こんにちは!パナソニックコネクト㈱でAIに関するR&Dを担当している瀬戸口です。
今回はパナソニックコネクト㈱がオープンソースで開発を進めている機械学習モデルであるCyclic boostingについて紹介したいと思います。
我々がオープンソース開発を推進している背景とCycilc boostingの概要はこちらでも紹介していますのでぜひご覧ください。
パナソニックコネクトが進める機械学習モデルのOSS開発
今回は更に踏み込んだCyclic boostingの技術解説と詳細な使用方法をご紹介したいと思います。
Cyclic boosting
Cyclic boostingはSCMシステムベンダー(SCM:サプライチェーンマネジメント)としてトップレベルの企業であるBlueYonderが自社の予測エンジンとして開発していた機械学習アルゴリズムです。
SCMに応用することを想定していたため主なユースケースは需要予測であり、需要予測を適用するビジネスシーンのためにデザインされた様々な機能を有していますが、Cyclic boostingのアルゴリズム自体はその他の回帰問題や分類問題にも活用できる汎用的なものです。Cyclic boostingの代表的な特徴をまとめると以下のようになります。
- 個々のターゲットの確率分布推定、影響度の可視化による高い説明性
- モデル構造自体の高い透明性
- 外れ値へのロバスト性
ここからCyclic boostingのアルゴリズムの紹介を通して、どこから上記のような特徴が生み出されているのかを解説したいと思います。
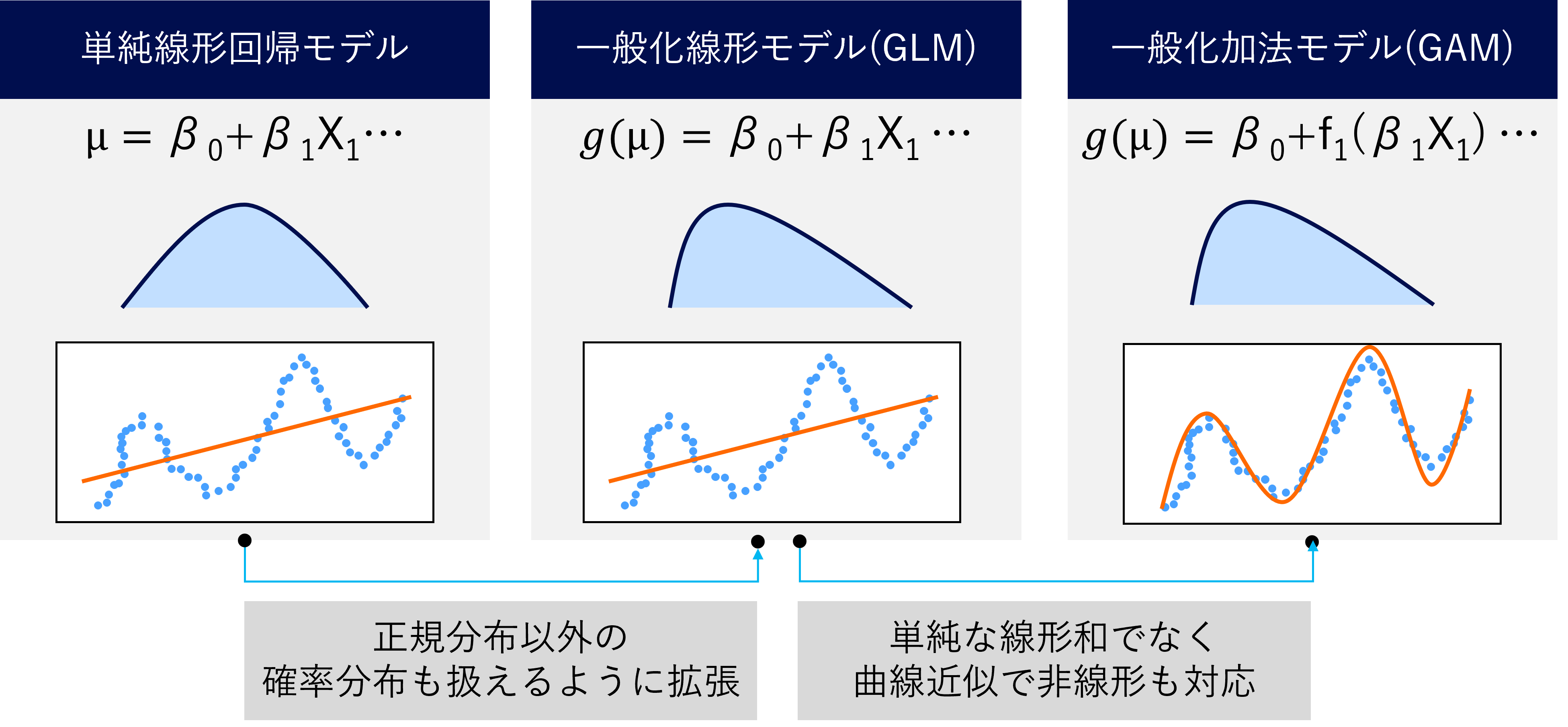
Cyclic boostingは一般化加法モデル (GAM: Generalized additive model)と呼ばれる線形回帰モデルに分類される構造をもっています。
GAMは最もシンプルな単純線形回帰モデルから一般化線形モデル(GLM: Generalized linear model)、そしてGAMという流れで発展していった手法です。
端的に表現するならば、正規分布以外の確率分布も扱え、曲線近似によって単なる線形和で表現できない説明変数と目的変数間の非線形関係を考慮できるようにしたモデルがGAMです。

線形回帰モデルは説明変数から計算された値の線形結合によって予測値が決まるため一般的にモデル自体の透明性が高い部類の手法です。
