Code Splitting、サボってきたのですが、必要になりそうだったので真面目に調べてみました。
これからCode Splittingやりたい方の入口的な役割になれれば幸いです。
Code Splittingとはなにか
Code Splittingはその名の通り「コードを分割すること」を指します。分割されたコードはユーザのアクションに応じて非同期に読み込まれます。

ちなみにWebpackでentry point分けることとかもCode Splittingと言えばそうなのですが、本記事では触れません。また、別にSPAでなくともCode Splittingはパフォーマンス向上に利用できますが、これ以降はSPAを前提に話します。
Code Splittingの目的
Code Splittingの目的は初期表示にかかる時間、及びユーザがインタラクションできるようになるまでの時間の削減です。
SPAではJSがHTMLを生成してそれを描画します。なのでJSがパース/コンパイル/実行されるまでは何も表示されない時間が続きます。また、基本的にSPAはアプリケーション全てのコードを一つのファイルにバンドルするため、得てしてファイルサイズが大きくなりがちです。
なので、一度に全部読み込むのではなく、使う部分だけのJSを取り出して初期表示を速くしようというのがCode Splittingの目的です。
計測する
それでは私が所属してる会社の某サービスのSPAを例に、どれくらい伸び代がありそうかを見てみます。別に誰でも見れる情報なので特に怒られないとは思いますが、個人の記事であるため一応サービス名は伏せておきます。
まずページの表示にどれくらいかかっているのかをLighthouseで見てみます。
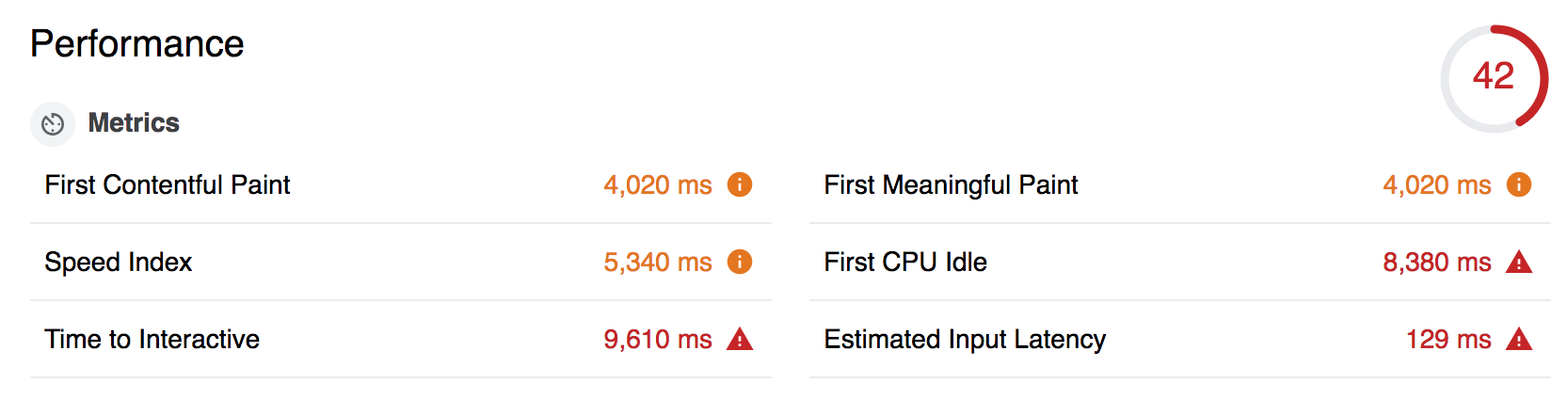
表示まで約4秒ほどかかっていますね。
そして、メインのSPAのJSの実行にかかっている時間はこんな感じ。

Totalで1秒ほどかかっています。
あれ意外と速いな…。若干企画倒れ感がしてきましたが次にCode Coverageを見てみます。
(ちなみにどっちかというとボトルネックになっているのは画像の読み込みでした。)
Code Coverageとはその名の通り、読み込まれているJSの何%が現在の表示に使われているのかを表す数値です。確認するためにはChromeの開発者ツールを使います。(他のブラウザのツールは見つけられませんでした)
Chromeで開発者コンソールを開いて Cmd + Shift + p (Windowsでは多分CmdがCtlr)を押してcoverageと入力してshow coverageでEnter押します。そうするとCoverageというタブが開くと思うので、「●」ボタンを押して計測を始めます。私のサイトでは結果はこのようになりました。

一番上の明らかにサイズが大きいものがSPAのbundle.jsなのですが、およそ1.2MBあるうちの52% がunusedだと仰っていますね。うーむ中々。ただ逆に言えばこれが伸び代で、最大で現在の半分の時間に短縮できるということを示してくれています。今回の例で言うと約1秒のところが0.5秒くらいになります。
Code SplittingしておけばSSRはいらない?
