はじめに
最近Command R+が界隈を賑わせています。
その賑わいの中でも「Command R+の日本語の応答速度が速い。」という声を良く聞きます。(半分以上X経由なので、よく聞くというよりも良く見るが近いですが、)
そこで今回はCommand R+の日本語の応答速度が本当に速いのか、なぜ速いのかについてトークナイザー観点で述べたいと思います。
ELYZA等の日本語モデルのトークナイザーとの比較実験パートもあります。
本記事では「Command R+の日本語の応答速度が本当に速いのか、なぜ速いのか」という問いについて、完璧に回答はしていません。
応答速度とトークナイザーの関係及びCommand R+のトークンナイザー
まず前提として、入力あたりのトークン数が少なければ少ないほど応答時間が短くなります。よってトークナイザーは応答速度に大いに関係します。
詳しくは以下の記事で解説しています。少しだけ述べるとトークン数縮小に伴う語彙数増加によるEmbedding層肥大化による速度遅延<<トークン数増加による速度遅延となっています。ELYZAのfastのモデルが速い理由の一つもこの理由です。
前提の説明が終わったところで、Command R+のトークンナイザーについてMistralとOpenAIとの比較が公式サイトの図があったので、こちらに添付します。
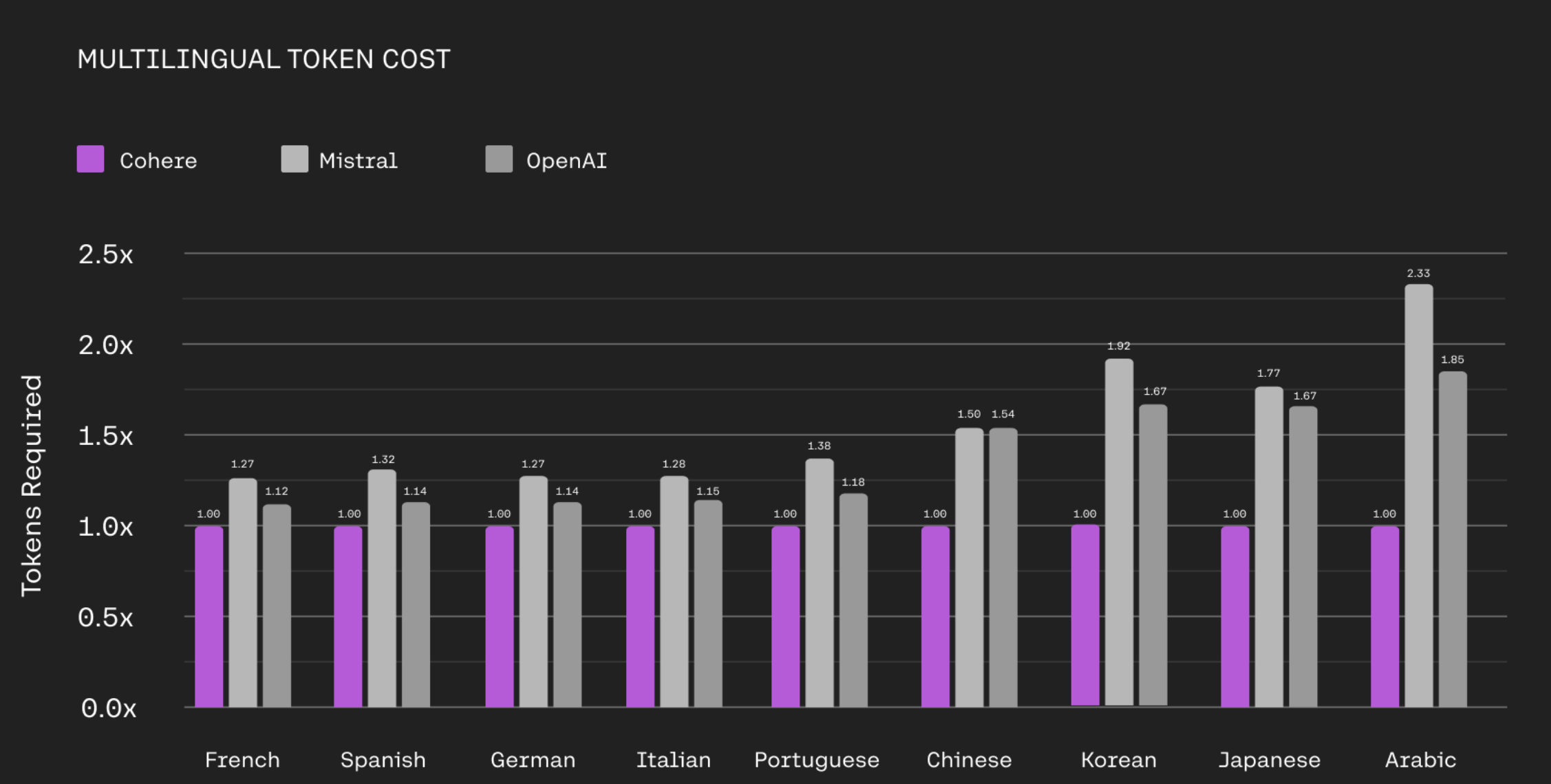
👇 引用元
少し見づらいですが、日本語における必要なトークン数(Tokens Required)はOpenAIのトークナイザーの約6割(1/1.67)であることがわかります。
これよりトークナイザーの観点からOpenAIのモデルよりもCommand R+は高速なことがわかります。
ここで記事を終わってしまったら味気ないので、実際にトークナイザーの試験を行いたいと思います。
トークナイザーの比較試験
ここではCommand R+のトークナイザーとOpenAIのトークナイザー、そして身近な例としてLLaMA2とELYZAとllm-jpのトークナイザーの比較を行います。
またCommand R+を語る上では欠かせない存在になるであろう、CohereのAyaのトークナイザーの結果も載せます。
Command R+の原著はまだありませんが、Ayaの原著論文はあるので以下に共有しておきます。
以下では語彙数およびトークン数の比較をしてみます。
語彙数の比較
まずはトークナイザーの語彙数の比較をします。
語彙数確認のためのプログラムは以下です。
# !pip install -U transformers
# !huggingface-cli login
from transformers import AutoTokenizer
# llama2
tokenizer_llama2 = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
# 日本語LLM
tokenizer_elyza = AutoTokenizer.from_pretrained("elyza/ELYZA-japanese-Llama-2-7b-fast-instruct")
