導入
近年、AI(人工知能)は日常生活のあらゆる側面に大きな影響を与えています。中でも、自然言語処理(NLP)領域は大きな進歩を遂げており、その中心に位置するのが会話型AIです。
2023年現在、最もインパクトを与えた会話型のAIはOpenAIによって開発されたChatGPTです。このモデルは大規模なデータセットを学習し、それにより人間のような自然な会話を生成する能力を持っています。その結果、ChatGPTは多くの用途で活用されており、その影響力は増大の一途を辿っています。
本記事では、ChatGPTに関する最新の研究論文12本を紹介します!!
言語モデルがどのように発展していったのかを論文ベースで把握したい方にオススメです!!
記事を読んで得られる知識は以下です。
- 言語モデルがどのようにプロンプトを処理しているかのイメージが掴める。
- 2023年現在での最新の研究動向がざっくり把握できる。
- プロンプトを考えるための前提知識が身に付く。
論文概要
OpenAIが選定した12の論文を紹介します。
基本: Chain-of-Thought(COT)
Chain-of-Thought(COT)の発展
- Self-Consistency Improves Chain of Thought Reasoning in Language Models (2022)
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models (2023)
- Language Models are Zero-Shot Reasoners (2022)
プロンプトエンジニアリング
- Large Language Models Are Human-Level Prompt Engineers (2023)
- Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling (2023)
言語モデルの解釈性
- Faithful Reasoning Using Large Language Models (2022)
- STaR: Bootstrapping Reasoning With Reasoning (2022)
言語モデルの応用•発展
- ReAct: Synergizing Reasoning and Acting in Language Models (2023)
- Reflexion: an autonomous agent with dynamic memory and self-reflection (2023)
- Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP (2023):
- Improving Factuality and Reasoning in Language Models through Multiagent Debate (2023)
論文の詳細の紹介ではなく、手法の簡単な紹介となります。
修士時代の専門分野が自然言語処理でないため、日本語訳や解釈に誤りがある可能性があります。
論文紹介におけるプロンプトの例は以下のサイトを参考にしております。
少しボリューミーですが、お付き合いください!!
論文紹介:基本: Chain-of-Thought(COT)
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022)
要約
モデルに思考の過程を考えさせる(ステップバイステップで考えさせる)技術であるChain-of-Thought(COT)を提案した。
内容
Chain-of-Thought(CoT)とは思考の連鎖を生成する技術であり、複雑な推論タスクを解決するための中間的な推論ステップを生成する技術です。
CoTの例は以下です。
このグループの奇数を合計すると偶数になります。: 4、8、9、15、12、2、1。
A: 奇数を全て加えると(9, 15, 1)25になります。答えはFalseです。
このグループの奇数を合計すると偶数になります。: 17、10、19、4、8、12、24。
A: 奇数を全て加えると(17, 19)36になります。答えはTrueです。
このグループの奇数を合計すると偶数になります。: 16、11、14、4、8、13、24。
A: 奇数を全て加えると(11, 13)24になります。答えはTrueです。
このグループの奇数を合計すると偶数になります。: 17、9、10、12、13、4、2。
A: 奇数を全て加えると(17, 9, 13)39になります。答えはFalseです。
このグループの奇数を合計すると偶数になります。: 15、32、5、13、82、7、1。
