はじめに
この記事の内容は日本オラクルが運営するOracle Cloud Hangout Cafe (OCHa Cafe)というMeetupのSeason9 #1 「Graph Database と Generative AI の素敵な関係」で発表した内容をベースに記載しております。
資料も公開していますのでご興味のある方はこちらも御覧ください。
なぜGraphRAGか
Large Language Model (LLM) が開発され、世の中的にAIが注目されています。LLMはWikipediaなどの公開情報を学習データしており、高度なテキスト生成が可能です。ただし、非公開の社内情報や最新の情報も踏まえた生成を行うニーズが増え、Retrieval-Augmented Generation (RAG) という技術が登場しました。RAGはLLMのテキスト生成に、外部情報の検索を組み合わせ、回答の精度を向上させる手法です。RAGの検索先のデータソースとして、複雑なデータの関係性を検索可能なGraphが注目されています。Graphを検索ソースとしたRAGをGraphRAGといいます。
今回は、Graph本来の技術や特徴に触れながら、GraphRAGの優位性と構築方法について紐解きます。またAIやRAGの構成で使われるOSSフレームワークを使い、Oracle Databaseを使ったGraphRAGを試してみます。
Graphとは
グラフは頂点 (Node, Vertex) と辺 (Edge, Relation, Link) で表されるデータモデルです。グラフは、エンティティをNodeとして表し、エンティティ同士の関係性をEdgeで表します。例えば、人物、物や場所はNodeとなります。一方、兄弟、姉妹、居住などの関係性を表す言葉はEdgeとなります。
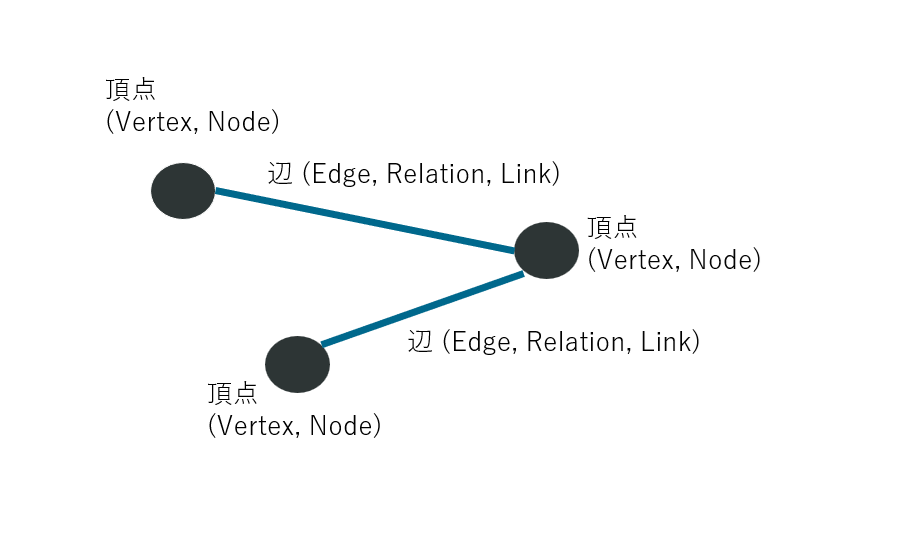
グラフの種類には、「主語 (Subject) - 述語 (Predicate) - 目的語 (Object)」というトリプルベースで表現されるRDF Graphと、ノードとエッジに属性 (Property) を持たせることで柔軟にスキーマを変更できるProperty Graphの2種類あります。
今回は、Property Graphをベースに解説します。
Property Graph
Property Graphは、NodeとEdgeで表されるデータモデルに、LabelやPropertyという属性情報を付与することができます。LabelやPropertyを追加することで、スキーマを意識せず自由にグラフを拡張できます。
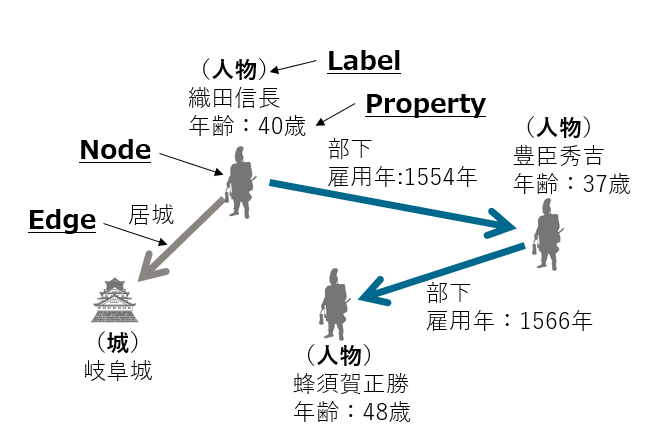
| 要素 | 説明 | 例 |
|---|---|---|
| Node | データのエンティティを表す | 織田信長 |
| Edge | ノード間の関係性を表す | 部下 |
| Label | ノードやエッジにカテゴリやタイプで識別できるように種類を付与できる | (人物) |
| Property | Key-Valueでノードやエッジに属性データを付与できる | 年齢:40歳 |
Graph Databaseとは
グラフデータベースとは、グラフのデータモデルを管理、操作するためのオンラインデータベース管理システムです。
データベースとして、基本的なデータの管理やCRUD操作の機能があります。また、グラフデータモデル特有のグラフを辿る検索 (トラバーサル) やグラフアルゴリズムを実行する機能があります。
トラバーサル