次にCyclic boostingのモデルを表す式1を示します。Cyclic boostingはGAMの構造をベースに、平均2に対して各説明変数が正負のいずれかの影響を与えることで予測値が定まるようにモデル構造を変化させています。
このような構造を採用することで予測値に対して説明変数がどのような影響を与えているのかが理解しやすくなります。
GAMの構造と対応づけると、Factorと記述されている部分が曲線近似関数からの応答値に該当しており、これは後述するbinに分割された特徴量に対して重みをかけ合わせ平滑化したものです。またGAMと同様にLink関数も存在しています。
注1: 例は乗法モデルであるため積で記述されています。加法モデルであれば和で記述されます。また曲線近似のための関数やLink関数の記述は省略されています。
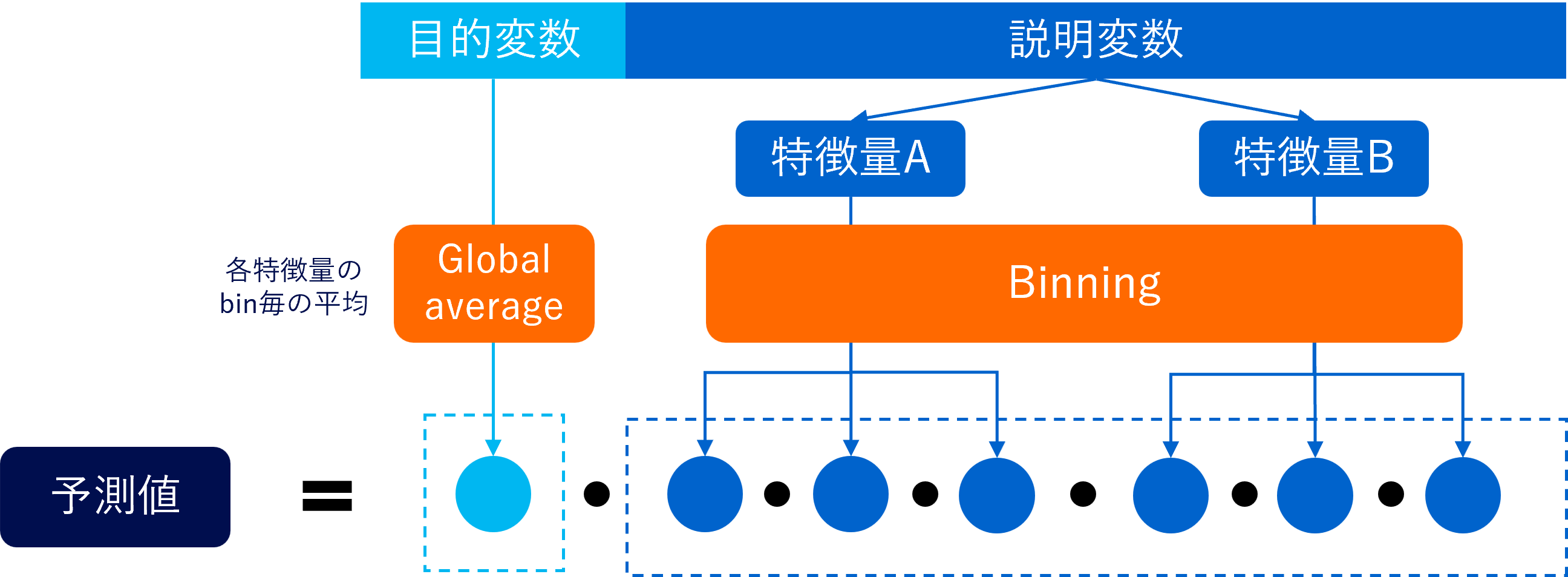
注2: 全てのbinと特徴量から得られる目的変数Yの値を平均化したものがGlobal averageです。
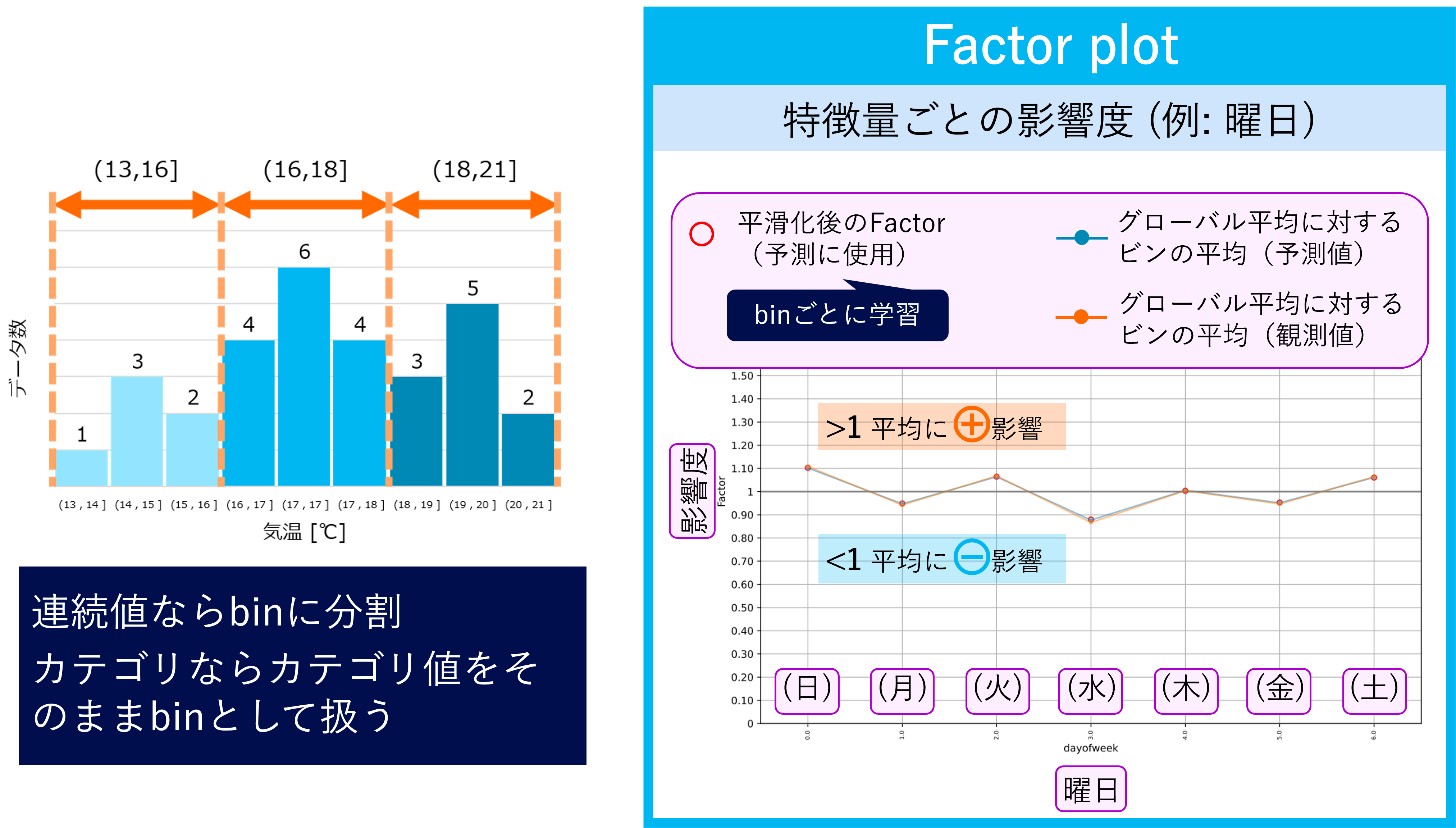
加えて、Cyclic boostingでは説明変数に対してBinningという処理を適用しています。
Binningは連続値をとる量的変数に対して行われる場合、例えば0~100の範囲の連続値のとき0~10, 10~20...のように分割し、範囲に含まれる値には全て同じ番号のラベルを振る。といったようにカテゴリ変数化する処理になります。また元々カテゴリ変数だったものは1つのカテゴリが1つのbinとして変換されます。
Cyclic boostingではこのbinがひとつの特徴量として扱われます。先ほど示したモデル構造と合わせるとCyclic boostingは平均に対して各binが正負のいずれかの影響を与えることで予測値が定まるように設計されていると言い換えることができます。
ここで小売店における需要予測のユースケースを考えてみます。このとき目的変数が需要(≒販売数の見込み)、説明変数が曜日だった場合、図に示すように月曜~日曜日のうち、例えば土日は高い販売数が見込めるなどの観測データの傾向を詳細に理解することができます。
