はじめに
この記事は慶應理工アドベントカレンダー2022の19日目の記事です。DjangoとReactを軽く触ったことがある人ならすぐ読むことができると思います。どちらも全く触れたことがない方でも環境さえ整えば実装はできるとは思います。DjangoやReact Nativeに触れたことがない方が触れてみるきっかけになれば幸いです。以下のようなとてもシンプルなアプリを作成しました。

注意
途中バックエンドの処理において、Linux(Mac)固有のコマンドを用いるためMacでしか動作確認できていないです。(Mac固有のafconvertコマンドをFFmpegコマンドで置き換えることができれば動作すると思います。) 保証はできませんが、それ以外は基本的にWindowsでも動くと思います。
背景
最近大学の実験において、ラズパイとAWSを用いて似たようなプロジェクトを行っていたので、せっかくならということでスマホアプリ化しました。ただ今回は文字起こしにGoogle Cloud Speech-to-Text APIを用い、タイトル自動生成にはHugging Faceのモデルを用いてDjangoで推論APIを作成しました。
フロントエンドの概要
フロントエンドはReact NativeというFacebook社が開発しているJavaScriptのオープンソースのアプリケーションフレームワークを用います。そのReact Nativeの中でも、iOS,Android,Webのアプリを簡単に作成,ビルドできるクロスプラットフォームであるExpoを用います。
以下は既に知っている方は飛ばしてください。
React Nativeの特徴
- Reactに触れたことがある人なら簡単にiOS、Androidアプリを作成できます。
- 【入門編】React Nativeとは?メリット・デメリットからHello, Worldまで が参考になると思います。
Expoの特徴
-
Expoの良いところはなんといっても実機での動作確認が簡単で、さくさくとアプリを作成できます。素のReact Nativeアプリや、ExpoからEjectしたプロジェクトで実機確認する際には、iOSではPCにスマホを有線で繋げ、Xcodeで時間をかけてビルドする必要があります。一方Expoではコマンドを1つ入力したときに表示されるQRコードをスマホで読み取るだけで動作確認ができます。(初回時にはExpoアプリをインストールし、登録する必要がある。)
-
悪いところとしては、機能が制限されていることがあります。特にネイティプの機能を使うようなライブラリは使えません。例えば、バックグラウンド処理は実装できなかったり、画像を選ぶライブラリでは複数枚の画像を選択できないなど...。Expoで開発する際には開発前にしっかりExpoで実装できるかを検討する必要があります。
バックエンド
バックエンドはDjangoというPythonのWebアプリケーションフレームワークを用います。そのDjangoの中でもDjango REST frameworkというライブラリを用いることでフロントエンドから呼び出せるRESTfulなAPIを作成できます。
Djangoの特徴
- Djangoは今回のように機械学習や深層学習のモデルを組み込む際にはとても適しています。なぜなら、ほとんどの機械学習のコードがPythonで書かれているためです。
Django REST frameworkの特徴
- Django REST framework(以下ではDRF)はDjangoを用いてAPIを簡単に作るためのライブラリです。そもそもAPIとはApplication Programming Interfaceの略であり、ソフトウェア、プログラム、Webサービスなどを繋ぐインターフェースのことです。APIを利用することでアプリ開発が容易になります。
システム構成
まずExpoではexpo-avというライブラリを用います。これにより、音声を録音、再生できます。この録音した音声ファイルをバックエンドで作成したAPIにPOSTで送信することで音声認識を行います。記事の後半では、そこで得られた文章をさらにバックエンドで作成した推論APIにPOSTで送信することでタイトル自動生成を行います。
以上のことから、DRFでは2つのAPIエンドポイントを作成する必要があります。
- 音声認識API(Google Cloud Speech-to-Text APIを用いる)
- タイトル自動生成API(Hugging Faceのモデルを用いる)
音声認識APIの作成にはGoogle Cloud Speech-to-Text APIを用います。OpenAIが公開している音声認識モデルであるWhisperを用いて実装しても良かったのですが、CPUのみの計算資源では推論時間が長くなってしまうことや、タイトル自動生成と同じ構成になってしまうのでここではAPIを用いることにしました。
フロントエンドの実装(前半)
まずアプリを作成したいディレクトリに移動し、以下のコマンドを実行します。
Nodeやnpmが入っていない場合には、npmをインストール|Windows、Mac、Linux|OS別を参考にしてインストールしてください。
sh237:SaveSpeechAsTextFront:~ $ npm install -g expo-cli
sh237:SaveSpeechAsTextFront:~ $ expo init SaveSpeechAsTextFront
2つ目のコマンド実行時に以下のような画面になりますが、一番上のblankを選択してください。

これにより以下のような構成のSaveSpeechAsTextFrontディレクトリが作成されると思います。
├── assets
├── node_modules
├── .gitignore
├── App.js
└── app.json
└── babel.config.js
└── package.json
└── yarn.lock
次に作成されたSaveSpeechAsTextFrontディレクトリ内で以下のコマンドを実行し、必要なパッケージをインストールしてください。
sh237:SaveSpeechAsTextFront:~ $ npx expo install @expo/vector-icons@^13.0.0
sh237:SaveSpeechAsTextFront:~ $ npx expo install expo-file-system@~15.1.1
sh237:SaveSpeechAsTextFront:~ $ npx expo install expo-av@~13.0.2
sh237:SaveSpeechAsTextFront:~ $ npx expo install expo-dev-client@~2.0.1
sh237:SaveSpeechAsTextFront:~ $ npx expo install expo-modules-core@~1.0.3
sh237:SaveSpeechAsTextFront:~ $ npx expo install expo-updates@~0.15.6
sh237:SaveSpeechAsTextFront:~ $ npx expo install ky@^0.32.2
sh237:SaveSpeechAsTextFront:~ $ npm install -g eas-cli
-
expo-file-systemExpoでファイルを扱うためのパッケージ -
expo-avExpoでオーティオを扱うためのパッケージ -
ky非同期APIの呼び出しを行う際に使うパッケージ
(axiosを用いることが多いが、Expoで音声ファイルを含めてPOSTすると失敗したのでこのパッケージを用いる)
次にExpoのアカウントがなければここから登録します。(登録は右上のSign Upボタンから行える)
App.jsの実装
ほとんどのReact Nativeのアプリや、Expoのアプリにおいては、基本的にApp.jsに処理を追加する形で実装します。画面遷移を行ったりする場合にはApp.jsから子コンポーネントを呼び出すようにして開発しますが、今回は画面遷移を行わないのでApp.jsだけに処理を追加すればよいです。
まず必要なパッケージのインポートを行います。
import React, { useState, useRef, useEffect } from 'react';
import { View, StyleSheet, ScrollView, Text, Button } from 'react-native';
import { Audio } from 'expo-av';
import ky from 'ky';
import * as FileSystem from 'expo-file-system';
import { MaterialCommunityIcons } from '@expo/vector-icons';
import { Ionicons } from '@expo/vector-icons';
import { FontAwesome5 } from '@expo/vector-icons';
次にAppコンポーネントの中で変数の初期化や処理の初期化を行います。
export default function App() {
//オーディオの再生に必要な変数
const AudioRecorder = useRef(new Audio.Recording());
const AudioPlayer = useRef(new Audio.Sound());
//変数の初期化
const [RecordedURI, SetRecordedURI] = useState('');
const [AudioPermission, SetAudioPermission] = useState(false);
const [IsRecording, SetIsRecording] = useState(false);
const [IsPLaying, SetIsPLaying] = useState(false);
const [resultText, setResultText] = useState('');
//録音の許可を求める関数の呼び出し
useEffect(() => {
GetPermission();
}, []);
...