初期表示と聞くとSSRがよく引き合いに出されますが、Code Splittingで最適化していてSEOの要求も強くないのであればSSRいらないのかと言われると、そんなことはなくFirst Meaningful Paint(FMP)にこだわるのであればSSRが必要です。
SSRは事前にJSを実行して描画されたHTMLを返してくれます。なのでリクエストが返ってきてから表示されるまでの時間は速いです。Code Splittingをした場合はファイルサイズが小さくなったとは言え依然としてJSが読み込まれてからでないとHTMLは描画されません。FMPが指標として重要である場合SSRは視野に入れた方がよいでしょう。
逆にSSRする場合はCode Splittingいらない?
SSRライブラリは基本的にページ単位でのCode Splittingしてるっぽいので、この質問はもはやナンセンスかもしれないんですが、SSRする場合にもCode Splittingは重要です。
SSRが実現してくれるのは初期の"表示"(HTMLの生成)までです。SPA実行した場合にレンダーされるHTMLを返してくれる訳ですが、これはあくまで見た目の部分だけの話であり、実際にはJSを実行する処理が走ります。このJSの実行が終わるまではクリックしても何も反応してくれません。この「ユーザがインタラクションできるようになるまでの時間」を Time to Interactive(TTI) と呼びます。
TTIに長い時間をかけてると、ユーザに「押してるのに全然反応しない!」といった負の体験を与えてしまう恐れがあります。SSRした際は、コンテントが見えてから実際に反応してくれるまでの体感時間はむしろ増えてしまうので、対策しないとより負の体験を与えやすくなってしまうのではないかと思います。なのでCode SplittingはこのTTIを削減するために重要です。
Code Splittingのデメリット
これはメリットの裏返しなのですが、分割したモジュールを読み込む際にレイテンシーが増えることは一つのデメリットでしょう。1ファイルなSPAでは一回読み込まれてさえしまえばあとはパフォーマンスを発揮してくれますが、Code Splittingを用いた場合は分割されたファイル個別に読み込みが発生します。(後述しますが、これを抑えるためにprefetch/preloadが有用です)
また分割すればするほどファイルが増えるため、リクエスト数が増えることによるオーバヘッドもあります。
せっかくJSの読み込みの時間を削減したのに今度はネットワークがボトルネックになった、なんて状況になったらあまり笑えないので、この辺りはバランスとってチューニングしていくのが大切そうです。
(Webpackの)Code Splittingの仕組み
現状Code SplittingをやろうとしたらWebpackを使わざるを得ないっぽいので、Webpack前提で考えます。(ちなみに利用するimport()自体は現在TC39 でstage-3となっているDynamic importとなるべく同じ仕様のようです。)
Webpack のバンドルの仕組み
まずCode Splittingの前にWebpackのbundlingがどうやって実現されているのかを確認してみます。Webpackはbundleする時にモジュールのマップを作ります。実際にwebpackが生成したバンドルファイルを見てみましょう。
簡単な例でビルドしてみて、Webpackが生成したファイルの中身をみてみます。
文字列をexportするだけのa.js と、それを読み込んで console.log するだけのindex.jsを作りました。
const a = 'a';
export default a;
import a from './a';
console.log(a);
それではビルドした結果を見てみると、まずモジュールのマップが作られていることが確認できます。
{
/***/ "./src/a.js":
/*!******************!*\
!*** ./src/a.js ***!
\******************/
/*! exports provided: default */
/***/ (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval("__webpack_require__.r(__webpack_exports__);\nconst a = 'a';\n/* harmony default export */ __webpack_exports__[\"default\"] = (a);\n\n\n//# sourceURL=webpack:///./src/a.js?");
/***/ }),
/***/ "./src/index.js":
/*!**********************!*\
!*** ./src/index.js ***!
\**********************/
/*! no exports provided */
/***/ (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval("__webpack_require__.r(__webpack_exports__);\n/* harmony import */ var _a__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! ./a */ \"./src/a.js\");\n// const getTheme = name => import(`./theme/${name}.js`);\n\n// getTheme('dark').then(module => console.log(module));\n\n\nconsole.log(_a__WEBPACK_IMPORTED_MODULE_0__[\"default\"]);\n\n// const a = () => import('./a');\n\n// a().then(module => console.log(module));\n\n\n//# sourceURL=webpack:///./src/index.js?");
/***/ })
ファイルパス名をキーとして、コードの中身が値となったオブジェクトが作られていますね。このファイルパス名が個々のモジュールのIDとなります。
そして、次に重要なのはこちらの moduleId を引数に取った __webpack_require__ と言う関数です。
この関数が指定されたmoduleIdのモジュールを実行します。
/******/ // The require function
/******/ function __webpack_require__(moduleId) {
/******/
/******/ // Check if module is in cache
/******/ if(installedModules[moduleId]) {
/******/ return installedModules[moduleId].exports;
/******/ }
/******/ // Create a new module (and put it into the cache)
/******/ var module = installedModules[moduleId] = {
/******/ i: moduleId,
/******/ l: false,
/******/ exports: {}
/******/ };
/******/
/******/ // Execute the module function
/******/ modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
/******/
/******/ // Flag the module as loaded
/******/ module.l = true;
/******/
/******/ // Return the exports of the module
/******/ return module.exports;
/******/ }
そして、最後にmodules(前述のモジュールのマップ)を引数に取る関数を古き良きIFFIパターンで即時実行し、最初にentryポイントのモジュールを __webpack_require__ 関数で実行することによってWebpackはバンドリングを実現してくれています。
それでは次にCode Splittingをしてビルドしてみた時の結果を見てみます。
a.jsの中身を以下のように書き換えてみます。
const a = () => import('./a');
a().then(module => console.log(module));
WebpackではTC39で現在stage-3のDynamic Importの構文を利用しており、import関数がある場合自動的にimportの対象のファイルを別のChunkファイルとして生成します。
なので、今回ビルドした時は先ほどのmain.jsとは別に次のファイルが生成されました。main.jsの他に0.jsがあります。
0.jsの中身は次のように、b.jsの内容を持っています。
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([[0],{
/***/ "./src/a.js":
/*!******************!*\
!*** ./src/a.js ***!
\******************/
/*! exports provided: default */
/***/ (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval("__webpack_require__.r(__webpack_exports__);\nconst a = 'a';\n/* harmony default export */ __webpack_exports__[\"default\"] = (a);\n\n\n//# sourceURL=webpack:///./src/a.js?");
/***/ })
}]);
main.jsの方にも変化があります。
また、chunkを非同期で読み込むための requireEnsure(chunkId) という関数が追加されています。(長いので詳細な内容は割愛)そしてその関数を用いてChunkとなったモジュールを読み込んでいます。
eval("const a = () => __webpack_require__.e(/*! import() */ 0).then(__webpack_require__.bind(null, /*! ./a */ \"./src/a.js\"));\n\na().then(module => console.log(module));\n\n\n//# sourceURL=webpack:///./src/index.js?");
まとめるとWebpackではそれぞれのモジュールに対してIDを振り、そのIDと実際のコードのマップを作ります。あるモジュールが他のモジュールを使う際には __webpack_require__ という関数を用いてその対象のモジュールを実行する訳ですが、これを実際に必要になった時に非同期に行う仕組みがCode Splittingです。
Code Splittingのパターン
それでは実際にCode Splittingを使っていこう!となった場合に具体的にどうやって分割していくのかという話ですが、大きくは次の3パターンが主流みたいです。
- Page
- Fold
- Temporal
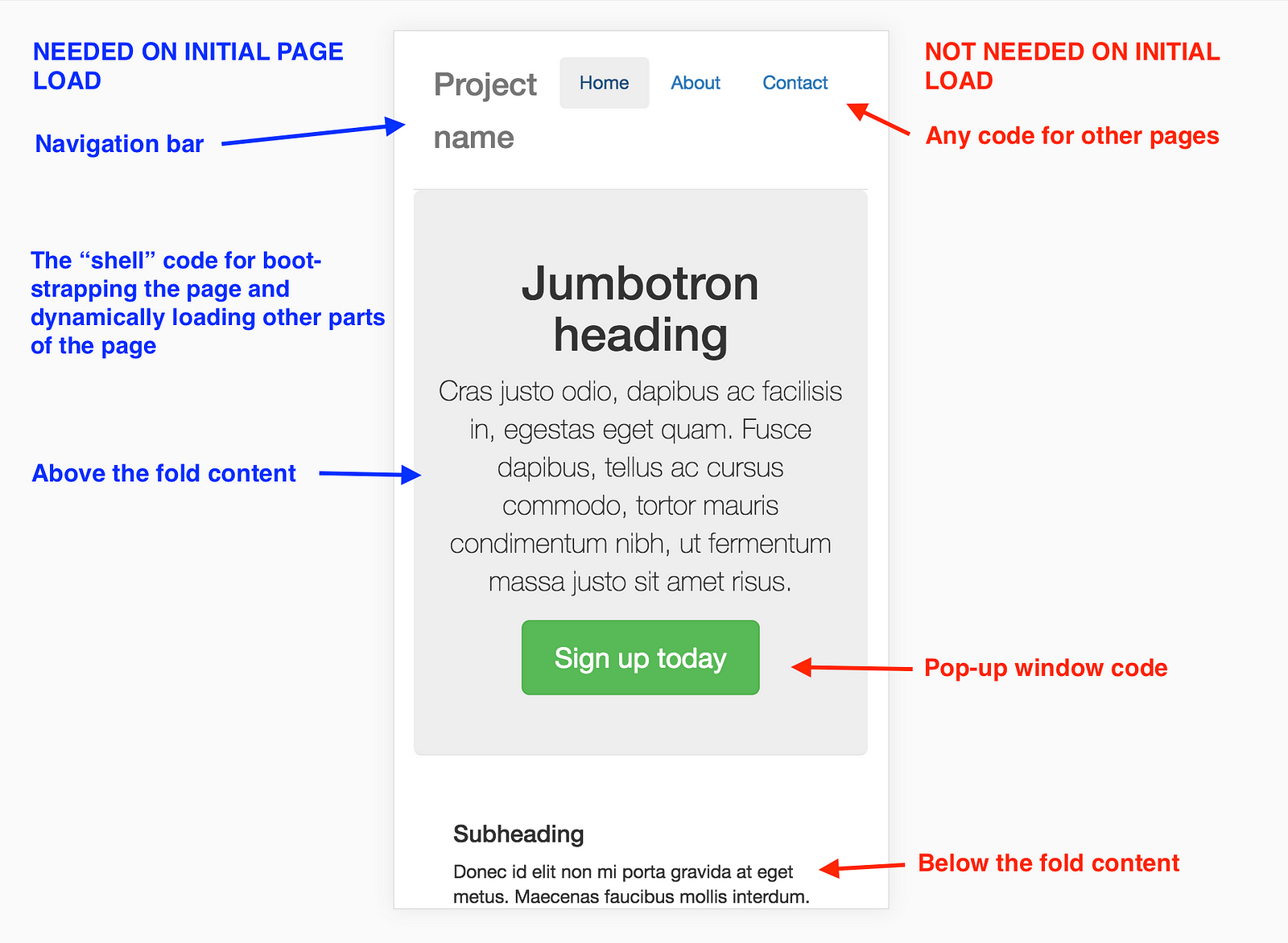
1.Page
これはイメージしやすいと思うんですが、ページ毎に分割してルートの変換が行われた時に読み込まれるようにする考え方です。基本的にRouterの部分で以下のような感じで設定してあげることになります。
/* Vueでの例 */
const Home = () => import(/* webpackChunkName: "home" */ './Home.vue');
const About = () => import(/* webpackChunkName: "about" */ './About.vue');
const Contact = () => import(/* webpackChunkName: "contact" */ './Contact.vue');
const routes = [
{ path: '/', name: 'home', component: Home },
{ path: '/about', name: 'about', component: About },
{ path: '/contact', name: 'contact', component: Contact }
];
2.Fold
Foldという聞き慣れない英単語を言われてもピンと来ないと思うのですが、Above the Fold という単語は "最初の表示域" という意味です。元はSEO界隈の用語っぽいです。
例えばQiitaをスマホで開いた場合ですが、最初の表示域はこんな感じになります。

影になっている部分がBelow the Fold、初期表示域にはない部分です。記事のリストの部分はCode Splittingしても意味ないですが、下の方に色んなランキングを表示している部分があるので、それらをCode Splittingして遅延読み込みするのは多少最適化に繋がるかもしれません。Foldはイメージ的にはそんな感じです。
設計にもよりますが、そのCode Splittingする場所をWrapするコンポーネントを作る必要があったり、適切なローディングプレイスホルダーを出しておくなど実装のトリッキーさはやや上がるかなという印象です。
3. Temporal
3番目のTemporalですが、これはモーダルとかツールチップとか最初に表示されないようなUI要素を指します。それらのコンポーネントが出現するトリガーとなるイベントと一緒に絡めて対象のコンポーネントを読み込みます。
その他もろもろ
Dynamic Code Splitting
実はWebpackのCode Splittingにはもう一種類あり、Dynamic Code Splittingと言います。
Dynamicと言いつつやってることはstaticだったり、名前がDynamic importと紛らわしかったり(これは私だけかもしれない)しますが、状態によって読み込むChunkを変更することを可能にしてくれるのがDynamic Code Splittingです。
例として theme というフォルダの中にいくつかファイルを作ります。

そしてindex.jsを書き換えて、以下のようにimport()関数の引数のパス名が動的に決まるようにします。
const getTheme = name => import(`./theme/${name}`);
getTheme('dark').then(module => console.log(module));
