文字情報のみでフランス語の名詞の性を学習したニューラルネットワークモデルによって、"covid"の性を予測してみた話です。
はじめに
新型コロナウイルスはCoronavirus Diseaseの略でCOVID-19と名付けられています。そして名詞に性があるフランス語において、次の記事によるとcovidが女性名詞であると定められたそうです。(フランス語の「COVID」は女性名詞、学術機関が裁定 @cnn_co_jp )
COVIDは英語の「coronavirus disease」の略語で、フランス語にすると「maladie provoquee par le corona virus(コロナウイルスが引き起こす疾病)」と翻訳される。
「Maladie」は女性名詞なので、定冠詞は「la」を使う。従って、COVID―19も「la COVID―19」とすべきだと判断した。
略語のもともとの単語をたどって得た結論ということですが、"covid"という字面だけで考えた場合、果たしてどちらの性の名詞っぽいのか、機械学習モデルに投げてみることにしました。
フランス語の名詞の性について
How to Easily Guess the Gender of French Nouns with 80% Accuracyによると、
According to a study by McGill University, a noun’s ending indicates its gender in 80% of cases
ということで、語尾の文字のパターンによって8割は分類できるとのことで、今回の文字情報だけで予測を行うことは、ある程度妥当だと考えることとします。ちなみにフランス語でmasculineを男性、feminineを女性を意味します。
学習と予測
1単語を1つのデータとして、文字をone-hotエンコードした入力の系列をRNNに入力し、男性名詞か女性名詞かを予測するモデルを作ります。
| c | o | v | i | d | |
|---|---|---|---|---|---|
| ↓ | ↓ | ↓ | ↓ | ↓ | |
| [0010...0] | [0000...0] | [0000...0] | [0000...0] | [0001...0] | |
| ↓ | ↓ | ↓ | ↓ | ↓ | |
| RNN→ | RNN→ | RNN→ | RNN→ | RNN→ | 予測(Masc/Fem) |
データ
コーパス
REDACと呼ばれる、単語にタグ付けされているフランス語のコーパスを使用します。POS-tagged corpus [.tag.7z] (612 MB)のデータが1行ごとに、単語 \t 品詞 \t 基本形の形で記されています。解答した後、名詞(NOM)が含まれており、基本形が書かれている行のみを取り出し、ファイルに出力しています。
cat wikipediaFR-2008-06-18.tag | grep NOM | grep -v unknown | sort | uniq -i > wikipediaFR_NOM_uniq
中身はこのような状態です。
...
Acridine NOM acridine
Acrobate NOM acrobate
Acrobates NOM acrobate
Acrobatie NOM acrobatie
Acrobaties NOM acrobatie
...
https://www.keyxl.com/aaaa6c6/383/French-Accents-Alt-Codes-keyboard-shortcuts.htm によると、フランス語で用いられる文字はアルファベットのほかâäèéêëîïôœùûüÿçの41文字になるそうです。
import string
all_chars = string.ascii_lowercase + 'âäèéêëîïôœùûüÿç'
# abcdefghijklmnopqrstuvwxyzâäèéêëîïôœùûüÿç
先ほどのファイルから、これらの文字のみを含まれているもの、今回使用する単語として抽出しておきます。各列の基本形を取り出してwordsに格納しています。(単数・複数を混ぜると訓練データと評価データの分割が面倒になるためです)
import re
p = re.compile("[^abcdefghijklmnopqrstuvwxyzâäèéêëîïôœùûüÿç]")
words = []
with open('./wikipediaFR_NOM_uniq', errors='ignore') as f:
for line in tqdm(f):
word = line.split('\tNOM\t')[-1].lower().replace('\n', '')
if p.search(word) == None:
words.append(word)
名詞の性
以上によってフランス語の名詞を取り出したので、それらの性別を調べる必要があります。
https://github.com/sammous/spacy-lefff で公開されているフランス語のPOSタグ予測のライブラリを使用します。
import spacy
from spacy_lefff import LefffLemmatizer, POSTagger
nlp = spacy.load('fr')
french_lemmatizer = LefffLemmatizer()
nlp.add_pipe(french_lemmatizer, name='lefff')
doc = nlp("Apple cherche a acheter une startup anglaise pour 1 milliard de dollard")
for d in doc:
# 1単語ごとにtag_で品詞情報を得る
print(d.text, '\t\t', d.tag_)
# =>
Apple NOUN__Gender=Masc|Number=Sing
cherche NOUN__Gender=Fem|Number=Sing
a AUX__Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin
acheter VERB__VerbForm=Inf
une DET__Definite=Ind|Gender=Fem|Number=Sing|PronType=Art
startup ADJ__Number=Sing
anglaise NOUN__Gender=Fem|Number=Sing
pour ADP
1 NUM__NumType=Card
milliard NOUN__Gender=Masc|Number=Sing|NumType=Card
de ADP
dollard PROPN__Gender=Masc|Number=Sing
1単語入力したときの品詞を得る関数を作っておきます。spacy-lefffでは、男性名詞を NOUN__Gender=Masc、女性名詞を NOUN__Gender=Femと出力するようです。
def pos_of_word(word):
return nlp(word)[0].tag_
print(word_gender['voyage']) #=> NOUN__Gender=Masc
エンコードによる前処理
モデルへの入力と出力として、文字情報と名詞の性別を数値にエンコードする必要があります。まず、予測するクラスである名詞の性別ラベルをエンコードします。
import pandas as pd
def encode_label(label, labels):
return pd.get_dummies(list(labels))[label].values
all_genders = ['NOUN__Gender=Masc', 'NOUN__Gender=Fem']
gender = 'NOUN__Gender=Fem'
encode_label(gender, all_genders)
# =>
array([0, 1], dtype=uint8) # 女性名詞
続いて、単語を文字ごとにOne-hotエンコードしたベクトルの系列に変換します。41文字
をエンコードするため、1文字が41次元のベクトルとなります。
# 1文字のエンコード
encode_label('è', all_chars)
# =>
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
dtype=uint8)
# 1単語のエンコード
def encode_word(text, all_chars):
return np.array([encode_label(char, all_chars) for char in text if char in all_chars])
encode_word("apple", all_chars)
# =>
array([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=uint8)
系列パディング
今回、kerasを用いて予測を行うのですが、RNNの入力の系列長は単語の文字数となり、もちろん単語によって文字数は異なるので、入力の際に特定のマスク値でパディングして、系列長を揃える必要があります。今回、系列長を100とすることで、全てのデータ(単語)が(100, 41)のshapeのnumpy配列となります。
from keras.preprocessing import sequence
def pad_sequence(x, maxlen, value):
return sequence.pad_sequences(x.T, maxlen=maxlen, value=value).T
input_dim = len(all_chars) #=> 41
hidden_num = 100
mask_value = -1
x = encode_word("apple", all_chars)
pad_sequence(x, hidden_num, mask_value).shape #=> (100, 41)
入力データ
以上の処理をすべての単語に対して行います
x_list, y_list = [], []
for word in tqdm(set(words)):
pos = pos_of_word(word)
if 'NOUN__Gender' in pos:
gender = pos.split('|')[0]
x = encode_word(word, all_chars)
x_padded = pad_sequence(x, hidden_num, mask_value)
x_list.append(x_padded)
y = encode_label(gender, all_genders)
y_list.append(y)
len(x_list)は25666となったので、25666単語が重複なしで抽出できたことになります。
全体の7割を訓練データに、残りを評価データに回すことにします。
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(x_list, y_list, train_size=0.7)
モデル
generatorによる入力データ
入力データが(無駄に系列長を100にしたこともあって)大きくなると、バッチがメモリに乗らなくなってしまうので、kerasのfit_generatorを使った学習を行うことにしました。バッチサイズ分のnumpy配列を返すgeneratorを定義します。
参考(https://hironsan.hatenablog.com/entry/2017/09/09/130608)
class Generator():
def __init__(self, datas, labels, batch_size):
self.datas = datas
self.labels = labels
self.batch_size = batch_size
self.data_size_ = len(self.datas)
self.steps_per_epoch_ = int((len(self.datas) - 1) / self.batch_size) + 1
def generator(self):
while True:
for batch_num in range(self.steps_per_epoch_):
start_index = batch_num * self.batch_size
end_index = min((batch_num + 1) * self.batch_size, self.data_size_)
inputs = self.datas[start_index: end_index]
labels = self.labels[start_index: end_index]
x, y = encode(inputs, labels)
yield x, y
def encode(inputs, labels):
global all_chars, genders
input_dim = len(all_chars)
hidden_num = 100
x, y = np.empty((0, hidden_num, input_dim)), np.empty((0, 2))
for input_, label in zip(inputs, labels):
x_ = input_[np.newaxis, :, :]
x = np.append(x, x_, axis=0)
y = np.append(y, label[np.newaxis, :], axis=0)
return x, y
学習
kerasでRNNを構築します。
from keras.layers import Input, Masking
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import SimpleRNN, LSTM
from keras.models import Model
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
from keras.preprocessing import sequence
import matplotlib.pyplot as plt
# モデル
hidden_dim = 10
batch_size = 512
inputs = Input(shape=(hidden_num, input_dim))
mask = Masking(mask_value, input_shape=(hidden_num, input_dim))(inputs)
rnn = SimpleRNN(hidden_dim)(mask)
output = Dense(2)(rnn)
model = Model(inputs=inputs, outputs=output)
model.summary()
# =>
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_21 (InputLayer) (None, 100, 41) 0
_________________________________________________________________
masking_21 (Masking) (None, 100, 41) 0
_________________________________________________________________
simple_rnn_14 (SimpleRNN) (None, 10) 520
_________________________________________________________________
dense_21 (Dense) (None, 2) 22
=================================================================
Total params: 542
Trainable params: 542
Non-trainable params: 0
_________________________________________________________________
学習します
optimizer = Adam()
model.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=['acc'])
generator_train = Generator(x_train, y_train, batch_size)
generator_val = Generator(x_val, y_val, batch_size)
history = model.fit_generator(generator_train.generator(), generator_train.steps_per_epoch_, epochs=150, validation_data=generator_val.generator(), validation_steps=generator_val.steps_per_epoch_, shuffle=True)
lossとaccuracyは以下のような感じで、評価データで8割届かないぐらいです...