}
RecordedURIは録音された音声ファイルへのパスを保存するステートで、IsRecordingは録音中かを保持するステートで、IsPLayingは再生中かを保持するステートである。useEffectの中で呼び出されているのは録音の許可を求める関数であるGetPermission関数である。初回レンダリング時のみ許可を求めるようにしている。
React Hooksの基礎文法(既知の方はスキップ推奨)
React Hooksという関数ベースで書く場合には、このように状態を保存するために以下のように初期化します。
const [現在の状態,状態を更新する関数] = useState(初期値);
こうすることで現在の状態を変数として扱える。また、状態を更新する関数(変更する値)とすることで変数を更新できます。
useEffectは指定したステートが変化した場合に実行する処理を登録できます。useEffect(実行する処理,[ステートの配列])における、第1引数の実行する処理が登録しておく処理で、第2引数の[ステートの配列]には変化を検知したい変数を配列として渡します。この第2引数が空の配列の場合、初期レンダリング時のみその第1引数に指定された処理を実行します。
App.jsの実装(続き)
...
//録音の許可を求める関数
const GetPermission = async () => {
const getAudioPerm = await Audio.requestPermissionsAsync();//録音の許可を求める
if (getAudioPerm.granted){
SetAudioPermission(getAudioPerm.granted);//許可があればtrue,なければfalse
}
};
ここでは非同期処理を用いてユーザーに録音の許可を求めています。
...
//録音の開始をする関数
const StartRecording = async () => {
try {
//録音の許可があるかどうか
if (AudioPermission === true) {
try {
//オーディオの再生に必要な設定
await Audio.setAudioModeAsync({
allowsRecordingIOS: true,
playsInSilentModeIOS: true,
});
//レコードの準備
await AudioRecorder.current.prepareToRecordAsync(
{
android: {
extension: '.m4a',
outputFormat: Audio.RECORDING_OPTION_ANDROID_OUTPUT_FORMAT_MPEG_4,
audioEncoder: Audio.RECORDING_OPTION_ANDROID_AUDIO_ENCODER_AAC,
sampleRate: 44100,
numberOfChannels: 1,
bitRate: 128000,
},
ios: {
extension: '.caf',
audioQuality: Audio.RECORDING_OPTION_IOS_AUDIO_QUALITY_HIGH,
sampleRate: 44100,
numberOfChannels: 1,
bitRate: 128000,
linearPCMBitDepth: 16,
linearPCMIsBigEndian: false,
linearPCMIsFloat: false,
}
}
);
//録音の開始
await AudioRecorder.current.startAsync();
SetIsRecording(true);
} catch (error) {
console.log(error);
}
} else {
//録音の許可がない場合は許可を求める
GetPermission();
}
} catch (error) {
console.log(error);
}
};
このStartRecording関数は、録音ボタンが押されたときに実行されます。まず録音の許可があるか確認し、許可があればオーディオの再生や録音に必要な設定を行い、録音を始めます。
...
//録音の停止をする関数
const StopRecording = async () => {
try {
//録音の停止
await AudioRecorder.current.stopAndUnloadAsync();
//録音した音声のURIを取得
const result = AudioRecorder.current.getURI();
if (result) SetRecordedURI(result);
//録音の状態を変更
AudioRecorder.current = new Audio.Recording();
const fileType = 'audio/x-caf'; // cafファイルのMIMEタイプ
const fileName = result.split('/').pop();
const fileData = await FileSystem.readAsStringAsync(result, {encoding: FileSystem.EncodingType.Base64});
const file = new File([fileData], fileName, {type: fileType});
let url = `http://localhost:8000/api/speech2text/${fileName}`; // POST先のURL
const client = ky.create({
headers: { 'content-Type': 'application/json' },
timeout: 100000, // milliseconds
});
// 送信するデータをセット
const formData = new FormData();
formData.append('file', {
uri: result,
name: fileName,
type: 'audio/x-caf',
});
// POST送信
let response = await client.post(url, {
body: formData,
});
//音声認識の結果を取得
const json = await response.json();
const parsed_json = JSON.parse(json);
const text = parsed_json.result[0];
setResultText(text);
url = `http://localhost:8000/api/summary`; // POST先のURL
if(text === ""){
setSummary("音声が認識できませんでした。");
SetIsRecording(false);
return;
}
////////////////////////////////
///タイトル自動生成の処理はここに書く///
///////////////////////////////
SetIsRecording(false);
} catch (error) {
console.log(error);
}
};
このStopRecording関数、録音ボタンが押されたときに実行されます。まず録音の停止をし、その後に変数を変更します。さらに、バックエンドで作成した音声認識APIに音声ファイルをPOSTし、結果として返ってきた文字列をresultText変数に代入します。
...
//録音した音声を再生する関数
const PlayRecordedAudio = async () => {
try {
//録音した音声を再生
await AudioPlayer.current.loadAsync({ uri: RecordedURI }, {}, true);
//プレイヤーの状態を取得
const playerStatus = await AudioPlayer.current.getStatusAsync();
//音声が再生されていない場合は再生する
if (playerStatus.isLoaded) {
if (playerStatus.isPlaying === false) {
AudioPlayer.current.playAsync();
SetIsPLaying(true);
}
}
} catch (error) {
console.log(error);
}
};
//再生中の音声を停止する関数
const StopPlaying = async () => {
try {
//プレイヤーの状態を取得
const playerStatus = await AudioPlayer.current.getStatusAsync();
//音声が再生されている場合は停止する
if (playerStatus.isLoaded === true)
await AudioPlayer.current.unloadAsync();
SetIsPLaying(false);
} catch (error) {
console.log(error);
}
};
1つ目のPlayRecordedAudioは録音された音声を再生する関数で、2つ目のStopPlaying関数は再生された音声を停止する関数です。どちらの関数の処理もシンプルであり、現在の状態を取得し、再生を開始/中止できる状態であれば処理を実行します。
...
return (
<ScrollView style={styles.container}>
<View style={styles.header}>
<Text style={styles.header_text}>音声認識アプリ</Text>
</View>
<View style={styles.icon_container}>
{IsRecording ? (
<>
<Text style={styles.text}>停止</Text>
<MaterialCommunityIcons style={styles.icon} name="record-rec" size={50} color="black" onPress={StopRecording }/></>) : (
<>
<Text style={styles.text}>録音</Text>
<MaterialCommunityIcons style={styles.icon} name="record-circle" size={50} color="black" onPress={StartRecording}/></>)}
{IsPLaying ? (
<>
<Text style={styles.text}>停止</Text>
<FontAwesome5 style={styles.icon} name="stop-circle" size={50} color="black" onPress={StopPlaying}/></>) : (
<>
<Text style={styles.text}>再生</Text>
<Ionicons style={styles.icon} name="play-circle-sharp" size={50} color="black" onPress={PlayRecordedAudio}/></>
)}
</View>
{*ここにsummayを表示させる*}
{resultText &&
<>
<Text style={styles.result_title}>結果</Text>
<View style={styles.result_container}>
<Text style={styles.result_text}>{resultText}</Text>
</View>
</>
}
</ScrollView>
);
}
ここで目に見える部分を作っています。これらのタグはHTMLのタグと酷似していますが、実際にはJSXタグと呼ばれるタグです。ただ、役割としてはほとんどHTMLタグと同じで、各タグによってレンダリングされる要素が異なります。録音するボタンと再生するボタンは@expo/vector-iconsライブラリのアイコンで作成しています。
{resultText &&
<>
<Text style={styles.result_title}>結果</Text>
<View style={styles.result_container}>
<Text style={styles.result_text}>{resultText}</Text>
</View>
</>
}
ここでは音声認識APIの結果であるresultText変数を表示させている。{式A && 要素}は、式Aがtrueのときのみ要素Aを表示させるようにしています。
...