リレーショナルなデータモデルとグラフデータモデルを比較した際に、グラフデータベースの特徴として、グラフを辿る探索 (トラバーサル)が高速な点が挙げられます。
グラフの各Nodeは接続先のEdgeとNodeの情報を持っており、データモデル探索時に経路に関するデータのみのアクセスでグラフを辿ることが可能なため、リレーショナルなデータモデルよりも、関係性を辿る検索は高速に結果を取得できます。この検索のことをパターンマッチングと言います。
グラフアルゴリズム
グラフデータモデルを扱うメリットとして、グラフに対してグラフアルゴリズムを実行できる点が挙げられます。
グラフアルゴリズムとは、グラフデータを効率的に操作、分析、利用するための手法やプロセスのアルゴリズムのことです。今回は冗長になるのでグラフアルゴリズムについては深堀しません。
Relational DatabaseとGraph Databaseの違い
一般的に広く使われているRelational Database (RDB) と Graph Database (GraphDB) のリレーションの違いについてまとめます。
Relational Database
RDBのデータ構造は、行と列の表形式でリレーションを用いて表されます。特にスキーマが厳格に決まっており、intやstringといったデータの形式やカラム名、Null値の扱いなどが事前に定義されます。
またクエリ言語は、宣言型のSQLで記述します。関係性を取得する際はJoinを使ってデータを取得します。複数の関係性を含んだデータを取得する場合は、Joinで複数のテーブルを結合しデータを取得するため、結合するテーブル数に依存してSQLクエリが長くなります。
Graph Database
GraphDBのデータ構造は、ノードとエッジによって関係性が表されます。スキーマが柔軟で、ノードやエッジに対して自由にプロパティを追加することができます。
クエリ言語は、Graph Query Language (GQL)で記述します。GQLを使いノードとエッジの関係を直接記述し、データを取得します。関係性を直接書くことが可能なため、複数の関係性を含んだデータ取得においても、クエリが短く、高速なトラバース処理により結果を取得できます。
以下の表にまとめています。
| Relational Database | Graph Database | |
|---|---|---|
| データ構造 | 行と列の表形式 | ノードとエッジによる関係性の表現 |
| スキーマ | 厳格なスキーマで管理 | スキーマレス |
| クエリ言語 | SQL | GQL (e.g. Cypher, PGQL) |
| イメージ |  |
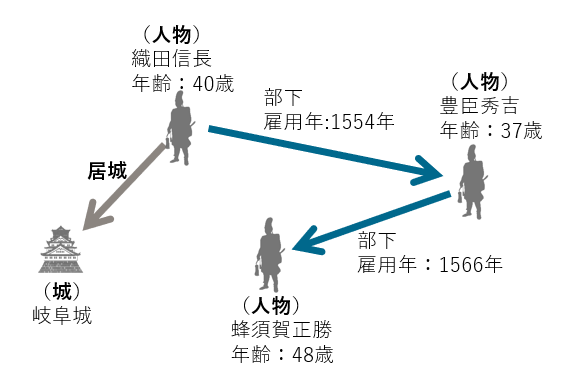 |
ここまで、GraphとGraph Databaseについて説明しました。次に、LLMとGraphの関係性について深ぼっていきます。
ココからは、LLMの活用で注目されているRAGの技術へ、Graphをする応用する方法について解説していきます。
Retrieval-Augmented Generation (RAG)とは
RAGとは、入力されたテキストに対して回答を生成する際に、外部ソースの情報検索と組み合わせることで回答精度を高める方法です。外部ソースとして最新のWeb情報や社内データベースの機密情報を用意し、入力に応じて検索することでLLMが知らない情報も出力に反映させることができます。
このRAGの手法で検索方法として使われているのがベクトルを使った類似度検索 (ベクトル検索) です。外部ソースを検索する際に、既存のデータのテキストや画像を数値のベクトルで表現します。入力も同様にベクトルに変換し、ベクトル同士の距離を計算することで類似度を測ることができます。この方法を使うことで入力に類似度が高いデータを検索することができます。
