Python in Excel とは
Excel in Pythonとは…言葉の通り「Excelの中でPythonが使えるようになった」という機能です。
Python in Excelでは、Pythonのライブラリーを用いて、数値計算や統計分析、データの可視化などがExcel上で可能になります。
2023年8月にパブリックプレビュー版がリリースされ、2024年9月に正式提供が開始されました。昨年から使われている方は新機能でもないですね。
↑上記MicrosoftのHPより。Excelの数式タブにPythonマークが表示されています。
通常のExcel・Pythonとの違い
この新機能、一見
「え、どこが新機能なの???」
と思う方も一定いらっしゃるかと思います。
というのも、Excel(csv)をPythonライブラリに読み込ませてグラフを作成したり機械学習を使用したり…というのはこれまでも実践できていたので、
「その関係性が入れ替わっただけ?」
「機能的に何か新しくは見えない…。」
という印象は別に間違っていないのですよね。
実際に触ってみて、確かにその通りだなと。
私が感じたPiEの1番のメリットは「機械学習のハードルが下がった」という点です。
- 現存のExcelデータからアプリ移行することなく、コード実装できる気軽さ
- 別途データの読み込みが不要、前処理も楽になる(かも)という点
- Cloud上の実行になるので、チーム開発(と呼べるものでもない)が実践できる点
など、機械学習が簡単にExcel内で実践できるようになりました。これはまあまあ便利かなと。
ただ一方で、グラフ作成や簡単な四則演算、平均・偏差値などの算出は、現状のExcel機能で十分な印象です。
そのため、Python in Excel の使用を検討している方は、Excelアプリ内で"機械学習を使用できる"という点をメインでみていただいた方がいいかな〜と感じました。
さっそく機械学習を実践してみた。
機械学習のサンプルとしてよく使われるアヤメのデータセットでお試ししてみます。
事前準備
まずアヤメのデータセットダウンロードはこちらから。
- データ件数
- 150 *3種類のアヤメそれぞれ50ずつ
- 特徴量
- ガクの長さ(sepal length)
- ガクの幅(sepal width)
- 花弁の長さ(Petal length)
- 花弁の幅(petal width)
- 目的変数
- 『花の種類(species)』
- setosa
- versicolor
- virginic
- 『花の種類(species)』
- 学習用:検証用
- それぞれのアヤメの種類で4:1の割合になるよう事前に分割済み
- つまり学習用が120、検証用が30のデータ件数
せっかくのExcelなので、わかりやすいようにシートで分割します。
以下が学習用(train)シート。

以下が検証用(test)シート。
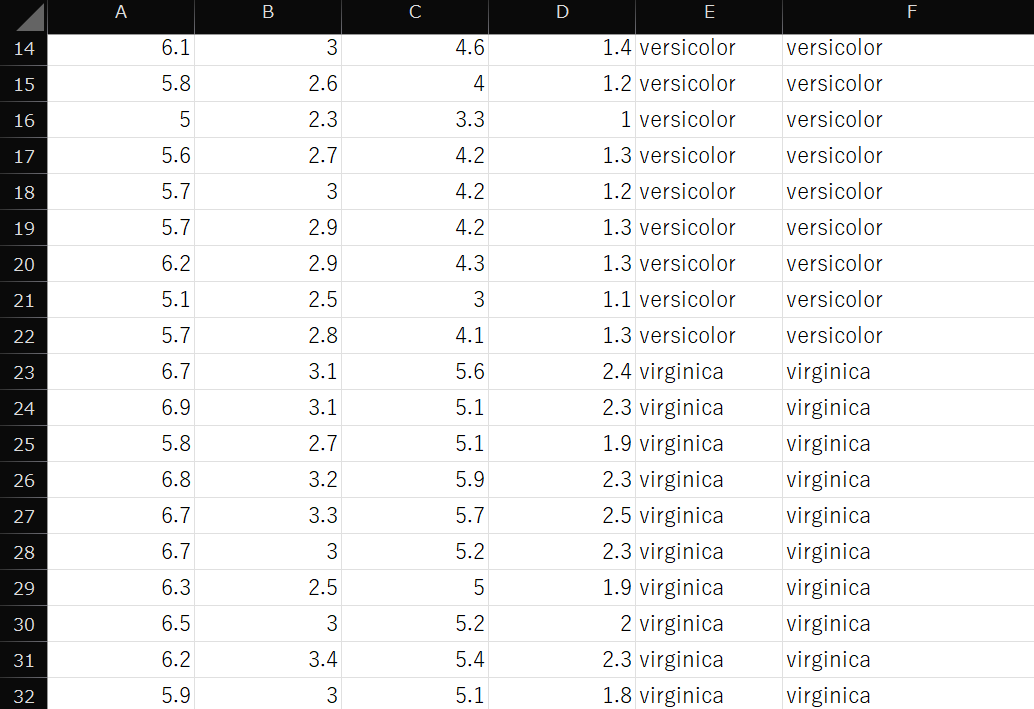
F列「予測」にPythonの機械学習による予測結果を入力していきます。

Pythonの実行コード
testシートのE1セルにPythonを挿入していきます。

以下、コードです。
学習モデルには簡易的なランダムフォレストを使用します。
from sklearn.ensemble import RandomForestClassifier
import pandas as pd #不要かも
# データを取得
df = xl("train!A1:E120", headers=True)
# 特徴量と目的変数を定義
X = df[["sepal_length", "sepal_width", "petal_length", "petal_width"]]
y = df["species"]
# モデルの作成と学習
clf = RandomForestClassifier()
clf.fit(X, y)
# テストデータを取得
test_X = xl("test!A1:D32",headers=True)
# 予測
predictions = clf.predict(test_X)
predictions
出力結果
以上の結果、下記のような出力になるのではないかと思います。

デフォルトでは、セルにそのまま出力してくれないようなので、
「PY」の文字の左にある「Python出力」から「Excelの値」を選択しましょう。

以下のようにそれぞれの予測結果がセルに挿入されています。
アヤメのデータセットは、人間の直観でもなんとなく3種を区別できる程度の簡単な情報です。そのため、今回の機械学習の精度も100%となりました。

今後の可能性
冒頭でもお伝えしたようにPiEのメリットは、「諸々手間が少ない!」ということです。
Pythonのさらに高度な機能・複雑な機械学習は、Excel上ではなく整備された開発環境がいいのは間違いありません。ただ、使うかどうか気づくかどうかはさておき、PythonがExcelに組み込まれたことで、多くの人々にとってPython機械学習機能が身近なものになったはずです。
「あれ、こんなマーク前からあったっけ?」
↓
「ExcelでPythonができるのか!でも過去にデータ読み込みが上手くいかなくて挫折したんだよな…」
↓
「せっかくすぐできそうだしちょっと調べてみるか」
(このQiita投稿にたどりつく)
↓
「お!コードコピペで実行できる!しかもデータ読み込みもなしで手軽にできるやん!」
…みたいな話がどこかで起きていれば嬉しいなと思います。
もちろん実際の生のデータで行おうとすると、欠損地やエラー処理など、前処理が必須でしょう。ただ「Python上で前処理はできない(コードを知らない)が、普段から慣れているExcelだと前処理もできる!」なんて方は結構多いのではないでしょうか?
もしかしたら置換操作や単位・小数点の統一など、Excel内だからこそ簡単にできることもあるかもしれません。
一番厄介なのは、企業所有のPCだとバージョンやセキュリティの関係でそもそもPiEが使えないという事態でしょうね。これはあるあるかと思います。頑張って会社にかけあうしかありませんね。