const styles = StyleSheet.create({
container: {
flex: 1,
backgroundColor: '#fcfcfc',
},
header: {
height: 120,
paddingTop: 50,
justifyContent: 'center',
alignItems: 'center',
backgroundColor: '#aaf3f9',
borderRadius: 10,
shadowRadius: 10,
shadowColor: 'black',
shadowOpacity: 0.4,
elevation: 3,
},
header_text: {
fontSize: 30,
fontFamily: "Hiragino Sans",
fontWeight: "bold",
color: '#666666',
},
icon_container: {
display: 'flex',
flexDirection: 'row',
justifyContent: 'center',
justifySelf: 'center',
marginTop: 50,
},
icon: {
alignSelf: 'center',
justifyContent: 'center',
},
text:{
alignSelf: 'center',
justifyContent: 'center',
fontSize: 20,
fontFamily: "Hiragino Sans",
fontWeight: "bold",
color: '#666666',
},
result_container: {
marginTop : 5,
marginLeft: 20,
justifyContent: 'center',
justifySelf: 'center',
padding: 10,
width: "90%",
borderRadius: 4,
borderColor: '#666666',
borderWidth: 1,
},
result_title: {
marginTop : 10,
alignSelf: 'center',
fontSize: 30,
fontFamily: "Hiragino Sans",
fontWeight: "bold",
color: '#666666',
},
result_text: {
alignSelf: 'center',
justifyContent: 'center',
fontSize: 20,
fontFamily: "Hiragino Sans",
fontWeight: "bold",
color: '#666666',
}
});
ここでは各タグの配置や色などを設定しています。CSSの設定に似ていますが、プロパティ名はCSSと若干異なるので注意してください。
ここまででフロントエンドの実装は終わりです。
バックエンドの実装(後半)
