やったこと
「COTOHA API:構文解析の出力結果をグラフ化してみた」で作成されるグラフをViz.jsを用いてブラウザで見られるようにしました。
環境
- macOS 10.14.2
- Python 3.6.5 :: Anaconda, Inc.
- Chrome 72.0.3626.109(Official Build) (64 ビット)
動作の様子
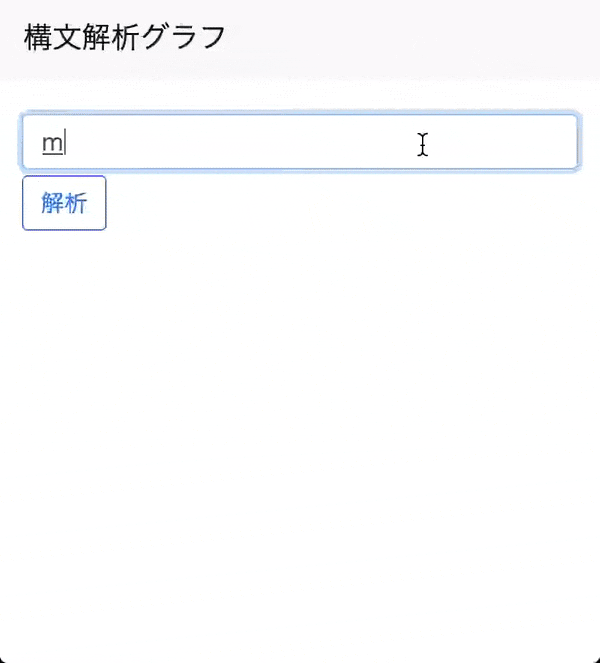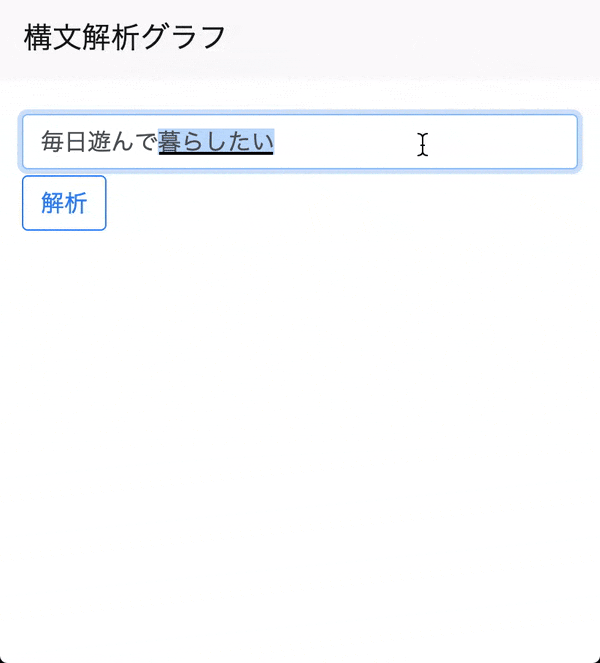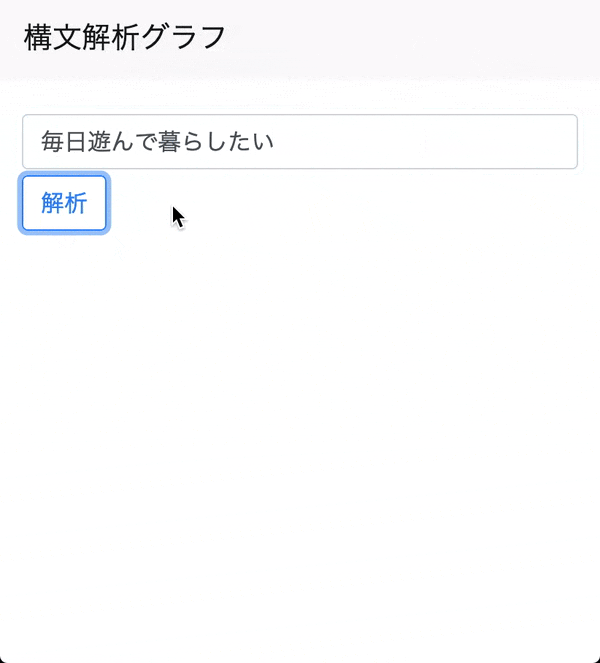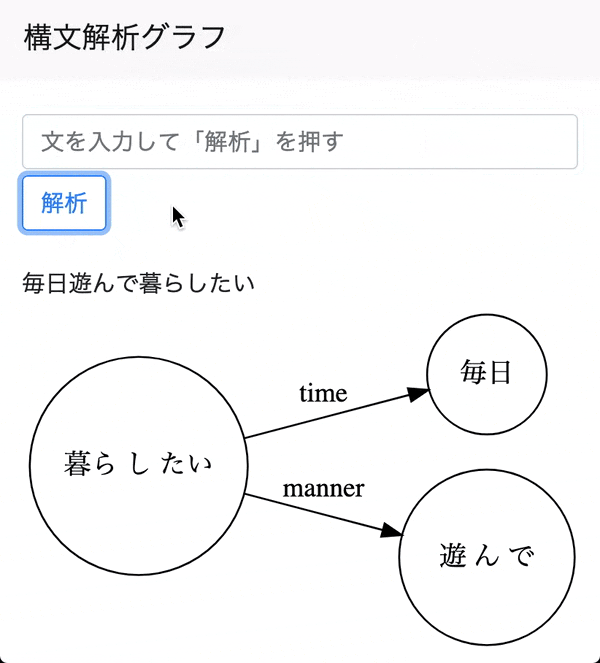
ソースコード
ディレクトリ構成(クリックで展開)
.