ベクトル検索を使ったRAGについては、こちらの記事で試しています。
ベクトル検索を使ったRAGの課題
上記で説明したベクトルを使ったRAGは以下のような課題があります。
- データの複雑な関係性を取得する際に、離れたデータの関係性を結び付けることが苦手
- 大規模なドキュメントにおいて、チャンクに跨る文脈を総合的に理解することが苦手
これらの課題に対して、データソースに知識ベースのGraph (Knowledge Graph) を使うことで横断的にリソースを検索することが可能になります。この手法をGrpahRAGと言い、RAGの精度向上が期待されています。
GraphRAGとは
GraphRAGは、RAGの検索システムにKnowledge Graphを使用したRAGの手法です。Graphを用いることで、グラフを辿る検索による、離れた複雑な関係性を持つデータも結び付けて取得することができます。またチャンクに分割するような大きなドキュメントに対しても、ドキュメントの要素がノードとエッジで表されるため、文脈を総合的に理解した検索が可能になります。
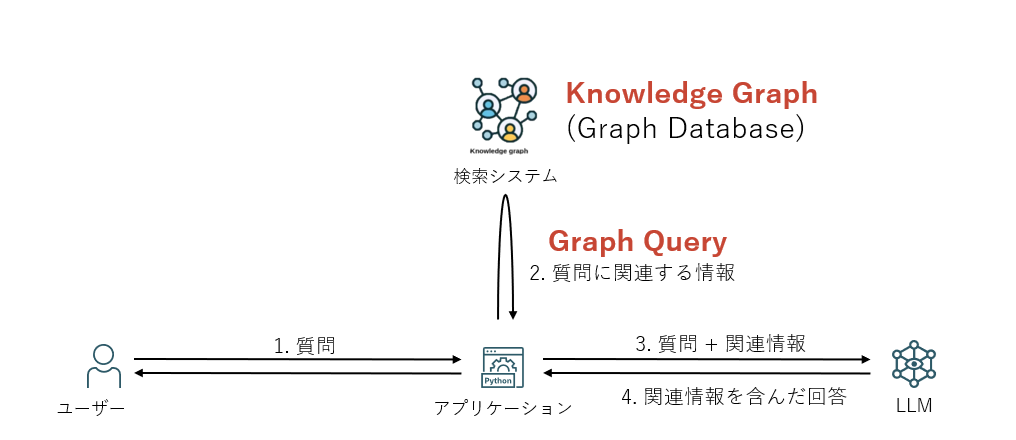
従来型のRAGとGraphRAGの比較
従来型のRAG (Vector)とGraphRAGの違いを簡単に表にまとめています。
| 従来のRAG (Vector) | Graph RAG | |
|---|---|---|
| データストア | Vector Store | Graph Store |
| 複雑性 | クエリに条件を複数付与すると、情報を速く正確に見つけるのが難しくなる | クエリに条件を複数付与しても、情報があれば速く正確に見つけられる |
| 完全性 | 類似度による取得のため、不完全、無関係な結果を提供する可能性がある | ノードとエッジで接続されているので、グラフに存在する正確な答えを返す |
| データソースの透明性 | 誤った情報を検索した場合、Vectorの類似性で判断しているため、誤った原因を特定できない | 誤った情報を検索した場合、検索されたデータを確認し原因を特定できる |
こちらの記事を参考にしています。
Oracle Graphとは
Oracle Graphとは、Oracle DatabaseにGraphの機能が備わっており、Oracle Databaseに入っているリレーショナルなデータをGraphのビューとして扱うことができる機能です。
これまでのOracle Databaseの機能はそのままで、Oracleが開発した高速なグラフ探索やグラフアルゴリズムを利用できます。
対応しているグラフは、RDF Graph, Property Graphで、対応しているクエリ言語は、SQL, PGQL, SPARQLです。
テーブルのグラフ化
Oracle Graphの特徴のひとつにRDB内のテーブルをグラフのビューに変換するCreate Property Graph 句があります。
詳細は、こちらの記事で詳しく書かれていますのでご参考ください
VERTEX TABLES句でノード情報を含んだテーブルを指定し、エッジをEDGE TABLES句を使い
で、エッジの情報をソースとターゲットを
SQLを用いたグラフクエリの実行
Oracle Graphのもう一つの特徴として、最新のSQL標準であるSQL:2023から追加されたProperty Graphの記法を23aiからサポートしています。
