TL;DR
Databricksを使いこなすには課金必須!
はじめに
KaggleやSIGNATEのデータ分析コンペに参加していると、モデル開発の過程でデータの処理やモデルのパラメータの調整、トレーニングデータのサイズ調整など、多くの実験を繰り返すので、それらを追跡・管理することが重要になります。
そんな中で、Databricksのエクスペリメント機能は、これらの実験を効率的に管理し、最適なモデルを見つけるためのMLOpsツールとなります。
今回は、Databricksとそのエクスペリメント機能について、初めて触れる方にもわかりやすく解説します。
Databricksとは?
Databricksは、「ビッグデータ処理と機械学習のためのクラウドベースの統合プラットフォーム」 です。Apache Sparkをベースにしており、データの処理からモデルの構築、デプロイまでをシームレスに行うことができます。
特徴的なのは以下の点です。
- 統合環境: データエンジニアリング、データサイエンス、機械学習の作業を一つのプラットフォームで行える
- スケーラビリティ: 大規模なデータセットも効率的に処理可能
- コラボレーション: チームでのデータ分析・モデル開発を促進
- MLflow統合: 機械学習の実験管理とモデルのライフサイクル管理をサポート
MLflowとエクスペリメント機能
Databricksの強みの一つが、「MLflowとの統合」 です。
MLflowは機械学習のライフサイクル全体を管理するためのオープンソースプラットフォームで、以下の機能があります。
- 実験の追跡(Tracking): モデルの学習過程やパラメータ、メトリクスを記録
- プロジェクト(Projects): 再現可能なコードを共有
- モデル(Models): モデルの管理と異なる環境へのデプロイ
- モデルレジストリ(Model Registry): モデルのバージョン管理とデプロイワークフロー
今回は特に実験の追跡に焦点を当てて説明します。
実践:エクスペリメント機能を使ってみよう
それでは、具体的なコード例を見ながら、Databricksのエクスペリメント機能がどのように役立つのか見ていきましょう。
前提条件
- Databricksアカウントとワークスペースへのアクセス
- 基本的なPythonとデータサイエンスの知識
サンプルコードの解説
以下のサンプルコードは、2つの異なるモデル(線形回帰とランダムフォレスト)を使用して、異なるトレーニングデータのサイズや特徴量の組み合わせによる性能の違いを比較しています。
ダミーデータのため、かなりシンプルなものです。
import numpy as np
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# ダミーデータ作成
np.random.seed(42)
