この記事のモチベーション
ChatGPTのAPIは叩けば叩くほど料金が嵩みます。
1回のリクエストで複数種類の回答が得られれば、APIを叩く回数は少なく済みます。複数個の回答を得たいとき、JSONであると都合がいいです。
この記事の参考元となった動画
この記事を書くにあたり、下記の動画を参考にしています。
この動画では、JSONだけではなくCSVやPydanticという形式の情報を取得する方法も紹介されていますが、この記事ではJSONのみを扱います。
参考元となった動画からのプラスアルファ
以下の項目は、参考元となった動画にはないこの記事のオリジナル要素です。
- 仮説検証:JSONの内容の順序は結果に影響を及ぼすのではないか?
- 仮説検証:日本語での出力を期待している場合でも、LangChainのOutput Parserを使うと、英語の出力が混ざるのではないか?
JSONを取り出す: Output Parserを使用しない場合
Output Parserを使用しなくても、適切なプロンプトを与えれば、JSONを取り出すことは可能です。
!pip install openai
!pip install langchain
!pip install japanize_matplotlib
OPENAI_API_KEY = "ここにあなたのキーを入れてください。"
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import openai
from langchain.chat_models import ChatOpenAI
from langchain.schema import AIMessage
from langchain.schema import HumanMessage
from langchain.schema import SystemMessage
messages = [] #ここに、GPTに送るメッセージを順に格納する。
# 役割を与える
messages.append(SystemMessage(content="""
あなたは、ブランドの命名に特化した一流のブランディングコンサルタントです。
あなたは、ユーザーから与えられた商品の情報をもとに、魅力的で記憶に残るブランド名を思いつきます。
その後、その説明と新しく生まれたブランド名に基づき、成功する可能性がどの程度あるかを1-10のスコアで評価してください。
出力は、以下のキーを持つJSON形式でフォーマットしてください:
brand_name // ブランド名
likelihood_of_success // 成功する可能性
reasoning // 成功の可能性の理由
"""))
# ユーザーからの質問
messages.append(HumanMessage(content=\
"""
商品情報: 裕福な子供たちを対象とした、新しくておしゃれなスニーカー
"""))
# AIから回答を得る。
chat = ChatOpenAI(model_name="gpt-3.5-turbo", openai_api_key= OPENAI_API_KEY)
response = chat(messages)
print(response.content)
実行結果
私が実行した結果は、以下のようになりました。
{
“brand_name”: “LuxeKicks”,
“likelihood_of_success”: 9,
“reasoning”: “LuxeKicksは裕福なイメージを持ち、子供たちにとってもおしゃれで魅力的なスニーカーブランドとして記憶に残ります。また、裕福な子供たちをターゲットにしているため、需要があり成功の可能性が高いと考えられます。”
}
これがJSONとして読み込めるか、ためしてみましょう。
import json
response_content_json = json.loads(response.content)
print(f"type of response_content_json: {type(response_content_json)}")
print(f"ブランド名: {response_content_json['brand_name']}")
print(f"成功の可能性: {response_content_json['likelihood_of_success']}")
print(f"理由: {response_content_json['reasoning']}")
私が実行した結果は、以下のようになりました。文字列がJSONとして適切な形式であるので、dict型に変換することができました。
type of response_content_json: <class ‘dict’>
ブランド名: LuxeKicks
成功の可能性: 9
理由: LuxeKicksは裕福なイメージを持ち、子供たちにとってもおしゃれで魅力的なスニーカーブランドとして記憶に残ります。また、裕福な子供たちをターゲットにしているため、需要があり成功の可能性が高いと考えられます。
このように、Output Parserを使わなくても、適切なプロンプトを送ればJSONを取得することができます。しかし、Output Parserを使う方がより簡潔です。
JSONを取り出す: Output Parserを使用する場合
Output Parserを使用すると、LangChainがGPTのようなLLMからJSONを引き出すための指示をいい感じに作ってくれます。
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