GRAPH_TABLE句の中に、グラフクエリを記載することで、SQLでグラフのビューに対してパターンマッチングを実行できます。
Oracle Graphを使ったGraphRAGを試してみる
前提
本記事で試す環境は、以下の前提で動作検証しています。
- Python: 3.11.9
- oracledb: 2.4.1
- LangChain: 0.3.0
0. 事前準備
OCIの環境構築
グラフデータベースとしてOracle Database 23aiを使います。
Oracle Database 23aiの構築方法は、OCI Tutorialの「101: ADBインスタンスを作成してみよう」と、「215 : Graph Studioで金融取引の分析を行う」を参考にしてください。
GitリポジトリのClone
今回使うソースコードはこのGitHubに公開しています。
$ git clone -b dev/oracle_graph https://github.com/sh-sho/langchain.git
$ git clone https://github.com/sh-sho/ochacafe_graphrag.git
次にPythonのライブラリをインストールします。requirements.txtに必要なライブラリが記載されているので以下のコマンドでインストールをします。
$ pip install -r ./ochacafe_graphrag/requirements.txt
langchain-communityのライブラリはアンインストールしてください。
$ pip uninstall langchain-community
環境変数の設定
次に環境変数を設定します。
.env.exampleファイルをコピーして.envファイルを作成します。
$ cp .env.example .env
.envの内容をご自身の環境に合わせて書き換えます。
ORACLE_USERNAME=user
ORACLE_PASSWORD=pw
ORACLE_DSN=dsn
ORACLE_JDBC=xxxx
ORACLE_WALLET_DIR=xxx
ORACLE_WALLET_PASSWORD=wallet_pw
AZURE_OPENAI_ENDPOINT=https://xxx
AZURE_OPENAI_API_KEY=xxxx
AZURE_OPENAI_API_VERSION=2024-xxxx
AZURE_OPENAI_CHAT_DEPLOYMENT_NAME=gpt-4o
GRAPH_NAME=xxxx
ORACLE_USERNAME, ORACLE_PASSWORD, ORACLE_DSNはOracleDatabaseに接続するための環境変数です。本コードはoracleユーザか同等の権限を持ったユーザで実行可能です。対応するユーザ名、パスワード、DSNを設定してください。
また、今回はAzureOpenAIを用いていますが、通常のOpenAIでも実行可能です。
コードはoracle_graph_demo/oracle_graph_demo.ipynbのNotebookに書かれています。上から順に実行して下さい。必要なライブラリのインストール、環境変数の設定、Oracle Databaseへの接続のコードを実施したのち、以下の内容へ進んでください。
1. テキストからのノードとエッジの要素抽出
今回は、LangChainのフレームワークを活用し、テキストからOracle Graphを作成します。
まず、LangChainのLLMGraphTransformer関数を使い、テキストからノードとエッジとなる要素を抽出します。