曜日の例は比較的イメージがしやすく分析なしでも推測できそうなものですが、事前知識のないまったく未知のドメインや、より複雑な関係性を分析せねばならないケースにおいて詳細に影響を分析できるCyclic boostingは非常に有効な手段であると思います。
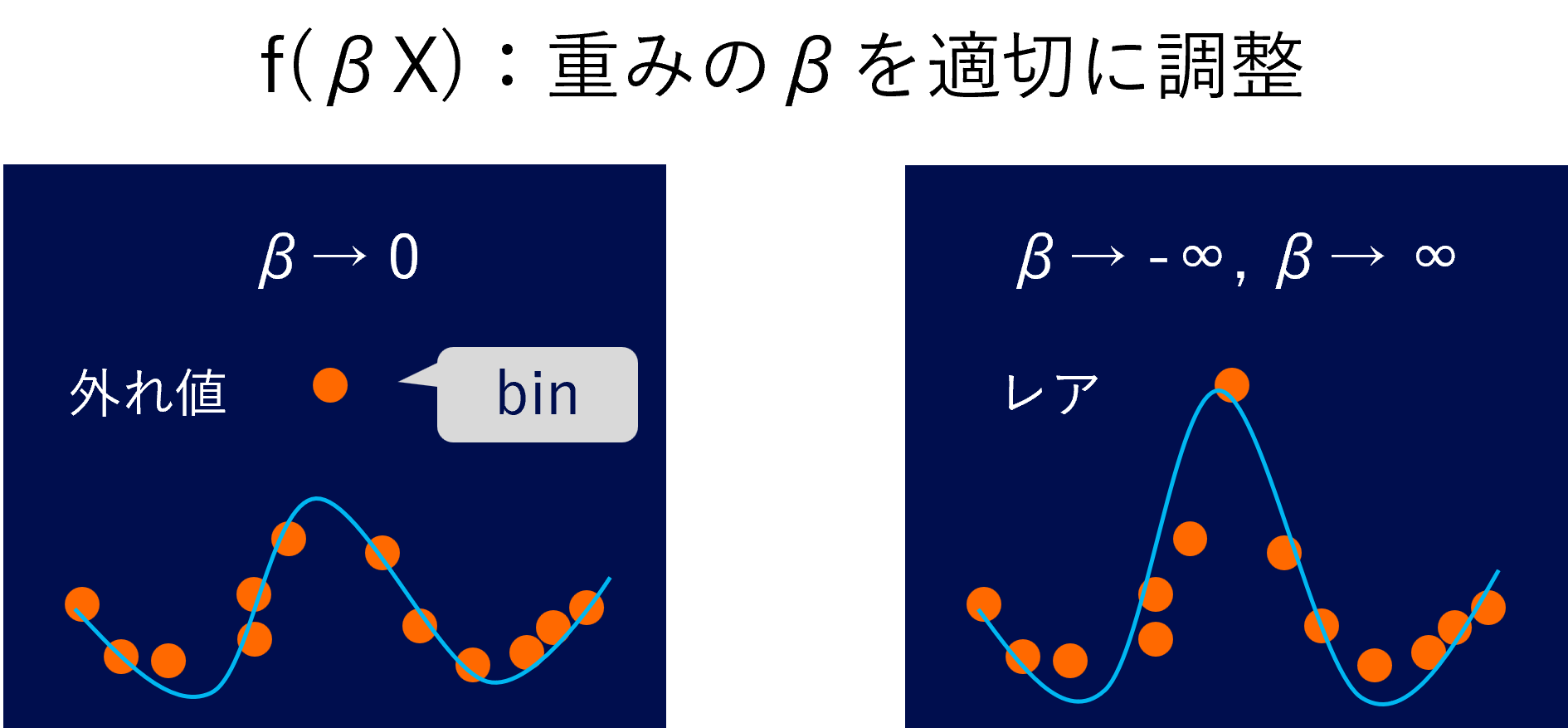
Binningは外れ値に対してロバストに推論することにも貢献します。
量的変数において外れ値が問題になるのは何らかの理由で実際の事象では起こり得ない観測データが得られたとき、モデルが外れ値に引っ張られて推定する場合です。こういったケースにおいてもBinningによって外れ値をbinに振り分けて、そのbinに対する重みを0にしてしまえば外れ値の影響を無くすことができます。
また、それが外れ値ではなく観測頻度が極端に少ないレアなサンプルだったとしても目的変数yに対する影響をモデル化できるため、レアなサンプルでの予測をより精度良くすることに繋がります*3。これは小売店の需要予測のケースの場合、販売回数の少ない商品があったとしても、その商品の需要予測をより良くするということにあたります。
上記のCyclic boostingのモデル構造を最もシンプルに記述すると以下のようなイメージになります。新たなデータに対する予測は学習時に得たBinningの振り分けとGlobal averageの値を利用して行います。
注*3: 単に各binに重みづけするだけではレアなサンプルの場合は観測データに過学習してしまうことがあるため、ベイズ正則化や平滑化を適用しています。
小売り店舗の仮想販売データを利用したCyclic boostingによるモデリングの例
ここからはCyclic boostingのレポジトリに用意されているJupyter notebookを使った回帰モデルのチュートリアルを1-stepずつ説明しながら、よりCyclic boostingの理解を深めたいと思います。
ぜひCyclic boostingのリポジトリをcloneして、お手元の環境で動かしながら追っていただければと思います。チュートリアルはこちら
まず事前準備としてpipを利用してCyclic boostingのpackageをインストールしておいてください。
一番初めのセルはjupyter-blackというcode formatterを利用していない人は関係がないので読み飛ばしてOKです。
