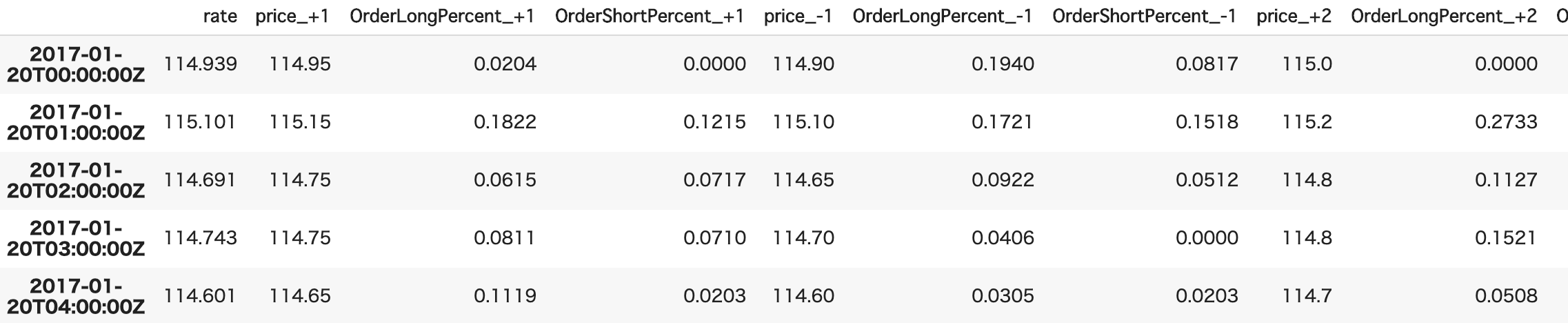
なお2017年1月20日以前のデータは存在しないようです。また、1時間ごとのブックの取得に大体20~30分くらいかかります。
def fetch_orderbook(instrument="USD_JPY", levels = 5, timeframe="15m"):
'''
instrument : 通過ペアの名前
levels : 中心のレートからいくつまで上(下)を取得するか, >0
timeframe : 何分毎にブックを取得するか, "m":minute, "H":hour, "D":day, >="5m"
ex) "1H":1時間ごとに取得, "2D":1日ごとに取得
'''
accountID = "×××-×××-×××-×××"
access_token ="××××××××××××"
api = API(access_token=access_token, environment="live")
if timeframe[-1]=="m":
diff = 60 * int(timeframe[:-1])
elif timeframe[-1]=="H":
diff = 60 * 60 * int(timeframe[:-1])
elif timeframe[-1]=="D":
diff = 60 * 60 * 24 * int(timeframe[:-1])
timestamp = datetime.datetime(year=2017, month=1, day=20)
now = datetime.datetime.utcnow()
processed_book, book_timestamps = [], []
counter = 0
start = datetime.datetime.utcnow()
while True:
try:
#現在まで取得し終わったら終了
if now < timestamp:
break
#サーバーへの過剰なアクセスの防止およびログ出力
counter+=1
if counter%100==0:
print(timestamp, datetime.datetime.utcnow()-start)
start = datetime.datetime.utcnow()
counter=0
time.sleep(1)
#orderbookの取得
r=instruments.InstrumentsOrderBook(instrument=instrument, params={"time":timestamp.strftime("%Y-%m-%dT%H:%M:00Z")})
api.request(r)
book_created_rate, buckets, book_created_time = float(r.response["orderBook"]["price"]), r.response["orderBook"]["buckets"], r.response["orderBook"]["time"]
#book作成時のレートに近いindexの取得
bucket_rate = [round(float(b["price"]), 2) for b in buckets]
upper_idx = np.searchsorted(bucket_rate, book_created_rate)
lower_idx = upper_idx - 1
#現在価格からlevels分離れたのを追加
row_book = [book_created_rate]
for i in range(levels):
upper, lower = buckets[upper_idx + i], buckets[lower_idx - i]
bucket = [upper["price"], upper['longCountPercent'], upper['shortCountPercent'],
lower["price"], lower['longCountPercent'], lower['shortCountPercent']]
bucket = [float(num) for num in bucket]
row_book.extend(bucket)
processed_book.append(row_book)
book_timestamps.append(book_created_time)
except:
#土日
pass
timestamp+=datetime.timedelta(seconds = diff)
#columの名前
column_names = ["rate"]
for i in range(levels):
column_names.extend(["price_+{}".format(i+1), "OrderLongPercent_+{}".format(i+1), "OrderShortPercent_+{}".format(i+1),
"price_-{}".format(i+1), "OrderLongPercent_-{}".format(i+1), "OrderShortPercent_-{}".format(i+1)])
#データの結合
orderbook = pd.DataFrame(processed_book, columns=column_names, index=book_timestamps)
return orderbook
ポジションブックについても同様に
