1. 本投稿の概要
1-1. 本Qiita投稿の目的
- データ分析・機械学習の学習を実ビジネスに落とし込む練習のため
- 様々なライブラリ・コードに触れるため
1-2. 今回学んだこと3選
- 探索的データ解析(EDA:Exploratory Data Analysis)の重要性
- 機械学習を用いた、ビッグデータのトピックモデリング
- コーティングする際のChatGPTの便利さ
詳しくは最後のまとめに書きます。
1-3.kaggleコンペの概要
Kaggleの「メルカリの価格提案チャレンジ〜メルカリ販売者に出品価格を自動で提案できるかどうか〜」というテーマのコンペです。
丁寧に解説している記事を参考に引用しておきます。
ちなみに、メルカリにおいて「なぜ値段推定が重要なのか?」を解説しておくと、
適切な値段推定を自動でできると出品の負担・ハードルが下がり、
メルカリマーケットがより活発になるからです。
ご存知の方も多いと思いますが、メルカリでは出品者が自由に値付けを行います。
この値付けの問題として、
- メルカリの相場より、高い値段で出品した場合売れない
- 逆に相場より低い値段で出品してしまった場合、出品者が損をする
などがあるようです。
上記の解決策として、
- 出品予定の商品・カテゴリをメルカリ内で検索して、自分で相場価格を調べる
がありますが、これでは
- 出品者に大きな手間がかかる
- そもそもメルカリに登録直後の出品者はそんなことを思いつかない
といったデメリットが発生し、
メルカリが目指したい"気軽に商品を回せるサービス"から遠ざかってしまいます。
そのため、「出品時に商品情報から適切な値段を自動的に提示することで出品時の手間を削減し、さらに出品を簡単にすれば、出品数が増え、出品者の満足度も上がるのでは?」
ということですね。
メルカリ全体の機能改善に繋がるため、確かにこのコンペ結果のビジネス価値はかなり大きなものと思えます。
1-4.ノートブック・コードの概要
今回は上記コンペで投票数1位・ゴールドメダルとなったNotebookを写軽します。
以下が該当のNotebookです。
本ノートブックでは最終価格予測までは行っていません。
ただハイレベルなデータ探索とわかりやすい可視化によって、投票数が1位になっていると思われます。実際にこのノートブックを用いて、モデルの選定→モデル学習に取り掛かっている投稿も多くあります。
このコードに日本語の解説をつけ、またところどころ省略されている解説を挟んでいきます。
1-5. 本投稿の流れ
1.本投稿の概要
2.コード前編…データセット全体のEDA
3.コード後編…変数”商品説明”のEDA
4.まとめ
より細かい流れは目次をご覧ください。
2. コード前編:データセット全体のEDA
2-1. 必要なライブラリのインポート
#ライブラリのインポート
import nltk
import string
import re
import numpy as np
import pandas as pd
import pickle
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="white")
from nltk.stem.porter import *
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from collections import Counter
from wordcloud import WordCloud
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
%matplotlib inline
import bokeh.plotting as bp
from bokeh.models import HoverTool, BoxSelectTool
from bokeh.models import ColumnDataSource
from bokeh.plotting import figure, show, output_notebook
import warnings
warnings.filterwarnings('ignore')
import logging
logging.getLogger("lda").setLevel(logging.WARNING)
Python初心者で学習中の身として、注目したライブラリは「nltk」と「bokeh」。
初めての使用でした。
- nltk
英語による自然言語処理をする上で役立つライブラリ
- bokeh
インタラクティブなデータ可視化ライブラリ
グラフの拡大縮小やスライダーなどで動的にグラフを操作することが可能、
HTML形式・画像で保存できる。
matplotlibと比べられがち。
2-2. データセットの読み込み・全体概要
#訓練データtrainとテストデータtestを作成
train = pd.read_table('/kaggle/input/"ファイル名"/train.tsv')
test = pd.read_table('/kaggle/input/"ファイル名"/test.tsv')
メルカリが提供しているデータセットが7zという形式だったため、
ダウンロード後、macPCでも取り扱えるよう下記アプリで解凍しました。
ほかのコードもいくつか拝見したのですが、
tsv形式をcsv形式に変換するやり方で進めている方もいました。
ここからどんなデータが与えられているのかを確認していきます。
#訓練データとテストデータのサイズを確認
print(train.shape)
print(test.shape)
>>>出力結果
(1482535, 8)
(693359, 7)
2/3が訓練用、1/3がテスト用くらいの割合のようです。
#trainのデータフレーム冒頭5行を表示
train.head()
>>>出力結果

# trainのデータ型を確認
train.dtypes
>>>出力結果
train_id int64
name object
item_condition_id int64
category_name object
brand_name object
price float64
shipping int64
item_description object
dtype: object
#各変数の統計量を表示
def display_all(df):
with pd.option_context("display.max_rows", 1000):
with pd.option_context("display.max_columns", 1000):
display(df)
display_all(train.describe(include='all').transpose())
>>> 出力結果