A:
以下の例では、数列の和の偶奇の判定の際に、「数列の和」を計算させる中間処理を加えています。またこのように少数の例を提示する手法をfew-shot learningといいます。
CoTのメリットは以下です。
- 複雑な問題を中間ステップに分解することを可能となり、より多くの推論ステップを必要とする問題に追加の計算を割り当てることができること。
- モデルの振る舞いに対する解釈可能な「窓」を提供することで特定の答えに至った過程を把握でき、推論パスがどこで間違ったのかをデバッグできること。
- 数学の単語問題、常識推論、記号操作などのタスクに使用でき、原理的には人間が言語を通じて解決できる任意のタスクに適用可能であること。
- COTの技術により、十分に大きい言語モデルを扱うことができること。(COTがないと十分に大きい言語モデルの性能を発揮できていないというニュアンス)
約100Bのパラメータを持つモデルでのみパフォーマンスが向上することが判明しています。
研究分野への影響
CoTの考え方は現在のChatGPTを含む言語モデルで欠かせない技術であり、後続の自然言語処理系の研究ほぼ全てに影響しています。今回紹介する論文の中では、Zero Shot Learningに関わる論文と最も深く関わりがあります。
論文紹介:Chain-of-Thought(COT)の発展
Self-Consistency Improves Chain of Thought Reasoning in Language Models (2022)
要約
言語モデルの推論経路を複数に増やし、投票制することで、Self-Consistency (自己整合性)を高めてモデルの精度が向上させた。
内容
CoTを促すために用いられている貪欲的な方法は、最も可能性の高い推論経路をたどって最終的な答えを出す、ナイーブなアプローチです。
しかし正解に繋がる経路が最も可能性の高い推論経路だった場合には、貪欲法のアプローチでは解決できません。
本手法ではCoTの貪欲的なデコードを、デコーダーからのサンプリングに置き換えることで多様な推論経路のセットを生成します。
そして生成した推論経路を集め、最も一貫性のある(Self-Consistency)回答を選択します。
ここでの一貫のある回答とは、多数決の投票結果を意味します。

このアプローチは、複雑な推論問題では通常、解法が複数存在するはずであるというヒューリスティックなアイデアを活用しています。
研究分野への影響
推論経路を増やして考慮するという手法は他の自然言語処理の論文でも多く利用されています。また後続研究には以下で紹介するToTがあります。
Tree of Thoughts: Deliberate Problem Solving with Large Language Models (2023)
要約
(多様な推論経路からの出力から投票することではなく、)生成した(中間的な推論を含む)推論のツリーを検索するTree of Thoughts(ToT)を提案した。
内容
Tree of Thoughts(ToT)では、推論経路を複数とし、推論のステップを木構造とします。そしてある推論のステップから次の推論ステップを探索的に決定します(木構造にすることで深さ優先探索や幅優先探索ができる)。また、必要に応じて先読みや推論ステップの後退を行い、グローバルな(縦横無尽な)推論ステップの選択を行うことも可能な点がToTの特徴です。
ToTの概念図は以下です。

(b)はCoT、(c)はSelf-Consistencyを加えたCoT、(d)はToTです。
図からもわかるようにToTは、経路を探索的に決定することで推論を行います。
ToTを使ったプロンプトは以下のようになります。
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...
Language Models are Zero-Shot Reasoners (2022)
要約
解答例を例示されずに推論を行うzero-shot推論の有効性を示した。
内容
これまでの研究では、CoTをはじめとするfew-shot learningを基礎としており、ある程度の答えの例を提示したり、答え方自体を教える必要がありました。
一方で、この手法はプロンプトエンジニアリングに労力がかかってしまいます。そこでモデルには事前に解答例を提示せず、代わりに「ステップバイステップで考える」というプロンプトを提示する「zero-shot CoT」を提案しました。

「ステップバイステップで考える」というプロンプトを提示すると、モデルはステップバイステップで解決するための中間の推論パスを生成することができます。これによりCoTを用いた推論ができるようになります。