こうしてビルドするとthemeフォルダ内にあるそれぞれのファイルに対してChunkが生成されます。
こうすることによって動的にどのChunkを読み込むのかを変更することができるようになりました。このDynamic Code Splittingはパフォーマンスを上げることが目的というよりは、用途としてはA/Bテストで機能の出し分けをしたり、サイトのテーマを変えたりなどが挙げられます
ちなみに./theme/${name}.js のようにするとjsファイルだけChunkを産むとかできます。
prefetch/preload
参考: in webpack – webpack – Medium
v4.6からはいった機能ですが、prefetchというフラグをつけてあげることで、Chunkにしたモジュールを事前に読み込んでおくことができます。
やり方は簡単でimport()関数内にコメントつけるだけです。
import(/* webpackPrefetch: true */ "./hoge")
これにより
<link rel="prefetch" href="hoge.js">
のタグがHTMLファイル内に作られます。
ちなみに複数のChunkを作っていてprefetchする順番を制御したい場合は true の代わりに数値を入れてあげればいいそうです。(というよりtrueは0としてカウントされている) z-indexを彷彿とさせますね。
preload も同様で、こちらも専用のコメントをつけるだけです。
import(/* webpackPreload: true */ "ChartingLibrary")
prefetch/preloadの違いについてはこちらに詳しい
https://blog.jxck.io/entries/2016-03-04/preload.html
ReactやVueなどで扱う場合
import()だけでもできなくはないですが、書き方をサラッとご紹介。
Vueの場合
Vueだと vue-loader が解決してくれるので、SFCで書いている方は特に追加の設定は必要なくCode Splittingが導入できます。
// いつもならこうしてるところを
// import Hello from "./components/Hello"
// こうするだけ
const Hello = () => import("./components/Hello")
export default {
components: {
Hello
}
}
めっちゃ簡単。
Reactの場合
Reactの場合はVueのようにライブラリ自体がサポートしてくれているわけではないので、何らかのライブラリを用いる必要があります。いくつかあるのですが、一番有名どころはこちらのreact-loadableっぽいです。
GitHub - jamiebuilds/react-loadable: A higher order component for loading components with promises.
react-loadbleからそのまま実装例をコピペしてきました↓
import Loadable from 'react-loadable';
import Loading from './my-loading-component';
const LoadableComponent = Loadable({
loader: () => import('./my-component'),
loading: Loading,
});
export default class App extends React.Component {
render() {
return <LoadableComponent/>;
}
}
こちらもVueほどステップなしとは行きませんがそこまで複雑ではないですね。
ただこのreact-loadable、そもそもissueが受け付けられていなかったりWebpack v4のmigrationのPRが謎にspam扱いされてcloseされてたり未来が明るくなさそうみたいです。
複雑なことやらないなら自前でラッパーコンポーネント作っても行けそうだけど、この辺のライブラリ事情は詳しい人いたら教えてほしい。
感想
やたら長文になってしまいましたが、ご読了いただきありがとうございました。Code Splittingは割と職人芸的なイメージが強くてちゃんと触れてこなかったのですが、Webpackが便利すぎたせいか意外と怖くなかったです。SPAの初回のロードの遅さって開発していると慣れてしまいがちな気がするのですが、ユーザの体験を毀損しているかもしれないと気を引き締めて行きたいですね。
それではよいCode Splittingを〜。
参考
- https://webpack.js.org/guides/code-splitting/
- 3 Code Splitting Patterns For VueJS and Webpack
-
The Cost Of JavaScript In 2018 – Addy Osmani – Medium
- Code Splittingのみがテーマの記事ではないですが、パフォーマンス関連の色々が詰まった勉強になる記事です。