以上、データセット全体の簡単な概要をまとめます。
- 数値/連続変数
- price: 商品の最終入札価格。testで予測する目的変数
- shipping cost: 配送料
- カテゴリ変数
- shipping cost: 配送料。売り手が負担する場合は1、買い手が負担する場合は0のバイナリ指標
- item_condition_id: 売り手が提供する商品の状態
- name: 商品の名前
- brand_name: 商品の製造ブランド名
- category_name: 「\」で区切られた商品のカテゴリ
- item_description: 商品の短い説明
2-3. 各変数の概要
ここから1つ1つの変数をチェックしていきます。
2-3-1.目的変数:price(商品価格)
改めて今回の分析で目的変数となるのは、
「メルカリの市場に対する売り手へ提案する価格=price」です。
まず、上記の統計量の整理からprice部分に注目します。
・平均値は約27ドル
・中央値は約17ドル
・最大値は約2000ドル
(記事では中央値が267ドルと書かれていますが誤りかと思われます)
以上のことから、price変数の分布は「大きく左に偏っていること」が予想されます。
そこで、価格に対して"対数変換"を行います。
データを対数変換すると、データの分布を正規分布に近づけることができます。
なぜこの操作をするのかというと、この変換によって正規分布を仮定した解析手法(パラメトリックな手法)を適用することができるからです。
今回は、対数変換の前に+1を加えて、ゼロや負の値を避けるようにしています。
plt.subplot(1, 2, 1)
(train['price']).plot.hist(bins=50, figsize=(20,10), edgecolor='white',range=[0,250])
plt.xlabel('price+', fontsize=17)
plt.ylabel('frequency', fontsize=17)
plt.tick_params(labelsize=15)
plt.title('Price Distribution - Training Set', fontsize=17)
plt.subplot(1, 2, 2)
np.log(train['price']+1).plot.hist(bins=50, figsize=(20,10), edgecolor='white')
plt.xlabel('log(price+1)', fontsize=17)
plt.ylabel('frequency', fontsize=17)
plt.tick_params(labelsize=15)
plt.title('Log(Price) Distribution - Training Set', fontsize=17)
plt.show()
>>> 出力結果
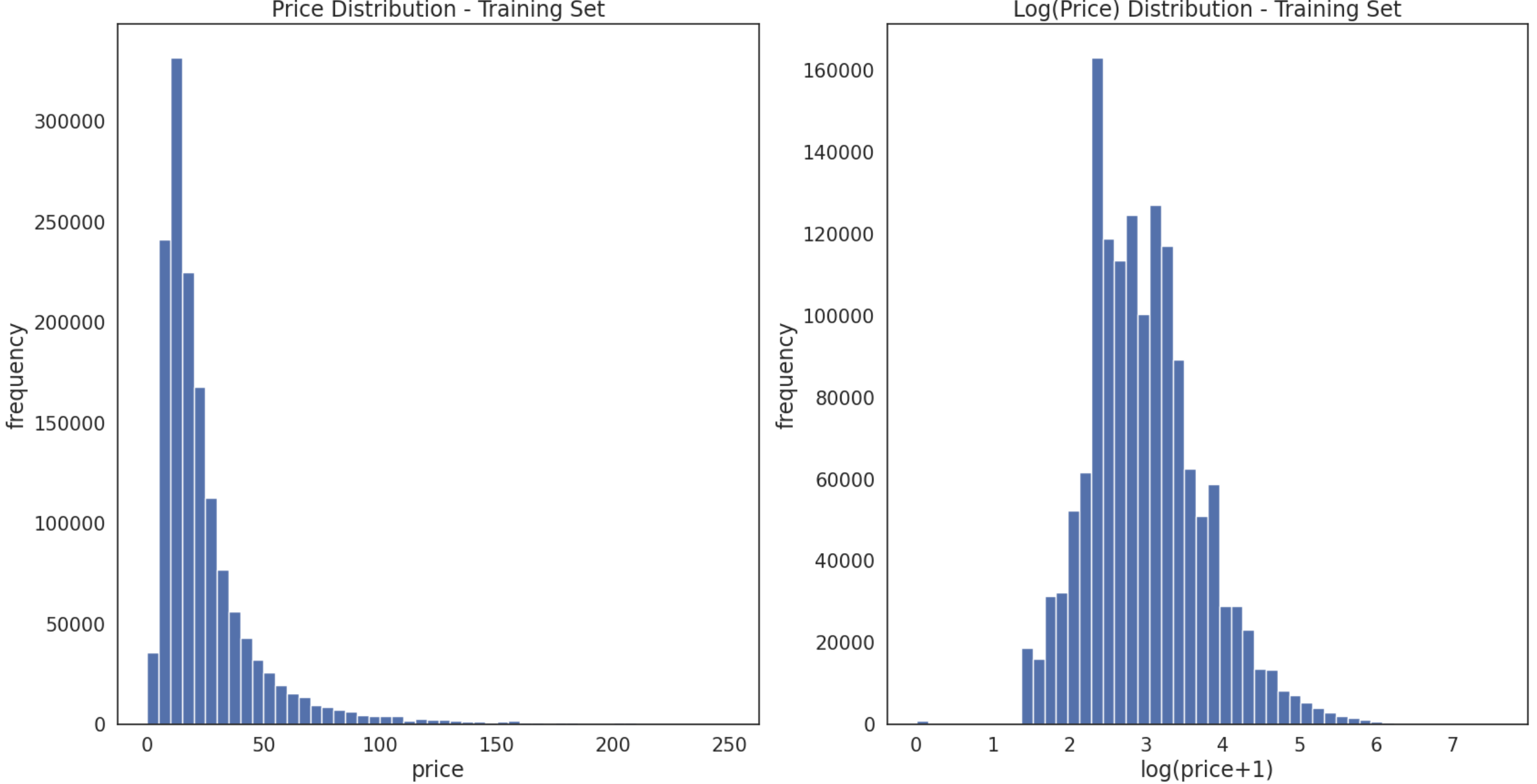
左図が対数変換する前のpriceの分布、
右図が対数変換した後のpriceの分布です。
正規分布の形に近づいていることがわかります。
なぜ正規分布に近づけることが重要なのか?
それは一言で言うと「確率が求められるようになるから」です。
詳しくは統計分野の話になりますね。私は統計検定2級を勉強した際に出会いました。
2-3-2.説明変数:shipping(配送料)
ここからは目的変数price以外の、説明変数についてです。
まずshipping(配送料)について、配送料は
「0:出品者負担 1:購入者負担」
のバイナリ変数(0か1の2択しかない項目)となっています。
統計量を見てみると、約55%が出品者負担、約45%が購入者負担とだいたい半々くらいのようです。
配送料をどちらが負担するかによって商品価格は変わるのでしょうか?
以下、グラフにして、「出品者負担のときの商品価格(緑)」と「購入者負担のときの商品価格(青)」を比較して確認してみます。
prc_shipBySeller = train.loc[train.shipping==1, 'price']
prc_shipByBuyer = train.loc[train.shipping==0, 'price']
fig, ax = plt.subplots(figsize=(20,10))
ax.hist(np.log(prc_shipBySeller+1), color='#8CB4E1', alpha=1.0, bins=50,
label='Price when Seller pays Shipping')
ax.hist(np.log(prc_shipByBuyer+1), color='#007D00', alpha=0.7, bins=50,
label='Price when Buyer pays Shipping')
ax.set(title='Histogram Comparison', ylabel='% of Dataset in Bin')
plt.xlabel('log(price+1)', fontsize=17)
plt.ylabel('frequency', fontsize=17)
plt.title('Price Distribution by Shipping Type', fontsize=17)
plt.tick_params(labelsize=15)
plt.show()