次に必要なPackageをimportします。
ここでCyclic boosting packageからimportしているモジュールについて概要を説明します。これ以降のチュートリアルの流れを追っていきながら、適宜参照することでより役割が理解できると思います。
- flags
- 説明変数のデータ特性を示すフラグ。Cyclic boostingを実行するとき挙動の制御に使われます
- common_smoother
- Cyclic boostingが学習される重み(factor)に対して適用する平滑化関数をハンドリングするためのclass。この平滑化による曲線近似によって非線形な関係性を捉えます
- observer
- Cyclic boostingの学習過程を記録するobserver。このobserverによってモデルが捉えた傾向などを可視化できます
- binning
- Cyclic boostingの学習のために実装された特徴量のもつ値をbinに振り分けるためのclass。このチュートリアルではbinningの処理をもつPipelineを使ってモデルの学習を行うため利用していませんが、そうでない場合はsklearnのpipelineを利用してモデルの実行時は必ず実行されるようにしておく必要があります
- plots
- observerからデータを受け取って分析のための画像を生成するツール
- pipelines
- Binningとモデルがセットにされたpipeline群。多くの場合こちらから必要なモデルを選んで利用することが最もシンプルです
- smoothing
- 平滑化関数群。データに適した平滑化関数を選ぶことでより汎化性を高められますが指定しなくも学習は実行できます
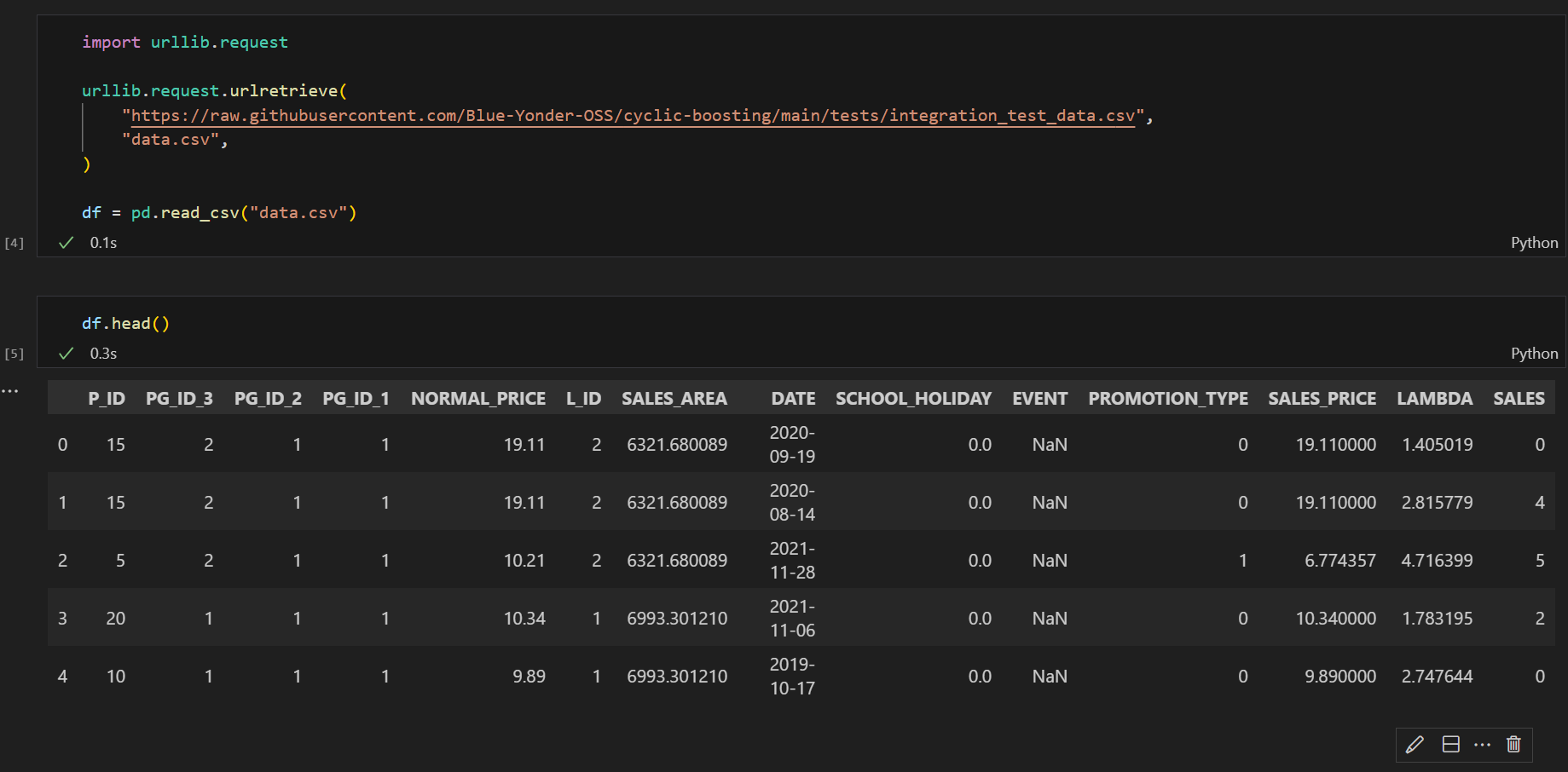
それでは次に使用するデータセットを見ていきましょう。
こちらは小売店舗の需要と実販売数をシミュレートして作成した仮想データセットです。このような仮想データセットをシミュレートするためのライブラリもオープンソースで公開していますのでぜひご活用ください。
小売店舗の仮想データシミュレーションライブラリ -demand_forecasting_simulation-
さて、本題に戻りデータセットにはどのようなデータがあるか、こちらも概要を整理します。
- P_ID [int]
- 製品ID
- PG_ID_3 [int]
- 製品のグループ。例えばP_IDがビールのような製品名を示し、PG_ID_3はアルコール、ノンアルコールのような何らかのグループを示します
- PG_ID_2, PG_ID_1
- PG_ID_3よりも上の階層がある場合のグループ。今回のデータセットでは全て1、つまりグループ分けがない状態です
- NORMAL_PRICE [float]
- 通常時の販売価格
- L_ID [int]
- 店舗ID
- SALES_AREA [float]
- 店舗の座標。仮想データの座標系や範囲などは現実のものと異なります。値が近ければ近いところに位置していることを示します
- DATE [str]
- 日付
- SCHOOL_HOLIDAY [int]
- 学生の長期休暇期間かを示すフラグ
- EVENT [str]
- 祝日などの不規則なイベント。何もない場合はNull
- PROMOTION_TYPE [int]
- 販促活動の有無を示すフラグ。何もない場合は0、ある場合は1以上であり販促活動の種別によって値が異なる
- SALES_PRICE [float]
- 実売価格
- LAMBDA [float]
- 潜在的な需要。SALESはこの需要をもとに様々なシミュレーションによる影響を考慮して計算される
- SALES [int]
- 販売数。潜在需要から加工されたもの
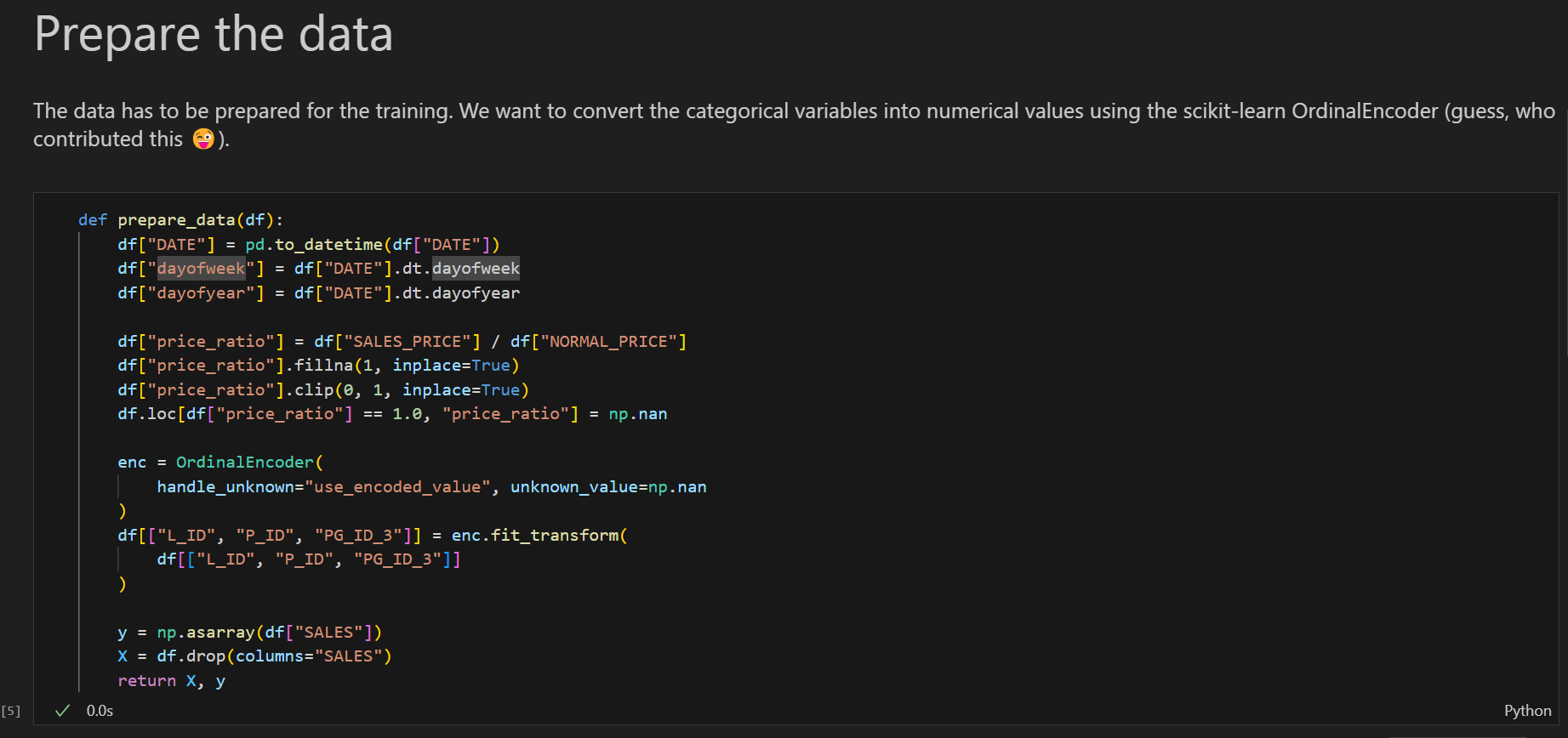
このセルではデータセットに対して前処理を加えています。
やっていることはシンプルです。Cyclic boostingは数値しか扱えないので最低限int型かfloat型への変換処理を行います。
一方でBinningを適用するため欠損値はそのままでよく、正規化等のスケーリングも必要ありません。理由は欠損値もbinとして設定でき、binで区分けするため値の大きさも影響しないためです。
- 日付を文字列から列挙された曜日、列挙された年の日付に変換
- 通常価格からの変動割合を計算
- IDを順序つきのint型カテゴリに変換
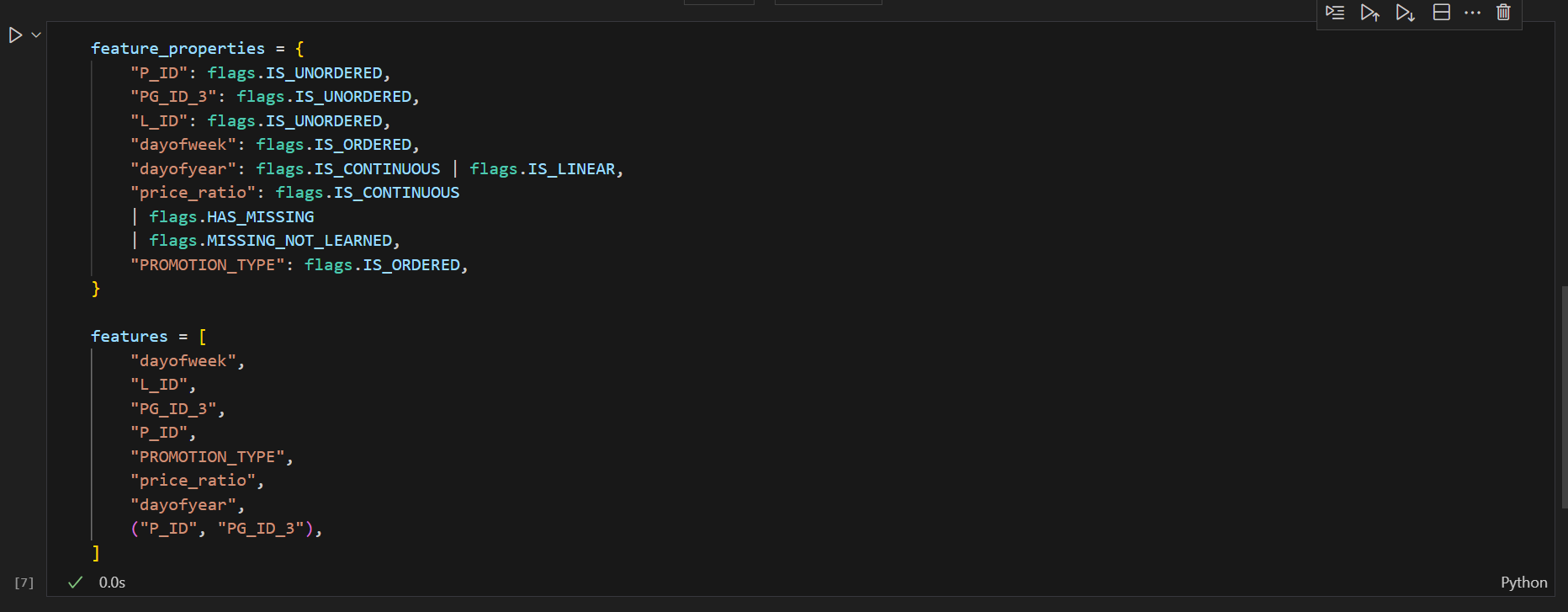
ここから徐々にCyclic boostingのユニークな設定がでてきます。