音声認識ではGoogle CloudのSpeech-to-Text APIを用いるため、まずその設定を行います。ここからGoogle Cloudの登録をしてください。
(※クレジットの登録をしなければいけません。90日間使える$300分のクレジットで使えます。それ以降にAPIを叩くとある使用量を超えると料金が発生します。料金はこちらから確認できます。お試しで使う分には料金は発生しないと思います。お試し期間ではほぼ発生しません。)
ようこそという画面に切り替わったら、以下に示したようにメニューからAPIとサービス→ライブラリを選択します。
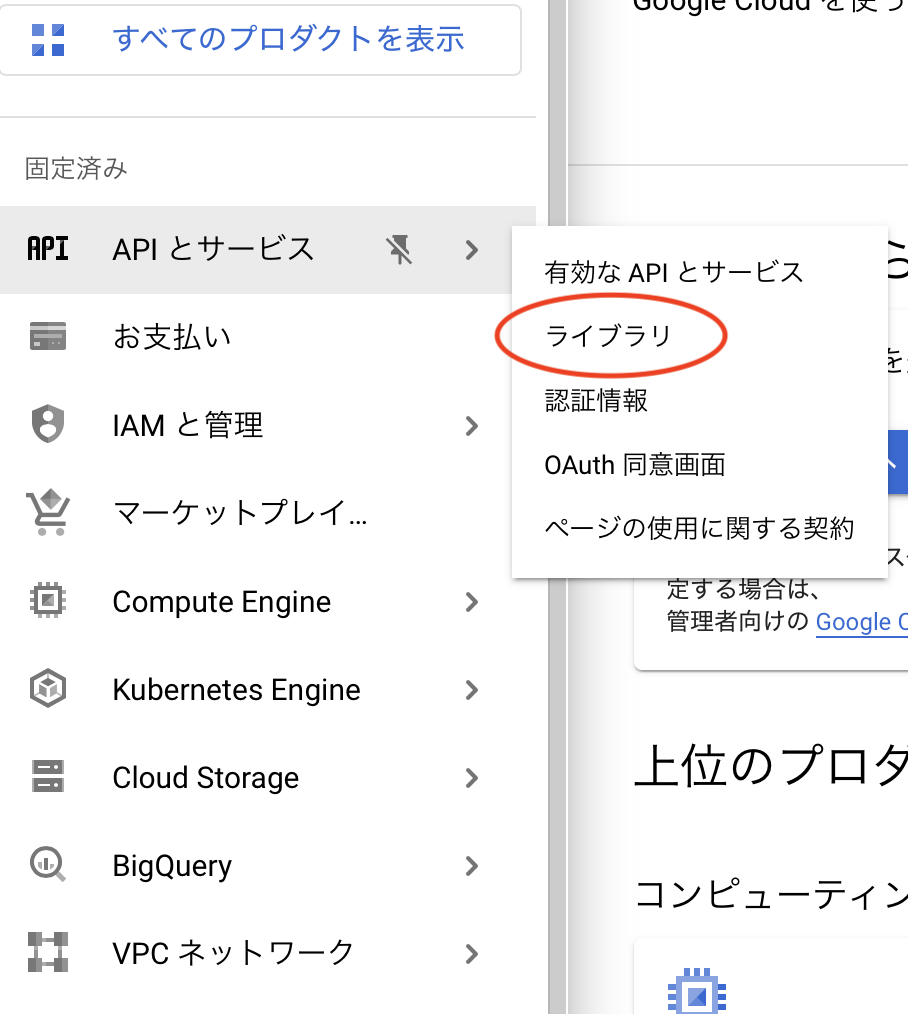
次に検索バーでSpeech-to-Textと打つことで、以下のライブラリを選択します。
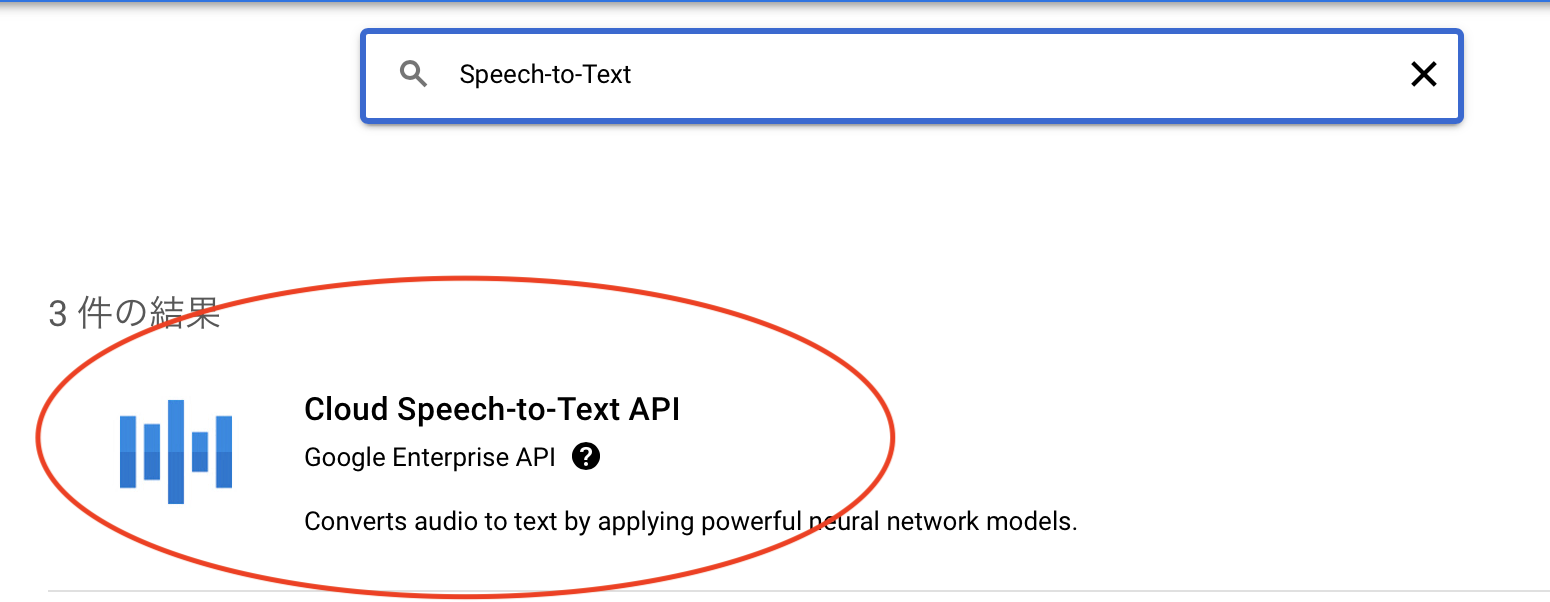
選択した後に表示される有効にするボタンを押すことでこのAPIを使うことができます。
次に認証情報の設定をする必要があります。まず、以下の画像のようにメニューからAPIとサービス→有効なAPIとサービスを選択します。
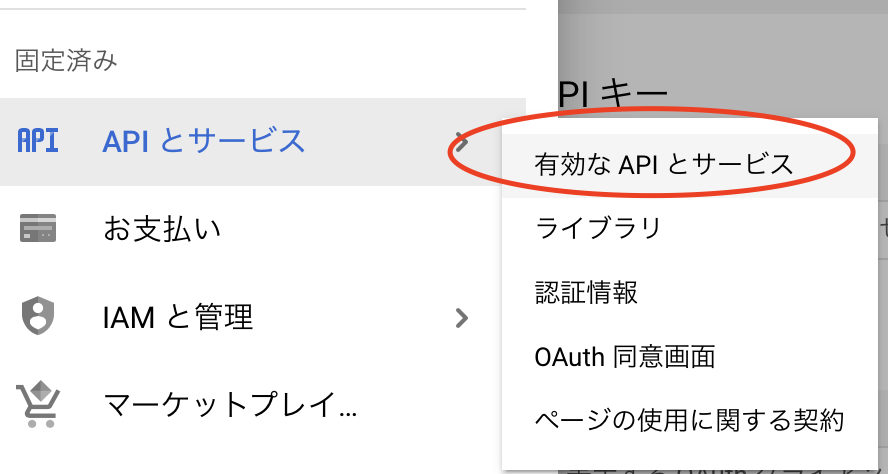
遷移後の画面で下にスクロールし、Cloud Speech-to-Text APIを選択します。
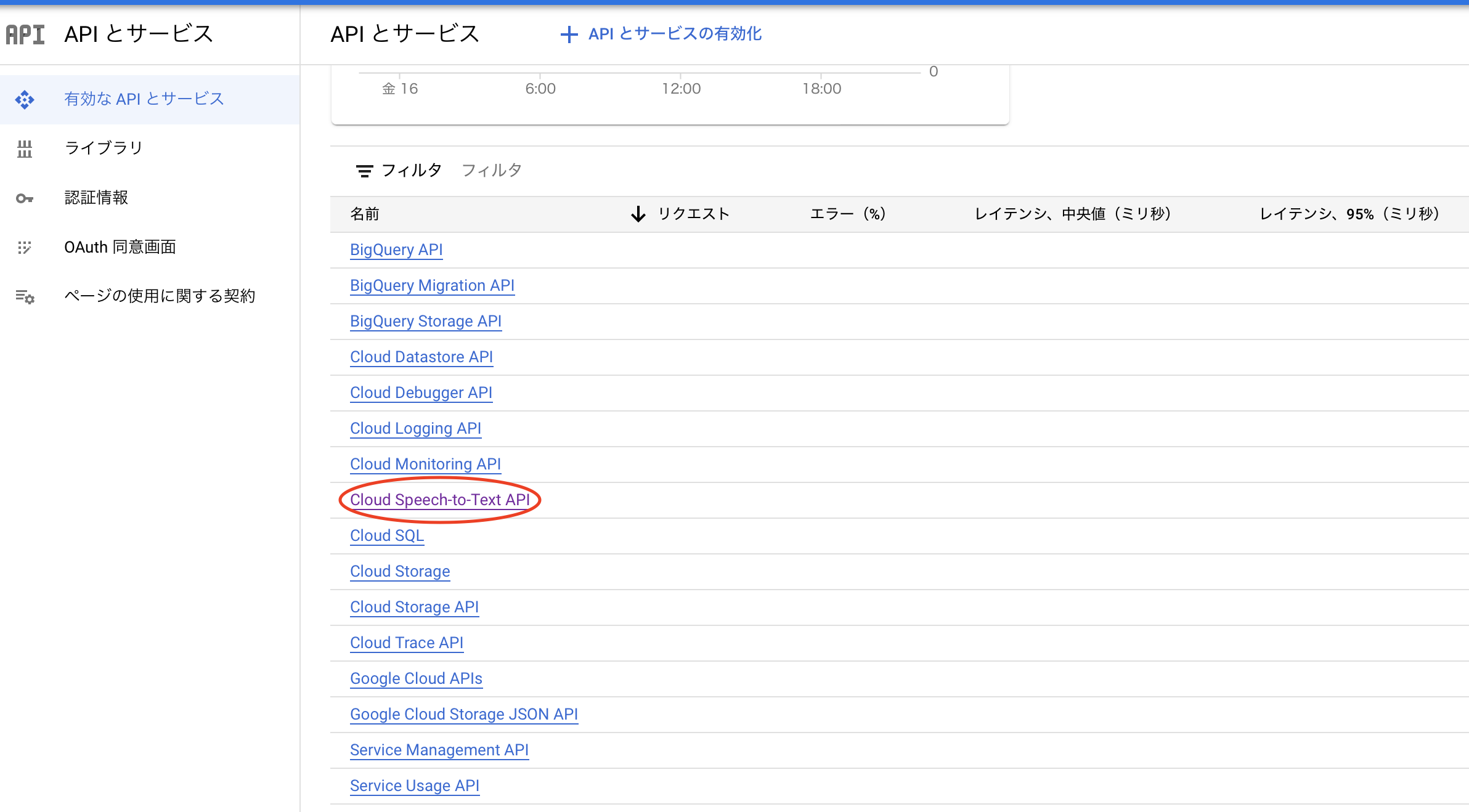
以下のような画面に遷移されたら、認証情報タブを選択します。すると画面の中央右側に認証情報を作成というボタンがあるので押します。すると画像のようにプルダウンメニューが表示されるので、サービスアカウントを選択します。
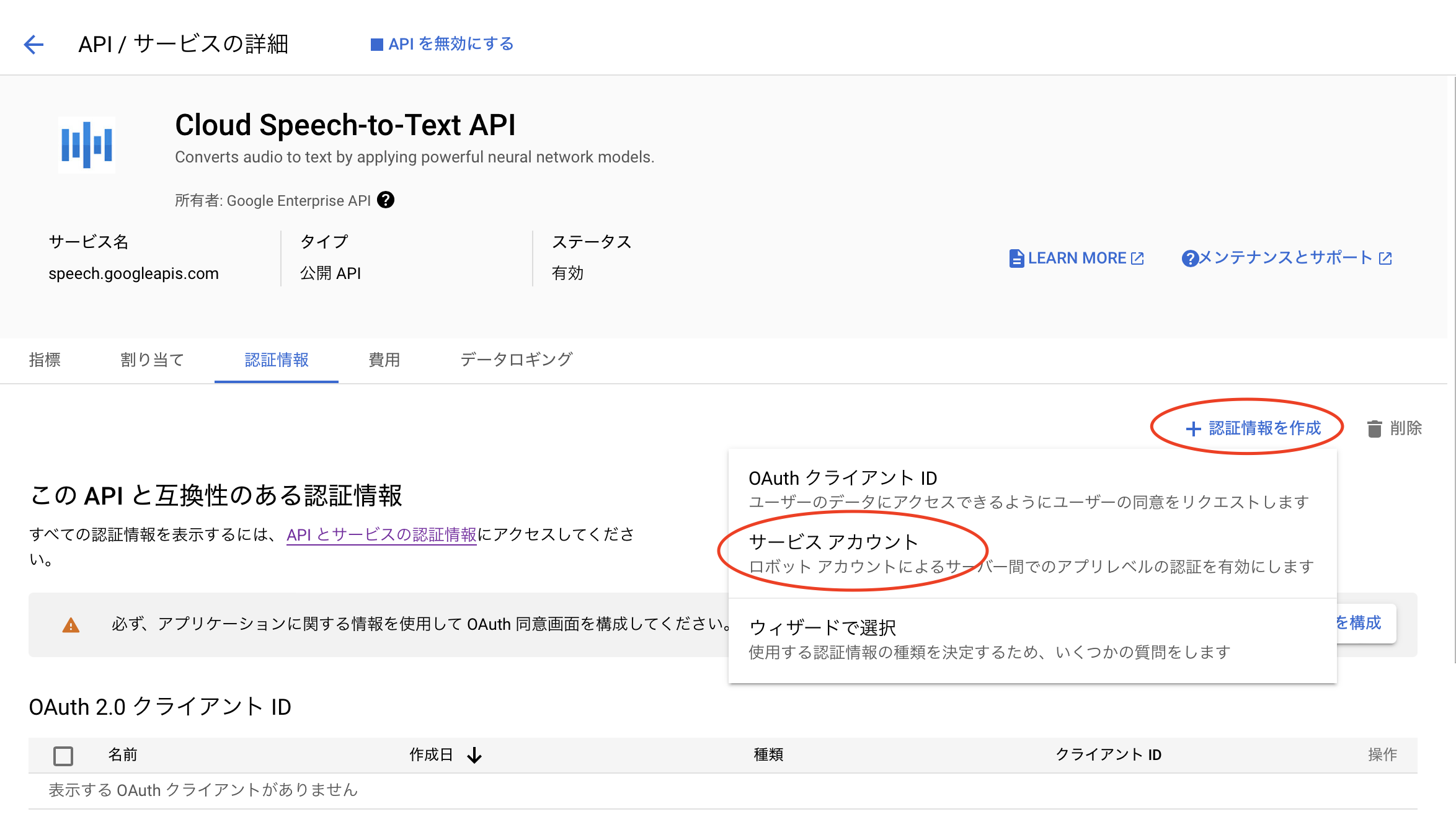
遷移後の画面でサービスアカウントを作成しますが、名前はここではssatとします。(名前は何でも問題ないです。)
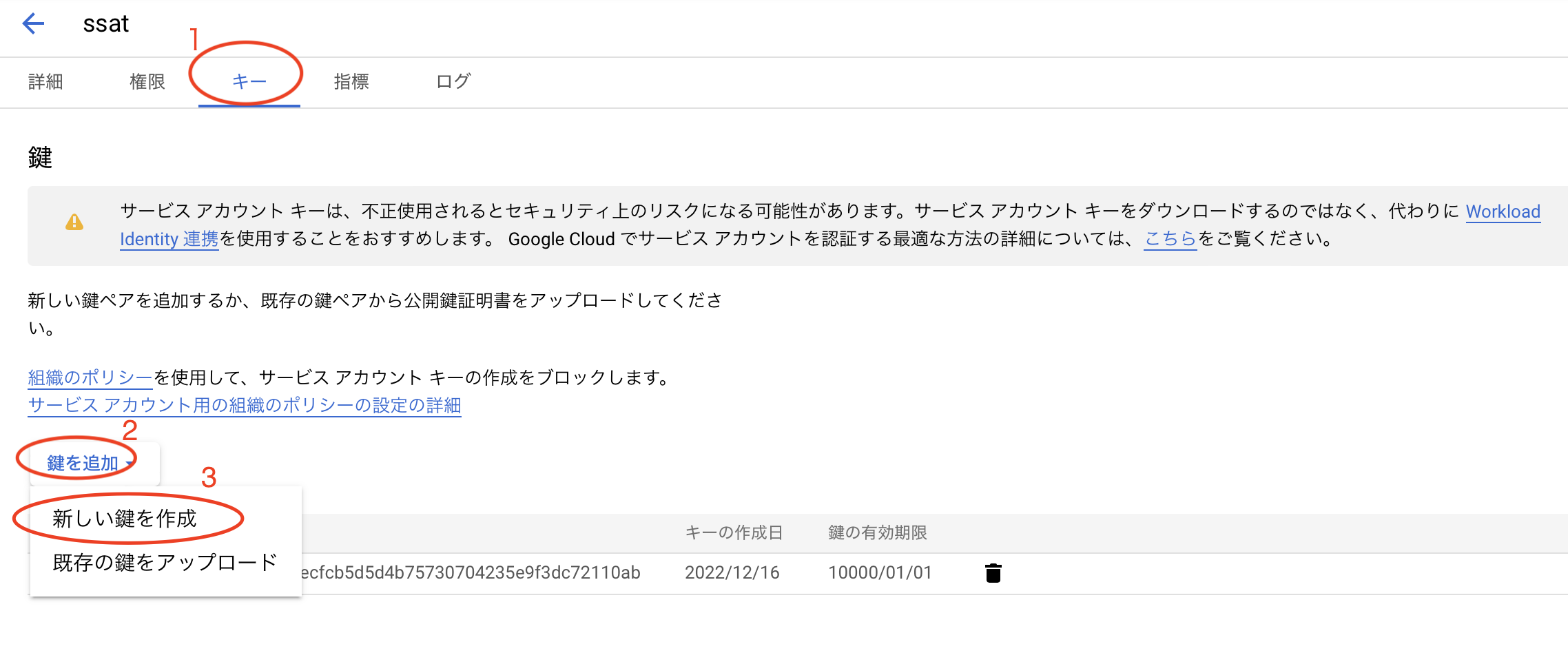
さらに、ロールはオーナーを選択します。Cloud Speech-to-Text APIの画面に戻って、下にスクロールすると、作ったアカウントがあると思うので選択します。すると以下のような画面になるので、画像のように選択することでキーがjsonとして保存されます。
Cloud Storageの設定
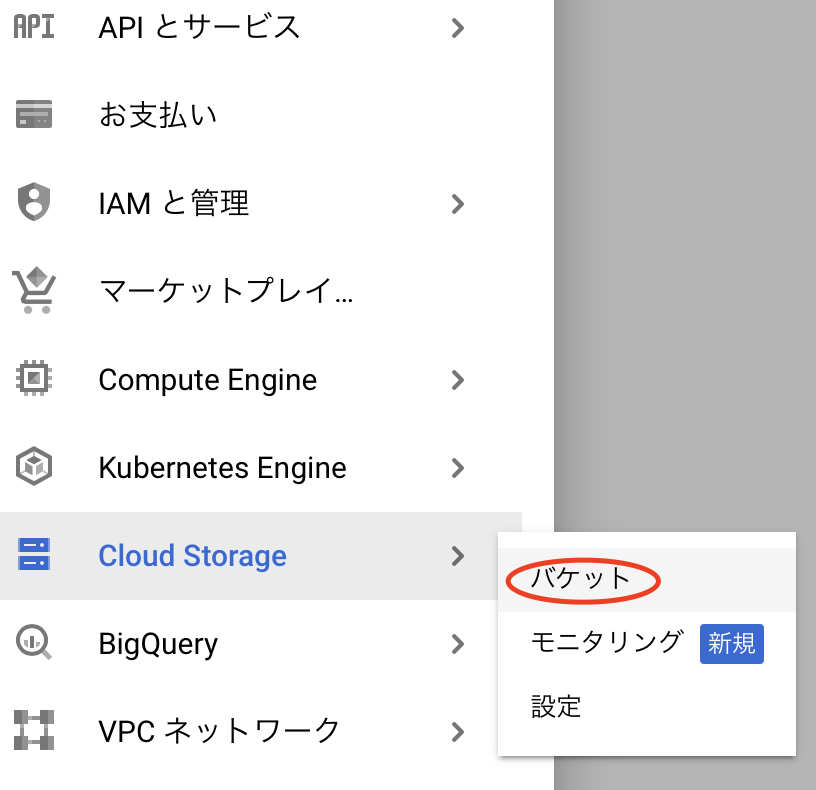
このAPIでは、1分以上のファイルを処理するには、Cloud Storageにファイルをアップロードしている必要があります。そのためCloud Storageでバケットを作成し、設定を行います。まずGoogle Cloudの以下のメニューからCloud Storage→バケットを選択します。
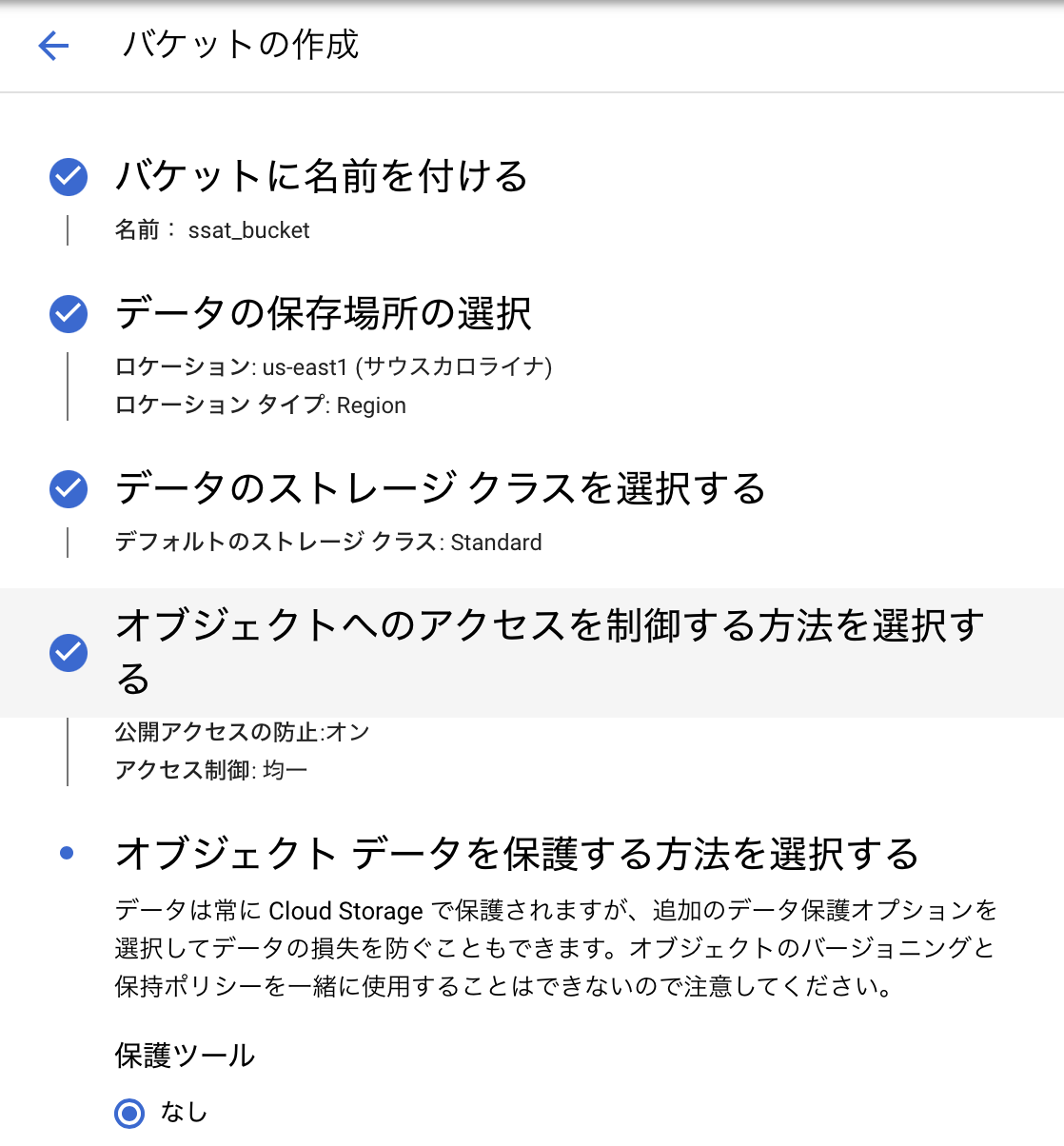
次に上部にある作成ボタンを押し、バケット作成画面に進みます。ここでは以下のような設定にしました。(特に指定はない。また、名前はユニークである必要があるみたいです。)
