前回の続き。
WebDriverを導入し、Seleniumが使えるようになったので早速使ってみる。
環境
- macOS Majove (ver 10.14.6)
- Python 2.7.10
- FireFox Quantum 69.0 (64bit)
- Selenium 4.0.0 alpha-1
- geckodriver 0.24.0 for macOS
目標
今回使うのはAccuWeatherという天気サイト
https://www.accuweather.com/en/jp/japan-weather
ここから現在の気温と天候を取得する。場所は 埼玉県さいたま市 とする。
import文
今回は天気情報を取得するだけなので、Seleniumを使う最低限のモジュールのみをインポートする。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
AccuWeatherの構造把握
サイトを開くと、上部中央に検索画面が配置されていることが分かる
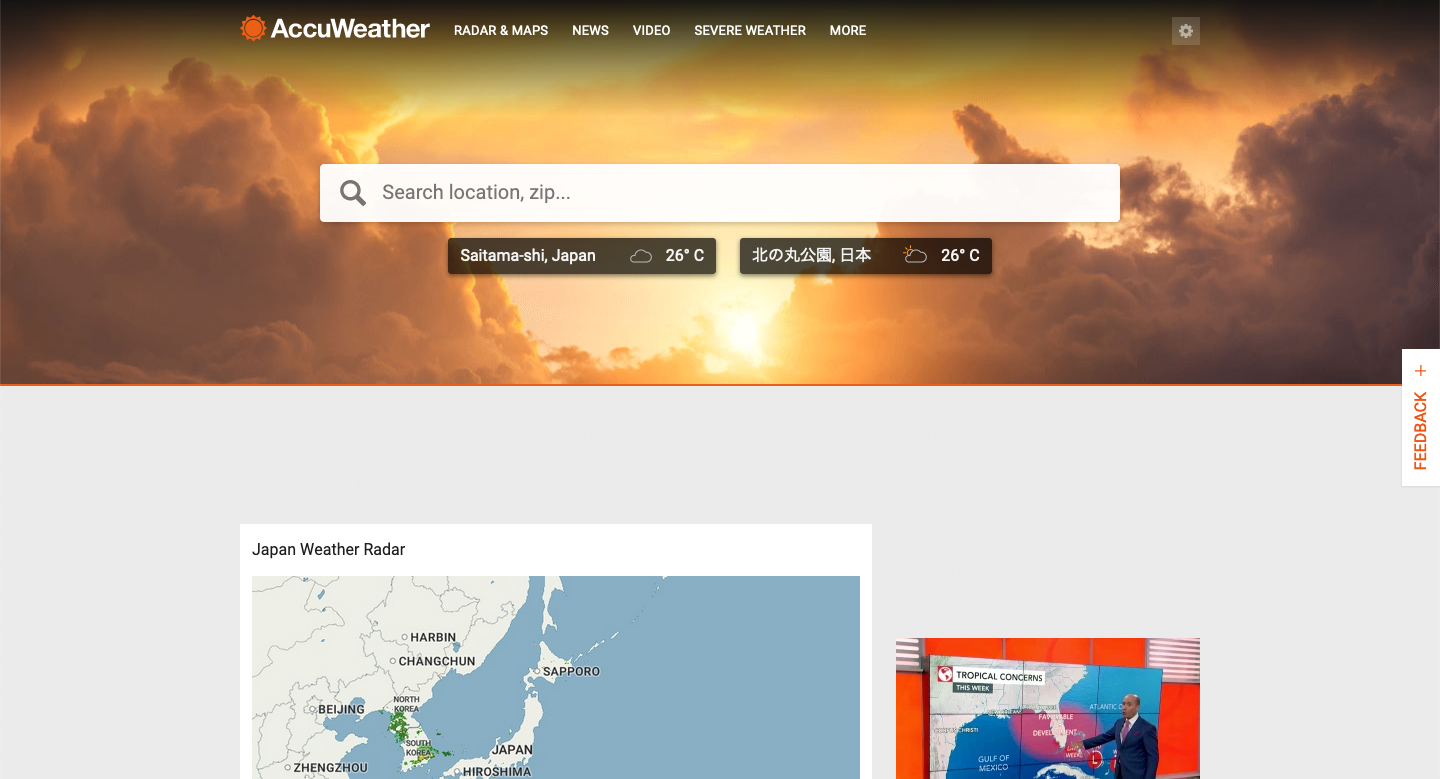
この検索ボックスの構造は以下のようになっている。

簡単に構造化すると以下。
<head>
└ <body>
└ <div>
└ <div>
├ <div>
└ <div>
└ <div>
├ <svg>
├ <form class="search-form" action="/en/search-locations" method="GET">
└ <input class="search-input" name="query" type="text" placeholder="Search location, zip..." autocomplete="off">
</form>
├ ・・・
上記のinputタグから、queryという名前の要素を指定して代入すればいいことが分かる。
埼玉県さいたま市 を調べたいので、代入するものは Saitama-shi という文字列とする。
この検索ボックスに文字列を代入してEnterすれば検索できることから、この動作を.pyに記していく。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("https://www.accuweather.com/en/jp/japan-weather")
search_word = driver.find_element_by_name("query")
search_word.send_keys("Saitama-shi")
search_word.send_keys(Keys.RETURN)
ここまでで以下の画面まで推移することが確認できた
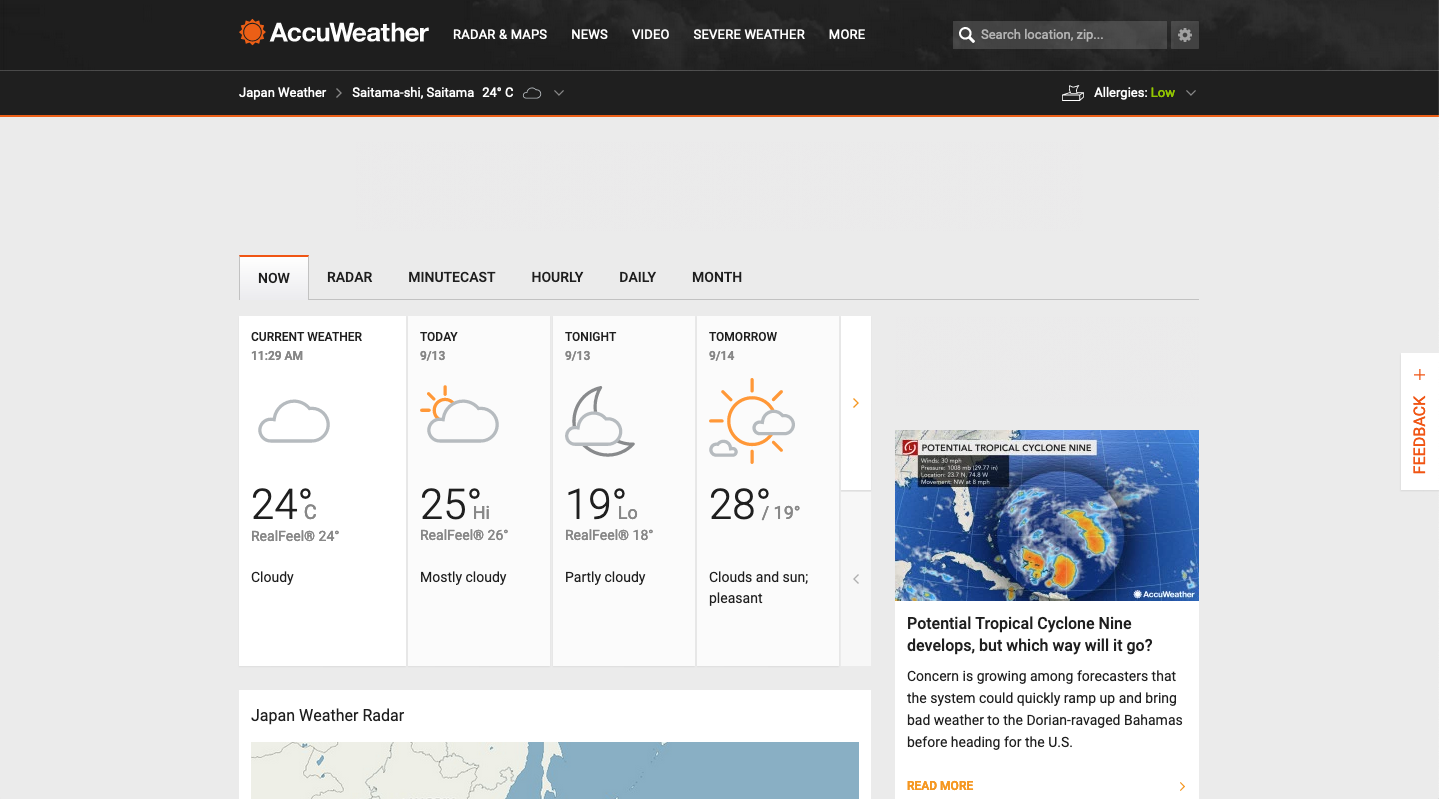
今回は現在の気温と天候を取得することが目標なので、先の画面の CURRENT WEATHER 内の 24° と Cloudy が取得できればクリアとなる。
早速HTMLを見てみると、<div class="curcon-panel">内に存在していることが分かる
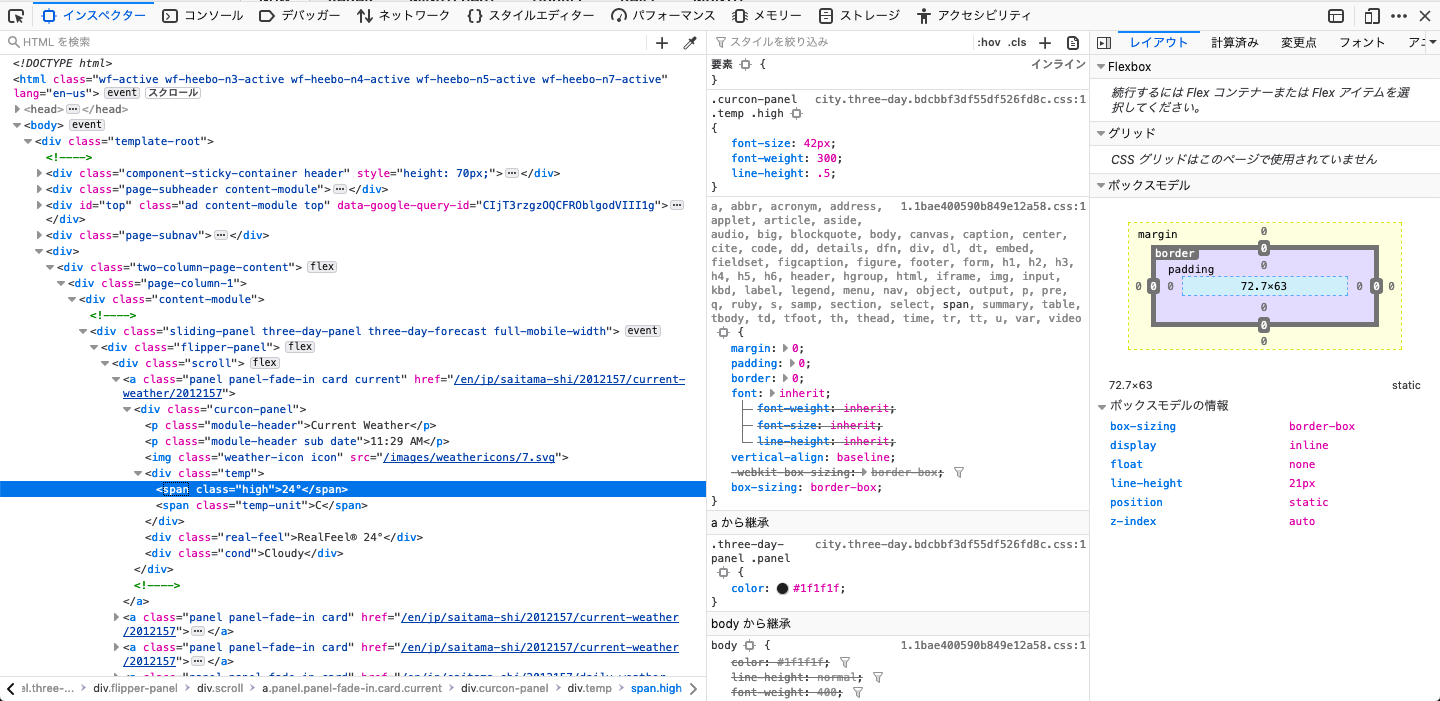