Cyclic boostingはオプションとしてfeature_properties、feature_groupsという引数をもっています。
feature_propertiesは辞書形式で学習するデータの特性をフラグとして指定できます。Cyclic boostingではこのフラグを参照して適用するBinningや平滑化関数を調整します。
feature_groupsにはモデリングに使う特徴量を指定します。ここで重要なのがタプルで指定されている2つ以上の説明変数からなる交互作用項です。
これは説明変数が組み合わさって生まれる非線形な関係性を表す情報となり、有効な組み合わせを設定できればモデルの精度を向上させることに寄与します*4。このチュートリアルでは製品グループと製品IDの組み合わせを交互作用項に設定しています。
注*4: 一方で3変数以上など複雑な交互作用項を設定すると観測データに対して過学習する可能性があったり、モデルの複雑度が増して分析しにくくなったりする可能性があるため注意が必要です。
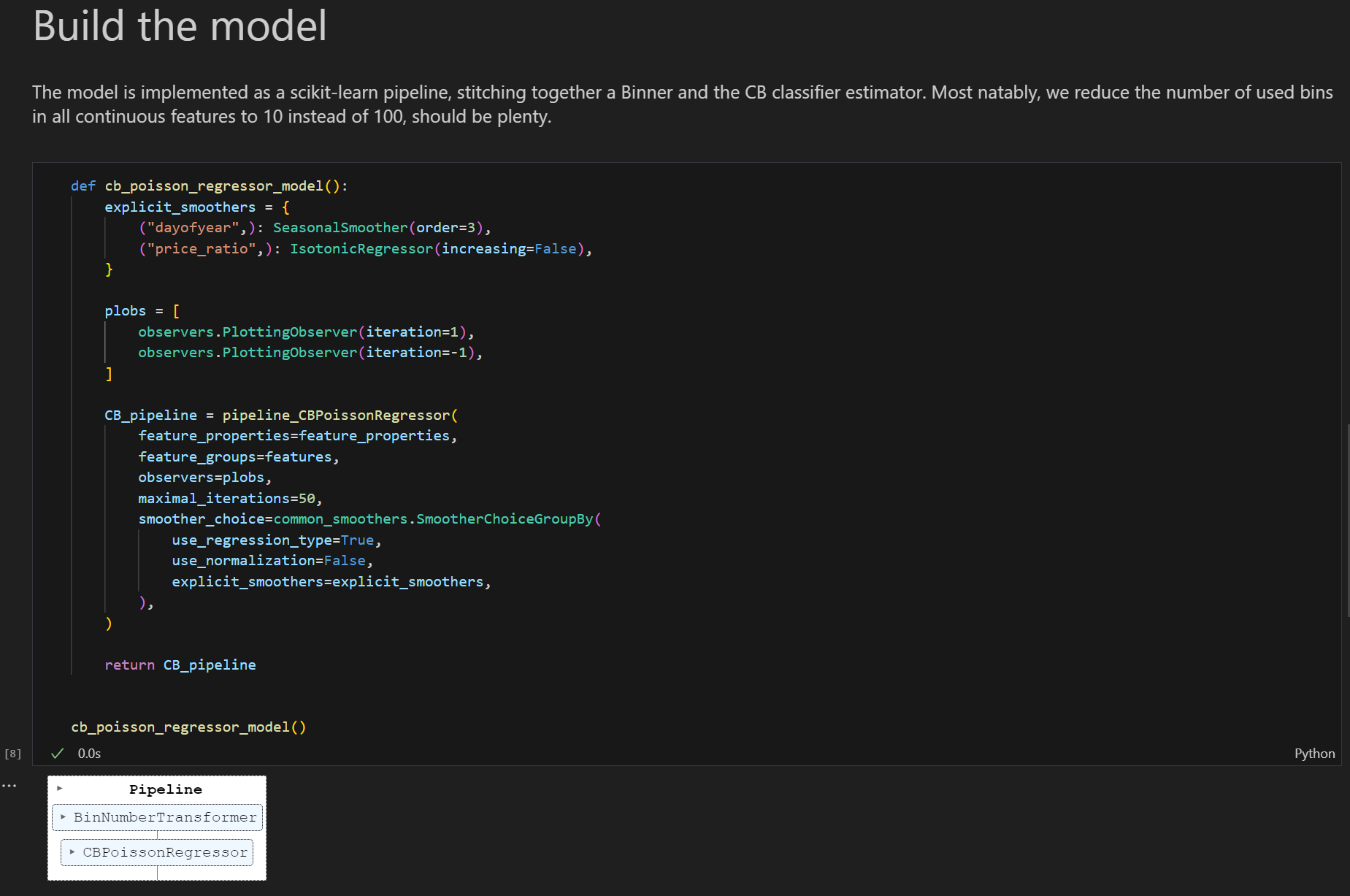
最後はモデル定義です。
小売店舗の販売数に関するデータの場合、ランダムなイベントが一定期間に何回発生するかを示す確率分布であるポワソン分布を仮定してモデリングすることがベターです。そのためCyclic boostingのPoisson Regressorのpipelineを使用してモデル定義します。
指定できる引数について、pipelineの引数の一つであるsmoother_choiceには任意の特徴量に対して適用する平滑化関数を指定できます。
また、observersには学習を記録するためのoverserverのリストを渡すことができます。このときiterationに-1を渡すと学習の最後まで自動的に記録します。記録データはモデルの可視化に利用されます。
Cyclic boostingはこれらの引数を特に指定せずとも学習の実行が可能ですが、より良いモデルを得たい場合は活用すると良いと思います。
また、Cyclic boostingはGAM由来の構造をもつため、このように様々なユースケースに対して使う手法を適切に選ぶことでより良い学習モデルを得ることができます。
以下、Cyclic boostingが現段階でカバーしているケースを参考までに紹介しておきます。