├── config.ini
├── cotoha_api.py
├── graph.py
├── cotoha_graph_api.py
├── index.html
├── css
│ └── bootstrap.min.css
└── js
├── bootstrap.bundle.min.js
├── jquery-3.3.1.min.js
├── full.render.js
└── viz.js
cotoha.ini(クリックで展開)
cotoha.ini
[COTOHA API]
Developer API Base URL: https://api.ce-cotoha.com/api/dev/nlp/
Developer Client id: AAAAAAAAAAAAAAAAAAAAAAAAAA
Developer Client secret: aaaaaaaaaaaaaaaaaaaaaaaaaa
Access Token Publish URL: https://api.ce-cotoha.com/v1/oauth/accesstokens
「自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた」の「設定ファイル」です。
COTOHA APIのアカウントを取得して、アカウントホームに表示されるDeveloper Client id、Developer Client secretを記入して下さい。
cotoha_api.py(クリックで展開)
cotoha_api.py
# -*- coding:utf-8 -*-
import os
import urllib.request
import json
import configparser
import codecs
# COTOHA API操作用クラス
class CotohaApi:
# 初期化
def __init__(self, client_id, client_secret, developer_api_base_url, access_token_publish_url):
self.client_id = client_id
self.client_secret = client_secret
self.developer_api_base_url = developer_api_base_url
self.access_token_publish_url = access_token_publish_url
self.getAccessToken()
# アクセストークン取得
def getAccessToken(self):
# アクセストークン取得URL指定
url = self.access_token_publish_url
# ヘッダ指定
headers={
"Content-Type": "application/json;charset=UTF-8"
}
# リクエストボディ指定
data = {
"grantType": "client_credentials",
"clientId": self.client_id,
"clientSecret": self.client_secret
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
res = urllib.request.urlopen(req)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディからアクセストークンを取得
self.access_token = res_body["access_token"]
# 構文解析API
def parse(self, sentence):
# 構文解析API URL指定
url = self.developer_api_base_url + "v1/parse"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"sentence": sentence
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
raise e
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
# 固有表現抽出API
def ne(self, sentence):
# 固有表現抽出API URL指定
url = self.developer_api_base_url + "v1/ne"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"sentence": sentence
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
print ("<Error> " + e.reason)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
# 照応解析API
def coreference(self, document):
# 照応解析API 取得URL指定
url = self.developer_api_base_url + "beta/coreference"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"document": document
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
print ("<Error> " + e.reason)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
# キーワード抽出API
def keyword(self, document):
# キーワード抽出API URL指定
url = self.developer_api_base_url + "v1/keyword"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"document": document
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
print ("<Error> " + e.reason)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
# 類似度算出API
def similarity(self, s1, s2):
# 類似度算出API URL指定
url = self.developer_api_base_url + "v1/similarity"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"s1": s1,
"s2": s2
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
print ("<Error> " + e.reason)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
# 文タイプ判定API
def sentenceType(self, sentence):
# 文タイプ判定API URL指定
url = self.developer_api_base_url + "v1/sentence_type"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"sentence": sentence
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
print ("<Error> " + e.reason)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
# ユーザ属性推定API
def userAttribute(self, document):
# ユーザ属性推定API URL指定
url = self.developer_api_base_url + "beta/user_attribute"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"document": document
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
print ("<Error> " + e.reason)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
if __name__ == '__main__':
# ソースファイルの場所取得
APP_ROOT = os.path.dirname(os.path.abspath( __file__)) + "/"
# 設定値取得
config = configparser.ConfigParser()
config.read(APP_ROOT + "config.ini")
CLIENT_ID = config.get("COTOHA API", "Developer Client id")
CLIENT_SECRET = config.get("COTOHA API", "Developer Client secret")
DEVELOPER_API_BASE_URL = config.get("COTOHA API", "Developer API Base URL")
ACCESS_TOKEN_PUBLISH_URL = config.get("COTOHA API", "Access Token Publish URL")