上記グラフより、配送料が出品者負担になっているほうが、商品価格の平均が高いことがわかります。
これは、「もし出品者が配送料を購入者負担にする場合、商品価格自体を本来の値段より低価格に設定する必要がある」ということが予想できます。
メルカリで商品の出品や購入を経験したことがある方は想像しやすいのではないでしょうか。確かに私もメルカリで欲しいものを購入する際、配送料が出品者負担になっているというだけで、お得感がある気がします。
配送料をどちらが負担するかによって、本来予想される商品価格に一定価格を上乗せするかしないかを考慮する予想ができそうですね。
2-3-3.説明変数:category_name(商品カテゴリー)
次の説明変数は商品カテゴリーについてです。
商品カテゴリーの例を見てみると、まずメインのカテゴリーがあり、その後ろに2つのサブカテゴリーが続いています。
(例: Men/Tops/T-shirts, Home/Home Décor/Home Décor Accents)
この商品カテゴリー(正確に言うとサブカテゴリー)によって、商品価格がざっくりと分類できることはなんとなく予想できるかと思われます。
例えば上記例に挙げた、男性用のTシャツであれば、安くても¥1000、高くても¥10000ほど?小物インテリアであれば、もちろん物にもよりますがだいたい¥1000前後でしょうか。
このメインカテゴリーとサブカテゴリー、商品価格を予想・提案するための重要な説明要因になりそうなため、詳しく中身を見ていきます。
当たり前ですが、商品カテゴリーは文字型として入力されています。
そのため、DataFrameのnuniqueなどによって、
ユニークな要素の数(重複を除いた要素の種類の数)、データが空のnull数、カテゴリごとのカウント数などを確認します。
(もしかしたら最初からこれが整数型で登録されていてもいいのかもしれませんね。)
print(train['category_name'].nunique())
>>>出力結果
1287
print(train['category_name'].isnull().sum())
>>>出力結果
6327
train['category_name'].value_counts()[:5]
>>>出力結果
Women/Athletic Apparel/Pants, Tights, Leggings 60177
Women/Tops & Blouses/T-Shirts 46380
Beauty/Makeup/Face 34335
Beauty/Makeup/Lips 29910
Electronics/Video Games & Consoles/Games 26557
Name: category_name, dtype: int64
上記より、
・1287のカテゴリーセット(メイン+サブの組み合わせ)があること
・カテゴリ自体のない商品が6327あること
・150万件の商品のうち、一番多いカテゴリでも約6万件しかないこと
などがわかります。
上記ではサブカテゴリーまで含めた1セットで確認しています。
よって、ここからは/:スラッシュで区切ったカテゴリをそれぞれ3つの異なる列に分けます。
後ほど、この情報が購入者観点から非常に重要であること、
brand_name列の欠損情報の処理方法がモデルの予測にどのように影響するかがわかります。
def split_cat(text):
try: return text.split("/")
except: return ("No Label", "No Label", "No Label")
train['general_cat'], train['subcat_1'], train['subcat_2'] = \
zip(*train['category_name'].apply(lambda x: split_cat(x)))
test['general_cat'], test['subcat_1'], test['subcat_2'] = \
zip(*test['category_name'].apply(lambda x: split_cat(x)))
記事内ではここでtrain.head()を出力し、しっかり/ごとにsplitできているか確かめていますが、本投稿では割愛します。
また、ついでにテストデータもここで分割しておきます。
print(train['sgeneral_cat'].nunique())
>>>出力結果
11
x = train['general_cat'].value_counts().index.values.astype('str')
y = train['general_cat'].value_counts().values
pct = [("%.2f"%(v*100))+"%"for v in (y/len(train))]
trace1 = go.Bar(x=x, y=y, text=pct)
layout = dict(title= 'Number of Items by Main Category',
yaxis = dict(title='Count'),
xaxis = dict(title='Category'))
fig=dict(data=[trace1], layout=layout)
py.iplot(fig)
>>>出力結果
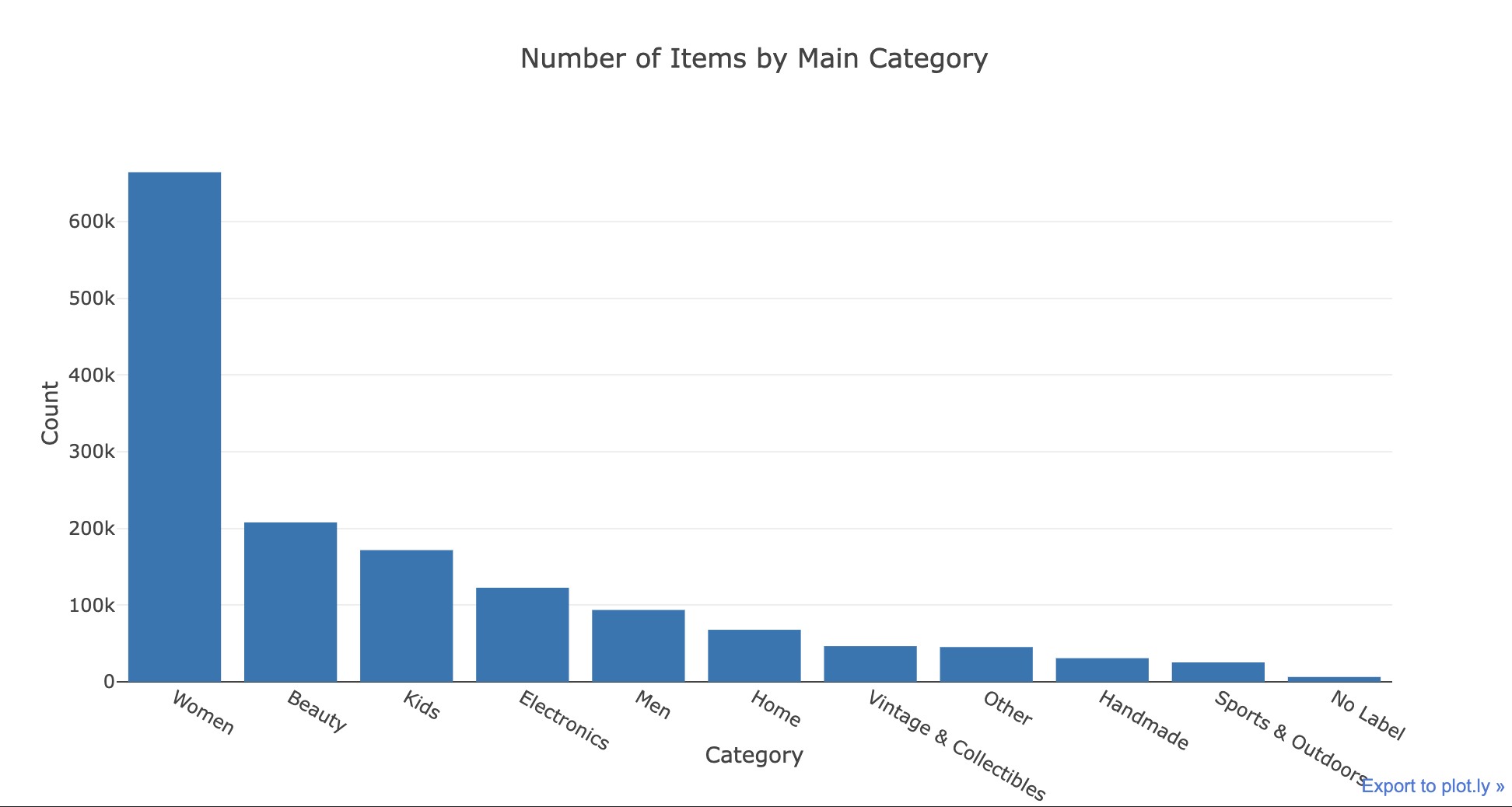
メインカテゴリーは11ありますが、上位7つを使用することにします。
女性向け商品が最も人気のカテゴリーで、このカテゴリーだけで全体の45%と約半分を占めます。
その後に美容、子供向け商品、電子機器、男性向け商品、家具、ヴィンテージコレクションと続いていますが、この上位7つで全体の約9割を占めています。
general_cats = train['general_cat'].unique()
x = [train.loc[train['general_cat']==cat, 'price'] for cat in general_cats]
data = [go.Box(x=np.log(x[i]+1), name=general_cats[i]) for i in range(len(general_cats))]
layout = dict(title="Price Distribution by General Category",
yaxis = dict(title='Category'),
xaxis = dict(title='Log Price')) #お手本間違えてる?
fig = dict(data=data, layout=layout)
py.iplot(fig)
>>>出力結果