今回扱うテキストは、織田信長の歴史に関する文章を用います。織田信長の家臣や出身などの情報が含まれています。
text = """
織田 信長(おだ のぶなが)は、日本の戦国時代から安土桃山時代にかけての武将・大名。戦国の三英傑の一人。
尾張国(現在の愛知県)出身。織田信秀の嫡男。家督争いの混乱を収めた後に、桶狭間の戦いで敵大将の今川義元を討ち取り、勢力を拡大した。足利義昭を奉じて上洛し、後には義昭を追放することで、畿内を中心に独自の中央政権(「織田政権」[注釈 4])を確立して天下人となった。
豊臣秀吉、徳川家康や明智光秀を家臣とし信長の政権を広げた。しかし、天正10年6月2日(1582年6月21日)、家臣・明智光秀に謀反を起こされ、本能寺で自害した。
これまで信長の政権は、豊臣秀吉による豊臣政権、徳川家康が開いた江戸幕府への流れをつくった画期的なもので、その政治手法も革新的なものであるとみなされてきた[2]。しかし、近年の歴史学界ではその政策の前時代性が指摘されるようになり、しばしば「中世社会の最終段階」とも評され[2]、その革新性を否定する研究が主流となっている
"""
LLMGraphTransformerのパラメータとして、allowed_nodesとallowed_relationshipsで、抽出するノードとエッジを事前に定義することができます。
ノードとしてPerson, Place, Roleを、エッジとしてRetainer, Resides_at, Had_roleを抽出します。
llm_transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Place", "Role"],
allowed_relationships=["Retainer", "Resides_at", "Had_role"]
)
documents = [Document(page_content=text)]
graph_documents = llm_transformer.convert_to_graph_documents(documents)
print(graph_documents)
抽出されたGraphDocumentの結果がこちらです。
[GraphDocument(
nodes=[
Node(id='織田信長', type='Person', properties={}),
Node(id='尾張国', type='Place', properties={}),
Node(id='愛知県', type='Place', properties={}),
...
Node(id='本能寺', type='Place', properties={})],
relationships=[
Relationship(
source=Node(id='織田信長', type='Person', properties={}),
target=Node(id='尾張国', type='Place', properties={}),
type='RESIDES_AT', properties={}),
...
Relationship(
source=Node(id='織田信長', type='Person', properties={}),
target=Node(id='明智光秀', type='Person', properties={}),
type='RETAINER', properties={})],
source=Document(metadata={}, page_content='\n織田 信長(おだ のぶなが)は、日本の戦国時代から安土桃山時代にかけての武将・大名。
...
しかし、近年の歴史学界ではその政策の前時代性が指摘されるようになり、しばしば「中世社会の最終段階」とも評され[2]、その革新性を否定する研究が主流となっている\n')
)
]
ノードとして織田信長, 本能寺などが、エッジとして織田信長と尾張国とのRESIDES_ATという関係性が抽出されています。
2. Oracle Graphの作成
次に、抽出されたGraphDocumentの要素からOracle Graphを作成します。今回は、OracleGraphというクラスを作成しており、クラスの中でOracle Databaseへの接続 → テーブルの作成 → グラフの作成を行っています。一連の処理をadd_graph_documentsで実行します。グラフの名前はperson_graphとします。
client = OracleGraph(url=JDBC_URL, username=UN, password=PW)
client.add_graph_documents(graph_documents=graph_documents, graph_name='person_graph')
実行結果として以下のようなグラフが作成されます。
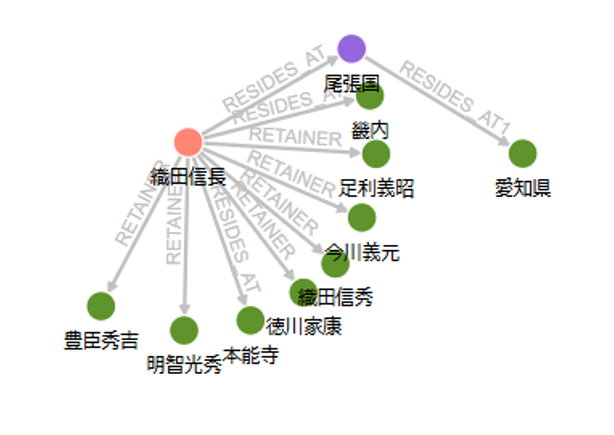
3. パターンマッチングによる検索
作成したグラフに対してグラフクエリを実行してみます。まず、person_graphに対してPERSONラベルがついたノードのidを取得してみます。
select_query = """
SELECT *
FROM GRAPH_TABLE( PERSON_GRAPH
MATCH (n IS Person)
COLUMNS(n.id)
)
"""
sql_results = client.query(query=select_query)
print(sql_results)
上記のように、MATCH句以降のグラフクエリをGRAPH_TABLE句を用いることSQLとして実行できます。グラフ検索の結果は以下のようになります。
[('織田信長',), ('織田信秀',), ('今川義元',), ('足利義昭',), ('豊臣秀吉',), ('徳川家康',), ('明智光秀',)]
Personというラベルがついた、人物のノードを取得できています。
4. グラフのパターンマッチングによる出力生成
ここまでで、ドキュメントをグラフ化し、グラフクエリを用いてグラフに対してパターンマッチングを行い結果を取得することができました。
ただ昨今のRAGのユースケースを考えると、自然言語で入力を行い、グラフクエリを使った検索を行い、自然言語で出力される一連の流れを自動化することが望ましいです。
というわけで、今回はAgentとTool Callingを使い自然言語でのやり取りの中にグラフ検索を加えたGraph RAGを実装します。
Toolは以下の3つ作成します。
- RetainerTool: 部下を取得するSQLを返すTool
class RetainerToolInput(BaseModel):
query: str = Field(description="A query for RetainerTool")
names: str = Field(description="Name of target person")
class RetainerTool(BaseTool):
name: str = "retainer_tool"
description: str ="""
A function that identifies someone who is retainer a particular person
and returns the names of both individuals.
"""
args_schema: Type[BaseModel] = RetainerToolInput
def _run(self, names: str, *args: Any, **kwargs: Any) -> str:
GRAPH_NAME = os.getenv("GRAPH_NAME")
return f"""
SELECT a, b
FROM GRAPH_TABLE({GRAPH_NAME}
MATCH (a IS Person) - [e] -> (b IS Person)
WHERE e.name = 'RETAINER' and a.id = '{names}'
COLUMNS(a.id as a, b.id as b))
"""
- RoleTool: 役割を取得するSQLを返すTool
class RoleToolInput(BaseModel):
query: str = Field(description="A query for RoleTool")
names: str = Field(description="Name of target person")
class RoleTool(BaseTool):
name: str = "role_tool"
description: str = """
A function that identifies a role a particular person holds
and returns the names of the person and the role.
"""
args_schema: Type[BaseModel] = RoleToolInput
def _run(self, names: str, *args: Any, **kwargs: Any) -> str:
GRAPH_NAME = os.getenv("GRAPH_NAME")
return f"""
SELECT a, b
FROM GRAPH_TABLE({GRAPH_NAME}
MATCH (a IS Person) - [e] -> (b IS Role)
WHERE e.name = 'HAD_ROLE' and a.id = '{names}'
COLUMNS(a.id as a, b.id as b))
"""
- ResideTool: 居住地を取得するSQLを返すTool
class ResideToolInput(BaseModel):
query: str = Field(description="A query for ResideTool")
names: str = Field(description="Name of target person")
class ResideTool(BaseTool):
name: str = "recommend_tool"
description: str ="""
A function that identifies a person who reside at particular place
and returns the names of the person and the place.