# ResponseSchemaを使い、キーの名前と、入るべき値の説明を記述する。
brand_name_schema = ResponseSchema(name="brand_name", description="ブランド名")
likelihood_of_success_schema = ResponseSchema(name="likelihood_of_success", description="1から10のスコアで示された、成功する可能性")
reasoning_schema = ResponseSchema(name="reasoning", description="スコアの理由。これは日本語で記述されなければなりません。")
# ResponseSchemaをもとに、指示を作成する。
response_schemas = [brand_name_schema,
likelihood_of_success_schema,
reasoning_schema]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
# 作成された指示
print(format_instructions)
以下のように指示が作成されます。
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing “`json” and ““`”:
“`json
{
“brand_name”: string // ブランド名
“likelihood_of_success”: string // 1から10のスコアで示された、成功する可能性
“reasoning”: string // スコアの理由。これは日本語で記述されなければなりません。
}
“`
この指示(format_instructions)をSystemMessageに組み込み、APIを叩いてみましょう。
# 役割を与える
messages.append(SystemMessage(content=f"""
あなたは、ブランドの命名に特化した一流のブランディングコンサルタントです。
あなたは、ユーザーから与えられた商品の情報をもとに、魅力的で記憶に残るブランド名を思いつきます。
その後、その説明と新しく生まれたブランド名に基づき、成功する可能性がどの程度あるかを1-10のスコアで評価してください。
{format_instructions}
"""))
# ユーザーからの質問
messages.append(HumanMessage(content=\
"""
商品情報: 裕福な子供たちを対象とした、新しくておしゃれなスニーカー
"""))
# AIから回答を得る。
chat = ChatOpenAI(model_name="gpt-3.5-turbo", openai_api_key= OPENAI_API_KEY)
response = chat(messages)
print(response.content)
結果
“`json
{
“brand_name”: “LuxKid”,
“likelihood_of_success”: “8”,
“reasoning”: “このブランド名は、裕福な子供たちを対象にしていることを示しています。Luxは「豪華」や「高級」を意味し、Kidは「子供」という意味です。また、ブランド名の短さと独自性も魅力的です。裕福な親が子供のために高品質でおしゃれなスニーカーを買うことに興味を持つ可能性が高いため、成功の可能性は8と評価されます。”
}
“`
この、バッククォートで囲まれた内容をoutput_parser.parse()に送ってやると、dictに変換してくれます。
response_as_dict = output_parser.parse(response.content)
print(f"type of response_content_json: {type(response_as_dict)}")
print(f"ブランド名: {response_as_dict['brand_name']}")
print(f"成功の可能性: {response_as_dict['likelihood_of_success']}")
print(f"理由: {response_as_dict['reasoning']}")
type of response_content_json: <class ‘dict’>
ブランド名: LuxKid 成功の可能性: 8
理由: このブランド名は、裕福な子供たちを対象にしていることを示しています。Luxは「豪華」や「高級」を意味し、Kidは「子供」という意味です。また、ブランド名の短さと独自性も魅力的です。裕福な親が子供のために高品質でおしゃれなスニーカーを買うことに興味を持つ可能性が高いため、成功の可能性は8と評価されます。
注意:得られた出力がJSONではない場合がある
Output Parserを使った場合も使わない場合も、得られた出力が期待した通りのJSONとして扱えないことがあります。
原因は、以下のようなものが考えられます。
- AIが”創造性”を発揮してしまい、予定していないキーを創り出してしまった場合
- 危険なコンテンツとして判断され、AIが回答を拒絶した場合
- JSONとして扱いたい文字列の前後に、AIが断り書きを入れてしまった場合
場合によっては、whileやtryを使って、JSONを取得できるまでリトライを行う必要があります。
仮説検証:JSONの内容の順序は結果に影響を及ぼすのではないか?