メインカテゴリだけの価格(対数にした後)の分布を見ると、どのカテゴリも最大値を除くと比較的均等に分布しており、特筆すべき極端なカテゴリはありません。
やはりサブカテゴリーが大事なようですね。
次に2つのサブカテゴリについて、見ていきます。
print(train['subcat_1'].nunique())
>>>出力結果
114
print(train['subcat_2'].nunique())
>>>出力結果
871
x = train['subcat_1'].value_counts().index.values.astype('str')[:15]
y = train['subcat_1'].value_counts().values[:15]
pct = [("%.2f"%(v*100))+"%"for v in (y/len(train))][:15]
trace1 = go.Bar(x=x, y=y, text=pct,
marker=dict(
color = y,colorscale='Portland',showscale=True,
reversescale = False
))
layout = dict(title= 'Number of Items by Sub Category (Top 15)',
yaxis = dict(title='Count'),
xaxis = dict(title='SubCategory'))
fig=dict(data=[trace1], layout=layout)
py.iplot(fig)

第一サブカテゴリは114、第二サブカテゴリは871あります。
第一サブカテゴリをグラフにしてみましたが、
一番多いのは運動着で約9%と、サブカテゴリはかなり分布が浅く広いようです。
2-3-4.そのほかの説明変数
これまで7つある変数のうち、
「商品価格」「配送料」「商品カテゴリー」を見てきましたが、ほかの変数はいかがでしょうか。
そのほかの変数「商品名」「ブランド」「商品状態」はここでは一旦置いておきます。
どれも商品や商品カテゴリーによって左右されることが予想できるためです。
また「商品状態」は1~5によって状態が数値化されていますが、5の新品状態に近づくほど価格が高くなり1の劣化状態に近づくほど価格が下がるのは明らかです。
これは私の個人的な見解ですが、
ビジネス現場においては”最小努力”の観点も必要かと思っています。(特に日本では)
もちろん統計量やなんとなくの分布を確認することに越したことはないのですが、
いち早く目的にたどり着くため、「仮説→検証」は小さなものでも繰り返していくべきかと思われます。
残りの変数「商品説明」はこのあとの章にて、詳しく記載していきます。
ここからが本記事の最大の山場となります。
3. 変数「商品説明」のEDA
まだ触れていない変数「Item description(商品説明)」についてです。
商品説明は非構造化データであるため、解析がより難しくなっています。
また私たち人間からしても直感で予想がしにくいです。
詳細な説明があると、入札傾向や入札価格は高くなるのでしょうか?
それとも長い説明文はユーザーから読まれなくなり、入札傾向が低くなるのでしょうか?
3-1 「商品説明」の概要
まずは、「説明文の長さ」から傾向を確認していきます。
句読点を取り除き、いくつかの英語のストップワード( "a", "the"のような単語)と呼ばれる3文字未満の単語を削除します。
関数wordCountは、テキストを入力として受け取り、その中の特定の条件に合致する単語の数を返します。以下では、ストップワードを除き、3文字以上の単語の数を数えています。
def wordCount(text):
try:
text = text.lower()
regex = re.compile('[' +re.escape(string.punctuation) + '0-9\\r\\t\\n]')
txt = regex.sub(" ", text)
words = [w for w in txt.split(" ") \
if not w in stop_words.ENGLISH_STOP_WORDS and len(w)>3]
return len(words)
except:
return 0
train['desc_len'] = train['item_description'].apply(lambda x: wordCount(x))
test['desc_len'] = test['item_description'].apply(lambda x: wordCount(x))
train.head()
>>>出力結果

左端が切れていますが、trainデータの冒頭5行を出力しています。
一番右に「desc_len」という「説明文の単語数」を表す列が追加されました。
では、この長さと商品価格の雄感を見ていきます。
df = train.groupby('desc_len')['price'].mean().reset_index()
trace1 = go.Scatter(
x = df['desc_len'],
y = np.log(df['price']+1),
mode = 'lines+markers',
name = 'lines+markers'
)
layout = dict(title= 'Average Log(Price) by Description Length',
yaxis = dict(title='Average Log(Price)'),
xaxis = dict(title='Description Length'))
fig=dict(data=[trace1], layout=layout)
py.iplot(fig)
>>>出力結果