つまり以下の<span></span>内部を抽出する必要がある。
<div class="curcon-panel">
<p class="module-header">Current Weather</p>
<p class="module-header sub date">11:29 AM</p>
<img class="weather-icon icon" src="/images/weathericons/7.svg">
<div class="temp">
<span class="high">24°</span>
<span class="temp-unit">C</span>
</div>
<div class="real-feel">RealFeel®️ 24°</div>
<div class="cond">Cloudy</div>
</div>
WebDriverには要素を抽出する機能があるため、適切なモジュールを選択して使っていく。
今回はネスト状態であるためパスを指定して抽出していく。
ここで用いられるのがXpathである。
例えば<h1></h1>までのXpathは以下のように指定する。
/html/body/h1
<span></span>のディレクトリを表す場合にはspan[@class='hogehoge']と表記する。
しかし通常HTMLのパスはネスト状態になっているため、フルパスを指定することは面倒である。
ここで、ノードを省略するのが//である。
今回であれば以下のようにすればhighのクラスを探索してくれる。
//span[@class='high']
Xpathを指定できたところで、SeleniumでXpathから値を取得するdriver.find_element_by_xpath()を記述し、気温をとってくる。
天候はclass nameを元に探索し、最後にコマンドラインに表示させて終了。
ここまでで以下のコードになる
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("https://www.accuweather.com/en/jp/japan-weather")
search_word = driver.find_element_by_name("query")
search_word.send_keys("Saitama-shi")
search_word.send_keys(Keys.RETURN)
current_temp = driver.find_element_by_xpath("//span[@class='high']")
condition = driver.find_element_by_class_name("cond")
print ('Current Temp: ' + (current_temp.text))
print ('Condition : ' + (condition.text))
これをTerminalで実行してみると以下のようなエラーが出る
$ python OpenByFirefox.py
Traceback (most recent call last):
File "OpenByFirefox.py", line 12, in <module>
