はじめに
Slackの特定のチャンネルを対象に、投稿されたメッセージ履歴を取得→ファイル出力の方法を紹介します。
Slackにはエクスポート機能がありますが、ここで紹介するのは、エクスポート機能を使用せずにメッセージ内容を取り出す方法です。
SlackAPI
WebAPIを使用しました。
SlackAPIにアクセスして、APIを作成します。TOKEN取得までの流れは多くの人がまとめてくれているので、そちらを参考にしてください。
conversations.history
conversations.historyを使用してメッセージを取得します。ただし、単純にこれを使うだけではスレッドのメッセージを取得しないので、今回はデータ内のタイムスタンプを参照してスレッド返信を取得するようなコードを書きました。
Tokenに使用したスコープ
- channels:history
- channels:read
- groups:history
- im:history
- mpim:history
- users:read
Pythonでの実装
出力内容
- メッセージタイプ(メッセージ or メッセージへのスレッド返信)
- 投稿者
- 投稿時刻
- メッセージ内容
メッセージと、それへの返信は並べて出力する形にしました。
コード
import requests
import pandas as pd
from datetime import datetime
import urllib3
urllib3.disable_warnings()
def main():
SLACK_CHANNEL_NAME = "出力ファイルの名前"
SLACK_CHANNEL_ID = "チャンネルID"
TOKEN = "取得したTOKEN"
SLACK_URL_his = "https://slack.com/api/conversations.history"
SLACK_URL_user = "https://slack.com/api/users.info"
SLACK_URL_rep = "https://slack.com/api/conversations.replies"
SLACK_URL_mem = "https://slack.com/api/conversations.members"
members_dict = get_members(SLACK_CHANNEL_ID, TOKEN, SLACK_URL_mem, SLACK_URL_user)
msgs_all = get_message(SLACK_CHANNEL_ID, TOKEN, SLACK_URL_his, msgs_all = [], latest_ts = None)
msgs_ls = get_msgslist(SLACK_CHANNEL_ID, TOKEN, SLACK_URL_rep, msgs_all)
out_all = []
out_all = get_outlist(out_all, msgs_ls, members_dict)
output = pd.DataFrame(out_all,
columns=['type','name', 'time', 'text'])
output.to_csv(SLACK_CHANNEL_NAME + '.csv', encoding = 'utf_8_sig')
if __name__ == "__main__":
main()
以下、main()で使用した各関数
get_members
def get_members(SLACK_CHANNEL_ID, TOKEN, SLACK_URL_mem, SLACK_URL_user):
# チャンネル内のユーザーIDリストを取得
headers = {'Authorization': 'Bearer ' + str(TOKEN)}
params = {'channel': SLACK_CHANNEL_ID}
response_mem = requests.get(SLACK_URL_mem, headers=headers, params=params, verify=False)
json_mem = response_mem.json()
members_id = json_mem['members']
# IDから名前リストを取得
members_name = []
for id in members_id:
headers = {'Authorization': 'Bearer ' + str(TOKEN)}
params = {'channel': SLACK_CHANNEL_ID, 'user':id}
response_info = requests.get(SLACK_URL_user, headers=headers, params=params, verify=False)
json_info = response_info.json()
members_name.append(json_info['user'].get('real_name'))
# IDと名前の対応辞書を作成
members_dict = {key:val for key, val in zip(members_id, members_name)
if val is not None}
return members_dict
get_message
def get_message(SLACK_CHANNEL_ID, TOKEN, SLACK_URL_his, msgs_all = [], latest_ts = None):
# チャンネル内のメッセージのリストを返す関数
# ここで返すリストにはスレッド返信は含まれない
headers = {'Authorization': 'Bearer ' + str(TOKEN)}
params = {'channel': SLACK_CHANNEL_ID, 'latest':latest_ts}
response_his = requests.get(SLACK_URL_his, headers=headers, params=params, verify=False)
json_his = response_his.json()
msgs_his = json_his['messages']
msgs_all.extend(msgs_his)
# 一度に取得できるメッセージ数は100なので、チャンネル内のメッセージ数が100以上の場合は再帰処理
if len(msgs_his) == 100:
get_message(msgs_all, msgs_his[-1].get('%tbs'))
return msgs_all
get_msgslist
def get_msgslist(SLACK_CHANNEL_ID, TOKEN, SLACK_URL_rep, msgs_his):
# スレッド返信がある場合は、返信も含めたリストに再構成して時系列順に並べたリストを返す関数
msgs_ls = []
for msgs in msgs_his:
if msgs.get('thread_ts'):
headers = {'Authorization': 'Bearer ' + str(TOKEN)}
params = {'channel': SLACK_CHANNEL_ID, 'ts':msgs.get('thread_ts')}
response_rep = requests.get(SLACK_URL_rep, headers=headers, params=params, verify=False)
json_rep = response_rep.json()
msgs_rep = json_rep.get('messages')
if msgs != None:
msgs_ls.append(msgs_rep)
msgs_ls.reverse()
return msgs_ls
get_outlist
def get_outlist(out_ls, msgs_ls, members_dict):
# 必要な要素のみを抽出したリストを返す関数
for msgs in msgs_ls:
for i in range(len(msgs)):
if members_dict.get(msgs[i].get('user')) == None:
# 現在チャンネルに含まれていないメンバーはIDのまま表示
count = 0
for user_id, name in members_dict.items():
if count == 0:
text = msgs[i].get('text')
text = text.replace(user_id, name)
count = count + 1
tmp = [
msgs[i].get('user'),
datetime.fromtimestamp(int(float(msgs[i].get('ts')))).strftime('%Y/%m/%d %H:%M:%S'),
text
]
else:
count = 0
for user_id, name in members_dict.items():
if count == 0:
text = msgs[i].get('text')
text = text.replace(user_id, name)
count = count + 1
tmp = [
members_dict.get(msgs[i].get('user')),
datetime.fromtimestamp(int(float(msgs[i].get('ts')))).strftime('%Y/%m/%d %H:%M:%S'),
text
]
if i == 0:
# main:スレッド返信以外
tmp.insert(0, 'main')
else:
# reply:スレッド返信
tmp.insert(0, 'reply')
out_ls.append(tmp)
return out_ls
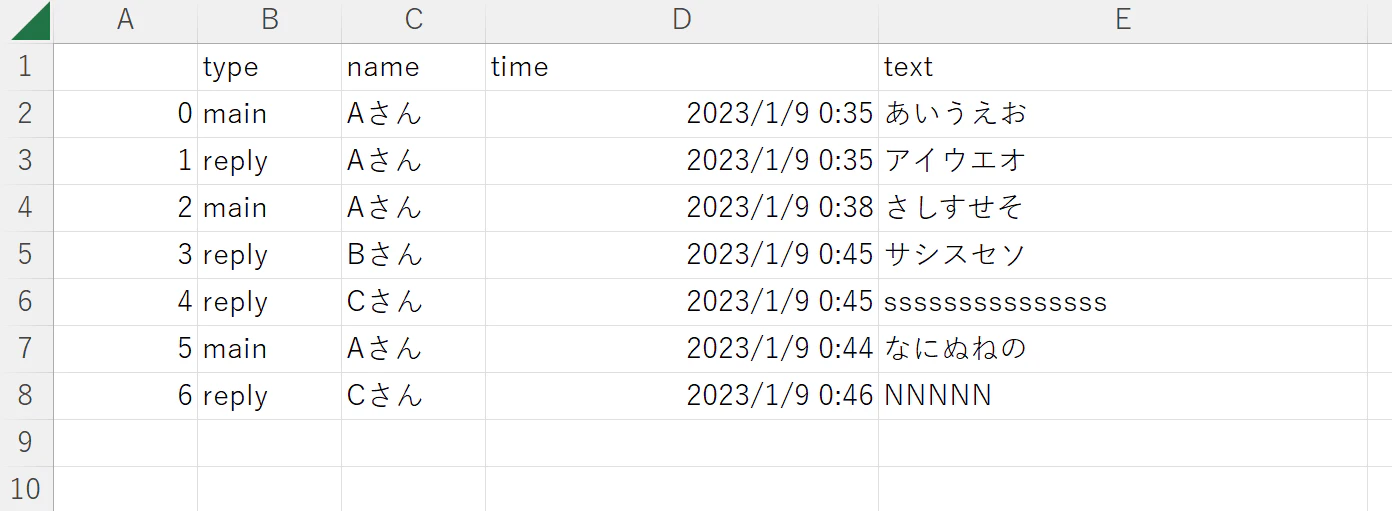
CSV出力例
出力したcsvファイルを確認するとこんな感じです。
出力順は、メッセージの投稿時刻(スレッド元となるメッセージ)の昔→最近です。スレッド返信は、スレッド元となるメッセージに連なるようにしています。
改善したいこと
get_outlist内で3重のfor文を回している点。for文を重ねて回すと時間がかかるので、ぜひ改善したいが案が思いついていないのが現状。