最もメジャーなものが乗法回帰モードです。チュートリアルも乗法回帰モードのCyclic boostingを活用しています。
その他にも確率分布のパラメータ推定のための推定器や、需要予測から発展し、製品販売するときに影響する価格弾力性や特定顧客へのターゲティング分析のための推定器などもカバーしています。詳細は公式Documentをご覧ください。
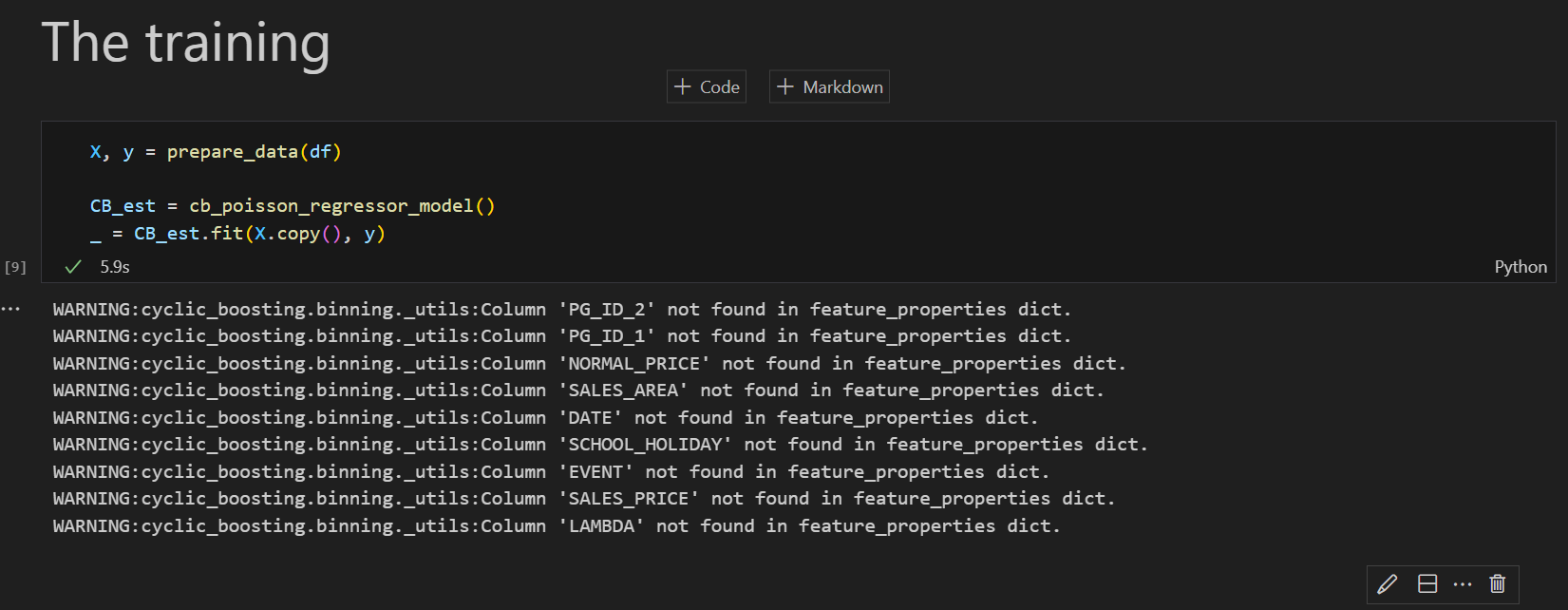
これで準備は整いました。学習の実行方法はとてもシンプルです。
Cyclic boostingはSclkit-learnのようなインターフェースで実装されていますので、fit関数の呼び出しだけで実行することができます。
このときデータセットに含まれているのにfeature_propertiesに指定されていない特徴量について設定が正しいか警告がでますが特に実行に関しては問題ありません。
推論過程も同様です。馴染みのある使い方ですね。
チュートリアルの最後は可視化です。
Cyclic boostingではplot_analysis関数を使うことでデータ分析することなくモデルが捉えたデータセットの傾向を可視化することができます。
plot_analysisのplot_observerにはpipelineに設定したobserverのインスタンスを、binnersにはBinningのインスタンスを指定します。
pipeline_CBPoissonRegressorにはindexが若い順にbinnerとestimatorのインスタンスが保持されているため、それらをindexを指定してplot_analysis関数に渡しています。
この関数を実行すると分析結果のグラフがpdfファイルにまとめて出力されます。いくつか可視化されるグラフの見方について説明します。
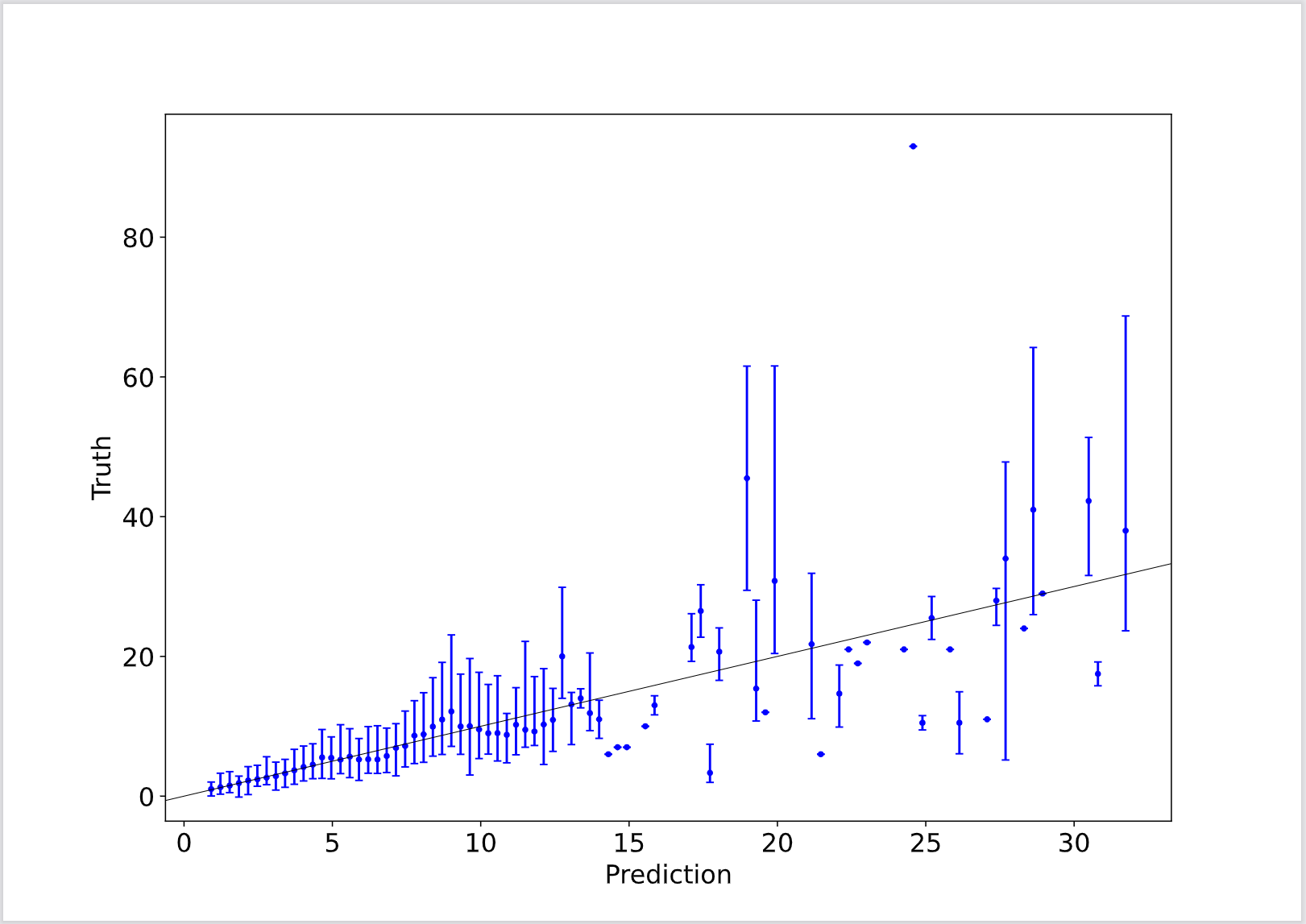 |
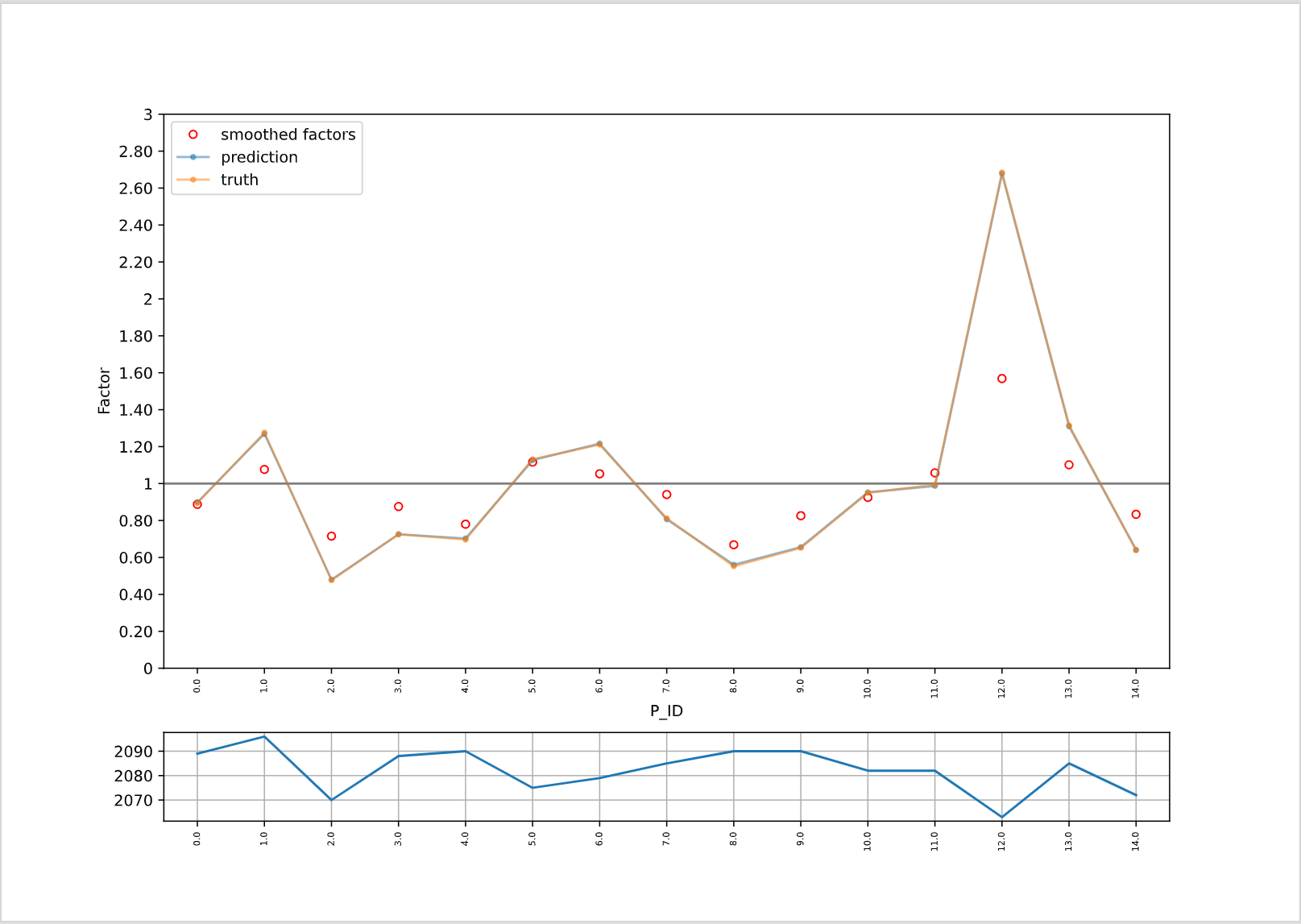 |
左図は真値と予測値の対角プロットです。ひげは1σ分の範囲を示しています。
右図は各binが予測値に与える影響を示した折れ線グラフです。Global average=1を基準としたとき、各binが正負いずれの影響をどれだけが与えているかを示します。