X = np.random.rand(100, 2) * 10 # 2列の特徴量
df = pd.DataFrame(X, columns=["feature1", "feature2"])
y = 3 * df["feature1"] + 2 * df["feature2"] + np.random.randn(100) * 2 # ノイズを加えた線形データ
# 比較用のパターン
experiments = [
{"model": LinearRegression(), "train_size": 0.8, "features": ["feature1"], "run_name": "LinearRegression_Train80_Feature1"},
{"model": LinearRegression(), "train_size": 0.5, "features": ["feature1"], "run_name": "LinearRegression_Train50_Feature1"},
{"model": RandomForestRegressor(n_estimators=50), "train_size": 0.8, "features": ["feature1"], "run_name": "RandomForest_Train80_Feature1"},
{"model": RandomForestRegressor(n_estimators=50), "train_size": 0.8, "features": ["feature1", "feature2"], "run_name": "RandomForest_Train80_Feature1+2"}
]
for exp in experiments:
# 特徴量を選択
X_selected = df[exp["features"]]
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size=1-exp["train_size"], random_state=42)
with mlflow.start_run(run_name=exp["run_name"]): # run_nameを指定
model = exp["model"]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
# MLflow に記録
mlflow.log_param("model_type", type(model).__name__)
mlflow.log_param("train_size", exp["train_size"])
mlflow.log_param("features", ", ".join(exp["features"]))
mlflow.log_metric("mse", mse)
