「ROC曲線とPR曲線、なんとなく見てるけど、正直違いがよく分からない…」
そんな経験、ありませんか?
機械学習モデルの評価方法として広く使われているPR曲線(Precision-Recall曲線)とROC曲線(Receiver Operating Characteristic曲線)。
一見似ていますが、目的や前提条件によって“使うべき曲線”は大きく変わってきます。
この記事では、
- ROC曲線とPR曲線の仕組みと違い
- クラス不均衡なデータでどちらが適切か
- 実務での使い分け方
を、図解と具体例を交えてわかりやすく解説します。
1. 基本概念:混同行列を理解する
PR曲線とROC曲線を理解するためには、まず混同行列(Confusion Matrix)の基本概念を押さえる必要があります。
混合行列は、分類モデルの予測結果と正解の関係 を整理するための表です。
特に 二値分類 のときによく使われます。
| 予測:陽性 | 予測:陰性 | |
|---|---|---|
| 実際:陽性 | 真陽性(TP) | 偽陰性(FN) |
| 実際:陰性 | 偽陽性(FP) | 真陰性(TN) |
これらの値から、以下の指標が計算できます.
- 適合率(Precision):TP / (TP + FP) - 陽性と予測したもののうち、実際に陽性だった割合
- 再現率(Recall):TP / (TP + FN) - 実際に陽性のもののうち、陽性と予測できた割合
- 特異度(Specificity):TN / (TN + FP) - 実際に陰性のもののうち、陰性と予測できた割合
- 偽陽性率(FPR):FP / (FP + TN) = 1 - 特異度 - 実際は陰性なのに陽性と予測した割合
具体例:がん検診のケース
例として、「がんの有無」を分類するモデルを考えましょう。
- Positive(陽性):がんがある
- Negative(陰性):がんがない
そして、100人の検査結果のうち、以下のような分類がされたとします:
| 予測:がんあり | 予測:がんなし | |
|---|---|---|
| 実際:がんあり(10人) | 8人(TP) | 2人(FN) |
| 実際:がんなし(90人) | 5人(FP) | 85人(TN) |
💡それぞれの意味は?
-
TP(True Positive)=8人
→ 本当にがんがある人を「がんあり」と正しく予測できた。 -
FN(False Negative)=2人
→ 実はがんがあるのに、「がんなし」と誤判定してしまった(←一番怖い)。 -
FP(False Positive)=5人
→ 実はがんがないのに、「がんあり」と誤判定してしまった(←再検査が必要)。 -
TN(True Negative)=85人
→ 本当にがんがない人を「がんなし」と正しく予測できた。
2. PR曲線とROC曲線の特徴
PR曲線(Precision-Recall Curve)
PR曲線は次の2軸を用います。
- x軸:適合率(Precision = TP / (TP + FP))
- y軸:再現率(Recall = TP / (TP + FN))
こちらは、陽性クラスに特化した性能評価を行う指標です。
再現率を高めると精度が下がりやすいなど、2つの指標はトレードオフの関係にあります。
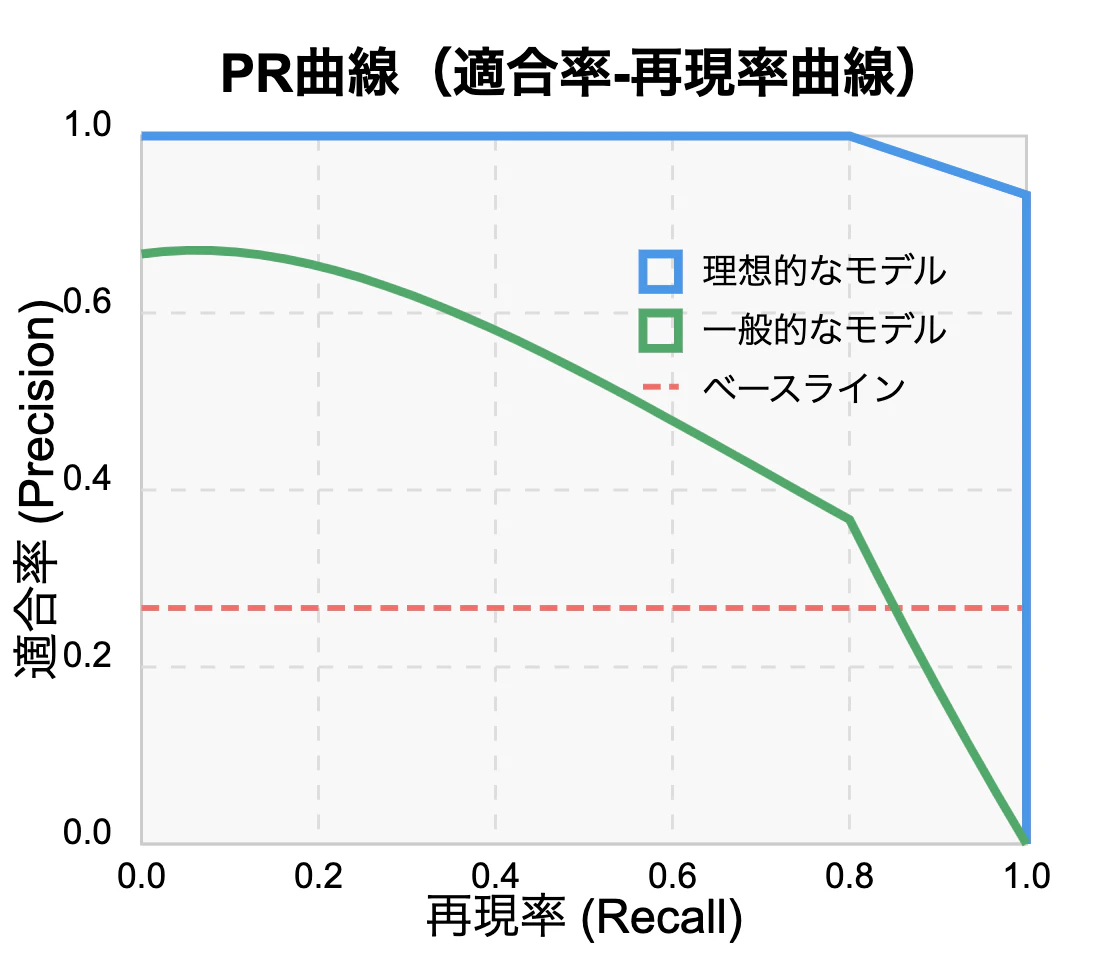
特徴:
- 適合率と再現率はトレードオフの関係にあります
- 曲線の下の面積が大きいほど、モデルの性能が高いことを示します(AUC-PR)
- 理想的なモデルは右上のコーナー(Precision=1, Recall=1)に近づきます
- データの不均衡に敏感:陽性クラスの割合が低い場合(不均衡データ)でも性能の違いを明確に表示できます
例えるなら:
「針の穴を見つける名探偵。希少な事象をどれだけ見逃さずに、かつ正確に当てられるかを評価する。不均衡データセットでの実力が光る。」
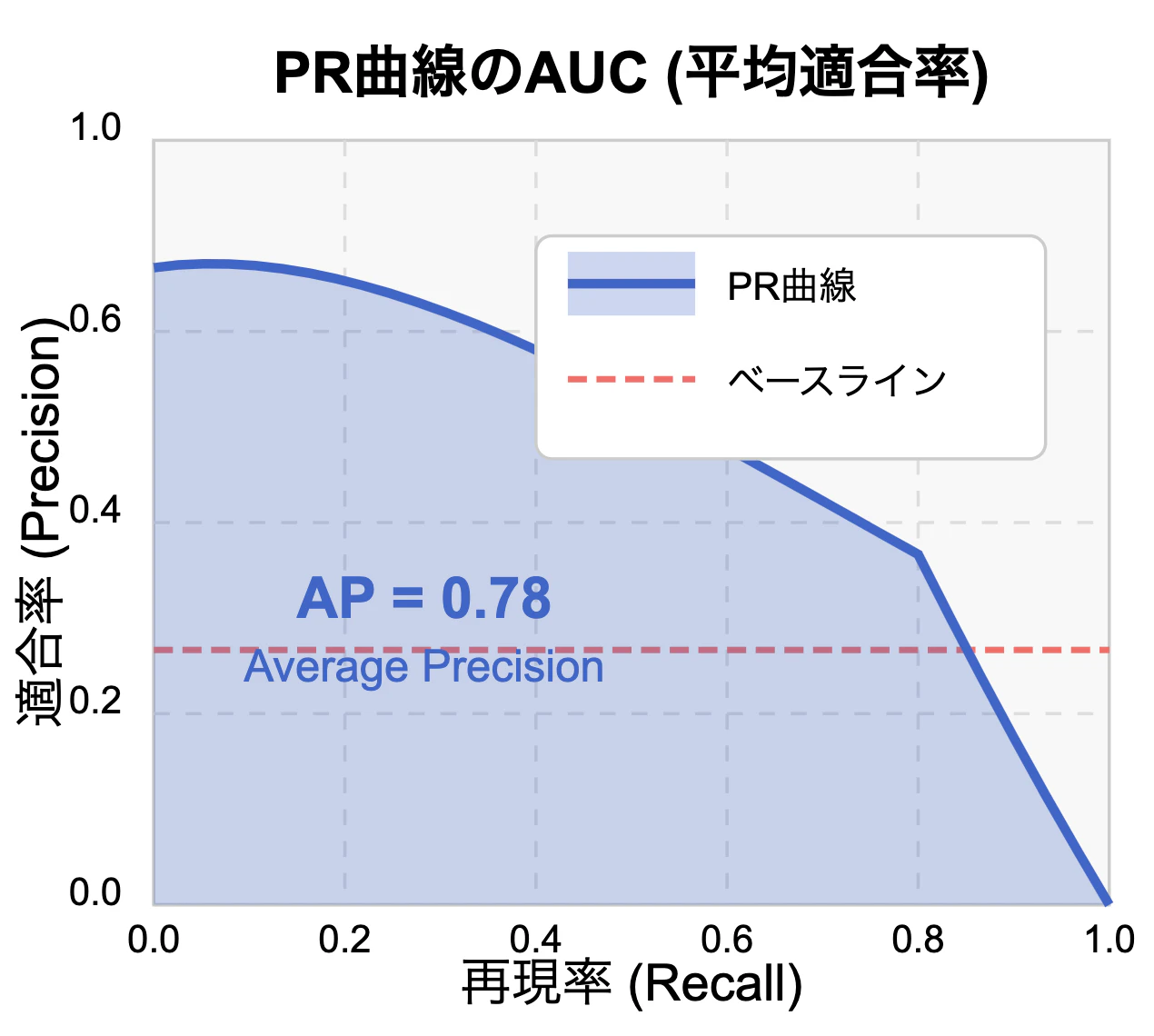
💡 AUC-PRとは?
PR曲線の面積(AUC-PR)は、陽性クラスに対してどれだけ有効に検出できたかを評価します。
特に陽性の割合が少ない(クラス不均衡な)データでは、AUC-ROCよりAUC-PRの方が信頼できることが多いです。
ROC曲線(Receiver Operating Characteristic Curve)
ROC曲線は、以下の2軸を使ってモデルの性能を可視化するグラフです。
- x軸:偽陽性率(FPR = False Positives / Total Negatives)
- y軸:真陽性率(TPR = True Positives / Total Positives)
FPRが低く、TPRが高いほど理想的なモデル。
つまり、グラフが左上に近いほど高性能ということになります。
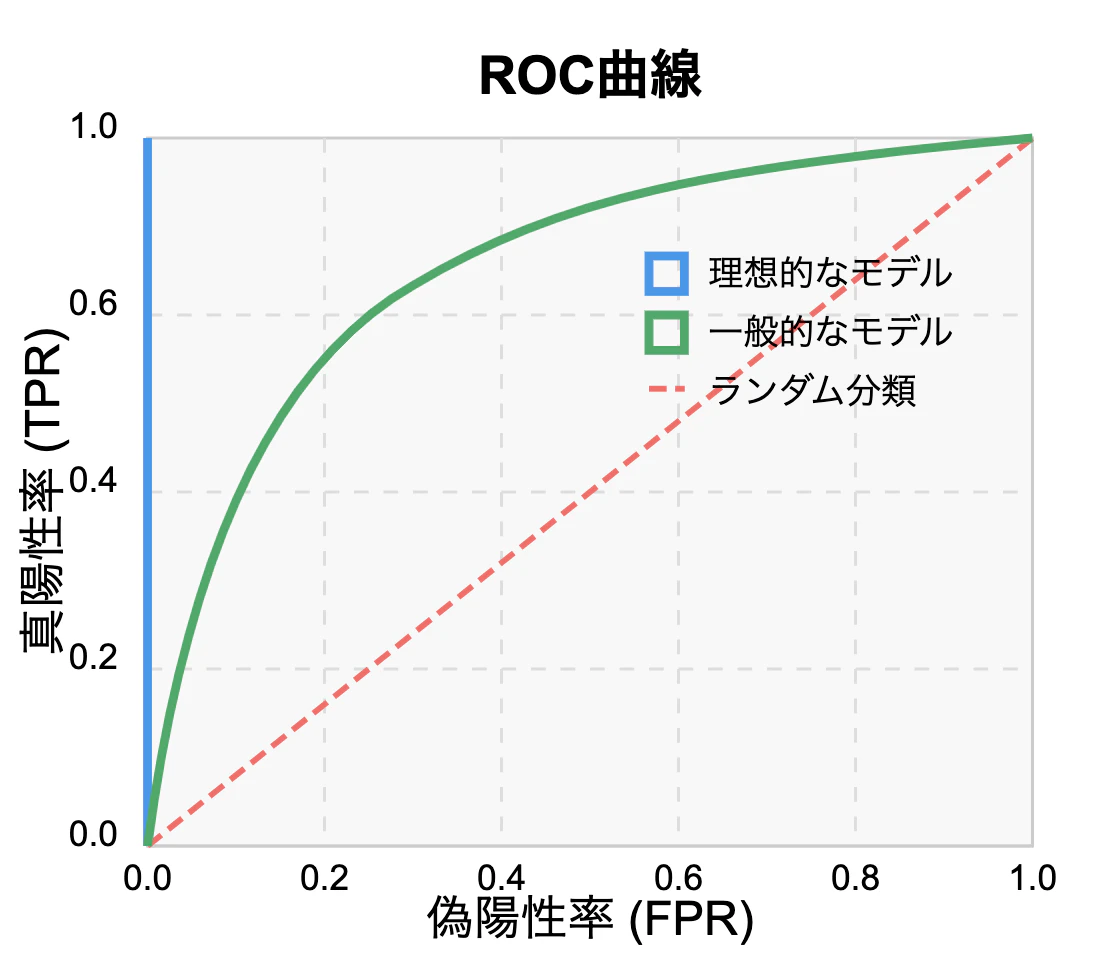
特徴:
- 様々な閾値における真陽性率と偽陽性率のトレードオフを示します
- 曲線の下の面積(AUC-ROC)が大きいほど、モデルの性能が高いことを示します
- 理想的なモデルは左上のコーナー(FPR=0, TPR=1)に近づきます
- データの不均衡の影響を受けにくい:クラス分布が変わっても比較的安定した評価が可能です
例えるなら:
「バランス感覚に優れたジャッジ。両方のクラスを公平に扱い、様々なデータセットでも安定した評価を下す。モデル比較の万能選手。」
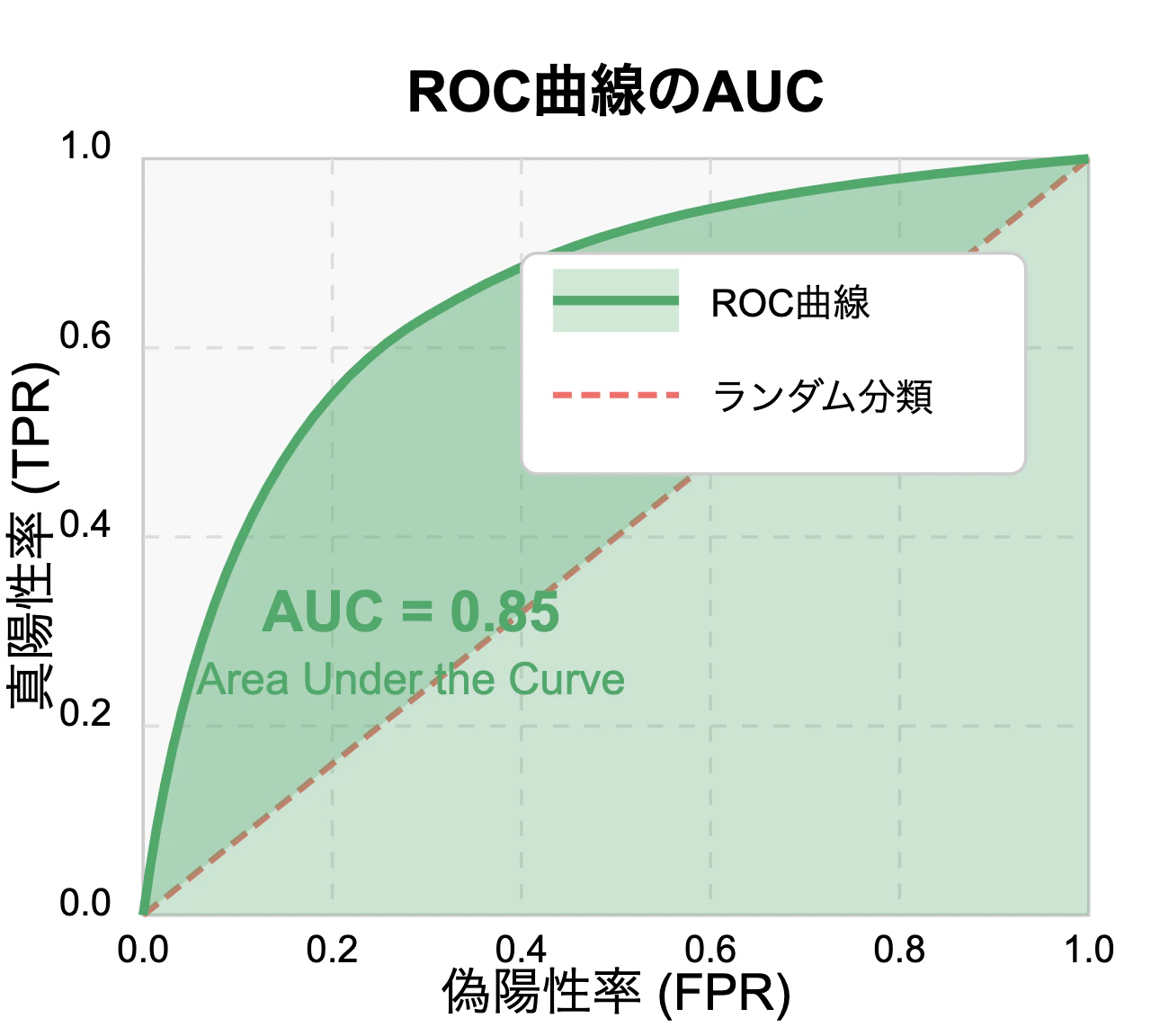
AUC-ROCとは?
ROC曲線の下の面積(AUC = Area Under the Curve)は、ランダムに選んだ陽性と陰性を正しく順位づけできる確率と解釈できます。
値が1に近いほど性能が良く、0.5であれば完全なランダムと同等です。
3. 覚え方のコツ
💡PR曲線を覚えるコツ
- 「PP-RR」:Precision-Precision, Recall-Recall で覚える(縦軸が適合率P、横軸が再現率R)
- 「正確さと網羅性のバランス」 として覚える:正確に当てる(Precision)か、漏れなく拾う(Recall)か
- 「不均衡データの探知機」:クラス不均衡データの評価ならPR曲線が敏感に反応
💡ROC曲線を覚えるコツ
- 「真と偽の率」:縦軸が真陽性率(TPR)、横軸が偽陽性率(FPR)
- 「対角線基準」:対角線(y=x)より上にあればランダムより良い
- 「左上を目指せ!」:左上コーナー(偽陽性ゼロで真陽性最大)が理想形
PR曲線 vs ROC曲線 比較一覧
| 観点 | PR曲線(Precision-Recall曲線) | ROC曲線(Receiver Operating Characteristic曲線) |
|---|---|---|
| フォーカス対象 | 陽性クラスの検出性能 | 全体の識別能力 |
| x軸 | 適合率(Precision) | 偽陽性率(FPR) |
| y軸 | 再現率(Recall) | 真陽性率(TPR) |
| クラス不均衡への強さ | 不均衡データに強く、性能の変化を繊細に捉える | 不均衡データでは過大評価されやすい |
| ベースライン | 陽性クラスの割合(データにより変動) | 常に一定(FPR = TPR で0.5の対角線) |
| AUCの意味 | 陽性検出の精度と網羅率のバランス(F1スコアに近い) | 陽性と陰性の順位づけ性能を示す |
| 関心の対象 | 陽性クラスに特化した評価 | 陰性・陽性の両方を考慮 |
| 代表的ユースケース | 詐欺検出、希少疾患診断、異常検知などの不均衡問題 | モデル比較、全体的な分類性能評価 |
4. ユースケース:いつどちらを使うべきか
PR曲線が適しているケース
- 高度に不均衡なデータセット:陽性例が非常に少ない場合(詐欺検出、希少疾患の診断など)
- 偽陽性よりも偽陰性が重大な問題になるケース:がん検診など見逃しが致命的な場合
- 陽性クラスに関心がある場合:陰性クラスの正確な予測にあまり関心がない場合
例:
- クレジットカード詐欺検出(詐欺取引は全取引の0.1%未満)
- 希少疾患の診断(患者は人口の極一部)
- スパムフィルタリング(スパムでないメールの見逃しが重要)
ROC曲線が適しているケース
- 比較的バランスの取れたデータセット:陽性と陰性の割合が近い場合
- 偽陽性と偽陰性のバランスを評価したい場合
- モデル間の一般的な比較:異なるアルゴリズムやハイパーパラメータの選択
例:
- 性別分類(比較的均等)
- 顧客のチャーン予測(離脱率が適度にある場合)
- 多くの医療診断(病気の有病率が適度にある場合)
選択指針
- 極端な不均衡がある? → PR曲線を選択
- 総合的な性能比較がしたい? → ROC曲線を選択
- 完璧を期すなら両方を使う:両方の曲線を計算して、より完全な評価を行う
5. Pythonによる実装
必要なライブラリ
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_recall_curve, roc_curve, auc, average_precision_score, roc_auc_score