current_temp = driver.find_element_by_xpath("//span[@class='high']")
File "/Library/Python/2.7/site-packages/selenium-4.0.0a1-py2.7.egg/selenium/webdriver/remote/webdriver.py", line 399, in find_element_by_xpath
return self.find_element(by=By.XPATH, value=xpath)
File "/Library/Python/2.7/site-packages/selenium-4.0.0a1-py2.7.egg/selenium/webdriver/remote/webdriver.py", line 1014, in find_element
'value': value})['value']
File "/Library/Python/2.7/site-packages/selenium-4.0.0a1-py2.7.egg/selenium/webdriver/remote/webdriver.py", line 318, in execute
self.error_handler.check_response(response)
File "/Library/Python/2.7/site-packages/selenium-4.0.0a1-py2.7.egg/selenium/webdriver/remote/errorhandler.py", line 242, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: //span[@class='high']
つまり//span[@class='high']が見つからないために12行目でdriver.find_element_by_xpath()が実行できないことを表している。
Xpathに間違いはないことから、実行速度が速すぎることが問題であると考えた。
そこで読み込みに5秒間のバッファを持たせるため、以下の1行をdriver.find_element_by_xpath()の動作の直前に追加する。
driver.implicitly_wait(5)
これで実行したところ、しっかりと値が取得できた。
$ python OpenByFirefox.py
Current Temp: 24°
Condition : Cloudy
待機処理について
先ほどはdriver.implicitly_wait(5)を使って5秒間の固定で待機処理をしたが、実践では 無駄が生じてしまう or 読込時間の変化に対応できない 点であまりいい方法とは言えない。
そこで以下のようにWebDriverWaitメソッドを使用することで、期待されている処理が完了するまで待機させる方法をとる。
意味としては 指定されたXpathが見つかるまで待機し、15秒でタイムアウトする という処理である。
WebDriverWait(driver, 15).until(EC.presence_of_element_located((By.XPATH, "//span[@class='high']")))
以下で詳細を説明していく。