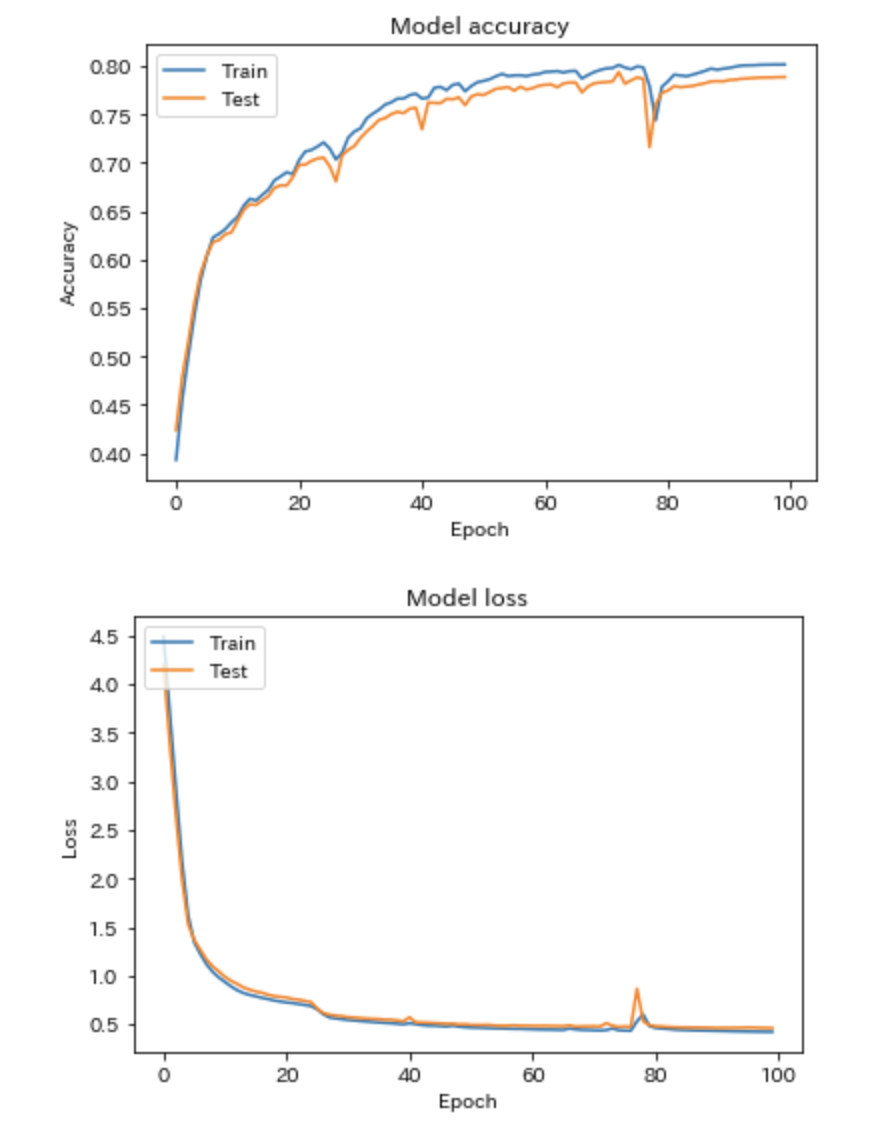
"covid"を予測してみる
ここまで少し長くなりましたが、ようやくこのモデルが"covid"をどちらの性と予測するのか、試してみます。
def predict_gender(model, word): # モデルと単語から性別を予測する
global al_chars, hidden_num, mask_value
x_target = [pad_sequence(encode_word(word, all_chars), hidden_num, mask_value)]
y_target = [np.array([0, 0])]
x_target, _ = encode(x_target, y_target)
return model.predict(x_target)
結果

np.array([1, 0])が男性名詞、np.array([0, 1])が女性名詞ということで結果的には女性名詞らしいですが、ほぼ差はありませんでした

"coronavirus"は男性名詞っぽいらしいです。
おわりに
ちなみにフランス語のGoogle検索でのヒット数的には、正式に女性名詞と決まったこともあるのか、
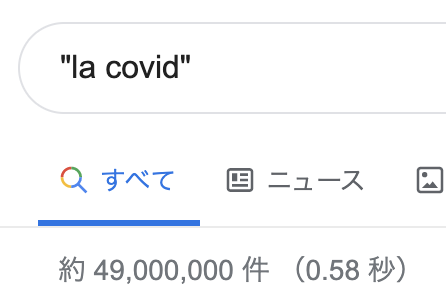

と、女性名詞の冠詞であるlaを使ったページのほうが割合的に若干多くなっていました。
人間にとっても微妙な差なので、モデル的にも微妙という結論でしょうか