はじめに
昨日がオリンピックの開会式でしたが、入場行進の国の順番がカタカナ表記の五十音順だということが少し話題になっていました
過去には2008年の北京オリンピックで「2008年北京大会でも、中国語(簡体字)による国名頭文字の画数順」だったらしいですが、日本でも1964年の東京オリンピックでは普通にアルファベット順だったらしいです
そこで入場順と開催地の言語には関係があって、各開催年(開催地)での入場順を比較してグループ化(クラスタリング)した場合にアルファベット順で入場した回とそうでない回に分かれるのではないか、と思って実験がてら調べてみました
- 実行環境
- python 3.6.5
オリンピックの情報(開催年、開催地、入場順)をWikipediaで調べる
スクレイピング用の関数を用意してwikipediaから情報を取得します
from bs4 import BeautifulSoup
import requests
def get_soup(url):
response = requests.get(url)
response.encoding = response.apparent_encoding
html = response.text
return BeautifulSoup(html, 'html.parser')
開会式のページのURL
このページの下部にあるテーブル(下の図)からWikipediaに開会式の情報がある回URLを取得します
url = "https://en.wikipedia.org/wiki/1972_Summer_Olympics_national_flag_bearers"
soup = get_soup(url)
summer_olympics = soup.select_one(".nowraplinks").select(".navbox-list")[0]
winter_olympics = soup.select_one(".nowraplinks").select(".navbox-list")[1]
celemony_urls = [tag.get("href") for tag in summer_olympics.select('a') if tag.get("class") is None]
celemony_urls += [tag.get("href") for tag in winter_olympics.select('a') if tag.get("class") is None]
celemony_urls = [url for url in celemony_urls if "closing" not in url] # closingは閉会式なのでいらない
# 後で使いたいので開会式のURLがある、夏の開催年と冬の開催年をリストにしておく
summer_years = [url.split("/wiki/")[-1].split("_")[0] for url in celemony_urls if "Summer" in url]
winter_years = [url.split("/wiki/")[-1].split("_")[0] for url in celemony_urls if "Winter" in url]
''' celemony_urlsはこのような配列
['/wiki/1952_Summer_Olympics_national_flag_bearers',
'/wiki/1964_Summer_Olympics_national_flag_bearers',
'/wiki/1976_Summer_Olympics_national_flag_bearers',
'/wiki/1980_Summer_Olympics_national_flag_bearers',
'/wiki/1984_Summer_Olympics_national_flag_bearers', ...
'''
開催年から開催地にアクセスする
https://en.wikipedia.org/wiki/Olympic_Games のテーブルから開催年と開催地の対応を取得しておきます (このとき、すでに定義した celemony_urls に含まれている開催地のみを使用します)
url = "https://en.wikipedia.org/wiki/Olympic_Games"
soup = get_soup(url)
country_by_year = {}
summer_list = soup.select_one(".nowraplinks").select(".div-col")[0].select("li")
winter_list = soup.select_one(".nowraplinks").select(".div-col")[1].select("li")
for tag in summer_list:
year, country = tag.text.split(" ")[0], " ".join(tag.text.split(" ")[1:])
if year not in summer_years: continue
country = country.strip()
country_by_year[year] = country
for tag in winter_list:
year, country = tag.text.split(" ")[0], " ".join(tag.text.split(" ")[1:])
if year not in winter_years: continue
country = country.strip()
country_by_year[year] = country
''' country_by_yearはこのような辞書型オブジェクト
{'1952': 'Helsinki',
'1964': 'Tokyo',
'1976': 'Montreal',
'1980': 'Moscow',
'1984': 'Sarajevo', ...
'''
開催年(開催地)と開会式での入場順を取得する
https://en.wikipedia.org/wiki/2020_Summer_Olympics_Parade_of_Nations では次のようなテーブルがあります。各開催年のページのこのテーブルから国ごとの入場順の数字を取得します
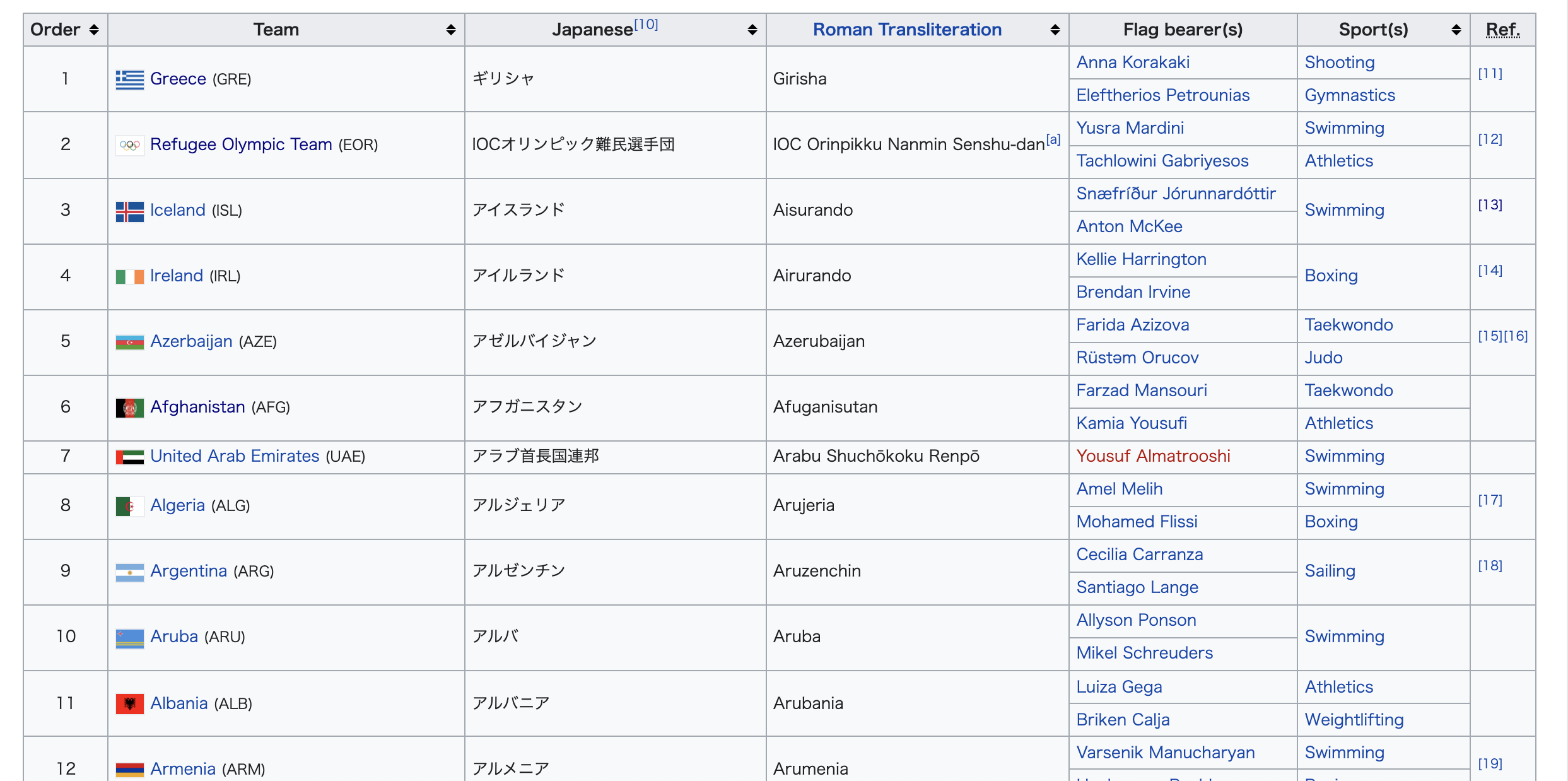
def parse_order_by_country(soup): # 引数の開催年の国ごとの入場順を辞書にして返す
order_by_country = {}
for tr in soup.select_one(".wikitable").select("tr")[1:]:
if len(tr.select("td")) < 3: continue # flag bearersのtrがrowspan=2で作られているので
order, country = tr.select("td")[0].text, tr.select("td")[1].text
country = unidecode.unidecode(country).strip()
order_by_country[country] = int(order)
return order_by_country
base_url = "https://en.wikipedia.org"
country_order_by_year = {}
for celemony_url in celemony_urls:
year = celemony_url.split("/wiki/")[-1].split("_")[0]
url = f"{base_url}{celemony_url}"
soup = get_soup(url)
order_by_country = parse_order_by_country(soup)
host_country = country_by_year[year]
country_order_by_year[f"{year}_{host_country}"] = order_by_country
''' country_order_by_yearは、開催年・地を1番目、入場国を2番目のキーにした辞書
{'1952_Helsinki': {'Greece (GRE)': 1,
'Netherlands Antilles (AHO)': 2,
'Argentina (ARG)': 3,
'Australia (AUS)': 4, ...
'''
ここまでで、各開催年(開催地)での各国の入場順が手元にある状態になりました
国の入場順から各開催年をクラスタリングする
pandasのDataFrameに先程の辞書を渡すことで、出場国✕開催年(開催地)の2次元配列が出来上がります、
import pandas as pd
df_country_order_by_year = pd.DataFrame(country_order_by_year)
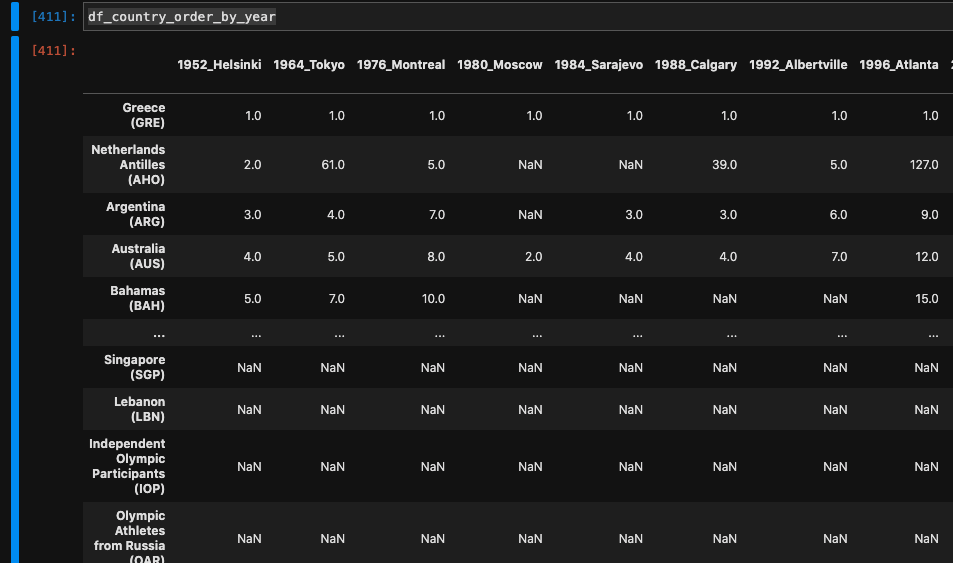
この列ベクトルを各開催年(開催地)の特徴量とすることで、開催年ごとの入場順の類似度を調べることができると考えられます。今回はこのベクトルで開催年をクラスタリングします
このデータは当然ながら欠損値が多く、(他に良い方法が思いつかないので)今回はすべての開催で出場している国の入場順を対象に調べることにします。全部で17カ国となりました
df_country_order_by_year_dropped = df_country_order_by_year.dropna()
最後にこれらのベクトルを階層的クラスタリングします
import scipy.cluster.hierarchy as hcluster
linkage = hcluster.linkage(df_sorted_index_of_country_by_year.T)
dendro = hcluster.dendrogram(linkage, labels=df_sorted_index_of_country_by_year.columns, orientation="left")
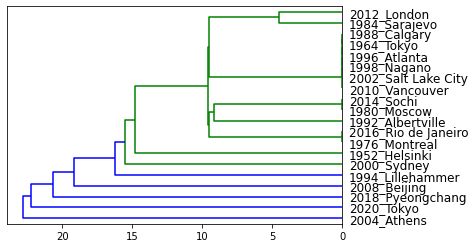
この樹形図からは、1994年(リレハンメル)、2004年(アテネ)、2008年(北京)、2018年(平昌)、2020年(東京)とそれ以外というように見えます
おわりに
残念ながらリレハンメルオリンピックは普通にアルファベット順なのですが、それ以外は
- 2004年(アテネ) : ギリシア語のアルファベット順(α、β、γで始まり、χ、ψ、ωで終わる)
- 2008年(北京) : 国名を中国語(簡体字)表記したときの画数順
- 2018年(平昌) : 朝鮮語のハングルの字母カナダラ順
- 2020(東京) : 頭文字の五十音順
ということで、アルファベット順ではない入場順がクラスタで分かれていることが分かりました(その他の回でアルファベット順ではない回があるのかどうかは調べておりません)