研究分野への影響
zero-shotの推論にもLLMはを活用できるということが示されたので、LLMの汎用性や応用可能性が広がりました。
論文紹介:プロンプトエンジニアリング
Large Language Models Are Human-Level Prompt Engineers (2023)
要約
人間と同等以上に質の高いプロンプトを言語モデルに作成させる手法であるAutomatic Prompt Engineer(APE)を提案した。
内容
今までの研究では全て人間がプロンプトを考えていましたが、この論文では言語モデルにプロンプトを考えさせる、つまりプロントエンジニアリングの自動化を行いました。
プロンプトを生成するアルゴリズムであるAutomatic Prompt Engineer(APE)は以下のステップから構成されます。
- 初期提案の生成:特定のタスクを達成するための候補となるプロンプトを生成します。下図のProposalに対応します。
- スコア関数の適用:生成されたプロンプトの品質を評価するためのスコア関数を選択します。このスコア関数は、データセットとモデルが生成するデータとの間の一致度(尤度)を測定します。下図のScoring及びLog Probablityに対応します。
- 反復的な提案: 初期の提案が十分に良いものでない場合、APEは反復的なプロセスを通じて新しい提案を生成します。これにより、より良いプロンプトを見つけるための探索空間が広がります。下図のHigh Score Candidates、Similar Candidatesで詳細な処理を行っています。

様々なタスクにおいて、APEは人間によって作成されたものと同等またはそれ以上のパフォーマンスを達成できることが示されました。
APEには二つの問題点があります。
一つ目はLLMによって提案された大量の命令候補が必要であり、計算量が多いことです。
二つ目は、APEが必ずしも人間が簡単に解釈できる命令を生成するとは限らないため、モデルの動作の背後にある理由を理解するのが難しくなってしまう恐れがあることです。
Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling (2023)
要約
プロンプトを再利用することで、CoTの可能性があるプロンプトの自動検索して言語モデルの精度を向上させた。
内容
精度に向上の余地があったLLMの精度を高めるためのプロンプトを自動生成するアルゴリズムを提案しました。
提案手法では、言語モデルが与えられたプロンプトに対して生成した応答を新たなプロンプトとして再利用し、そのプロンプトに対する新たな応答を生成するというプロセスを繰り返す(Repromptingする)ことで、言語モデルのCoTを形成します。このプロセスは、Gibbsサンプリングという統計的手法を用いて自動化されています。
提案手法の利点は、プロンプトの再利用することによるモデル間の知識の伝達を促進し、知識が伝達されたモデルのパフォーマンスを大幅に向上させることが可能な点です。
多段階推論を必要とするタスクにおいて、Repromptingはゼロショット、少数ショット、人間が書いたCoTベースラインよりも一貫して優れた性能を達成しました。
論文紹介:言語モデルの解釈性
Faithful Reasoning Using Large Language Models (2022)
要約
言語モデルの推論の透明性、信頼性を解釈できる手法を提案した。
内容
言語モデルの推論は不透明であり、信頼性が低いという課題がありました。
特に言語モデルはインターネットから収集された人間のデータに基づいて学習されるため、バイアスを拾いやすく(影響を受けやすく)、またバイアスを永続させやすい(バイアスの影響が残ってしまう)ことが知られています。(Bender et al, 2021; Betz et al, 2021; Weidinger et al, 2021)
そこで提案手法では、2つのファインチューニンングされた言語モデル(1つはSelectionモデル、もう1つはInferenceモデル)を用いることで、文脈からの選択と推論というCoTを生成し、推論の根拠を追跡できるようにします。
これらの2つのファインチューニンングされた言語モデルは、論理的妥当性の定義を反映した因果構造を持つように構築します。これにより、モデルの答えが、ある仮定のもとで、与えられた文脈から論理的に導かれることが保証されます。(詳しくは論文をご覧ください。)
最後にHalterモデルで答えの形式に合った出力を行います。もし答えが出力できない場合は「不明」として、もう一度SelectionモデルとInferenceモデルに選択と推論を行わせます。
