本記事の要約
初学者向けに、Nishikaコンペ「中古マンション価格予測」への参加経験を紹介します。Nishikaはデータサイエンスコンペサイトで、簡単なUIと日本語対応が魅力。筆者は、前処理の重要性や難しさを再認識し、特徴量エンジニアリングやモデル選定の重要性を学びました。特に、OptunaとLightGBMを組み合わせることで、ハイパーパラメータの最適化と効率的なモデル構築を実現。結果、初学者でも試行錯誤し、学びを得る機会があったと感じています。
Nishikaコンペの紹介
Nishikaのデータサイエンスコンペに参加しました。
今回はその感想や学びを初学者向けに紹介します。
*私もコードを書き始めてまだ1年未満の初学者ですので、中級者~上級者の方はぜひアドバイスをください。
Nishikaと言えば、日本版Kaggleとよく称されるサイトです。
もともとAIプロダクトやAI人材の事業を取り組んでいる会社。
「私たち”にしか”できない~」と言った意味がある会社ということで、なんだか好印象ですね。
参加したコンペは定期的に開かれている「中古マンション価格予測」
いくつかの説明変数から目的変数に価格を置いた、機械学習ではよくあるテーマで。

感想
まず感想です。
「「「普通にレベルが高い」」」
正直、なめていました。
上位楽勝でしょ~とは思っていないですが、参加人数が少なくて「初学者が挑みやすい場所かな?」と勝手に感じていましたが、ランキング上位の方のスコアが眩しすぎる。
見てくださいこれ。
↓12/3昼時点
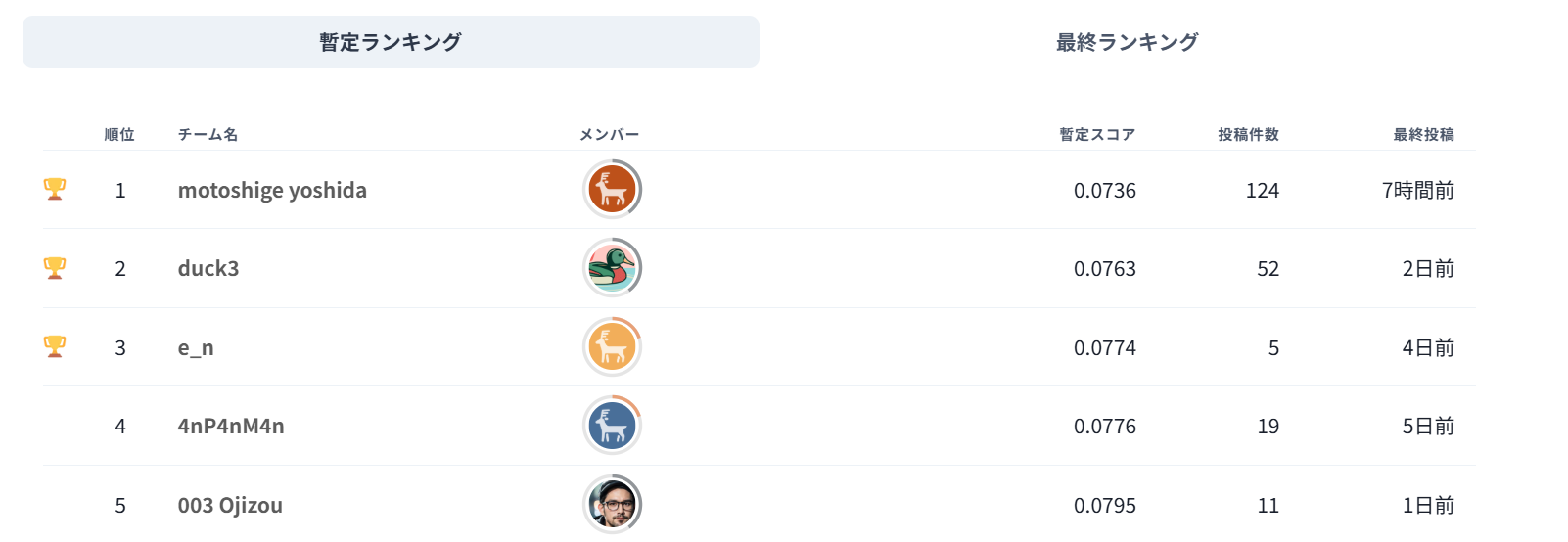
1位の方の熱量がすごく感じられます…。私はここ1~2週間しか開いていないですが、この方ほぼ毎日投稿してスコアを更新し続けておられます。
でも3位の方の「わずか5回の投稿」でここまでこられているのもすごすぎる…。
私個人としては、12/3時点で33位。
一旦今回のコンペ参加の目的は達成したと思っているので、これ以上スコアを上げようとは思っていないのですが、もう無理な気がする…。
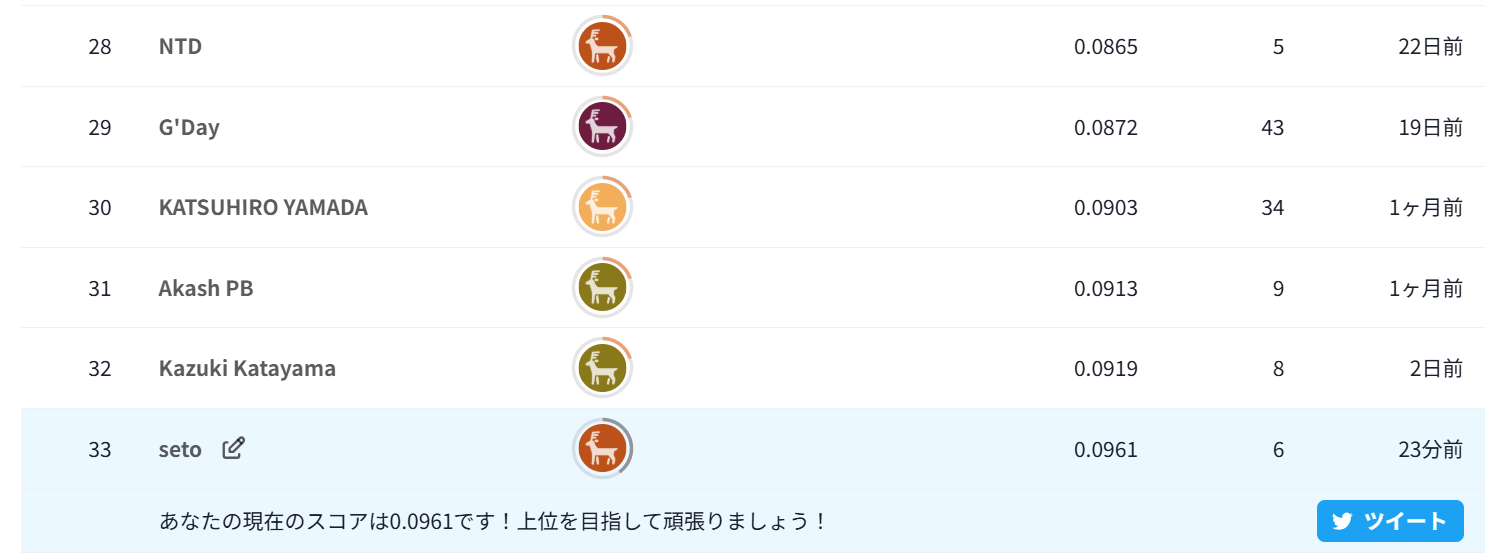
ただまあ、取り組んだ過程は楽しかったです!
言い訳みたいで恥ずかしいが、これでも一応私なりに頑張ったんです(震え声)
↓わずか5回ですが…投稿の度にスコアが上がっていく感覚は嬉しかった。
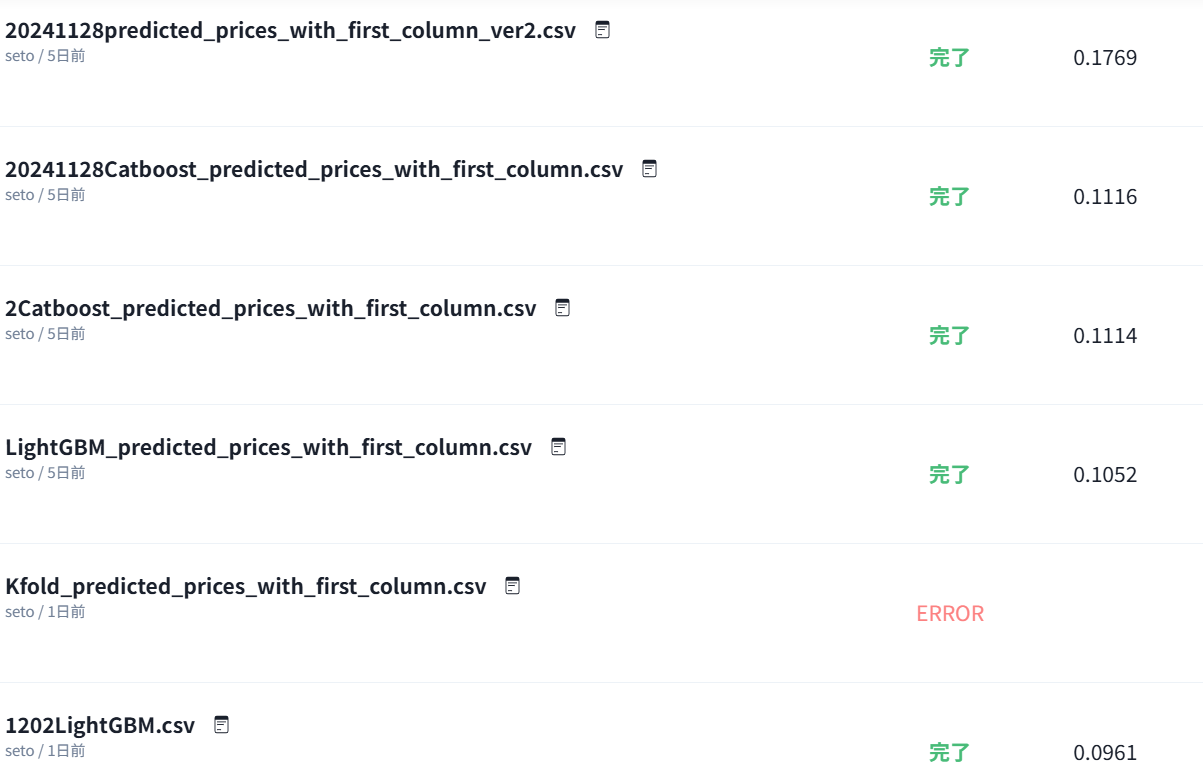
何より1番強く実感したのは、ストレスのなさ。
Nishikaの特徴はなんといっても「Kaggleよりシンプルなユーザーインターフェース」「スムーズな操作性」「日本語!」だと思います。
Kaggleってたまによくわからない操作だったり、データがゴロゴロしてたりあるんですよね…。私の英語力が悪いというのもありますが。
具体的な学び
ここからは具体的に私の学びを伝えていきます。
繰り返しますが、初学者用です。
前処理の重要性
もうこれは言うまでもないと思いますが、まず「データの前処理」はとても重要でとても難しく、かつ工夫のしがいがあるフェーズ。
わかっているつもりでしたが、今回改めて思い知りました。
今回のデータセットで用意されている説明変数は30個程度あるのですが、まあ~データがボロボロ。
まずはここをどれだけ粘り強く取り組めるかで、コンペの土俵に上がれるかが決まります。私はこの前処理フェーズで諦めたことがKaggele上で数回あります…。
似た言葉で「特徴量エンジニアリング」がありますが、ここは一旦度外視。
「特徴量エンジニアリング」はモデルのパフォーマンスを高めるために新しい特徴を作り出したり、既存の特徴を改良したりしますが、
「前処理」はデータを適切な形式に整えることを主眼としています。
前処理がある程度できるようになったら、特徴量エンジニアリングもできるようになるので、初学者のみなさんはまず前処理を一緒に頑張りましょう。
ざっくりいうと以下のアクションが必要です。
- 欠損値の確認
- 外れ値の確認
- データの型の確認
- データ分布の確認
- 上記確認後の対応力
- 粘り強く取り組む姿勢(?)
今回のコンペの説明変数は30個程度ありますが、欠損値ばかりのものもあれば正規分布に従わないものもあれば、「面積」「建築年数」など明らかに価格に強く影響しそうなものがあります。
取り組み始めて1番最初のファイルを提出するまでの工数を100とした場合、私はこの前処理フェーズで80くらいの工数です。それくらいを基準に考えていいのではないかと思います。
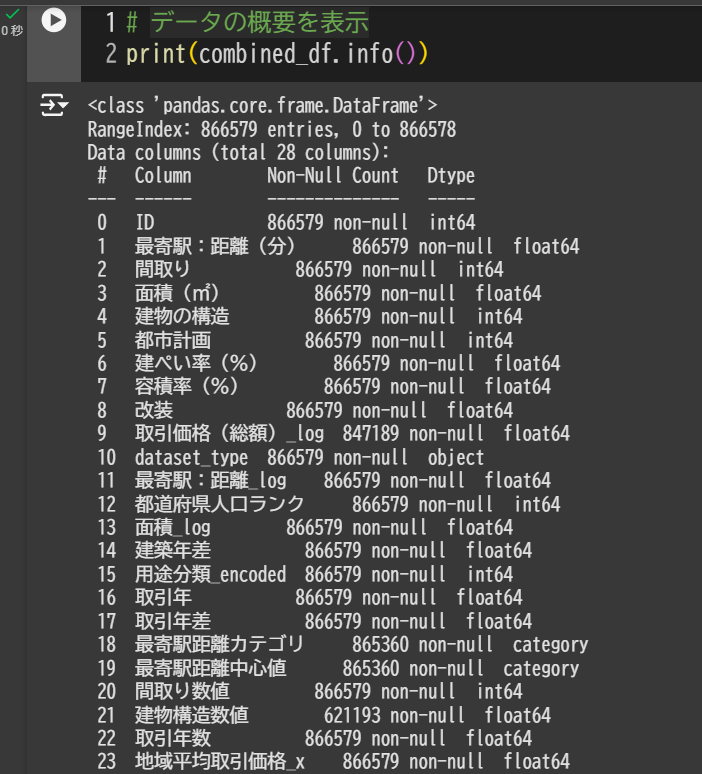
(スクショですみません)
私の提出コードでは削除したり追加したりで最終的に23個の特徴量になりましたが、きっと上位の方々はもっと秀逸な前処理+特徴量エンジニアリングをされているのだと思います。
モデル選定
冒頭で出していますが、私のスコアの向上は主に「モデルの変更」です。
前処理をある程度終えてしまえば、一番手っ取り早くいじれるのはモデル部分なんですね。それにしてもここまで変わるとは思わなかった。
いろんな種類のモデルがあると思いますが、ここで具体的な言及は割愛します。
「どのモデルがいいかわからない…」という方も多いと思いますが、一旦コンペに参加してスコアを出す"だけ"であれば、モデルの具体的なアルゴリズムを知る必要はありません。
CatboostとかLightGBMとか、調べていたら出会ういわゆる「良いモデル」と呼ばれているのものを使ってください。そしてそこからまたいくつかのモデルを試してみてください。ちなみに私が使用しているのはLightGBMです。
パラメータの調整や評価方法の改善などの工夫はそのあとです。
だいたいどんなモデルがあるかはいろいろ見ていくうちにわかってきます。そういう意味で、ほかの方のコードを見たり模写したりするのは大事なんですよね。
最低限知っておいたほうがいいかなと思うのは
機械学習のなかでも「回帰」問題であること、
訓練用データがある「教師あり学習」を使用すること、
以上2つ。
これくらいのことがなんとなくわかっていれば取り組むことができると思います。
生成AIの活用
ChatGPTやClaude,Copilotなど、種類はなんでもいいのですが、
コーディングに生成AIは必ず活用しましょう。
もはやAI無しでするのは効率が悪いです。
特に初学者の方は、いちいち細かな文法やエラー原因を確認してインプットに時間をかけているのであれば、非常にもったいないと思います。
彼らはコーディングが本当に上手なんですよね。
そこにはこちらもある程度の”指示の出し方”が要求されますが、徐々に感覚を掴んでくると思います。
私が今回感じた学びとして、「前提情報を伝えることに時間をかけたほうが、最終的に楽になる」ということです。
例えば、前処理フェーズで欠損値が多い変数を削除したいとき…。
「このカラムの列を削除するPythonコードを教えて」
という指示より、あらかじめ
- 本コンペのテーマと目的
- テーブルの名前とカラム一覧
- 1つ1つのカラムに前処理を行おうとしていること
- モデルは~~~を使用しようと思っていること
- モデルの精度向上を目指していること
などを伝えておくことで、前後の流れが前処理をかけるときもコードをそのままコピペできたりします。
課題
私の課題は明確で「特徴量エンジニアリング」です。
スコアを向上させるために、モデルの試行錯誤、ハイパーパラメータの検討などは実施したのですが、特徴量は最低限度の前処理から大きく変更していません。
ここからさらにモデルを向上するには、もう特徴量をいかに活用できるかだと思っています。
生成AIも使いながらいろいろと試したのですが、なかなか効果的な特徴量を追加できませんでした。ここはやはり人間に考えることなんでしょうか。
例えば、重要な説明変数「面積」「建築年数」を使用して新たな特徴量「面積÷建築年差」を作成するとか、不動産ライブラリや日本統計などから新しい不動産データソースを取り込む、とかでしょうか…。
ここには経験とアイデア力、それを実行に移す環境とコーディング知識が必要だと思います。次のコンペでは、ある程度時間をかける覚悟をもってこうしたことに取り組んでみたいと思っています。
コードモデル部分抜粋
Optunaはハイパーパラメータの最適化を担い、LightGBMは高性能な機械学習モデルの構築を担います。2つを組み合わせることで、LightGBMモデルのパフォーマンスを自動的に最適化し、効率よく高精度なモデルを構築できました。