# COTOHA APIインスタンス生成
cotoha_api = CotohaApi(CLIENT_ID, CLIENT_SECRET, DEVELOPER_API_BASE_URL, ACCESS_TOKEN_PUBLISH_URL)
# 解析対象文
sentence = "吾輩は猫である"
# 構文解析API実行
result = cotoha_api.parse(sentence)
# 出力結果を見やすく整形
result_formated = json.dumps(result, indent=4, separators=(',', ': '))
print (codecs.decode(result_formated, 'unicode-escape'))
「自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた」のcotoha_api_python3.pyです。
graph.py(クリックで展開)
graph.py
from graphviz import Digraph
def graphviz_parse(jsonfile):
dependencies,chunks = extract_dependency_info(jsonfile)
# グラフの初期化
G = Digraph()
G.attr('node', shape="circle")
G.attr(rankdir='LR')
for k in chunks:
G.node(chunks[k])
# 係り受け情報よりノードとエッジを追加
for dependency in dependencies:
G.edge(chunks[dependency[0]],chunks[dependency[1]],label=dependency[2])
# グラフ描写
return G.source.replace("\n", "").replace("\t", " ")
def extract_dependency_info(jsonfile):
chunkid_text_dict = dict()
dependency_info = list()
# 解析結果(json)から係り受け情報を抽出
for chunk in jsonfile["result"]:
chunk_id = chunk["chunk_info"]["id"]
tokens = [token["form"] for token in chunk["tokens"]]
chunkid_text_dict[chunk_id] = " ".join(tokens)
for link in chunk["chunk_info"]["links"]:
dependency_info.append([chunk_id,link["link"],link["label"]])
return dependency_info,chunkid_text_dict
「COTOHA API:構文解析の出力結果をグラフ化してみた」のコードを少し修正しています。
cotoha_graph_api.py(クリックで展開)
cotoha_graph_api.py
import cotoha_api
import graph
from bottle import get, request, static_file, run
from json import dumps
@get('/<filepath:path>')
def root(filepath):
return static_file(filepath, root=APP_ROOT)
@get('/get_dot')
def get_dot():
sentence = request.query.sentence
d = {}
if (sentence):
result = api.parse(sentence)
dot = graph.graphviz_parse(result)
d['text'] = sentence
d['dot'] = dot
else:
d['text'] = ""
d['dot'] = ""
return dumps(d)
# ソースファイルの場所取得
APP_ROOT = cotoha_api.os.path.dirname(cotoha_api.os.path.abspath( __file__)) + "/"
# 設定値取得
config = cotoha_api.configparser.ConfigParser()
config.read(APP_ROOT + "config.ini")
CLIENT_ID = config.get("COTOHA API", "Developer Client id")
CLIENT_SECRET = config.get("COTOHA API", "Developer Client secret")
DEVELOPER_API_BASE_URL = config.get("COTOHA API", "Developer API Base URL")
ACCESS_TOKEN_PUBLISH_URL = config.get("COTOHA API", "Access Token Publish URL")
# COTOHA APIインスタンス生成
api = cotoha_api.CotohaApi(CLIENT_ID, CLIENT_SECRET, DEVELOPER_API_BASE_URL, ACCESS_TOKEN_PUBLISH_URL)
run(host="0.0.0.0", port=int(cotoha_api.os.environ.get("PORT", 8080)))
index.html(クリックで展開)
index.html
<!doctype html>
<html lang="ja">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<link rel="stylesheet" href="./css/bootstrap.min.css">
<title>構文解析グラフ</title>
</head>
<body>
<nav class="navbar navbar-expand-lg navbar-light bg-light">
<span class="navbar-brand">構文解析グラフ</span>
</nav>
<div class="container">
<form class="my-4">
<input type="text" class="form-control mb-1" placeholder="文を入力して「解析」を押す">
<button type="submit" class="btn btn-outline-primary">解析</button>
</form>
<div class="my-1" id="text"></div>
<div id="graph"></div>
</div>
<script src="js/viz.js"></script>
<script src="js/full.render.js"></script>
<script src="./js/jquery-3.3.1.min.js"></script>
<script src="./js/bootstrap.bundle.min.js"></script>
<script>
var url = './get_dot';
var viz = new Viz();
function renderSVG(dot) {
viz.renderImageElement(dot)
.then(function(element) {
$("#graph").html(element);
});
};
function getDot(sentence) {
$.ajax({
url: url + '?sentence=' + sentence,
dataType: 'JSON',
}).done(function(data){
if (data.text != "") {
$("#text").text(data.text);
renderSVG(data.dot);
$("input").val("");
}
});
};
$("button").click(function(){
getDot($("input").val());
return false;
});
</script>
</body>
</html>
CSS/JSファイルの入手先(クリックで展開)
- bootstrap.min.css / bootstrap.bundle.min.js
- Bootstrapのダウンロードページから入手
- jquery-3.3.1.min.js
- jQueryのページから入手
- viz.js / full.render.js
- Viz.jsのリリースページから入手
Pythonライブラリ(クリックで展開)
pip install bottle
pip install graphviz
bottleとgraphvizを使います。
動かし方
- ソースコードをおいたディレクトリ(cotoha_api_graph.pyがあるディレクトリ)で
python cotoha_api_graph.pyを実行 - ブラウザから
http://localhost:8080/index.htmlでアクセス
グラフを縦長にする
grapy.pyの9行目を以下のように変更するとグラフが縦長になります。
スマホからアクセスする場合は、縦長の方がみやすいです。
grapy.pyの9行目
G.attr(rankdir='TB')
そういえば……
COTOHA APIの公式ページに解析デモあったなあと、ここまで作って気付きました。