Halterモデルのポイントは、「不明」と回答することを許容していることであり、これによりハルシネーションを回避することができます。(当てずっぽうに答えを出力することを回避できます。)

提案手法は、多段階論理的推論と科学的質問応答においてベースラインよりも優れていること、人間が妥当性を確認できることを確認しました。
STaR: Bootstrapping Reasoning With Reasoning (2022)
要約
モデルの判断根拠を生成するSelf-Taught Reasoner(STaR)を提案した。
内容
言語モデルの判断根拠生成は、大規模な(判断根拠を含む)データセットが必要でした。
(数学のデータセットの場合は、問題と答えだけでなく、途中式や考え方等の解法を含むデータセット)
そこで、少数の根拠例と判断根拠がないデータセットを反復的に活用し、次第に複雑な推論を行う能力をブートストラップする技術であるSelf-Taught Reasoner(STaR)を提案しました。
STaRのアルゴリズムは非常にシンプルであり、(1)(2)(3)を繰り返すことで、与えられた少数の根拠例をもとに言語モデルをファインチューニングします。
(1) 少数の根拠例から多くの質問に答える根拠を生成する。
(2) 生成された答えが間違っていれば、正しい答えを与えて再度根拠を生成する。
(3) 最終的に正しい答えをもたらしたすべての根拠で微調整する。

またSTaRでは、解決できなかった問題に対する直接的なトレーニングシグナルを受け取らないため、最終的にトレーニングセット内の新しい問題を解決できないことが分かっています。
STaRのアルゴリズムには弱点があり、それは学習最初期モデルがある程度の推論能力を持っていなければならないという点です。
研究分野への影響•関わり
STaRではモデルが根拠を自己生成できます。したがってSTaRの技術を応用することができれば、主に説明性が必要な問題に対して言語モデルの汎用性が高まります。
論文紹介:言語モデルの応用•発展
ReAct: Synergizing Reasoning and Acting in Language Models (2023)
要約
一般的な行動を伴うタスクにおいて推論(Reasoning)とタスク固有のアクション(Acting)を交互に行うことでCoTを機能させた。
内容
一般的なタスクは推論だけではなく、実際の行動が必要です。
例えば「きれいなナイフをカウンタートップに置く」というタスクが与えられたとします。
このタスクを解決するためには、ただ推論するだけでなく、実際にナイフを手に取るといった行動を計画する必要があります。
また行動によって追加で情報を得ることができます。上記のナイフの例で考えると、ナイフを手に持っているという新たな情報がモデルに追加されます。
行動から得られた情報を言語モデルが活用できるようにした手法がReasoning and Acting(ReAct)です。
ReActは推論->行動を交互に繰り返すことで、行動から得られた情報を逐次的に推論に利活用できる->質の高いCoTが可能としました。
質問応答(HotPotQA)、事実検証(Fever)、テキストベースのゲーム(ALFWorld)、ウェブページナビゲーション(WebShop)といった4つの異なるベンチマークで有効性を示しました。
研究分野への影響•関わり
この論文は、推論だけでなく、推論と行動を伴ったタスクについても言語モデルの有効性を高めたので、ロボット応用などの言語モデルの応用可能性を高めたと言えます。
Reflexion: an autonomous agent with dynamic memory and self-reflection (2023)
要約
過去の失敗を記憶している状態でタスクに再挑戦すると、その後のパフォーマンスが向上した。
内容
強化学習によってモデルの性能を向上させる技術は強力である一方で、大規模な言語モデルで実行することは(膨大な学習サンプルが必要であるため、また計算量が大きいため)難しいです。
そこで筆者らは、強化学習の考え方を用いて、言語フィードバックによって言語エージェントを強化するReflexionを提案しました。
ReflexionはActor、Evaluator、Self-Reflectionの3つの言語モデルから構成されています。
Actorは直近のフィードバック(短期記憶)とモデル全体の反省(長期記憶)をもとにアウトプットを行います。
Evaluatorは直近のフィードバックからアウトブットの品質を評価し、報酬スコアを計算します。