右図の場合、P_ID=12のサンプルの影響度が正の方向に大きいため、P_ID=12の販売数は相対的に大きい傾向があると解釈できます。下部の青い折れ線グラフは各binに含まれる学習データのサンプル数となります。
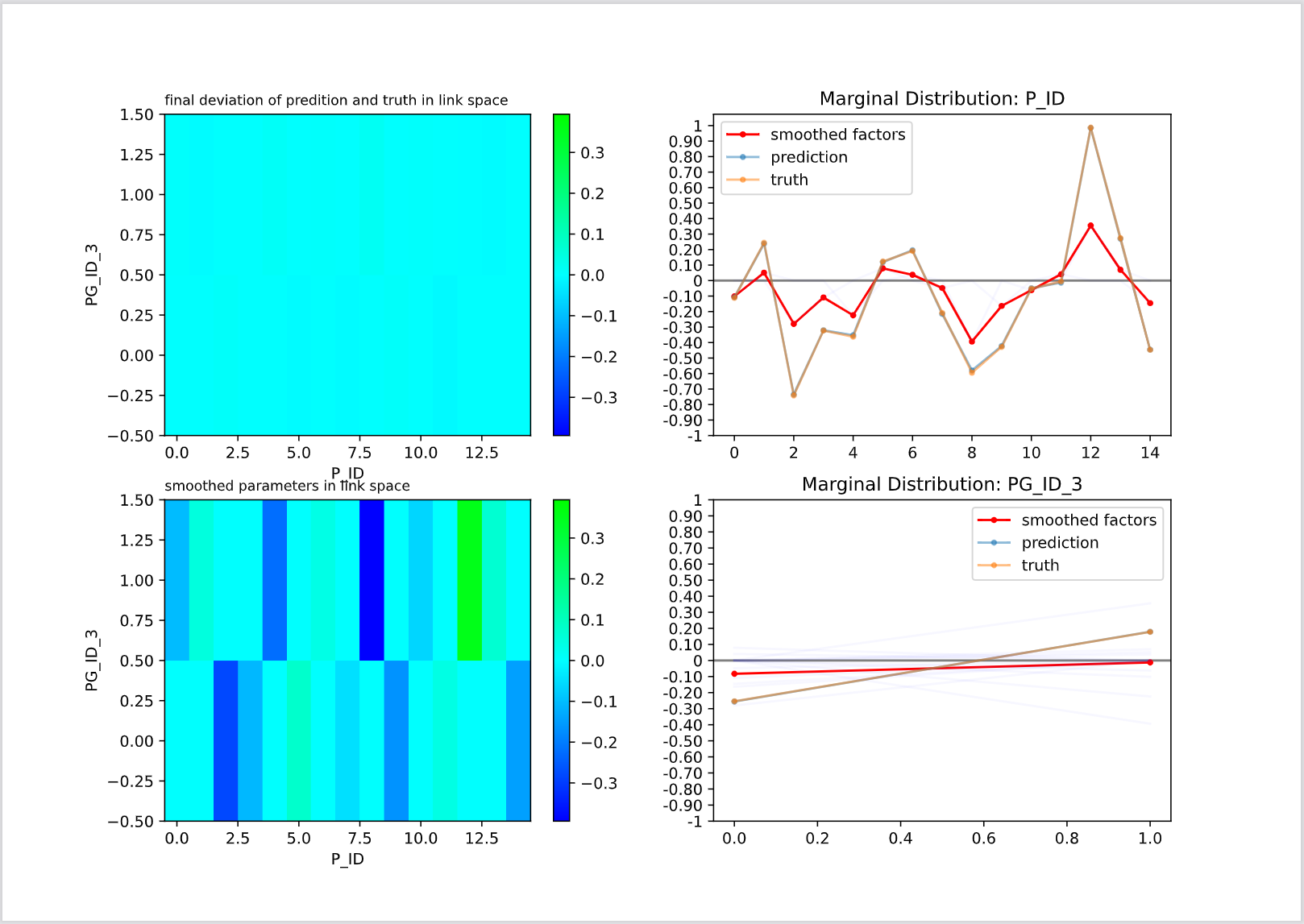 |
 |
左図は2つの変数からなる交互作用項を分析しているものです。
左上のヒートマップは予測値と真値の偏差を示しており、左下は交互作用項が予測値に与える影響を示しています。
この例では交互作用項として設定されていたPG_ID_3とP_IDの関係が示されています。今回利用したシミュレーションデータではP_ID=12のとき予測に正の影響を与えることを確認しました。
このとき、P_ID_3:製品グループ(今回は0 or 1)毎にみると同じ製品でもP_ID_3=1のとき販売数は大きい傾向があるがP_ID_3=0のときはさほど大きくないことがわかります*5。
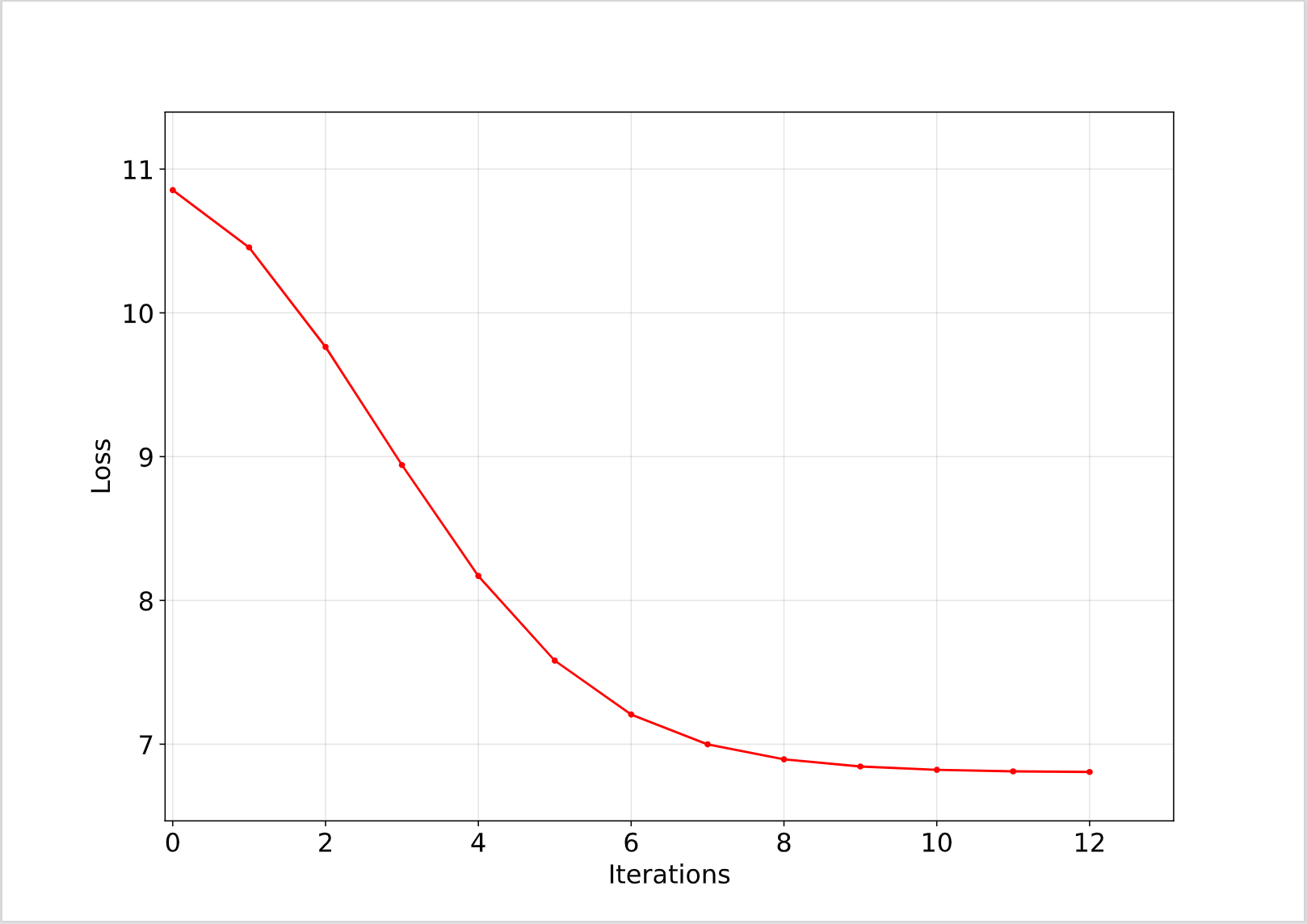
右図は学習を開始してから終えるまでの損失の推移です。徐々に小さくなっていることが確認できます。
このようにCyclic boostingを利用することでモデルが捉えた傾向をデータ分析なしに簡単に理解することができます。この説明性がCyclic boostingの強みです。
注*5: 緑が濃いほど正の影響が大きく、青が濃いほど負の影響が大きいことを表します。
おわりに
本記事ではCyclic boostingの技術的な要点とチュートリアルを通して実際の使い方を丁寧に追っていきました。
今後もパナソニックコネクト㈱では継続的に技術のアップデートを加えていきます。これをきっかけにぜひご活用いただければ幸いです!Issue報告やご質問などもお待ちしています!
各種リファレンス
- Cyclic boosting repository
- Cyclic boosting document
- 論文(より詳細な技術内容はこちらを参照ください)
- 関連レポジトリ
- skpro: 確率分布推定のためのパイプラインが含まれたライブラリです。こちらでもCyclic boostingを活用できるようにしています
- demand_forecasting_simulation: 小売り向けの需要シミュレーションパッケージです。仮想データが生成できます