データの準備
# サンプルデータの生成(バランスの取れたデータセット)
X_balanced, y_balanced = make_classification(n_samples=1000, n_classes=2, weights=[0.5, 0.5],
random_state=42)
# サンプルデータの生成(不均衡データセット)
X_imbalanced, y_imbalanced = make_classification(n_samples=1000, n_classes=2, weights=[0.95, 0.05],
random_state=42)
# データの分割
X_bal_train, X_bal_test, y_bal_train, y_bal_test = train_test_split(X_balanced, y_balanced,
test_size=0.3, random_state=42)
X_imb_train, X_imb_test, y_imb_train, y_imb_test = train_test_split(X_imbalanced, y_imbalanced,
test_size=0.3, random_state=42)
モデルのトレーニングと予測
# バランスデータでのモデル
model_balanced = LogisticRegression()
model_balanced.fit(X_bal_train, y_bal_train)
y_bal_pred_proba = model_balanced.predict_proba(X_bal_test)[:, 1]
# 不均衡データでのモデル
model_imbalanced = LogisticRegression()
model_imbalanced.fit(X_imb_train, y_imb_train)
y_imb_pred_proba = model_imbalanced.predict_proba(X_imb_test)[:, 1]
PR曲線の描画
def plot_pr_curve(y_true, y_score, title):
precision, recall, _ = precision_recall_curve(y_true, y_score)
average_precision = average_precision_score(y_true, y_score)
plt.figure(figsize=(8, 6))
plt.step(recall, precision, where='post', color='blue', alpha=0.8, linewidth=2)
plt.fill_between(recall, precision, alpha=0.2, color='blue')
# ベースラインの追加(陽性クラスの割合)
baseline = np.sum(y_true) / len(y_true)
plt.axhline(y=baseline, color='red', linestyle='--', label=f'ベースライン: {baseline:.3f}')
plt.xlabel('再現率 (Recall)')
plt.ylabel('適合率 (Precision)')
plt.title(f'{title} - PR曲線 (AP: {average_precision:.3f})')
plt.legend(loc='best')