バケットを作成したら、バケット一覧から今作成したバケットを選択し、権限タブを見ます。先程作成したサービスアカウントがオーナーであることを確認します。(サービスアカウントの名前は先程保存したjsonキーの先頭と同じなっています。)もしオーナーでなければ権限を追加する必要があります。以下の画像のように先ほど作成したサービスアカウントにStorage オブジェクト管理者とストレージ管理者の権限を以下の手順で付与します。
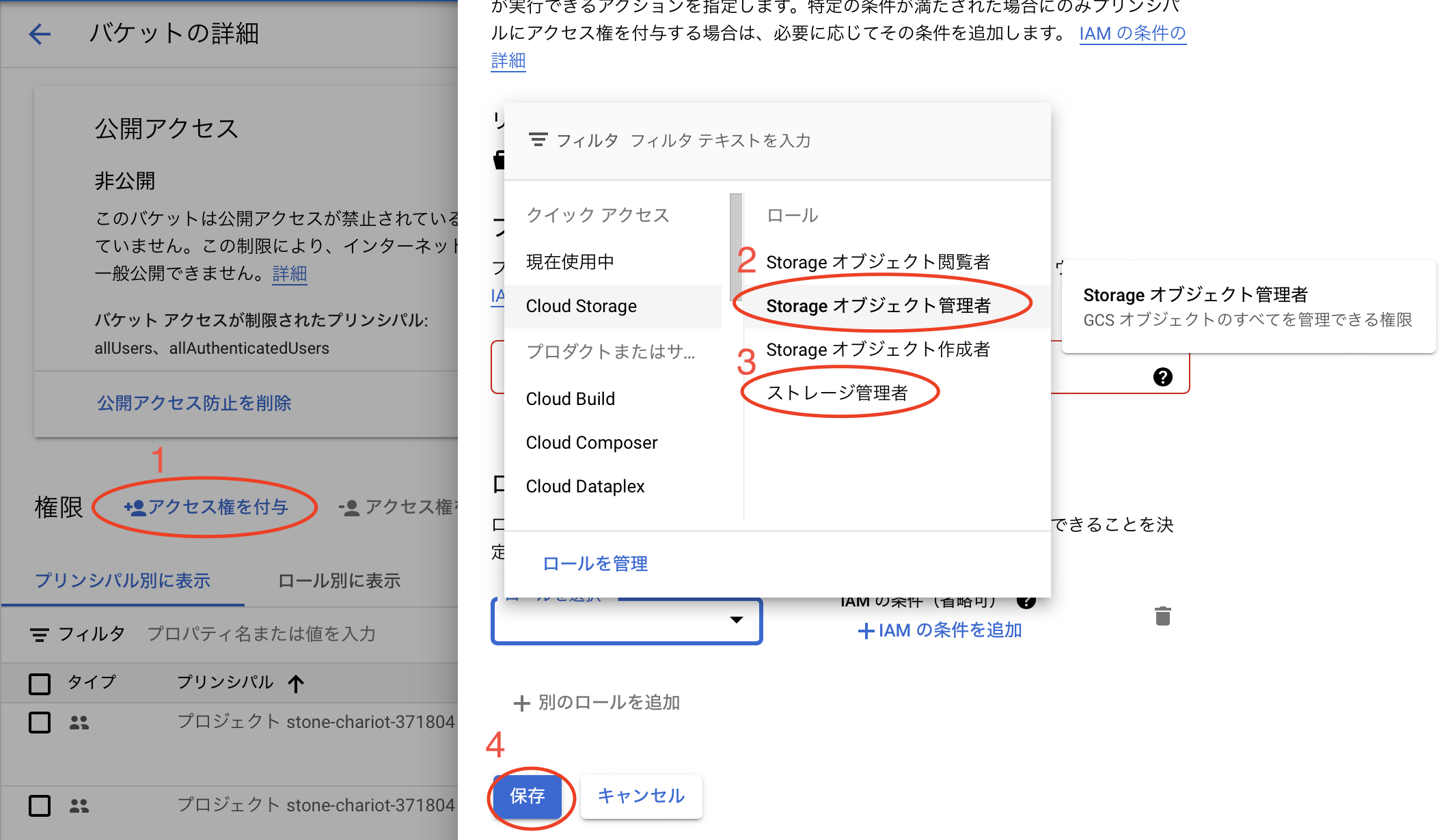
以上で設定は終わりです。お疲れさまでした。
Djangoの実装
次にDjangoの実装を行います。必要なライブラリが多いので、こちらからライブラリを仮想環境にインストールしてください。(このrequirements.txtをローカルに保存し、pip install -r requirements.txtとするとインストールできる。)
適当なフォルダを作成し、その中で以下のコマンドを実行し、Djangoプロジェクトを作成します。
sh237:SaveSpeechAsTextFront:~ $ django-admin startproject SaveSpeechAsTextBack
sh237:SaveSpeechAsTextFront:~ $ cd SaveSpeechAsTextBack
sh237:SaveSpeechAsTextFront:~ $ python manage.py startapp api
以下のような構成になっていると思います。
SaveSpeechAsTextBack
├── api
│ ├── migrations
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
└── SaveSpeechAsTextBack
├── __init__.py
├── asgi.py
├── settings.py
├── urls.py
└── wsgi.py
次にsettings.pyの設定を行います。
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
"api.apps.ApiConfig", #追加(アプリの登録)
"rest_framework", #追加(DRFの設定)
"corsheaders", #追加(CORSの設定)
]
MIDDLEWARE = [
"django.middleware.security.SecurityMiddleware",
"django.contrib.sessions.middleware.SessionMiddleware",
"django.middleware.common.CommonMiddleware",
"django.middleware.csrf.CsrfViewMiddleware",
"django.contrib.auth.middleware.AuthenticationMiddleware",
"django.contrib.messages.middleware.MessageMiddleware",