tokenizer_llmjp = AutoTokenizer.from_pretrained("llm-jp/llm-jp-13b-v1.0")
# cohere
tokenizer_aya = AutoTokenizer.from_pretrained("CohereForAI/aya-101")
tokenizer_commandr = AutoTokenizer.from_pretrained("CohereForAI/c4ai-command-r-plus")
tokenizer_llama2.vocab_size, tokenizer_elyza.vocab_size, tokenizer_llmjp.vocab_size, tokenizer_aya.vocab_size, tokenizer_commandr.vocab_size
上記の結果を以下の表で示します。
| トークナイザー | 語彙数 |
|---|---|
| LLaMA2 | 32,000 |
| ELYZA | 45,043 |
| llm-jp | 50,570 |
| Aya | 250,100 |
| Command R+ | 255,000 |
上記よりCohereのAyaとCommand R+は他のモデルと比べて圧倒的に語彙数が多いことがわかります。
ただしAyaやCommand R+はマルチバイリンガルモデルなので、日本語の語彙については正当に比較できていません。ですので上記語彙数はあくまで参考の数字となります。
トークン数の比較
次にトークン数の比較を行います。
ベンチマークの文章は、そこそこ長い&難しい文章として日本国憲法の前文を採用しました。
こちらの文章から改行を取り除いた文字列をトークナイザーに入力して比較試験を行います。
text = """日本国民は、正当に選挙された国会における代表者を通じて行動し、われらとわれらの子孫のために、諸国民との協和による成果と、わが国全土にわたつて自由のもたらす恵沢を確保し、政府の行為によつて再び戦争の惨禍が起ることのないやうにすることを決意し、ここに主権が国民に存することを宣言し、この憲法を確定する。そもそも国政は、国民の厳粛な信託によるものであつて、その権威は国民に由来し、その権力は国民の代表者がこれを行使し、その福利は国民がこれを享受する。これは人類普遍の原理であり、この憲法は、かかる原理に基くものである。われらは、これに反する一切の憲法、法令及び詔勅を排除する。
日本国民は、恒久の平和を念願し、人間相互の関係を支配する崇高な理想を深く自覚するのであつて、平和を愛する諸国民の公正と信義に信頼して、われらの安全と生存を保持しようと決意した。われらは、平和を維持し、専制と隷従、圧迫と偏狭を地上から永遠に除去しようと努めてゐる国際社会において、名誉ある地位を占めたいと思ふ。われらは、全世界の国民が、ひとしく恐怖と欠乏から免かれ、平和のうちに生存する権利を有することを確認する。