# モデルを記録
mlflow.sklearn.log_model(model, "model")
print(f"Model: {type(model).__name__}, Train Size: {exp['train_size']}, Features: {exp['features']}, MSE: {mse}")
コードの重要なポイント
- 実験の定義: 異なるモデル、トレーニングサイズ、特徴量の組み合わせを辞書のリストとして定義
-
MLflow実行:
mlflow.start_run()で各実験を開始 -
パラメータのロギング:
mlflow.log_param()でモデルタイプ、トレーニングサイズ、使用した特徴量を記録 -
メトリクスのロギング:
mlflow.log_metric()で平均二乗誤差(MSE)を記録 -
モデルの保存:
mlflow.sklearn.log_model()でモデル自体を保存
Databricksのエクスペリメント機能の利点
Databricksのエクスペリメント機能(MLflow Tracking)を使用することで、以下のような利点があります:
1. 実験の可視化と比較
Databricksの実験UIでは、複数の実験結果を一覧表示し、パラメータやメトリクスを比較することができます。上記のサンプルコードでは、4つの異なる実験を行いましたが、それらの結果を以下のように比較できます。
- 線形回帰とランダムフォレストのMSEの違い
- トレーニングデータサイズの影響(0.8 vs 0.5)
- 特徴量の数の影響(feature1のみ vs feature1+feature2)
以下、実際の画面です。
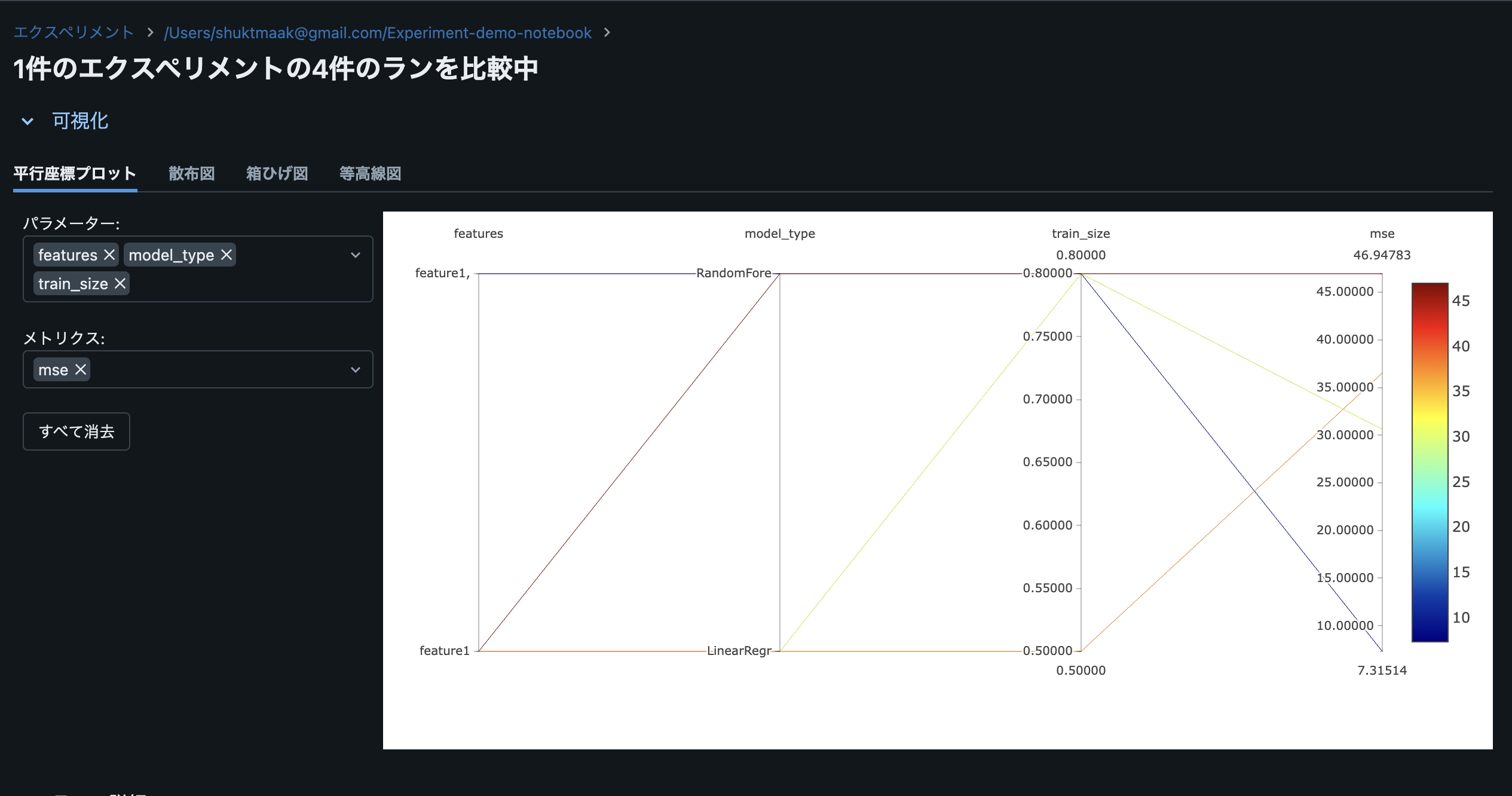
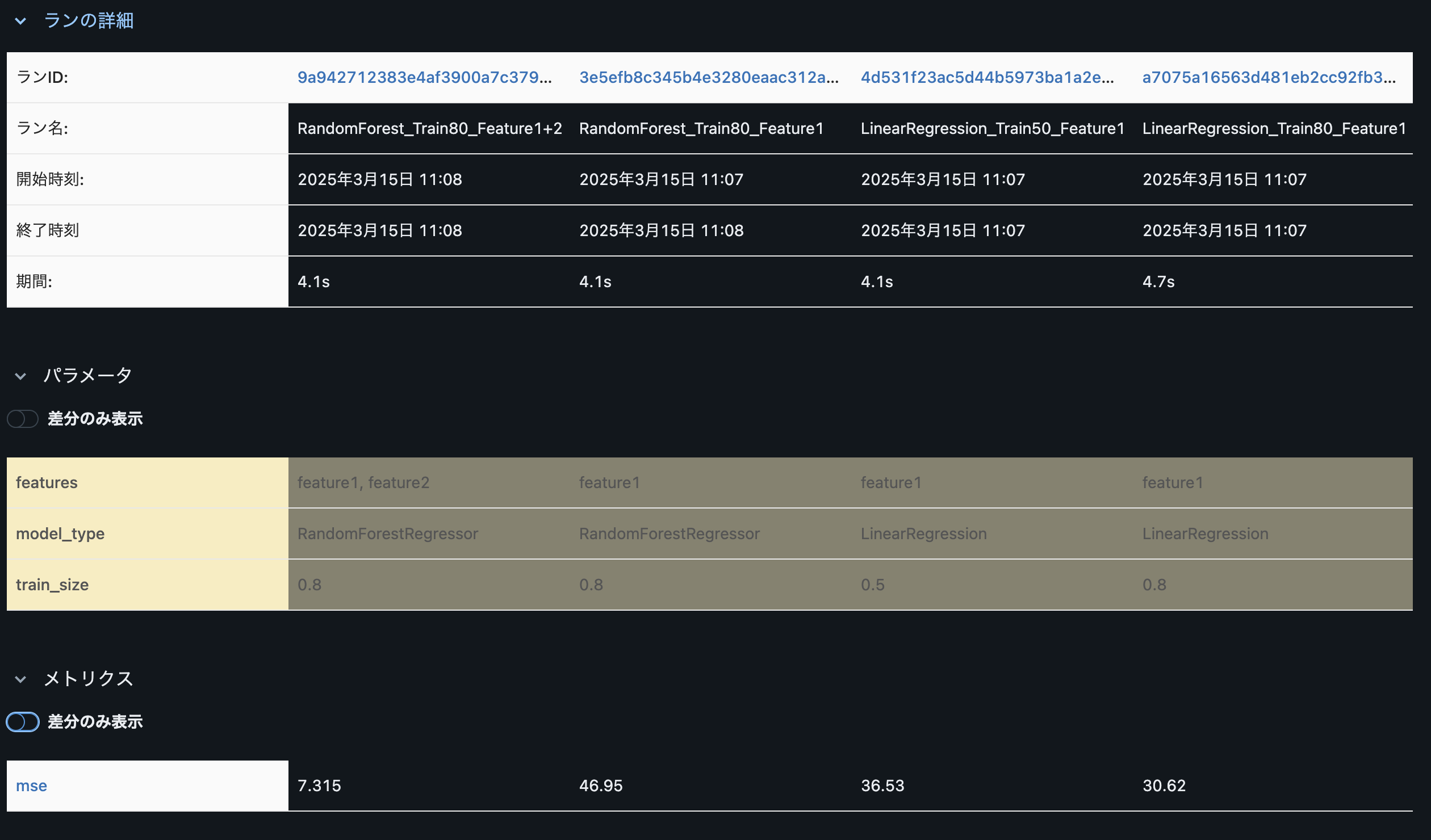
他にも箱ひげ図や等高線図で比較ができます。
今回のデモデータは簡単なサンプルなので、面白い図が出なかったので割愛します。
2. 再現性の向上
各実験の詳細(パラメータ、コード、環境など)が記録されるため、後でも実験を正確に再現することができます。チームメンバーとの共有や、論文・レポート作成時の裏付けとしても役立ちます。
3. モデルのバージョン管理
各実験で生成されたモデルは自動的に保存され、バージョン管理されます。最適なモデルを見つけた後、それを本番環境にデプロイするためのワークフローも整っています。
実際の業務での活用シナリオ
シナリオ1: 複数のモデルアーキテクチャの比較
データサイエンティストが予測モデルの開発を行う際、線形回帰、ランダムフォレスト、XGBoost、ニューラルネットワークなど、複数のモデルアーキテクチャを比較検討したいことがあります。Databricksのエクスペリメント機能を使えば、各モデルのパフォーマンスを一覧で比較し、最適なモデルを選択できます。
シナリオ2: ハイパーパラメータのチューニング