"django.middleware.clickjacking.XFrameOptionsMiddleware",
"corsheaders.middleware.CorsMiddleware", #追加
]
#CORS_ORIGIN_WHITELISTを追記する。
CORS_ORIGIN_WHITELIST = [
"http://localhost:3000"
]
#容量が大きいファイルの型を揃えるための設定
FILE_UPLOAD_HANDLERS = [
'django.core.files.uploadhandler.TemporaryFileUploadHandler',
]
...
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/4.1/howto/static-files/
STATIC_URL = 'static/'
MEDIA_URL = '/media/' #追加
MEDIA_ROOT = os.path.join(BASE_DIR, 'media') #追加
# Default primary key field type
# https://docs.djangoproject.com/en/4.1/ref/settings/#default-auto-field
...
まず先ほど作成したapiアプリを認識できるようにし、さらにCORSの設定をします。CORSの設定をしないとフロントエンドからAPIを叩くことが出来ません。また、ファイルの容量が大きくなるとファイルの型が異なってしまいエラーを吐くのでFILE_UPLOAD_HANDLERSの設定も行います。また、オーディオファイルをアップロードするmediaフォルダの指定もします。
次にルーティングの設定として、urls.pyに処理を追加します。まずSaveSpeechAsTextBack/urls.pyを以下のようにします。
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path("api/", include("api.urls")),
]
これにより、urlでlocalhost:8000/api/〇〇にアクセスすると、〇〇以降のパスの検索はapiフォルダのurls.pyの中で検索されます。そこで、apiフォルダにurls.pyを作成し、以下のように書きます。
from django.urls import path, include
from rest_framework import routers
from .views import AudioFileView,TextView
from django.conf import settings
from django.conf.urls.static import static
urlpatterns = [
path('speech2text/<str:filename>', AudioFileView.as_view(), name='speech2text'), # 音声認識API