- 3つのインポート文が新たに必要(後のソースコードを参照)
- WebDriverWaitの2つ目の引数である15はタイムアウトまでの時間を設定している
-
(By.XPATH, "//span[@class='high']")を無くしてEC.presence_of_all_elements_locatedに書き換えることでページ全体を読み込むまで待機という処理にできる -
By.XPATHは処理によって変えることができるBy.NAMEBy.CLASS_NAME-
By.IDなど
タイムアウトを15秒に設定し、今回の目標と同様の処理を以下のコードで実現できた。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# 新たなimport文
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("https://www.accuweather.com/en/jp/japan-weather")
search_word = driver.find_element_by_name("query")
search_word.send_keys("Saitama-shi")
search_word.send_keys(Keys.RETURN)
element = WebDriverWait(driver, 15).until(EC.presence_of_element_located((By.XPATH, "//span[@class='high']")))
current_temp = driver.find_element_by_xpath("//span[@class='high']")
condition = driver.find_element_by_class_name("cond")
print ('Current Temp: ' + (current_temp.text))
print ('Condition : ' + (condition.text))
タイムアウトが行われているのかも確認するため high --> fuga にして同処理を行ったところ、以下のようにTimeoutExceptionが確認できた。
$ python OpenByFirefox.py
Traceback (most recent call last):
File "OpenByFirefox.py", line 16, in <module>
element = WebDriverWait(driver, 15).until(EC.presence_of_element_located((By.XPATH, "//span[@class='fuga']")))
File "/Library/Python/2.7/site-packages/selenium-4.0.0a1-py2.7.egg/selenium/webdriver/support/wait.py", line 86, in until
raise TimeoutException(message, screen, stacktrace)
selenium.common.exceptions.TimeoutException: Message: