1. 今回扱うKaggleコンペについて
1-1. コンペ概要
今回のコンペのテーマ:アメリカン・エキスプレス のデフォルト予測
毎月の顧客ファイルに基づいて、「顧客が将来クレジットカードの残高を返済しない可能性」を予測します。
データセットである顧客ファイルは、最新のクレジットカード明細書から18か月分の動きを観察したもので、最終的に顧客が最新の明細書の日付から120日以内に支払わない場合は、デフォルト(陽性)と見なします。データセット内には特徴量として、
- D_* = 延滞変数
- S_* = 支出変数
- P_* = 支払い変数
- B_* = バランス変数
- R_* = リスク変数
など、合計して190のカラムがあります。
アメリカンエキスプレス、通称アメックスは日本でもよく知られている金融ブランドですね。日本では加盟店数や認知度からまだまだVISAやJCBが主流ですが、誰しも一度は聞いたことがあるかと思います。私はアメックスを持っている方は、少しリッチな方や旅行好きな方の印象がありました。
余談ですが、アメリカではクレジットカード文化が少し日本とは異なるようです。
クレジットカードは”信用の証”となるらしく、それは利用歴によって伝わります。滞納や不履行がない→支払い能力がある→サービスを提供できる…と言った具合でしょうか。
そんなアメリカンエキスプレス社が2年前に主催したコンペです。
1-2.評価方法
このコンペでは評価指標𝑀があらかじめ定められています。
𝑀 = (𝐺+𝐷) * 1/2
𝐺:順位付けの2つの尺度である正規化ジニ係数
𝐷:予測の上位4%でキャプチャされた正のラベルの平均(recall:再現率)
ジニ係数とは、データの不平等や分布の偏りを測定する統計指標です。機械学習では、モデルの予測順位の精度を評価するために使用されます。
正規化ジニ係数と再現率の平均を評価指標として使用することで、モデルが全体的に優れた予測性能を持ちながら、最も重要なケースを効果的に識別できるかをバランスよく評価できます。
評価指標は、分析・実用の際に非常に重要です。この評価指標を何にするかによって、データ分析の目的が想像できます。
本コンペ内でここまで言及されてはいませんが、おそらく今回の分析は、不履行になる予測を見たいがそれだけだと正常な履行の顧客を不履行にする割合が増えてしまうので、再現率にバランサーとしてジニ係数を足した形だと予想しています。
1-3. 解説するノートブック
使用モデル;XGBoost
データローダー:DeviceQuantileDMatrix
CV(クロスバリデーション):0.792
LB(スコア):0.793
「データローダー」とは、機械学習やデータサイエンスのコンテキストにおいて、データセットを効率的に読み込み・処理し、モデルに供給するためのツールやライブラリを指します。特に大規模なデータセットを扱う場合に重要な役割を果たします。
今回のデータローダーはGPUメモリの使用量が少なく、このおかげで、追加のカラムを多くエンジニアリングし、より多くのデータ行でトレーニングすることが可能でした。
本ノートブックの大きな特徴は、「Leader Board(スコア)が高い」だけでなく、「CV(クロスバリテーション)も高い」点です。
クロスバリデーション、つまり交差検証です。
trainデータを、さらにtestデータとtrainデータ(交差検証用のデータ)に分け、モデルを構築したあと交差検証用のデータを使ってモデルの精度の測定をしています。LBだけが高いと過学習を起こし汎化性能が低い可能性があるため、LBとCVどちらもが高く計算されることが理想です。
本ノートブックはスコアも上位10%でゴールドメダルを受賞、またKagglerからの投票数がぶっちぎりの1位です。そんなノートブックの要点を今回は解説していきます。
2. 本投稿からの学び3選
2-1.学び① 既存のEDAと組み合わせる
Kaggleコンペには分析・予測まで行っているノートブックと、探索的データ分析(EDA)だけを行っているノートブックがあります。
今回のノートブックでも、こうした”役割分担”を有効活用できることを学びました。
特にデータの特徴を知ることや可視化することに関して、手段はたくさんありますがデータセット自体は1つです。
確かにここに対して全コンペの提出物が争う必要はありません。
しっかりとデータの概要と特徴をつかむことができているEDAが1つあれば、それで十分です。
それよりもモデルの選定や評価数値(CVやLB)を改善することに時間をかけるほうがベターだと思います。
2-2.学び② 説明変数の追加
今回のノートブックでは、すでに用意されている特徴量190から、918にまで追加(細分化)している点が大きな特徴です。
例えば、顧客のある期間の「支出変数」が数十個カラムとして追加されていましたが、
それら「”複数”の支出変数」がある場合、これらのすべてを単体として変数ととるだけでなく、変数の「平均値」「最小値」「偏差」などを変数として扱っていました。
支出が全体的に高い人やある月だけ飛び抜けて支出が高い人、不履行になる可能性が高いのはどちらか…?など直感ではなかなかわかりにくいですが、大規模データと機械学習によって判断できますね。
こうしたそれぞれの項目が期間ごとに変数となっている場合は、変数を追加する意義があるように感じます。
2-3.学び③ バッチ処理のためのデータローダーの定義
今回データローダーとしてDeviceQuantileDMatrixを使用しています。これは、XGBoostライブラリで使用されるデータ形式の一つで、特にGPUを活用する際に効率的なメモリ使用と高速なトレーニングを可能にします。
特に大規模データの分析には適している形式です。使用自体は簡単ですが、強いていうとすれば、「GPU環境が必要」という大前提が使用するにあたっての難点かもしれません。
# バッチ処理のためのデータローダーを作成
Xy_train = IterLoadForDMatrix(train.loc[train_idx], FEATURES, 'target')
# DeviceQuantileDMatrixを作成して訓練データを準備
dtrain = xgb.DeviceQuantileDMatrix(Xy_train, max_bin=256)
# 検証データを準備
X_valid = train.loc[valid_idx, FEATURES]
y_valid = train.loc[valid_idx, 'target']
dvalid = xgb.DMatrix(data=X_valid, label=y_valid)
# モデルの訓練
model = xgb.train(
params=xgb_parms,
dtrain=dtrain,
evals=[(dtrain, 'train'), (dvalid, 'valid')],
num_boost_round=9999,
early_stopping_rounds=100,
verbose_eval=100
)
3.コードの要点
ここからは具体的な分析コード・機械学習のテクニックについてです。
今回は冒頭3-1でコード全体の流れを確認した後、要点となっているコード部分を細かく見ていきます。
3-1. 全体の流れ
-
ライブラリの読み込み
- ライブラリのインポート: 必要なPythonライブラリ(pandas, numpy, cupy, cudf, matplotlib, xgboostなど)を読み込み
-
データの読み込みと前処理
- データの読み込み: cudfライブラリを使用し、提供されたトレーニングデータを読み込み
- データ型への変換: customer_IDとS_2のデータ型を変換し、NaN値を特定の値(-127)で補完
- 特徴量エンジニアリング: 特徴量の集約処理を行い、数値特徴とカテゴリ特徴を集約
-
ターゲットの追加
- ターゲットデータを読み込み、トレーニングデータに結合
-
XGBoostモデルのトレーニング
- XGBoostライブラリのインポート: xgboostライブラリを読み込み
- モデルのパラメータ設定: XGBoostモデルのハイパーパラメータ(max_depth, learning_rate, subsampleなど)を設定
- データローダーの定義: DeviceQuantileDMatrixに対応したデータローダーを定義し、大規模データの処理を効率化
- 評価指標の定義: Kaggleの指定された評価指標を定義
- クロスバリデーションでのトレーニング: K-Foldを使用してトレーニング、各フォールドでの性能を評価
- モデルのトレーニング
-
トレーニング結果の保存と特徴量の可視化
- OOF(Out-Of-Fold)予測: クロスバリデーションの結果を保存し、各顧客の予測結果をCSVファイルに書き込み
- 特徴量の重要度の可視化: 特徴量の重要度を集計し、可視化。
-
テストデータの処理
- テストデータの読み込みと前処理: トレーニングデータと同様の前処理
- テストデータのサイズ確認と処理: テストデータを複数部に分けて処理するための関数を定義
3-2. データの前処理
3-2-1. cudfライブラリの使用
今回初めましての 「cudf」ライブラリについて、触れておきます。
import cupy, cudf
cudfは、NVIDIAが提供しているライブラリで、Pandasと使い方はほぼ同じです。データフレームの操作に特化しているのですが、大きな特徴は「GPUを使用している点」です。
GPUを使用するため、CPUを使用したPandasよりもcsvの読み込みが高速になり、またメモリも効率的に使うため、大規模データも扱いやすくなるようです。
今回使用してみて、特に大きな不自由点は感じませんでした。
使用条件だけ、CPUを使うPandasとは異なるのでその点だけ要確認ですね。
3-2-2. 特徴量の追加
データの前処理段階で、本コードでは新しい特徴量を追加しています。
この追加は、他の特徴量エンジニアリングしたノートブックを参照したり他のkagglerを意見交換をし、必要だと結論づけられているようです。Kaggleには特徴量を整理しただけのノートも多くあり、それは分析の工程で非常に重要ですし、ここに時間がかかるため重宝されています。
この特徴量の追加操作が以下のコードです。
def process_and_feature_engineer(df):
all_cols = [c for c in list(df.columns) if c not in ['customer_ID','S_2']]
cat_features = ["B_30","B_38","D_114","D_116","D_117","D_120","D_126","D_63","D_64","D_66","D_68"]
num_features = [col for col in all_cols if col not in cat_features]
test_num_agg = df.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last'])
test_num_agg.columns = ['_'.join(x) for x in test_num_agg.columns]
test_cat_agg = df.groupby("customer_ID")[cat_features].agg(['count', 'last', 'nunique'])
test_cat_agg.columns = ['_'.join(x) for x in test_cat_agg.columns]
df = cudf.concat([test_num_agg, test_cat_agg], axis=1)
del test_num_agg, test_cat_agg
print('shape after engineering', df.shape )
return df
train = process_and_feature_engineer(train)
正確にいうと追加というよりは、細分化かもしれません。
まず新しい特徴量を生成する関数process_and_feature_engineerを定義しています。
またcat_featuresのカラムは文字列だったので、ここリスト型にもで変換しています。
その後、カスタマーIDごとにそれぞれの変数の「平均」「標準偏差 」「最小値 」「最大値 」「最後の値」を集計しています。
この集計したものを最初のprocess_and_feature_engineerによって、trainに追加しています。
num_aggが数値変数、cat_aggがカテゴリ変数を操作したものです。
この操作により、変数は918にまで増加しています。
3-3. XGBoostモデルの使用
前処理が済んだ後は、モデルの学習です。
本ノートブックではXGBoostモデルを使用しています。
XGBoostは数々のKaggleコンペで上位ランクの常連になっているアルゴリズムです。
上位になったノートだけでリストができるほど…
XGBoostは簡単にいうと、「決定木」「勾配」「ブースティング」の3つの特徴を組み合わせたもの。詳しいアルゴリズムは今回省略しますが、以下のサイトがわかりやすかったです。
パラメータの設定が煩雑、時間がかかるなどのデメリットはありますが、それを乗り越えると強力なモデルとなるわけです。
また1つ大きなメリットとして…XGBoostは欠損値を対処するアルゴリズムが組み込まれているので,欠損値をdropしたり代入する必要がなく,欠損値があるデータをそのままモデルに学習させることができます。これはでかい。
3-3-1. XGBoostモデルの構築準備
まずは前半、モデルを構築するための準備を行います。具体的には、必要なライブラリの読み込み、XGBoostのバージョン確認、そしてXGBoostモデルのハイパーパラメータを設定します。
# LOAD XGB LIBRARY
from sklearn.model_selection import KFold
import xgboost as xgb
print('XGB Version',xgb.__version__)
# XGB MODEL PARAMETERS
xgb_parms = {
'max_depth':4,
'learning_rate':0.05,
'subsample':0.8,
'colsample_bytree':0.6,
'eval_metric':'logloss',
'objective':'binary:logistic',
'tree_method':'gpu_hist',
'predictor':'gpu_predictor',
'random_state':SEED
}
>>>出力結果
XGB Version 1.6.1
モデルのバージョンを最初に確認する理由はいくつかありますが、主に以下2つです。
①互換性の確認
異なるバージョンのライブラリでは、関数やメソッドの挙動が異なることがあります。特定のバージョンで動作するコードが、他のバージョンではエラーを引き起こすこともあるようです。また分析のコーティングにあたり複数のライブラリを使用している場合、それらのライブラリ間で互換性の問題が発生することもあります。指定されたバージョンを使用することで、これらの問題を回避できます。
②再現性の確保
機械学習の実験やモデルのトレーニング結果を再現するためには、使用するライブラリのバージョンを明確にすることが重要です。これにより同じコードを異なる環境で実行した際に、一貫した結果が得られます。
次にパラメータを設定していますが、長文のため折りたたみで記載しておきます。
各パラメータの説明
max_depth:決定木の最大深さ。過学習を防ぐために深さを制限します。learning_rate:各ステップでの重みの縮小率。低くするとより多くのステップが必要になりますが、精度が向上する可能性があります。
subsample:各決定木を学習する際に使用するデータの割合。過学習を防ぐために使用します。
colsample_bytree:各決定木を学習する際に使用する特徴量の割合。これも過学習を防ぐために使用します。
eval_metric:評価指標。logloss はロジスティック損失を使用します。
objective:目的関数。binary:logistic は二値分類問題を解くためのロジスティック回帰を意味します。
tree_method:決定木の構築に使用するアルゴリズム。gpu_hist はGPUでのヒストグラムベースのアルゴリズムを使用します。
predictor:予測に使用するアルゴリズム。gpu_predictor はGPUでの予測を行います。
random_state:乱数シード。結果を再現可能にするために使用します。
3-3-2. XGBoostモデルの学習・性能評価
続いてのコードは、XGBoostを使用して交差検証を行い、アウト・オブ・フォールド(OOF)の予測を行います。また、あらかじめ与えられていた評価指標を使用してモデルの性能を評価します。
まずは、データのバッチ処理のクラスを定義します。
class IterLoadForDMatrix(xgb.core.DataIter):
def __init__(self, df=None, features=None, target=None, batch_size=256*1024):
self.features = features
self.target = target
self.df = df
self.it = 0 # set iterator to 0
self.batch_size = batch_size
self.batches = int(np.ceil(len(df) / self.batch_size))
super().__init__()
def reset(self):
'''Reset the iterator'''
self.it = 0
def next(self, input_data):
'''Yield next batch of data.'''
if self.it == self.batches:
return 0 # Return 0 when there's no more batch.
a = self.it * self.batch_size
b = min((self.it + 1) * self.batch_size, len(self.df))
dt = cudf.DataFrame(self.df.iloc[a:b])
input_data(data=dt[self.features], label=dt[self.target])
self.it += 1
return 1
IterLoadForDMatrixクラスは、大きなデータセットをバッチ処理するため、リストなどの複数の要素をもったデータ型に対し順番にデータを取り出す機能を提供しています。このあと使用するDeviceQuantileDMatrixというデータローダーと連携して使用されることが多いです。
ここでは定義だけの準備ですね。
次に評価指標の定義です。
def amex_metric_mod(y_true, y_pred):
labels = np.transpose(np.array([y_true, y_pred]))
labels = labels[labels[:, 1].argsort()[::-1]]
weights = np.where(labels[:,0]==0, 20, 1)
cut_vals = labels[np.cumsum(weights) <= int(0.04 * np.sum(weights))]
top_four = np.sum(cut_vals[:,0]) / np.sum(labels[:,0])
gini = [0,0]
for i in [1,0]:
labels = np.transpose(np.array([y_true, y_pred]))
labels = labels[labels[:, i].argsort()[::-1]]
weight = np.where(labels[:,0]==0, 20, 1)
weight_random = np.cumsum(weight / np.sum(weight))
total_pos = np.sum(labels[:, 0] * weight)
cum_pos_found = np.cumsum(labels[:, 0] * weight)
lorentz = cum_pos_found / total_pos
gini[i] = np.sum((lorentz - weight_random) * weight)
return 0.5 * (gini[1]/gini[0] + top_four)
amex_metric_mod 関数は、指定された評価指標を計算する関数です。モデルの性能を評価するために使用します。
次はいよいよ、交差検証とモデル学習です。
KFold交差検証を使用してデータを複数の分割に分け、各分割ごとにXGBoostモデルをトレーニング。その後、OOF予測を生成し、モデルの性能を評価します。
importances = []
oof = []
train = train.to_pandas() # free GPU memory
TRAIN_SUBSAMPLE = 1.0
gc.collect()
#kfold setting
skf = KFold(n_splits=FOLDS, shuffle=True, random_state=SEED)
for fold, (train_idx, valid_idx) in enumerate(skf.split(train, train.target)):
if TRAIN_SUBSAMPLE < 1.0:
np.random.seed(SEED)
train_idx = np.random.choice(train_idx, int(len(train_idx) * TRAIN_SUBSAMPLE), replace=False)
np.random.seed(None)
#foldごとの情報を出力
print('#' * 25)
print('### Fold', fold + 1)
print('### Train size', len(train_idx), 'Valid size', len(valid_idx))
print(f'### Training with {int(TRAIN_SUBSAMPLE * 100)}% fold data...')
print('#' * 25)
#バッチ処理
Xy_train = IterLoadForDMatrix(train.loc[train_idx], FEATURES, 'target')
X_valid = train.loc[valid_idx, FEATURES]
y_valid = train.loc[valid_idx, 'target']
#DeviceQuantileDMatrixの作成
dtrain = xgb.DeviceQuantileDMatrix(Xy_train, max_bin=256)
dvalid = xgb.DMatrix(data=X_valid, label=y_valid)
model = xgb.train(xgb_parms, dtrain=dtrain, evals=[(dtrain, 'train'), (dvalid, 'valid')],
num_boost_round=9999, early_stopping_rounds=100, verbose_eval=100)
model.save_model(f'XGB_v{VER}_fold{fold}.xgb')
#特徴量重要度の取得
dd = model.get_score(importance_type='weight')
df = pd.DataFrame({'feature': dd.keys(), f'importance_{fold}': dd.values()})
importances.append(df)
#OOF予測の取得と評価
oof_preds = model.predict(dvalid)
acc = amex_metric_mod(y_valid.values, oof_preds)
print('Kaggle Metric =', acc, '\n')
df = train.loc[valid_idx, ['customer_ID', 'target']].copy()
df['oof_pred'] = oof_preds
oof.append(df)
del dtrain, Xy_train, dd, df
del X_valid, y_valid, dvalid, model
_ = gc.collect()
#全体のOOF評価
print('#' * 25)
oof = pd.concat(oof, axis=0, ignore_index=True).set_index('customer_ID')
acc = amex_metric_mod(oof.target.values, oof.oof_pred.values)
print('OVERALL CV Kaggle Metric =', acc)
出力結果
Fold 1
Train size 367130 Valid size 91783
Training with 100% fold data...
[0] train-logloss:0.66283 valid-logloss:0.66283
[100] train-logloss:0.23666 valid-logloss:0.23945
[200] train-logloss:0.22229 valid-logloss:0.22760
[300] train-logloss:0.21621 valid-logloss:0.22366
[400] train-logloss:0.21221 valid-logloss:0.22161
[500] train-logloss:0.20900 valid-logloss:0.22033
[600] train-logloss:0.20626 valid-logloss:0.21954
[700] train-logloss:0.20391 valid-logloss:0.21902
[800] train-logloss:0.20165 valid-logloss:0.21865
[900] train-logloss:0.19943 valid-logloss:0.21827
[1000] train-logloss:0.19736 valid-logloss:0.21805
[1100] train-logloss:0.19537 valid-logloss:0.21784
[1200] train-logloss:0.19343 valid-logloss:0.21770
[1300] train-logloss:0.19160 valid-logloss:0.21759
[1400] train-logloss:0.18973 valid-logloss:0.21751
[1500] train-logloss:0.18788 valid-logloss:0.21745
[1600] train-logloss:0.18614 valid-logloss:0.21740
[1700] train-logloss:0.18442 valid-logloss:0.21737
[1798] train-logloss:0.18279 valid-logloss:0.21744
Kaggle Metric = 0.7917197917828411
Fold 2
Train size 367130 Valid size 91783
Training with 100% fold data...
[0] train-logloss:0.66289 valid-logloss:0.66280
[100] train-logloss:0.23714 valid-logloss:0.23787
[200] train-logloss:0.22289 valid-logloss:0.22583
[300] train-logloss:0.21670 valid-logloss:0.22182
[400] train-logloss:0.21265 valid-logloss:0.21992
[500] train-logloss:0.20945 valid-logloss:0.21874
[600] train-logloss:0.20668 valid-logloss:0.21798
[700] train-logloss:0.20423 valid-logloss:0.21755
[800] train-logloss:0.20192 valid-logloss:0.21723
[900] train-logloss:0.19980 valid-logloss:0.21702
[1000] train-logloss:0.19773 valid-logloss:0.21688
[1100] train-logloss:0.19572 valid-logloss:0.21674
[1200] train-logloss:0.19390 valid-logloss:0.21664
[1300] train-logloss:0.19201 valid-logloss:0.21651
[1400] train-logloss:0.19013 valid-logloss:0.21641
[1500] train-logloss:0.18834 valid-logloss:0.21638
[1560] train-logloss:0.18729 valid-logloss:0.21640
Kaggle Metric = 0.7918055597633943
Fold 3
Train size 367130 Valid size 91783
Training with 100% fold data...
[0] train-logloss:0.66282 valid-logloss:0.66298
[100] train-logloss:0.23658 valid-logloss:0.24061
[200] train-logloss:0.22214 valid-logloss:0.22869
[300] train-logloss:0.21602 valid-logloss:0.22472
[400] train-logloss:0.21201 valid-logloss:0.22280
[500] train-logloss:0.20872 valid-logloss:0.22174
[600] train-logloss:0.20598 valid-logloss:0.22106
[700] train-logloss:0.20352 valid-logloss:0.22052
[800] train-logloss:0.20125 valid-logloss:0.22017
[900] train-logloss:0.19910 valid-logloss:0.21989
[1000] train-logloss:0.19700 valid-logloss:0.21964
[1100] train-logloss:0.19499 valid-logloss:0.21955
[1200] train-logloss:0.19303 valid-logloss:0.21941
[1300] train-logloss:0.19120 valid-logloss:0.21931
[1400] train-logloss:0.18935 valid-logloss:0.21930
[1500] train-logloss:0.18760 valid-logloss:0.21928
[1600] train-logloss:0.18586 valid-logloss:0.21923
[1700] train-logloss:0.18412 valid-logloss:0.21921
[1800] train-logloss:0.18245 valid-logloss:0.21917
[1868] train-logloss:0.18129 valid-logloss:0.21924
Kaggle Metric = 0.7897768157182407
Fold 4
Train size 367131 Valid size 91782
Training with 100% fold data...