われらは、いづれの国家も、自国のことのみに専念して他国を無視してはならないのであつて、政治道徳の法則は、普遍的なものであり、この法則に従ふことは、自国の主権を維持し、他国と対等関係に立たうとする各国の責務であると信ずる。
日本国民は、国家の名誉にかけ、全力をあげてこの崇高な理想と目的を達成することを誓ふ。"""
text = text.replace('\n','')
トークン数確認のプログラムは以下です。
def print_token_count(text, tokenizer):
input_ids = tokenizer(text)['input_ids']
print(f"### {tokenizer.name_or_path}\nトークンサイズ: {len(input_ids)}")
print_token_count(text, tokenizer_llama2)
print_token_count(text, tokenizer_elyza)
print_token_count(text, tokenizer_llmjp)
print_token_count(text, tokenizer_aya)
print_token_count(text, tokenizer_commandr)
OpenAIのトークナイザーのトークン数は以下のOpenAIのサイトを用いて調査しました。
トークン数の比較結果はこちらです。
| トークナイザー | トークン数 |
|---|---|
| LLaMA2 | 809 |
| ELYZA | 474 |
| llm-jp | 434 |
| Aya | 393 |
| Command R+ | 410 |
| OpenAI | 731 |
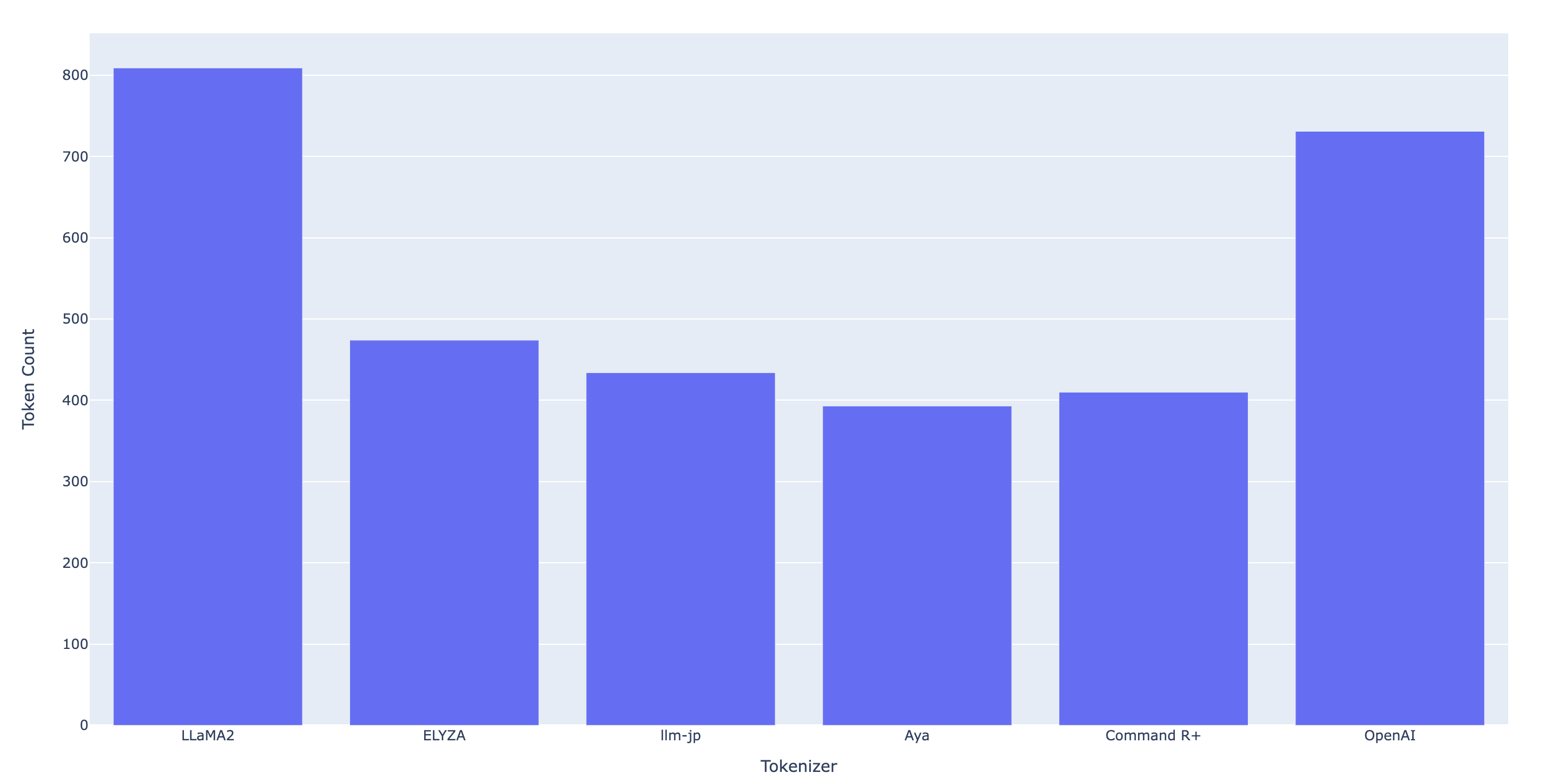
上記の結果より、CohereのAyaとCommand R+のトークナイザーは他のトークナイザーと比べてトークン数が削減できていることがわかりました。
筆者が驚いた点として日本語モデルであるELYZAやllm-jpのモデルよりもトークン数が少ないことです。
Cohereのモデルが高速な理由の一つとして実験ベースでもわかり満足したので記事を終えたいと思います![]()
おわりに
Command R+はトークナイザーもすごかった!
本記事で作成したプログラムはこちらです。
補足:LLMのモデルの応答速度の違いについて
LLMのモデルの応答速度の違いは、GPU等の環境差分がなければ以下2つの要因が考えられます。
- トークナイザーの処理
- モデルの処理(パラメータサイズや推論方法全て含める)
今回はトークナイザーの処理について着目して記事にしていますが、おそらくモデルの処理部分でもCommand R+は効率化されていると筆者は予想しています。(なぜならCohereの論文を以前調査した際に、LLMの効率化や最適化の論文が多かったからです。)
筆者はCommand R+を自由に動かす環境を持っていないので詳細な検証はできませんが、環境さえあれば実験してみたいなと思っている次第です。(弊社で検証することができれば、弊社テックブログで掲載するかもしれません。)