"""
args_schema: Type[BaseModel] = ResideToolInput
def _run(self, names: str, *args: Any, **kwargs: Any) -> str:
GRAPH_NAME = os.getenv("GRAPH_NAME")
return f"""
SELECT a, c
FROM GRAPH_TABLE({GRAPH_NAME}
MATCH (a IS Person) - [b is Resides_at] -> (c is Place)
WHERE a.id = '{names}'
COLUMNS(a.id as a, c.id as c))
"""
- SQLExecuteTool: SQLを実行するTool
class SQLExecuteToolInput(BaseModel):
query: str = Field(description="A query for SQLExecuteTool")
class SQLExecuteTool(BaseTool):
name: str = "sql_execute_tool"
description: str = """
A function that executes SQL queries and returns the results.
"""
args_schema: Type[BaseModel] = SQLExecuteToolInput
def _run(self, query: str, *args: Any, **kwargs: Any) -> list:
return client.query(query=query)
各Toolをtoolsとして配列にします。
reside = ResideTool()
role = RoleTool()
retainer = RetainerTool()
sqlexecute = SQLExecuteTool()
tools=[reside, role, retainer, sqlexecute]
次にAgentを使い自然言語で質問に回答するようなヘルプアシスタントを作成します。
先ほど作成したToolもセットします。
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
agent = create_tool_calling_agent(llm=llm, tools=tools, prompt=prompt)
sql_agent = AgentExecutor(agent=agent, tools=tools, verbose=True)
Agentを実行します。
まずは織田信長の部下を聞く質問を入力として渡しています。
sql_agent.invoke({'input': "織田信長の部下は誰ですか?"})
実行すると、まずretainer_toolが選択されていることがわかります。その引数としnamesパラメータに織田信長が渡されSQLを作成しています。その後、
検索結果として、織田信長と部下の関係 (Retainerのエッジを持つノード) が取得され出力に使われています。
Invoking: `retainer_tool` with `{'query': '織田信長の部下', 'names': '織田信長'}`
SELECT a, b
FROM GRAPH_TABLE(PERSON_GRAPH
MATCH (a IS Person) - [e] -> (b IS Person)
WHERE e.name = 'RETAINER' and a.id = '織田信長'
COLUMNS(a.id as a, b.id as b))
Invoking: `sql_execute_tool` with `{'query': "SELECT a, b FROM GRAPH_TABLE(PERSON_GRAPH MATCH (a IS Person) - [e] -> (b IS Person) WHERE e.name = 'RETAINER' and a.id = '織田信長' COLUMNS(a.id as a, b.id as b))"}`
[('織田信長', '織田信秀'), ('織田信長', '今川義元'), ('織田信長', '足利義昭'), ('織田信長', '豊臣秀吉'), ('織田信長', '徳川家康'), ('織田信長', '明智光秀')]
織田信長の部下は以下の人物です:
- 織田信秀
- 今川義元
- 足利義昭
- 豊臣秀吉
- 徳川家康
- 明智光秀
> Finished chain.
最終出力として、以下のような文章が生成されます。
{'input': '織田信長の部下は誰ですか?',
'output': '織田信長の部下は以下の人物です:\n\n- 織田信秀\n- 今川義元\n- 足利義昭\n- 豊臣秀吉\n- 徳川家康\n- 明智光秀'}
Graph RAGにより、Graphの内容をもとに回答を生成しています。今回、今川義元が織田信長の部下として誤った出力がされていますが、これはLLMでエンティティ抽出する際に、ノードを["Person", "Place", "Role"]に限定した影響です。エンティティ抽出に関してチューニングを行えば改善することが可能です。
参考資料