!pip install optuna
import optuna
from lightgbm import LGBMRegressor
from lightgbm.callback import early_stopping, log_evaluation
from sklearn.metrics import mean_squared_error
# Optuna の目的関数
def objective(trial):
# ハイパーパラメータの範囲指定
param = {
"n_estimators": trial.suggest_int("n_estimators", 100, 1000),
"learning_rate": trial.suggest_float("learning_rate", 0.01, 0.3, log=True),
"num_leaves": trial.suggest_int("num_leaves", 20, 300),
"max_depth": trial.suggest_int("max_depth", 3, 15),
"min_child_samples": trial.suggest_int("min_child_samples", 5, 100),
"subsample": trial.suggest_float("subsample", 0.6, 1.0),
"colsample_bytree": trial.suggest_float("colsample_bytree", 0.6, 1.0),
"reg_alpha": trial.suggest_float("reg_alpha", 1e-8, 10.0, log=True),
"reg_lambda": trial.suggest_float("reg_lambda", 1e-8, 10.0, log=True),
}
# モデル定義
model = LGBMRegressor(**param, random_state=42)
# モデルトレーニング
model.fit(
X_trn, y_trn,
eval_set=[(X_val, y_val)],
eval_metric="rmse",
callbacks=[early_stopping(stopping_rounds=50, verbose=False)],
)
# 検証データでの予測とスコア計算
y_val_pred = model.predict(X_val)
mse = mean_squared_error(y_val, y_val_pred)
return mse
# Optunaによるチューニング
study = optuna.create_study(direction="minimize") # MSEを最小化する方向
study.optimize(objective, n_trials=50) # トライアル回数を指定
# 最適なハイパーパラメータの表示
print("Best parameters:", study.best_params)
print("Best MSE:", study.best_value)
# 最適なパラメータでモデルを再構築
best_params = study.best_params
lgb_model = LGBMRegressor(**best_params, random_state=42)
# トレーニングと早期終了の設定
lgb_model.fit(
X_trn, y_trn,
eval_set=[(X_val, y_val)], # 検証データを指定
eval_metric="rmse", # 評価指標
callbacks=[
early_stopping(stopping_rounds=50, verbose=True), # 早期終了
log_evaluation(period=10) # 10ラウンドごとにログを出力
]
)
# テストデータでの予測
y_pred = lgb_model.predict(X_test)
# テストデータの予測結果を評価
print("Final MSE on validation set:", mean_squared_error(y_val, lgb_model.predict(X_val)))