40単語くらいまでは、価格が上がっていますが、
40~80単語までは微減しており、80単語以上は不規則な動きをしています。
価格が上がれば上がるほどデータ数が少ないことも影響していると思われますが、
おそらく説明文が長いことは影響していないように見えます。
価格をつけて購入に至るまでにはある程度の説明文が必須、という仮説が立てられそうです。
また、単語ごとの頻出度も確認します。
cat_desc = dict()
for cat in general_cats:
text = " ".join(train.loc[train['general_cat']==cat, 'item_description'].values)
cat_desc[cat] = tokenize(text)
flat_lst = [item for sublist in list(cat_desc.values()) for item in sublist]
allWordsCount = Counter(flat_lst)
all_top10 = allWordsCount.most_common(20)
x = [w[0] for w in all_top10]
y = [w[1] for w in all_top10]
trace1 = go.Bar(x=x, y=y, text=pct)
layout = dict(title= 'Word Frequency',
yaxis = dict(title='Count'),
xaxis = dict(title='Word'))
fig=dict(data=[trace1], layout=layout)
py.iplot(fig)
>>>出力結果
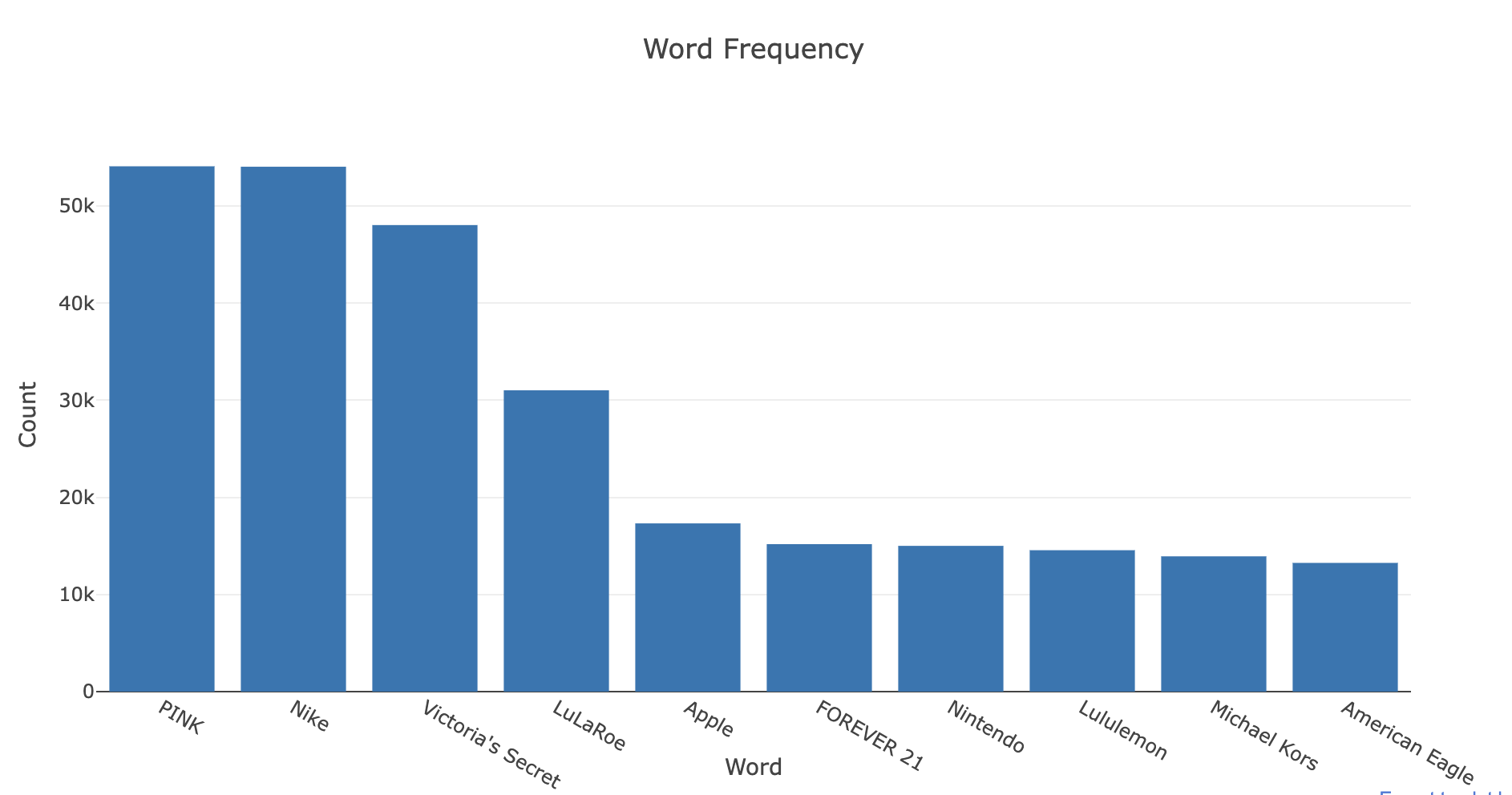
上記コードは、カテゴリごとに商品の説明文をトークン化し、全体の単語の頻度を計算して可視化するためのものです。
(エラーで1枚グラフを省略しています、解決次第貼り付けます。)
最も一般的な単語を見ると、「サイズ」「無料」「送料」という単語がよく使用されていることがわかります。また2枚目のグラフを見ると、ブランド名も非常に重要な役割を果たしていることがわかります。
ここからさらに説明文の自然言語処理を進めていきます。
3-2. 前処理①:トークン化
自然言語処理の最初のステップは、文書を「トークン化」することです。
トークン化の主な目的は、テキストを正規化することです。
通常、次の3つの基本的な段階が含まれます
-
記述を文に分割し、その後文をトークンに分割する
-
句読点とストップワードを削除する
-
トークンを小文字に変換する
また、ここでは3文字以上の長さの単語のみを残しそれ以外は削除します。
stop = set(stopwords.words('english'))
def tokenize(text):
"""
sent_tokenize(): segment text into sentences
word_tokenize(): break sentences into words
"""
try:
regex = re.compile('[' +re.escape(string.punctuation) + '0-9\\r\\t\\n]')
text = regex.sub(" ", text) # remove punctuation
tokens_ = [word_tokenize(s) for s in sent_tokenize(text)]
tokens = []
for token_by_sent in tokens_:
tokens += token_by_sent
tokens = list(filter(lambda t: t.lower() not in stop, tokens))
filtered_tokens = [w for w in tokens if re.search('[a-zA-Z]', w)]
filtered_tokens = [w.lower() for w in filtered_tokens if len(w)>=3]
return filtered_tokens
except TypeError as e: print(text,e)
train['tokens'] = train['item_description'].map(tokenize)
test['tokens'] = test['item_description'].map(tokenize)
train.reset_index(drop=True, inplace=True)
test.reset_index(drop=True, inplace=True)
tokens_ は文ごとのトークンのリストのリストになっています。
train および test データフレームには、処理されたトークンのリストが含まれる新しい 列tokensが追加されています。
説明文をきれいに処理できたかどうかの例を見てみましょう。
for description, tokens in zip(train['item_description'].head(),
train['tokens'].head()):
print('description:', description)
print('tokens:', tokens)
print()
>>>出力結果
description: No description yet
tokens: ['description', 'yet']
description: This keyboard is in great condition and works like it came out of the box. All of the ports are tested and work perfectly. The lights are customizable via the Razer Synapse app on your PC.
tokens: ['keyboard', 'great', 'condition', 'works', 'like', 'came', 'box', 'ports', 'tested', 'work', 'perfectly', 'lights', 'customizable', 'via', 'razer', 'synapse', 'app']
description: Adorable top with a hint of lace and a key hole in the back! The pale pink is a 1X, and I also have a 3X available in white!
tokens: ['adorable', 'top', 'hint', 'lace', 'key', 'hole', 'back', 'pale', 'pink', 'also', 'available', 'white']
description: New with tags. Leather horses. Retail for [rm] each. Stand about a foot high. They are being sold as a pair. Any questions please ask. Free shipping. Just got out of storage
tokens: ['new', 'tags', 'leather', 'horses', 'retail', 'stand', 'foot', 'high', 'sold', 'pair', 'questions', 'please', 'ask', 'free', 'shipping', 'got', 'storage']
description: Complete with certificate of authenticity
tokens: ['complete', 'certificate', 'authenticity']
商品説明に対して、tokensとして、3文字以上の単語がリストとして分割できていることがわかります。
また、以下は補足です。
WordCloud パッケージを使用すると、各カテゴリ内でどの単語の頻度が最も高いかを簡単に視覚化することもできます。
women,Beauty,kids,Electronicsのカテゴリの最も一般的な100個の単語とその頻度を取得します。
cat_desc = dict()
for cat in general_cats:
text = " ".join(train.loc[train['general_cat']==cat, 'item_description'].values)
cat_desc[cat] = tokenize(text)
women100 = Counter(cat_desc['Women']).most_common(100)
beauty100 = Counter(cat_desc['Beauty']).most_common(100)
kids100 = Counter(cat_desc['Kids']).most_common(100)
electronics100 = Counter(cat_desc['Electronics']).most_common(100)
def generate_wordcloud(tup):
wordcloud = WordCloud(background_color='white',
max_words=50, max_font_size=40,
random_state=42
).generate(str(tup))
return wordcloud
fig,axes = plt.subplots(2, 2, figsize=(30, 15))
ax = axes[0, 0]
ax.imshow(generate_wordcloud(women100), interpolation="bilinear")
ax.axis('off')
ax.set_title("Women Top 100", fontsize=30)
ax = axes[0, 1]
ax.imshow(generate_wordcloud(beauty100))
ax.axis('off')
ax.set_title("Beauty Top 100", fontsize=30)
ax = axes[1, 0]
ax.imshow(generate_wordcloud(kids100))
ax.axis('off')
ax.set_title("Kids Top 100", fontsize=30)
ax = axes[1, 1]
ax.imshow(generate_wordcloud(electronics100))
ax.axis('off')
ax.set_title("Electronic Top 100", fontsize=30)

どのカテゴリでもfreeやbrand、また色やサイズを表す単語が使われていることがわかります。
3-3. 前処理②:tf-idf
ここでは商品説明に含まれる単語の重要度を示す指標(tf-idf) を用いて、文書の中で重要な単語をとらえ、より詳細な特徴を掴んでいきます。
tf-idfは「Term Frequency–inverse Document Frequency」(単語頻度-逆文書頻度)の略です。これは、特定の単語の重要性をコーパス内の語彙に対して定量化するものです。この指標は2つの要素に依存します。
-
Term Frequency(単語頻度):
単語の出現回数 -
Inverse Document Frequency(逆文書頻度):
全ての文書の数を、特定キーワードが出てくる文書の数で割り対数をとったもの。つまり、「あれ」「する」など出現頻度は高くとも重要度が低い単語では小さくなり、特定の商品名や特徴を明確に表している単語など、出現頻度は低いがより重要な単語では大きくなります。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=10,
max_features=180000,
tokenizer=tokenize,
ngram_range=(1, 2))
all_desc = np.append(train['item_description'].values, test['item_description'].values)
vz = vectorizer.fit_transform(list(all_desc))
vz は tfidf 行列であり、その構造は以下の通りです。
- 行の数は、説明文の総数です。
- 列の数は、説明文全体にわたるユニークなトークンの総数です。
以下は、トークンをそのtf-idf値にマッピングする辞書を作成します。
tfidf = dict(zip(vectorizer.get_feature_names(), vectorizer.idf_))
tfidf = pd.DataFrame(columns=['tfidf']).from_dict(
dict(tfidf), orient='index')
tfidf.columns = ['tfidf']
tfidf.sort_values(by=['tfidf'], ascending=True).head(10)

上記は、最も低い tf-idf スコアを持つ10個のトークンです。
new,size,brandなど、予想通りかなり一般的な単語です。
逆に以下は、tf-idf スコアが最も高い10個のトークンです。
tfidf.sort_values(by=['tfidf'], ascending=False).head(10)

light bolt(ブランド名)やimt(頚動脈の内膜中膜複合体厚)など、
非常に具体的な単語が含まれており、これらを確認することで、商品が属するカテゴリを推測することができそうです。
3-4. 可視化①:t-SNE
t-SNE は、次元圧縮の手法で、特に可視化に用いることを意図しています。
データの局所的な構造をうまく捉えることができるだけでなく、さまざまなスケールのクラスタなど、大域的な構造を保ちながら可視化できる点が特徴です。
ただ、tf-idf 行列の次元が高いため、特異値分解 (SVD) 技法を使用して次元を削減する必要があります。
特異値分解については、上記記事を参考にしました。
そして単語を可視化するために、次は t-SNE を使用して次元を 50 から 2 に削減します。
t-SNE は 2 次元または 3 次元への次元削減に特に適しています。
t-Distributed Stochastic Neighbor Embedding (t-SNE):
t-SNE は、高次元データセットの視覚化に特に適した次元削減技法です。この技法は、高次元空間内の点の集合を取得し、それらの点の低次元空間 (通常は 2D 平面) における表現を見つけることを目標にします。ただ、t-SNE の複雑さは非常に高いため、通常は t-SNE を適用する前に他の高次元削減技術を使用します。
まず、t-SNE の実行に時間がかかるため、トレーニングおよびテストアイテムの説明からサンプルを取得します。その後、特異値分解を使用して各ベクトルの次元を n_components (50) に削減します。
trn = train.copy()
tst = test.copy()
trn['is_train'] = 1
tst['is_train'] = 0
sample_sz = 15000
combined_df = pd.concat([trn, tst])
combined_sample = combined_df.sample(n=sample_sz)
vz_sample = vectorizer.fit_transform(list(combined_sample['item_description']))
from sklearn.decomposition import TruncatedSVD
n_comp=30
svd = TruncatedSVD(n_components=n_comp, random_state=42)
svd_tfidf = svd.fit_transform(vz_sample)
from sklearn.manifold import TSNE
tsne_model = TSNE(n_components=2, verbose=1, random_state=42, n_iter=500)
tsne_tfidf = tsne_model.fit_transform(svd_tfidf)
このコードの全体的な流れは、トレーニングセットとテストセットのコピーを結合し、サンプルを抽出した後、tf-idf 行列を作成します。その後、特異値分解(SVD)を使って次元を削減し、さらに t-SNE を使って次元を 2 に削減します。これにより、説明文の次元削減されたデータを視覚化する準備が1つ整いました。
また今回は、Bokeh を使用して tf-idf 行列の次元削減後のデータポイントを視覚化するため、そのための準備を行います。
output_notebook()
plot_tfidf = bp.figure(plot_width=700, plot_height=600,
title="tf-idf clustering of the item description",
tools="pan,wheel_zoom,box_zoom,reset,hover,previewsave",
x_axis_type=None, y_axis_type=None, min_border=1)
output_notebook関数は、Bokeh プロットをノートブックに直接表示するための設定を行います。
この設定により、Bokeh を使って次元削減後の tf-idf 行列を視覚化できます。
このプロットには、さまざまなツールが含まれており、データポイントを詳細に調査することができます。例えば、tools パラメータは、プロットに使用するツールを指定します。
pan:プロットをドラッグして移動するツール
wheel_zoom:マウスホイールでズームインおよびズームアウトするツール
box_zoom:指定した範囲をズームインするツール
reset:プロットを元の状態にリセットするツール
hover:データポイントにカーソルを合わせると情報を表示するツール
previewsave:プロットを画像ファイルとして保存するツール
combined_sample.reset_index(inplace=True, drop=True)
tfidf_df = pd.DataFrame(tsne_tfidf, columns=['x', 'y'])
tfidf_df['description'] = combined_sample['item_description']
tfidf_df['tokens'] = combined_sample['tokens']
tfidf_df['category'] = combined_sample['general_cat']
plot_tfidf.scatter(x='x', y='y', source=tfidf_df, alpha=0.7)
hover = plot_tfidf.select(dict(type=HoverTool))
hover.tooltips={"description": "@description", "tokens": "@tokens", "category":"@category"}
show(plot_tfidf)
>>>出力結果

この画像は、商品説明を t-SNE によって次元削減し、Bokeh を使って可視化したもののプロットです。各商品説明がどのようにクラスタリングされるかを示しています。
画像から確認できることを以下3点です。
-
クラスタリングの可視化:
各点は商品説明を表しています。点の密集度や分布のパターンを見ることで、似たような説明を持つアイテムがどのようにグループ化されるかがわかります。 -
t-SNE による次元削減:
t-SNE は高次元データを2次元に縮約する手法で、データの構造やクラスタリングを視覚的に確認しやすくします。このプロットでは、50次元の tf-idf 特徴量を2次元に縮約しています。 -
ツールチップ機能:
Bokeh を使用しているため、プロット上の各点にカーソルを合わせると、ツールチップが表示されます。ツールチップには、商品説明、トークン、およびカテゴリが表示されます。これにより、各点が具体的にどの商品説明を表しているかを確認できます。
このプロットは、商品説明がどのようにグループ化されるかを視覚的に把握するために有用です。データの分布やクラスタの特徴を分析することで、データの傾向やパターンを理解する手助けとなります。
ツールチップはこんな感じ
いまカーソルを置いているあたりはwomanに関するものが多い。