plt.grid(True, linestyle='--', alpha=0.7)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.show()
# バランスと不均衡データセットでのPR曲線
plot_pr_curve(y_bal_test, y_bal_pred_proba, "バランスデータ")
plot_pr_curve(y_imb_test, y_imb_pred_proba, "不均衡データ")
ROC曲線の描画
def plot_roc_curve(y_true, y_score, title):
fpr, tpr, _ = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', alpha=0.8, linewidth=2,
label=f'ROC曲線 (AUC = {roc_auc:.3f})')
# ランダム予測のベースライン
plt.plot([0, 1], [0, 1], color='red', linestyle='--', label='ランダム予測 (AUC = 0.5)')
plt.xlabel('偽陽性率 (False Positive Rate)')
plt.ylabel('真陽性率 (True Positive Rate)')
plt.title(f'{title} - ROC曲線')
plt.legend(loc='best')
plt.grid(True, linestyle='--', alpha=0.7)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.show()
# バランスと不均衡データセットでのROC曲線
plot_roc_curve(y_bal_test, y_bal_pred_proba, "バランスデータ")
plot_roc_curve(y_imb_test, y_imb_pred_proba, "不均衡データ")
両方の曲線を並べて表示する関数
def compare_pr_roc(y_true, y_score, title):
# PR曲線の計算
precision, recall, _ = precision_recall_curve(y_true, y_score)
avg_precision = average_precision_score(y_true, y_score)
# ROC曲線の計算
fpr, tpr, _ = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr)
# プロット
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# PR曲線
ax1.step(recall, precision, where='post', color='blue', alpha=0.8, linewidth=2)
ax1.fill_between(recall, precision, alpha=0.2, color='blue')
baseline = np.sum(y_true) / len(y_true)
ax1.axhline(y=baseline, color='red', linestyle='--', label=f'ベースライン: {baseline:.3f}')
ax1.set_xlabel('再現率 (Recall)')
ax1.set_ylabel('適合率 (Precision)')
ax1.set_title(f'PR曲線 (AP: {avg_precision:.3f})')
