はじめに
2023年12月DeepMindやMeta出身の研究者が設立したMistral AIが、大規模言語(LLM)モデル「Mixtral 8x7B」をリリースしました。多くのベンチマークでGPT-3.5やLlama 2 70Bを上回る性能を持つと言われています。
Mixtral 8x7BはMixture-of-Experts(MoE)モデルを採用しています。
MoEとはモデルの中に複数のブロック(Expert)を用意しておき、入力によって適したブロック(Expert)のみを用いて推論をする手法です。Mixtral 8x7Bでは8つのExpertから2つのExpertのみを使用して推論します。
上記のMixtral 8x7Bは、通常の実装だと8つのExpertをGPU上に置いておく必要があるのでGPUのコストがかかります。
この問題を解決すべく、限られたGPU環境(例:無料枠のGoogle ColabのGPU)でMixtral 8x7Bを動かす手法を紹介した論文「Fast Inference of Mixture-of-Experts Language Models with Offloading」を紹介します。
- arXiv
- GitHub
すぐ動かしたい方はこちら
内容
本論文では以下3つの手法でMixtral 8×7Bの効率化をしています。
- Expertのキャッシュ保持
- Expertのプリロード
- 量子化
Expertのキャッシュ保持
下図はExpertがどのように使われているかを示した図であり、縦軸がExpertで横軸が入力のトークンです。青色で示したExpertは実際に使われているExpertです。(灰色は後述)
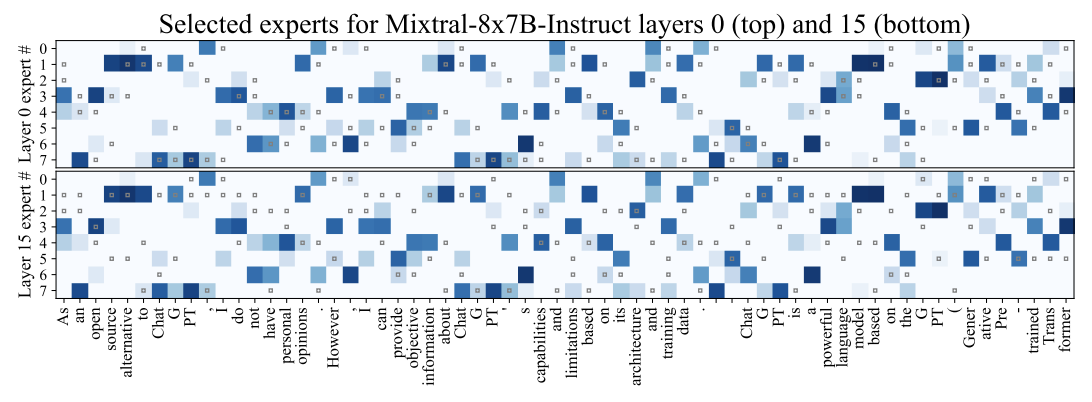
図より、各入力トークンによって異なるExpertが使われていることがわかると同時に、隣り合ったトークンで同一のExpertを使っていることが多いことがわかる。
このパターンを利用するために、本論文ではアクティブなExpertを将来のトークンのための「キャッシュ」としてGPUメモリに保持します。これにより同じエキスパートが再びアクティブになれば、即座に利用できるようになります。
キャッシュの保持の仕方としては、k個の直近使用されたExpertを常に保持するというLRU キャッシュを採用しています。
図の灰色の部分は、k=2の保持されたキャッシュを表しています。
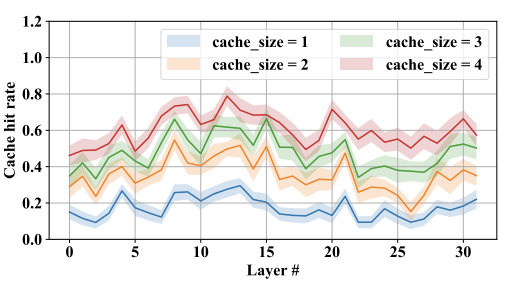
上図はLRU キャッシュのヒット率を表していてk=2,3で大体5割程度キャッシュがヒットしていることがわかります。
Expertのプリロード
上記キャッシュによってExpertのローディング時間を短縮できますが、依然キャッシュで対応できないExpertはローディングの必要があり、推論時間の大半を占めています。
MoEでは、前の層の最終出力を使って次回用いるExpertを選択することから、事前に確実にExpertをプリフェッチすることは不可能です。
しかし、何らかの手段で次のExpertを推測できればExpertをプリロードすることができます。(投機的なロード)
本論文では、次の層のゲーティング関数を前の層の隠れ状態に適用することで、次の層のExpertを正確に推測できることを発見しました。
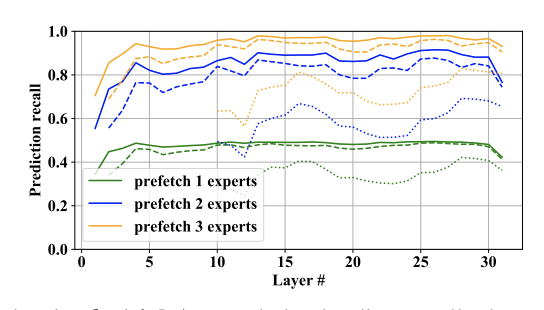
上図はプリロードのリコール(取りこぼしなくロードできたか)を示しており、実線が1層前の出力、点線が2層前の出力、ドット線が10層前の出力からExpertを予測しています。
層が手前であればあるほど、よりモデルの最終出力に近くなるので推測が容易になるためリコールが高くなります。(その分、並列処理内でプリロードできる時間が限られてしまいます。)
どの程度プリロードできるかはGPUサイズによりますが、プリロードできるExpertが1個(緑線)かつ2層前の出力を使ってもリコールが4,5割程度で、ランダムにプリロードする期待値よりは高いので効果がありそうです。
期待値の計算の仕方は2通りあって、キャッシュを保持するかしないかによって計算方法が異なります。
プリロードできるExpertを1個としたとき、
(i)キャッシュを保持しない場合だと、2/8 = 25%が期待値であり、(ii)k=2でキャッシュを保持する場合だと、キャッシュヒット率を50%として(2-1)/(8-2) = 16%が期待値となります。
つまり前の層の出力からのExpertの推測は、期待値よりも高い精度で推測できていることがわかります。(これも論文に書けば良いんじゃなかろうかと思っています。)
キャッシュの保持とプリロード1つ->キャッシュ保持をやめて、プリロードのエキスパートを3つにした方が精度が良く、時間を削減できそうですが、キャッシュ保持の方がメモリ的に嬉しそうです。(おそらく)
量子化
すべての非Expertを4bit、Expertをハーフ2次量子化(HQQ:Half Quadratic Quantization)(Badri & Shaji, 2023)で量子化しています。これによりMoEモデルの品質とサイズのトレードオフが改善されます。また1bit量子化では性能が著しく低下すると記述されています。
おわりに
いかがだったでしょうか。
2023年12月11日に公開されたMixtral 8x7bを、即座にGPUコストを小さくするという変更を加えて実験を行い、2023年12月28日に初稿をarXivへ出すという仕事の速さが怖いです。(裏で実はやっていたのかもしれませんが、)
手法自体はとてもシンプルであり、今後応用が十二分にできそうなので参考にしたいと思います。