3-5. 可視化②:k-means法
k-means法により、各ドキュメントや説明文が所属するクラスタの中心(セントロイド)からの平均二乗ユークリッド距離を最小化することができます。
先ほどt-SNEにより、データを適当なクラスタに分けられました。
ここからクラスタの平均を用いて、うまい具合にデータがわかれるように調整させていきます。
from sklearn.cluster import MiniBatchKMeans
num_clusters = 30 # need to be selected wisely
kmeans_model = MiniBatchKMeans(n_clusters=num_clusters,
init='k-means++',
n_init=1,
init_size=1000, batch_size=1000, verbose=0, max_iter=1000)
kmeans = kmeans_model.fit(vz)
kmeans_clusters = kmeans.predict(vz)
kmeans_distances = kmeans.transform(vz)
sorted_centroids = kmeans.cluster_centers_.argsort()[:, ::-1]
terms = vectorizer.get_feature_names()
for i in range(num_clusters):
print("Cluster %d:" % i)
aux = ''
for j in sorted_centroids[i, :10]:
aux += terms[j] + ' | '
print(aux)
print()
MiniBatchKMeansは、K-meansクラスタリングの効率的なバージョンで、大量のデータを扱う際に有効です。
ただ上記コードでは「IndexError: list index out of range」というエラーが起きます。
これは、sorted_centroids[i, :10] の部分で、クラスタのセントロイドのインデックスがリストの範囲を超えていることを意味します。このエラーを修正するためのに、クラスタ間の距離を低次元に減らす必要があります。そこで前述の t-SNE を使用します。
kmeans = kmeans_model.fit(vz_sample)
kmeans_clusters = kmeans.predict(vz_sample)
kmeans_distances = kmeans.transform(vz_sample)
tsne_kmeans = tsne_model.fit_transform(kmeans_distances)
colormap = np.array(["#6d8dca", "#69de53", "#723bca", "#c3e14c", "#c84dc9", "#68af4e", "#6e6cd5",
"#e3be38", "#4e2d7c", "#5fdfa8", "#d34690", "#3f6d31", "#d44427", "#7fcdd8", "#cb4053", "#5e9981",
"#803a62", "#9b9e39", "#c88cca", "#e1c37b", "#34223b", "#bdd8a3", "#6e3326", "#cfbdce", "#d07d3c",
"#52697d", "#194196", "#d27c88", "#36422b", "#b68f79"])
kmeans_df = pd.DataFrame(tsne_kmeans, columns=['x', 'y'])
kmeans_df['cluster'] = kmeans_clusters
kmeans_df['description'] = combined_sample['item_description']
kmeans_df['category'] = combined_sample['general_cat']
plot_kmeans = bp.figure(plot_width=700, plot_height=600,
title="KMeans clustering of the description",
tools="pan,wheel_zoom,box_zoom,reset,hover,previewsave",
x_axis_type=None, y_axis_type=None, min_border=1)
source = ColumnDataSource(data=dict(x=kmeans_df['x'], y=kmeans_df['y'],
color=colormap[kmeans_clusters],
description=kmeans_df['description'],
category=kmeans_df['category'],
cluster=kmeans_df['cluster']))
plot_kmeans.scatter(x='x', y='y', color='color', source=source)
hover = plot_kmeans.select(dict(type=HoverTool))
hover.tooltips={"description": "@description", "category": "@category", "cluster":"@cluster" }
show(plot_kmeans)

無事エラーもなく、k-means法による可視化ができました。
上記の解説したコードによって生成されたKMeansクラスタリングの可視化結果を示していますね。各点が異なる色で表示されており、それぞれの色がKMeansによって割り当てられたクラスタを表しています。ホバーすると、各点の詳細情報(説明、カテゴリ、クラスタ)が表示されるようになっています。
データフレームの作成のさい、前述でtsne_kmeansを用いて作成された次元削減されたデータを使い、kmeans_dfというDataFrameを作成しています。

例えば薄緑のクラスター9は、colorをしっかりと言及しているよう商品説明群に見えます。
3-6. 可視化③:LDA
トピックモデル(LDA)とは、「文書を構成する各単語はトピックに基づいて作られる」と仮定したモデルです。トピックとは、テーマや主題、分野のようなものです。トピックモデルでは、トピックごとに単語の出現頻度分布を想定することで、トピック間の類似性やその意味を解析できます。
例えば、アメリカのバイデン大統領と日本の岸田総理大臣がゴルフをしたという文書には、政治・スポーツ・国際の3つのトピックが入っていますね。
このように一つの文書は複数のトピックを持ちます。LDAでは各文書の単語ごとにトピックがあると仮定して、各単語はそのトピックからある確率で生成されたと考えます。つまり一つの文書に、政治っぽい単語があれば政治トピック、スポーツっぽい単語があればスポーツトピックのウェイトが高くなります。
引用:
以下のコードは、LDAを使用して上記商品説明のトピックを抽出し、各トピックに対して重要な単語を要約するためのものです。
LatentDirichletAllocationによってLDAモデルを設定します。
n_components はトピックの数を指定し、learning_method は学習方法を指定します。max_iter は最大の反復回数で、random_state は再現性のための乱数シードです。
cvectorizer = CountVectorizer(min_df=4,
max_features=180000,
tokenizer=tokenize,
ngram_range=(1,2))
cvz = cvectorizer.fit_transform(combined_sample['item_description'])
lda_model = LatentDirichletAllocation(n_components=20,
learning_method='online',
max_iter=20,
random_state=42)
X_topics = lda_model.fit_transform(cvz)
n_top_words = 10
topic_summaries = []
topic_word = lda_model.components_
vocab = cvectorizer.get_feature_names()
for i, topic_dist in enumerate(topic_word):
topic_words = np.array(vocab)[np.argsort(topic_dist)][:-(n_top_words+1):-1]
topic_summaries.append(' '.join(topic_words))
print('Topic {}: {}'.format(i, ' | '.join(topic_words)))
>>>出力結果
Topic 0: plus | shoes | necklace | mini | iphone plus | black | white | ipad | chain | book
Topic 1: bundle | save | items | ask | make | bundle save | please | one | want | free
Topic 2: case | iphone | works | phone | charger | screen | deal | cable | touch | one
Topic 3: description | yet | description yet | skin | time | edition | limited | soap | face | regular
Topic 4: free | shipping | free shipping | home | smoke | free home | smoke free | price | new | pet
Topic 5: please | day | ship | item | shipping | inches | purchase | items | know | let
Topic 6: pink | cute | super | black | secret | victoria | victoria secret | size | grey | super cute
Topic 7: worn | never worn | size | never | top | times | one | fits | nwt | pretty
Topic 8: care | rae | dunn | rae dunn | bubble | self | tear | slim | seal | weight
Topic 9: new tags | gold | new | color | tags | silver | green | black | size | like
Topic 10: condition | good | good condition | excellent | used | perfect | excellent condition | size | times | worn
Topic 11: use | come | apple | take | sale | store | hours | fast | around | days
Topic 12: like | new | like new | nike | pants | size | sweater | new condition | condition | shirt
Topic 13: fit | flaws | look | baby | light | last | jeans | size | would | hard
Topic 14: new | brand | brand new | never | used | box | never used | new never | size | tags
Topic 15: great | condition | great condition | bag | stains | inside | leather | zipper | pocket | strap
Topic 16: size | small | medium | large | dress | black | size small | back | women | size medium
Topic 17: full | color | hair | set | colors | brush | matte | makeup | lip | water
Topic 18: price | still | firm | used | price firm | authentic | see | body | picture | gently
Topic 19: lularoe | leggings | brown | per | lashes | nose | instructions | lularoe leggings | gel | inner
20のトピックとそれに関連する重要な単語が生成されました。
上記をクラスタリングで可視化します。
tsne_lda = tsne_model.fit_transform(X_topics)
unnormalized = np.matrix(X_topics)
doc_topic = unnormalized/unnormalized.sum(axis=1)
lda_keys = []
for i, tweet in enumerate(combined_sample['item_description']):
lda_keys += [doc_topic[i].argmax()]
lda_df = pd.DataFrame(tsne_lda, columns=['x','y'])
lda_df['description'] = combined_sample['item_description']
lda_df['category'] = combined_sample['general_cat']
lda_df['topic'] = lda_keys
lda_df['topic'] = lda_df['topic'].map(int)
plot_lda = bp.figure(plot_width=700,
plot_height=600,
title="LDA topic visualization",
tools="pan,wheel_zoom,box_zoom,reset,hover,previewsave",
x_axis_type=None, y_axis_type=None, min_border=1)
source = ColumnDataSource(data=dict(x=lda_df['x'], y=lda_df['y'],
color=colormap[lda_keys],
description=lda_df['description'],
topic=lda_df['topic'],
category=lda_df['category']))
plot_lda.scatter(source=source, x='x', y='y', color='color')
hover = plot_kmeans.select(dict(type=HoverTool))
hover = plot_lda.select(dict(type=HoverTool))
hover.tooltips={"description":"@description",
"topic":"@topic", "category":"@category"}
show(plot_lda)