ax1.legend(loc='best')
ax1.grid(True, linestyle='--', alpha=0.7)
ax1.set_xlim([0.0, 1.0])
ax1.set_ylim([0.0, 1.05])
# ROC曲線
ax2.plot(fpr, tpr, color='blue', alpha=0.8, linewidth=2,
label=f'ROC曲線 (AUC = {roc_auc:.3f})')
ax2.plot([0, 1], [0, 1], color='red', linestyle='--', label='ランダム予測')
ax2.set_xlabel('偽陽性率 (False Positive Rate)')
ax2.set_ylabel('真陽性率 (True Positive Rate)')
ax2.set_title('ROC曲線')
ax2.legend(loc='best')
ax2.grid(True, linestyle='--', alpha=0.7)
ax2.set_xlim([0.0, 1.0])
ax2.set_ylim([0.0, 1.05])
plt.suptitle(title, fontsize=16)
plt.tight_layout()
plt.show()
## 両方の曲線を比較表示
compare_pr_roc(y_bal_test, y_bal_pred_proba, "バランスデータでの比較")
compare_pr_roc(y_imb_test, y_imb_pred_proba, "不均衡データでの比較")
実際の出力イメージ
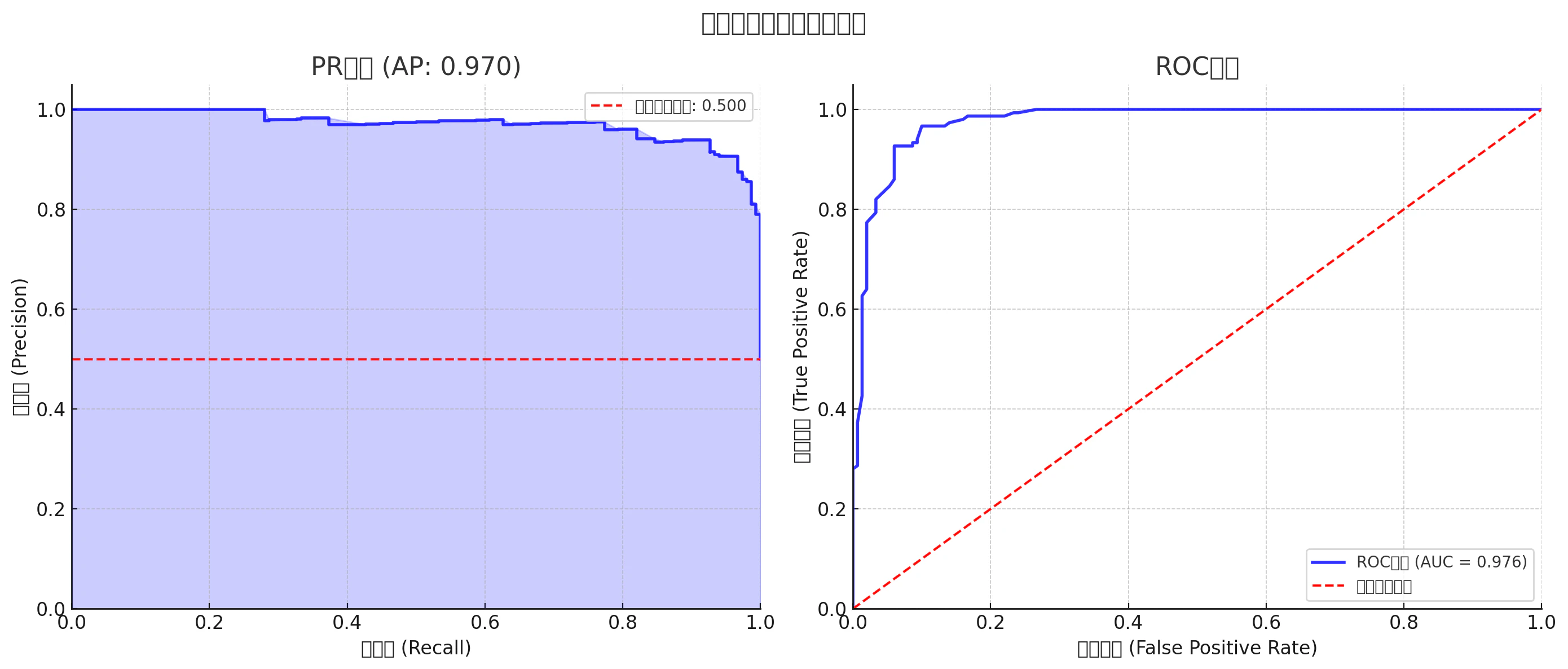
バランスの取れたデータ (クラス0:50%、クラス1:50%)
- ROC曲線もPR曲線もスムーズで、両方ともモデルの性能を良く評価できます。
- PR曲線のベースラインは0.5(陽性率が50%なので)で、モデルの性能がこのラインを大きく上回っている。
不均衡データの場合(クラス0:90%、クラス1:10%)
- ROC曲線は依然としてAUCが高く見え、「良いモデル」と誤解されやすい。
- PR曲線では、ベースラインが0.1(陽性率が10%)であり、それを超えていない場合は「実はダメなモデル」ということが分かる。
- PR曲線は陽性クラスの検出能力を強調しているため、不均衡データではPR曲線の方が適切な指標となる。
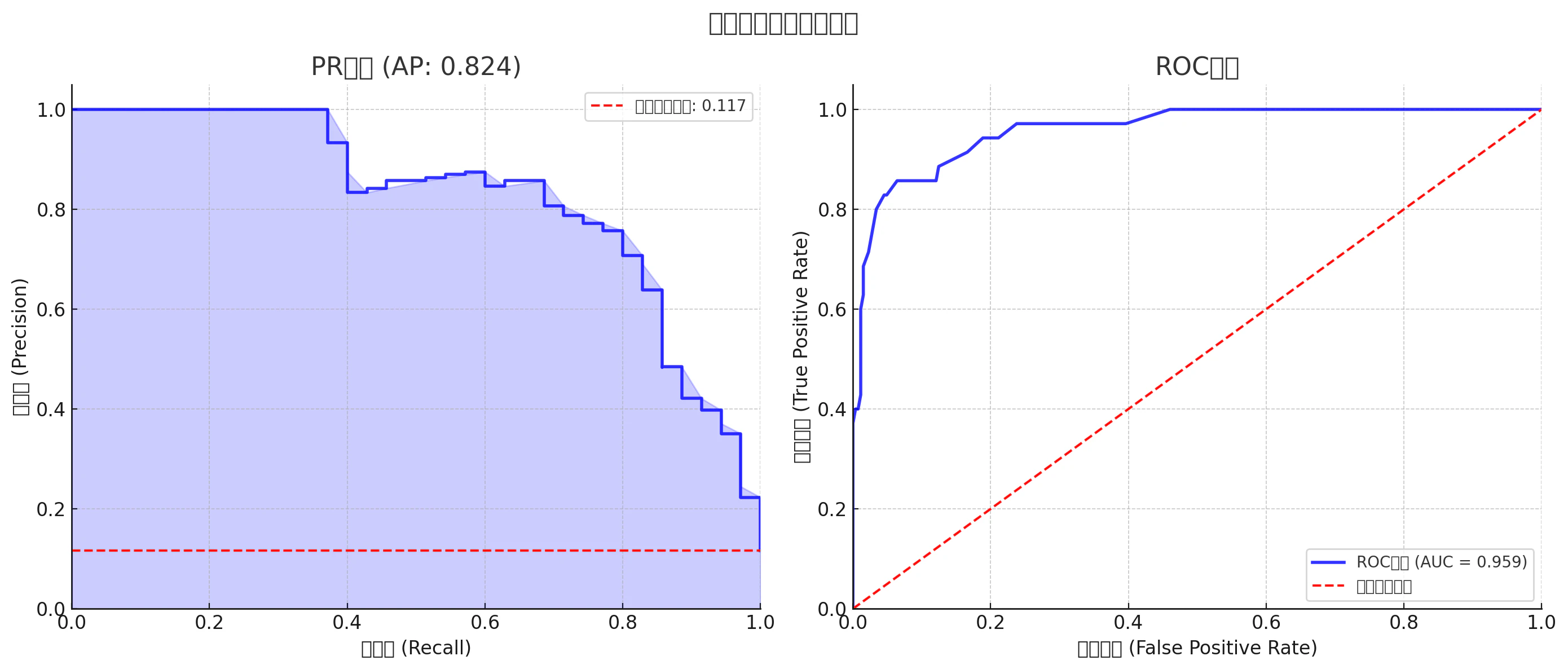
💡図から読み取れること
- ROC曲線は不均衡データでも高AUCを示すが、これは誤解を招く可能性あり
- PR曲線は陽性クラスの取りこぼしや無駄打ちの少なさを反映するため、不均衡データにおいてはPR曲線の方が正確
- どちらの曲線も比較することで、モデルの「見せかけ」ではなく本質的な性能が見える
6. まとめ:評価指標の選び方ひとつでモデルの見え方が変わる
機械学習モデルの性能は、どの評価指標を使うかによって印象が大きく変わります。
指標の選び方ひとつで、「優秀に見えるモデル」が「実は微妙なモデル」だった、なんてことも。
だからこそ大切なのは、目的に合った評価指標を選ぶこと。
それによって、モデルの「本当の実力」を正しく見極めることができます。
✅ ROC曲線:全体の識別能力をざっくり把握したいときに最適
✅ PR曲線:陽性クラス(例:詐欺、疾患など)に注目した精密な評価がしたいときに最適
状況に応じてうまく使い分けることで、信頼できるAIモデルの構築につながります。