[0] train-logloss:0.66280 valid-logloss:0.66295
[100] train-logloss:0.23653 valid-logloss:0.24081
[200] train-logloss:0.22220 valid-logloss:0.22880
[300] train-logloss:0.21597 valid-logloss:0.22492
[400] train-logloss:0.21188 valid-logloss:0.22304
[500] train-logloss:0.20870 valid-logloss:0.22206
[600] train-logloss:0.20592 valid-logloss:0.22133
[700] train-logloss:0.20341 valid-logloss:0.22072
[800] train-logloss:0.20111 valid-logloss:0.22037
[900] train-logloss:0.19898 valid-logloss:0.22016
[1000] train-logloss:0.19685 valid-logloss:0.21999
[1100] train-logloss:0.19480 valid-logloss:0.21986
[1200] train-logloss:0.19283 valid-logloss:0.21972
[1300] train-logloss:0.19092 valid-logloss:0.21968
[1400] train-logloss:0.18910 valid-logloss:0.21962
[1500] train-logloss:0.18732 valid-logloss:0.21963
[1521] train-logloss:0.18696 valid-logloss:0.21964
Kaggle Metric = 0.7878938674425217
Fold 5
Train size 367131 Valid size 91782
Training with 100% fold data...
[0] train-logloss:0.66285 valid-logloss:0.66277
[100] train-logloss:0.23742 valid-logloss:0.23813
[200] train-logloss:0.22312 valid-logloss:0.22596
[300] train-logloss:0.21693 valid-logloss:0.22189
[400] train-logloss:0.21286 valid-logloss:0.21983
[500] train-logloss:0.20967 valid-logloss:0.21863
[600] train-logloss:0.20698 valid-logloss:0.21791
[700] train-logloss:0.20450 valid-logloss:0.21738
[800] train-logloss:0.20219 valid-logloss:0.21693
[900] train-logloss:0.20003 valid-logloss:0.21655
[1000] train-logloss:0.19793 valid-logloss:0.21634
[1100] train-logloss:0.19592 valid-logloss:0.21608
[1200] train-logloss:0.19393 valid-logloss:0.21594
[1300] train-logloss:0.19205 valid-logloss:0.21580
[1400] train-logloss:0.19018 valid-logloss:0.21569
[1500] train-logloss:0.18836 valid-logloss:0.21559
[1600] train-logloss:0.18656 valid-logloss:0.21557
[1700] train-logloss:0.18479 valid-logloss:0.21545
[1800] train-logloss:0.18310 valid-logloss:0.21537
[1900] train-logloss:0.18141 valid-logloss:0.21533
[1964] train-logloss:0.18038 valid-logloss:0.21535
Kaggle Metric = 0.7953943638785084
OVERALL CV Kaggle Metric = 0.7913582522747471
このコードにより、交差検証を通じてXGBoostモデルを効果的にトレーニングし、評価指標を用いてモデルの性能を評価することができます。
ちなみにOut of foldについて整理しておきます。
- Out of Fold (OOF) とは?
OOFは、交差検証の過程でトレーニングに使用されなかったデータ(検証データ)に対する予測のこと。具体的には、KFold交差検証を行う際に、各分割でモデルをトレーニングし、そのモデルを使って検証データに対して予測を行うことで得られる予測値のこと。モデルの汎化性能(未知のデータに対する予測性能)を評価するために使用。
3-4.テストデータの処理と提出
trainデータと同じデータ分割し、その部分ごとにXGBoostモデルを使用して予測を行うことができます。ここはこれまでの操作とほぼ同様の操作になるため、解説は割愛します。
# CALCULATE SIZE OF EACH SEPARATE TEST PART
def get_rows(customers, test, NUM_PARTS = 4, verbose = ''):
chunk = len(customers)/NUM_PARTS
if verbose != '':
print(f'We will process {verbose} data as {NUM_PARTS} separate parts.')