機械学習モデルの性能はハイパーパラメータの選択に大きく影響されます。例えば、ランダムフォレストのn_estimatorsやmax_depthなど、様々なパラメータの組み合わせを試す必要があります。MLflowを使えば、これらのパラメータとそれに対応する性能メトリクスを自動的に記録し、最適な組み合わせを見つけることができます。
シナリオ3: チーム間のコラボ
複数のデータサイエンティストが同じプロジェクトに取り組む場合、お互いの実験結果を共有し、ベストプラクティスを学び合うことが重要です。Databricksのエクスペリメント機能を使えば、チームメンバー全員が各自の実験結果を閲覧し、知見を共有することができます。
ただ無料版はかなり限りがある…。
Databricksの無料版(Community Edition)と有料版(Standard、Premium、Enterprise)では利用できる機能に大きな違いがあります。有料版(課金すると)で追加される主な機能としては、
- コンピューティングリソースの拡張: より強力なクラスタやより多くのリソースを利用可能
- 高度なセキュリティ機能: ロールベースのアクセス制御、監査ログ、シングルサインオン
- 自動スケーリング: ワークロードに応じて自動的にクラスタをスケールアップ/ダウン
- ジョブスケジューリング: 高度なジョブスケジューリングと管理機能
- MLflowの拡張機能: モデルレジストリの完全な機能、モデルのサービング
- データレイク: データレイクの高度な機能とパフォーマンス最適化
以上があります。
特にMLflowに関しては、無料版でも基本的な実験管理はできますが、有料版ではモデルデプロイメントのパイプラインやモデルレジストリの高度な管理機能など、本番環境でのモデル運用に必要な機能が追加されます。また、無料版では時間や計算リソースに制限があるため、ビジネスで使用されるような大規模なデータセットや複雑なモデルの学習には有料版が適しています。
今回もお金払えばもっとできそうだった。ちょっと悔しい。
まとめ
Databricksのエクスペリメント機能(MLflow Tracking)は、機械学習モデル開発のワークフローを大幅に改善する強力なツールです。実験の追跡、可視化、比較を自動化することで、データサイエンティストはモデル開発に集中し、より質の高いモデルをより効率的に作成することができます。
特に、以下のような場面で威力を発揮します。
- 多数のモデルやパラメータの組み合わせを試す必要がある場合
- チームで協力してモデル開発を行う場合
- モデル開発の過程を透明化し、説明可能性を高める必要がある場合
- 過去の実験に基づいて新しい仮説を立て、検証する場合
まだDatabricksを試したことがない方は、この機会にぜひ試してみてください。機械学習モデル開発の効率と質を向上させることができると思います。