def fetch_positionbook(instrument="USD_JPY", levels = 5, timeframe="15m"):
'''
instrument : 通過ペアの名前
levels : 中心のレートからいくつまで上(下)を取得するか, >0
timeframe : 何分毎にブックを取得するか, "m":minute, "H":hour, "D":day, >="5m"
ex) "1H":1時間ごとに取得, "2D":1日ごとに取得
'''
accountID = "×××-×××-×××-×××"
access_token ="××××××××××××"
api = API(access_token=access_token, environment="live")
if timeframe[-1]=="m":
diff = 60 * int(timeframe[:-1])
elif timeframe[-1]=="H":
diff = 60 * 60 * int(timeframe[:-1])
elif timeframe[-1]=="D":
diff = 60 * 60 * 24 * int(timeframe[:-1])
timestamp = datetime.datetime(year=2017, month=1, day=20)
now = datetime.datetime.utcnow()
processed_book, book_timestamps = [], []
counter = 0
start = datetime.datetime.utcnow()
while True:
try:
#現在まで取得し終わったら終了
if now < timestamp:
break
#サーバーへの過剰なアクセスの防止およびログ出力
counter+=1
if counter%100==0:
print(timestamp, datetime.datetime.utcnow()-start)
start = datetime.datetime.utcnow()
counter=0
time.sleep(1)
#positionbookの取得
r=instruments.InstrumentsPositionBook(instrument=instrument, params={"time":timestamp.strftime("%Y-%m-%dT%H:%M:00Z")})
api.request(r)
book_created_rate, buckets, book_created_time = float(r.response["positionBook"]["price"]), r.response["positionBook"]["buckets"], r.response["positionBook"]["time"]
#book作成時のレートに近いindexの取得
bucket_rate = [round(float(b["price"]), 2) for b in buckets]
upper_idx = np.searchsorted(bucket_rate, book_created_rate)
lower_idx = upper_idx - 1
#現在価格からlevels分離れたのを追加
row_book = [book_created_rate]
for i in range(levels):
upper, lower = buckets[upper_idx + i], buckets[lower_idx - i]
bucket = [upper["price"], upper['longCountPercent'], upper['shortCountPercent'],
lower["price"], lower['longCountPercent'], lower['shortCountPercent']]
bucket = [float(num) for num in bucket]
row_book.extend(bucket)
processed_book.append(row_book)
book_timestamps.append(book_created_time)
except:
#土日
pass
timestamp+=datetime.timedelta(seconds = diff)
#columの名前
column_names = ["rate"]
for i in range(levels):
column_names.extend(["price_+{}".format(i+1), "PositionLongPercent_+{}".format(i+1), "PositionShortPercent_+{}".format(i+1),
"price_-{}".format(i+1), "PositionLongPercent_-{}".format(i+1), "PositionShortPercent_-{}".format(i+1)])
#データの結合
positionbook = pd.DataFrame(processed_book, columns=column_names, index=book_timestamps)
return positionbook
5.最後に
紹介しておいてなんですが、こちらのデータのみを用いてbotを組むのは難しいかと思います。(手数料がなければ)勝てるところまでは行けたのですが、どうにも手数料で勝てそうにありませんでした。もしかすると時間アノマリーとでも組み合わせるとうまくいくかも…?