print(f'There will be {chunk} customers in each part (except the last part).')
print('Below are number of rows in each part:')
rows = []
for k in range(NUM_PARTS):
if k==NUM_PARTS-1: cc = customers[k*chunk:]
else: cc = customers[k*chunk:(k+1)*chunk]
s = test.loc[test.customer_ID.isin(cc)].shape[0]
rows.append(s)
if verbose != '': print( rows )
return rows,chunk
NUM_PARTS = 4
TEST_PATH = '../input/amex-data-integer-dtypes-parquet-format/test.parquet'
print(f'Reading test data...')
test = read_file(path = TEST_PATH, usecols = ['customer_ID','S_2'])
customers = test[['customer_ID']].drop_duplicates().sort_index().values.flatten()
rows,num_cust = get_rows(customers, test[['customer_ID']], NUM_PARTS = NUM_PARTS, verbose = 'test')
skip_rows = 0
skip_cust = 0
test_preds = []
for k in range(NUM_PARTS):
print(f'\nReading test data...')
test = read_file(path = TEST_PATH)
test = test.iloc[skip_rows:skip_rows+rows[k]]
skip_rows += rows[k]
print(f'=> Test part {k+1} has shape', test.shape )
# PROCESS AND FEATURE ENGINEER PART OF TEST DATA
test = process_and_feature_engineer(test)
if k==NUM_PARTS-1: test = test.loc[customers[skip_cust:]]
else: test = test.loc[customers[skip_cust:skip_cust+num_cust]]
skip_cust += num_cust
# TEST DATA FOR XGB
X_test = test[FEATURES]
dtest = xgb.DMatrix(data=X_test)
test = test[['P_2_mean']] # reduce memory
del X_test
gc.collect()
# INFER XGB MODELS ON TEST DATA
model = xgb.Booster()
model.load_model(f'XGB_v{VER}_fold0.xgb')
preds = model.predict(dtest)
for f in range(1,FOLDS):
model.load_model(f'XGB_v{VER}_fold{f}.xgb')
preds += model.predict(dtest)
preds /= FOLDS
test_preds.append(preds)
# CLEAN MEMORY
del dtest, model
_ = gc.collect()
これで結果の確認とノートの提出を行い終了となります。
ちなみにノートブックには特徴量の重要性をそれぞれ可視化しています。
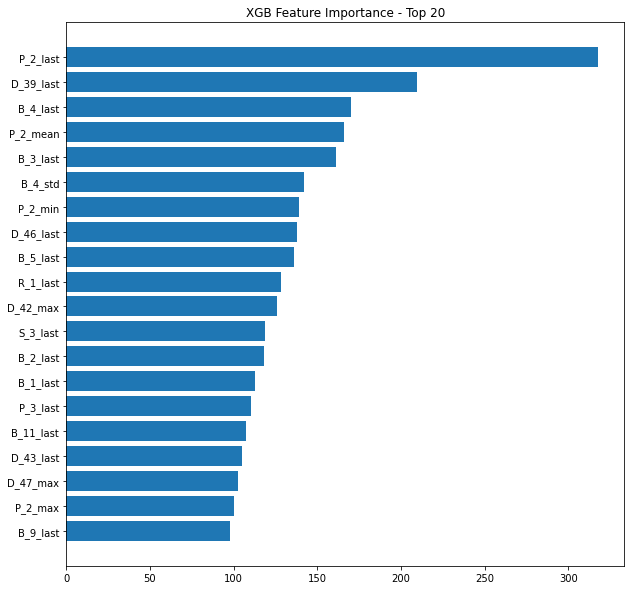
パッとみただけではどれがどれの項目かわからないですね、おそらくアメックス側で把握できるのでいいと思うのですが…。
lastが重要ということは「データの最後」の変数が重要な説明要因となっているようです。
データを追加した意義があったということですね。