LDAを用いて生成されたトピックの単語要約を示しています。各トピックには、それぞれに関連する上位の単語が表示されており、それらの単語がトピックを表現している内容を示しています。
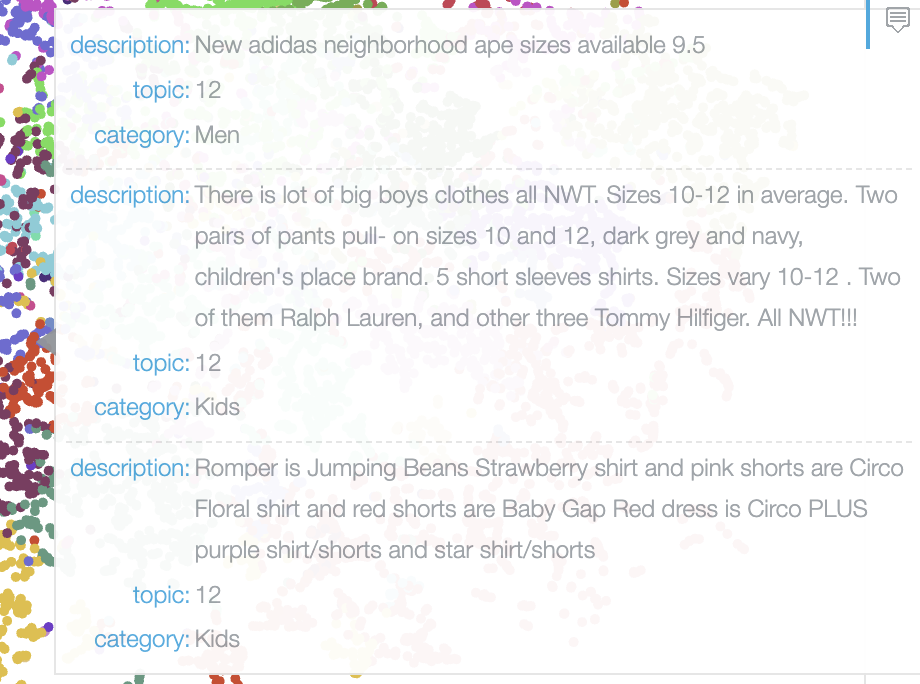
例えば、トピック12ではブランド名を明記したアパレルグッズやconditionについても明記されている商品が多い印象です。
4. まとめ
今回はKaggleのメルカリ主催コンペについて、既存の優秀なEDSコードを丁寧に真似&解説していくことを行いました。(予想よりかなり長くなってしまい、読んでくださる方にはなんだか申し訳ないです。)
今回のアクションを通じて、学んだことをまとめると以下です。
-
探索的データ解析(EDA)の重要性
Kaggleコンペの上位のノートブックを漁っていると、よく「First:〇〇-EDA」とか「探索的データ解析」とかをよく見かけます。導入フレーズのデータ可視化か〜くらいにしか思っていませんでしたが、かなり奥の深い世界ですね。
ビジネスにおいてデータ分析は、問題を解決するため・仮説を検証するためにあると思いますが、そのためにはどのようなデータセットを扱っているのか、どのような状況にあるのかをしっかりと理解するのが重要です。
今回もメルカリのデータセットがどういった構成で成っていて、商品説明の変数がどれだけ重要か、という前提がわかりました。こうして次フェーズ以降の分析に入る際の見立ても立つため、EDAのレベルでデータ分析全体のレベルも変わりそうですね。 -
機械学習を用いた、ビッグデータのトピックモデリング
今回後半では説明変数の1つ「商品説明」に関して、説明内に含まれる単語を用いてクラスタリング(トピックモデリング)を行いました。一見「なんか人間でもできるんじゃね?」と思えるアクションですが、今回のデータセットは約15万件ありました。とてもではないですが、人間の作業でやるにはしんどいですね。
こうしたビッグデータは、膨大かつ非構造の情報(書き方が揃っていないこと、記載ルールが統一されていないことなど)を含んでおり、それを人間が直感で理解し利用することは難しいです。トピックモデリングは、このような情報をトピックごとに分割し、構造化して解釈可能な情報に変換かつ意外なパターンや関連性を見つけ出すことが可能です。
実ビジネスでもSNSの消費者トレンドを予測することや医療記録・文献データから疾患のパターンや治療効果を抽出することなど、さまざまな面で利用されています。 -
コーティングする際のChatGPTの便利さ
今回の投稿を作成する際、思ってもいなかった発見がこれです。
「ChatGPTすげえ…!」
正直このChatGPTの有用性を知れたことが今回の一番の成果かもしれません。
コーティングをする際、解説やエラーを教えてもらったのですが、これが本当に正確かつわかりやすい!少々雑なプロンプトにも対応してくれました。ある程度のデータ分析の流れと統計学がわかっていれば、暗記は本当に不要になるのでは…?
↓こんな感じ。初見の変数やライブラリでも使い方を教えてくれる。

プログラマーは将来なくなる職業とよく言われていますが、それを肌で実感しました。現在Aidemyで機械学習の全体概要や具体的ツールを学んでいますが、学び方を改めて意識しようと思わされました。ただの技術力を磨くだけではなく、ビジネスとしての使える価値を追うこと、これができないと私自身の市場価値も下がってしまいそうです。例えば、こうして細かな解説や感情を乗せて伝えることはAIにはできないことの1つだと思います。
5. そのほか引用・補足
ちなみにデータ分析まで行ったスコア1位のノートブックは、下記です。
初めはこのコードを解説しようと考えていたのですが、
すでにさまざまな場所で解説がありましたので、本投稿のコードにしました。
以下の方々は自分でコードを作成されてコンペに参加されているので、すごいです。
特に2つ目の方は初学者でよくぞここまで…!