Self-Reflectionは、直近のフィードバックとEvaluatorからの出力を入力として、今後に役立つフィードバックをテキストベースで出力します。
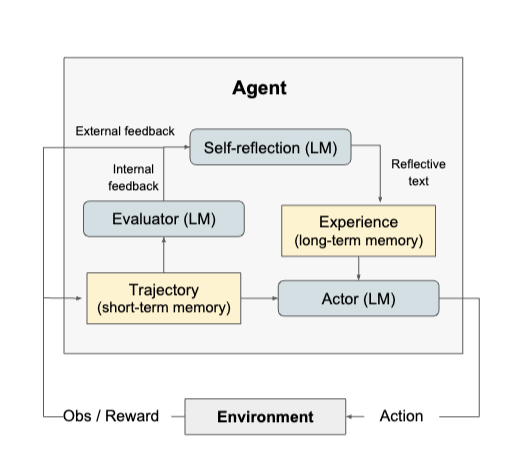
Actor、Evaluator、Self-Reflectionにより、過去の経験を生かしてアクションを選択でき、試行錯誤、内省、記憶の持続という反復的なプロセスを行うことができる。
Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP (2023)
要約
言語モデルと情報検索モデルを組み合わせた知識集約型の自然言語処理タスクを解決するための新しいフレームワークを提案した。
内容
言語モデルと情報検索モデルを使用した先行研究としてin-context learningがあります。
in-context learningとは、モデルに新しいタスクを教えるために、そのタスクの説明や例を含む「プロンプト」をモデルに与える手法です。
Translate the following English text to French: "{text}"
上記のin-context learningでは、モデルが「英語のテキストをフランス語に翻訳する」というタスクを正確に理解することを促すことができます。
言語モデルと情報検索モデルの性能を引き出すために筆者らはDemonstrate-Search-Predict(DSP)を提案しました。
DSPは、DEMONSTRATE、SEARCH、PREDICTの3つのステップから構成されています。
-
Demonstrate: 訓練データから言語モデルから望ましい動作を示すデモンストレーションを作成します。これにより、モデルは特定のタスクを解決するための方法を学習します。
-
Search: デモンストレーションをもとに複雑な問題を分解し、関連する情報を検索します。具体的には言語モデルを使用してクエリを生成し、情報検索モデルを使用して関連するパッセージを取得することによって行われます。
-
Predict: デモンストレーションと検索されたパッセージを使用して、問題の答えを生成します。
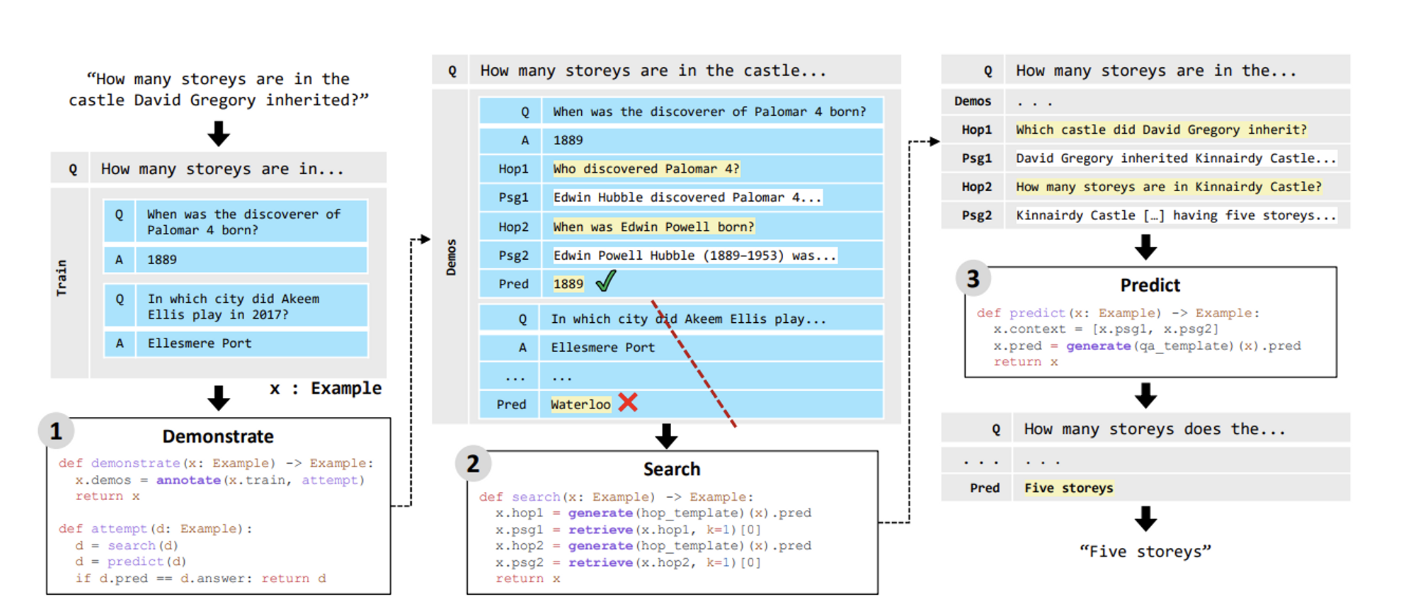
DSPは、複数の検索されたパッセージから情報を集約する能力を持っています。これにより、より広範で信頼性の高い情報を基に予測を生成することが可能となります。
DSPは既存手法であるin-context learningよりも高い精度で予測を行うことができました。
研究分野への影響•関わり
情報検索モデルにより、モデルに新しいドメインを追加できるため、言語モデルの応用性が高まりました。
Improving Factuality and Reasoning in Language Models through Multiagent Debate (2023)
要約
複数の言語モデルが複数回(ラウンド)議論を重ねることで、モデルの精度が向上した。
内容
筆者らは大規模な言語モデル(LLMs)のパフォーマンスを向上させるための新たなアプローチとして、複数の言語モデルに議論させる手法を提案しました。
議論において複数の言語モデルのインスタンスがそれぞれの応答と推論過程を提案します。議論を複数回繰り返すことで複数の言語モデルは共通の最終的な答えを導きます。
結果として、単一のモデルでなく、複数のモデルを用いた方が精度が高く、モデルの数を増やした方がより精度が高くなることが示されてました。
また言語モデルが初めて遭遇する問題に対する回答を改善するのに有効であることが示されました。
一方で、複数のモデルを用いることで計算リソースがかかる点やモデルの数を増やすほど議論の収束に時間がかかっていまう恐れがあります。
所感
今まで見聞きした効率的なプロンプトの書き方(step by step)が、なぜうまくいくかを大雑把に知ることができ、今後のプロンプト作成の参考になりました。(まだまだ理解は浅いですが、少しでもお気持ちがわかったはず。)
紹介論文は意外にもヒューリスティックなアプローチが多いなと感じました。特に答えに辿り着くまでの(推論の)中間ステップをどのように扱うかを研究の焦点にしている論文が多い印象を受けました。
我々一般人は計算リソースの観点から中々LLM系の研究に参加できませんが、LLMを少しでも効率良く扱うことはできるはずです。定期的にChatGPTを含むLLM系の論文に触れ、道具(もはや道具と言っていいのかわかりませんが)を効率的に扱う術を身につけることも大切であると感じています。
最後に、LLM系の研究に携わっている方々を応援しております!!