]
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
ここでは音声認識APIのエンドポイントを定めています。パスにファイル名を追加したのは、パスかヘッダーにPOSTで送るファイルのファイル名を含めなければならないからです。ヘッダーにファイル名入れても良かったのですが、URLに入れた方がわかりやすいと思ったからです。上記のルーティングにより、例えば、localhost:8000/api/speech2text/record.wavにPOSTでアクセスすると、record.wavをPOSTで送信し、その音声認識結果を返してくれるAPIになります。
次にフロントエンドから送信された拡張子が.cafの音声ファイルを扱いやすい.wavに変換するconvert_to_wav.pyを作成します。
from django.core.files import File
from pathlib import Path
import subprocess
import os
def convert_to_wav(audio_file, target_filetype='wav', content_type='audio/x-caf',bitrate="128k"):
""".cafファイルを.wavファイルに変換する"""
file_path = audio_file.temporary_file_path()
new_path = file_path[:-3] + target_filetype
#ファイルの情報を表示
subprocess.run(f"afinfo {file_path}", shell=True)
#コマンドによってwavファイルに変換
subprocess.run(f"afconvert -f WAVE -d LEI16@44100 -c 1 -b 128000 {file_path} {new_path}", shell=True)
#変換後のファイルをFileオブジェクトに変換
converted_audiofile = File(
file=open(new_path, 'rb'),
name=Path(new_path)
)
converted_audiofile.name = Path(new_path).name
converted_audiofile.content_type = content_type
converted_audiofile.size = os.path.getsize(new_path)
return converted_audiofile
pythonではsubprocessライブラリによってコマンドを扱うことができます。ここではcafファイルをwavファイルに変換するためにafconvertコマンドを使います。(このコマンドはMacOSだけでしか使えないため、Windowsでは他の方法でcafファイルをwavファイルに変換しなければならない。FFmpegコマンドで変換できるかも?)
次にmodels.pyの作成をします。Google Cloud関連、音声認識の処理はインスタンスメソッドとしてmodels.pyに書きました。その理由としては、各モデルインスタンスは音声ファイルを保持しているため、他からアクセスするよりここで書いたほうが簡潔になるからです。また、先程保存したjsonファイルをapiフォルダに移動させておいてください。(正直どこにおいてもパスさえ指定すればいいのですが、管理しやすいので。gitで管理するなら.gitignoreに含めておいたほうが良いです。)
以下の該当部分を移動後のパスに書き換えてください。
from django.db import models
from google.cloud import speech
from google.cloud import storage
from pydub import AudioSegment
import os
# 環境変数の設定
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '先程保存したjsonキーへのパス'
GCS_BASE = "gs://先程作成したバケット名/"
class AudioModel(models.Model):
file = models.FileField(blank=False, null=False, upload_to='audio/')
def __str__(self):
return self.file.name
def predicted_text(self):
client = storage.Client() # GCSのクライアントを作成
bucket = client.get_bucket('ssat_bucket') # バケットを取得
transcribe_file = self.file.name # ファイル名を取得
sound = AudioSegment.from_wav(self.file.path) # 音声ファイルを読み込み
sound.set_channels(1) # チャンネル数を1に変換
sound.set_frame_rate(44100) # サンプリングレートを44100に変換
sound.export(self.file.path, format="wav") # 変換した音声ファイルを上書き保存
length = sound.duration_seconds # 音声ファイルの長さを取得
length += 1 # 音声ファイルの長さに1秒を足す
if length > 60:
blob = bucket.blob(transcribe_file) # バケットにファイルをアップロード
blob.upload_from_filename(filename=self.file.path) # ファイルをアップロード
result = self.transcribe_model_selection_gcs(
gcs_uri=GCS_BASE + transcribe_file,
length=length) # 1分以上の音声ファイルをテキストに変換する
else:
result = self.transcribe_model_selection(
length=length) # 1分未満の音声ファイルをテキストに変換する
return result # テキストを返す
def transcribe_model_selection(self, length):
"""1分未満のファイルをテキストに変換する。
この場合は、音声ファイルをローカルに保存してから変換する。"""
client = speech.SpeechClient() # Speech-to-Textのクライアントを作成
# 音声ファイルを読み込み
with open(self.file.path, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content) # 音声ファイルを読み込み
# 音声ファイルの設定
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=44100,
language_code="ja-JP",
audio_channel_count=1,
)
# 音声ファイルをテキストに変換
response = client.recognize(config=config, audio=audio)
# テキストを返す
results = []
for i, result in enumerate(response.results):
alternative = result.alternatives[0]
results.append(alternative.transcript)
return results
def transcribe_model_selection_gcs(self, gcs_uri, length):
"""1分以上の音声ファイルをテキストに変換する。
この場合は、音声ファイルをGCSに保存してから変換する。"""
client = speech.SpeechClient() # Speech-to-Textのクライアントを作成
audio = speech.RecognitionAudio(uri=gcs_uri) # 音声ファイルを読み込み
# 音声ファイルの設定
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.ENCODING_UNSPECIFIED,
sample_rate_hertz=44100,
language_code="ja-JP",
model="default",
)
# 音声ファイルをテキストに変換
operation = client.long_running_recognize(config=config, audio=audio)
# テキストを返す
results = []
results_str = ""
response = operation.result(timeout=length*2)
for i, result in enumerate(response.results):
alternative = result.alternatives[0]
results_str += alternative.transcript
results.append(results_str)
return results
このAudioModelには音声ファイルを保存するfileフィールドがあり、保存されたファイルはmedia/audio/に保存されます。predicted_textメソッドによって上記のconvert_to_wav.pyで処理された後の音声ファイルをpydubライブラリによってさらにオーディオの設定をし、音声の長さを取得します。その音声が1分未満であればtranscribe_model_selectionメソッドを用い、1分以上であればtranscribe_model_selection_gcsメソッドを用いて音声認識をGoogle CloudのAPIで行います。先程も説明したように、音声が1分未満であれば同期的に処理でき、ローカルのファイルを指定して処理できますが、1分以上になると非同期的に処理することとなり、Google Cloudのバケットに音声ファイルをアップロードする必要があります。どちらの処理にも共通しているのは、まずSpeech-to-Textのクライアントを作成し、音声ファイルを読み込みます。さらに音声ファイルの設定を行いclient.recognizeかclient.long_running_recognizeメソッドを用います。結果は要素が1つの配列にして返しています。
from rest_framework import serializers
from .models import AudioModel,TextModel
from django.core.validators import FileExtensionValidator
class AudioFileSerializer(serializers.Serializer):
""""Aufioファイルを受け取るためのシリアライザ"""
file = serializers.FileField(
validators=[FileExtensionValidator(allowed_extensions=['wav', 'caf', 'mp3', 'm4a', 'flac'])])
class Meta:
model = AudioModel
fields = ('file',)
def create(self,validated_data):
return AudioModel.objects.create(**validated_data)
DRFにおけるシリアライザーとは、簡単に言えばデータの入出力を上手く処理してくれるようなものです。正確には、DjangoのモデルインスタンスやQuerySetなどのデータをPython標準のリストや辞書などに変換するしてくれるものです。そのため、jsonなどの他の形式への変換が簡単にできるため、serializerがデータをjsonなどに変換してくれるものと認識している人は多いと思います。ここでは、FileFieldを定義しており、音声ファイルを保持します。
最後に以上のconvert_to_wav.py、models.py、serializers.pyの3つを呼び出し、APIリクエストを解決してリクエストを返す処理を行うviews.pyを書いていきます。
from rest_framework import generics
from .convert_to_wav import convert_to_wav
from rest_framework.response import Response
from rest_framework import status
from .models import AudioModel
from .serializers import AudioFileSerializer,TextSerializer
from rest_framework.parsers import MultiPartParser
import json
class AudioFileView(generics.GenericAPIView):
serializer_class = AudioFileSerializer
parser_classes = [MultiPartParser, ]
queryset = AudioModel.objects.all()
def post(self, request, *args, **kwargs):
#ファイルを受け取る
file_obj = request.data
temp_audio_file = request.FILES['file']
#ファイルをwavファイルに変換
converted_temp_audio_file = convert_to_wav(temp_audio_file)
file_obj['file'] = converted_temp_audio_file
#ファイルが正しいか確認する
serializer = AudioFileSerializer(data=file_obj)
if not serializer.is_valid():
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
#ファイルを保存する
model = serializer.save()
result = model.predicted_text()
return Response(json.dumps({"result":result}), status=status.HTTP_201_CREATED)
GenericAPIViewのpostメソッドをオーバーライドし、POSTリクエスト時の振る舞いを書きます。まずファイルをrequestから受け取り、convert_to_wavメソッドによりcafファイルをwavファイルに変換します。次にserializerによってファイルが正しいのか確認し、正しい場合にpredicted_textメソッドにより音声認識を行い、その結果をresult変数で受け取り、レスポンスにjsonとして返しています。
以上でバックエンドの実装も終わりです。お疲れさまでした。
後はエディターでフロントエンドとバックエンドを2つのウィンドウで同時に開き、実行するだけなはずです。
フロントエンド
sh237:SaveSpeechAsTextFront:~ $ npx expo start
もしくは
sh237:SaveSpeechAsTextFront:~ $ npm start
でQRコードが出てきたらOKです。PCと同じWIFI環境であれば実機で表示されたQRコードを読み取ることで動作確認も出来ます。iOSシュミレーターを用いる場合には、ターミナルにiを入力することで実行できます。(iOSのシミュレーターを使うにはこちらが参考になると思います。アンドロイドのエミュレーターを使うにはこちらが参考になると思います。)
バックエンド
仮想環境に入った状態で以下のコマンドを入力してください。
sh237:SaveSpeechAsTextBack:~ $ python manage.py runserver
動作確認
上手く行けば以下の画像のようにタイトル(要約)以外は実装されている状態だと思います。再生ボタンを押し、RECに変わった状態で話しかけ、もう一度ボタンを押すことで音声認識が行われ、少し待つと結果が表示されると思います。

長くなってしまったのでタイトル自動生成は記事を分けようと思います。後半はこちらから。