GPTは、Step-By-Stepで思考を行うようにすると、結論の精度が上がることが知られています。参考元となった動画の方法では、JSONの出力順序が、名前・スコア・理由付けの順でした。
仮に、この理由付けがStep-By-Stepと同様の役割を担うとすると、スコアの後に理由付けがあるよりも、理由付けのあとにスコアがある方が、スコアが正確になるのではないでしょうか。
商品名が固定されている場合に、スコアと理由付けの順序によってスコアにばらつきが出るか確認してみましょう。
likelihood_of_success_schema = ResponseSchema(name="likelihood_of_success", description="1から10のスコアで示された、成功する可能性")
reasoning_schema = ResponseSchema(name="reasoning", description="スコアの理由。これは日本語で記述されなければなりません。")
# スコアが先の場合の指示を作成する。
response_schemas_score_first = [
likelihood_of_success_schema,
reasoning_schema,
]
output_parser_score_first = StructuredOutputParser.from_response_schemas(response_schemas_score_first)
format_instructions_score_first = output_parser_score_first.get_format_instructions()
system_message_score_first = SystemMessage(content=\
f"""
あなたは、ブランドの命名に特化した一流のブランディングコンサルタントです。
あなたには、ユーザーが思いついた商品名と、その商品の情報が与えられます。
その後、その説明と新しく生まれたブランド名に基づき、成功する可能性がどの程度あるかを1-10のスコアで評価してください。
{format_instructions}
""")
# スコアが後の場合の指示を作成する。
response_schemas_score_last = [
reasoning_schema,
likelihood_of_success_schema,
]
output_parser_score_last = StructuredOutputParser.from_response_schemas(response_schemas_score_last)
format_instructions_score_last = output_parser_score_last.get_format_instructions()
system_message_score_last = SystemMessage(content=\
f"""
あなたは、ブランドの命名に特化した一流のブランディングコンサルタントです。
あなたはに、ユーザーが思いついた商品名と、その商品の情報が与えられます。
その後、その説明と新しく生まれたブランド名に基づき、成功する可能性がどの程度あるかを1-10のスコアで評価してください。
{format_instructions}
""")
# 高得点を期待する、ユーザーからのインプット
human_message_high = HumanMessage(content=\
"""
商品名:LuxKid
商品情報: 裕福な子供たちを対象とした、新しくておしゃれなスニーカー
""")
# 低得点を期待する、ユーザーからのインプット
human_message_low = HumanMessage(content=\
"""
商品名:歩くとピヨピヨ鳴る靴
商品情報: 裕福な子供たちを対象とした、新しくておしゃれなスニーカー
""")
# 点数を取得する関数
def retrieve_score(messages, output_parser, llm_key, model_name = "gpt-3.5-turbo", tolerance = 5):
chat = ChatOpenAI(model_name=model_name, openai_api_key= llm_key)
success = False
try_count = 0
while not success and tolerance > try_count:
try:
try_count += 1
response = chat(messages)
parsed_response = output_parser.parse(response.content)
score = float(parsed_response["likelihood_of_success"])
return score
except Exception as e:
print(e)
if try_count == tolerance:
print(f"規定の回数である{tolerance}回まで実行しましたが、JSONを取得できませんでした。")
# サンプル数100で、スコアを取得する。
messages_score_first_high = [system_message_score_first, human_message_high]
messages_score_first_low = [system_message_score_first, human_message_low]
messages_score_last_high = [system_message_score_last, human_message_high]
messages_score_last_low = [system_message_score_last, human_message_low]
high_scores_score_first = []
low_scores_score_first = []
high_scores_score_last = []
low_scores_score_last = []
for i in range(100):
print(f"{i+1}個目のスコアを取得中です。")
high_scores_score_first.append(
retrieve_score(
messages = messages_score_first_high,
output_parser = output_parser_score_first,
llm_key = OPENAI_API_KEY)
)
low_scores_score_first.append(
retrieve_score(
messages = messages_score_first_low,
output_parser = output_parser_score_first,
llm_key = OPENAI_API_KEY)
)
high_scores_score_last.append(
retrieve_score(
messages = messages_score_last_high,
output_parser = output_parser_score_last,
llm_key = OPENAI_API_KEY)
)
low_scores_score_last.append(
retrieve_score(
messages = messages_score_last_low,
output_parser = output_parser_score_last,
llm_key = OPENAI_API_KEY)
)
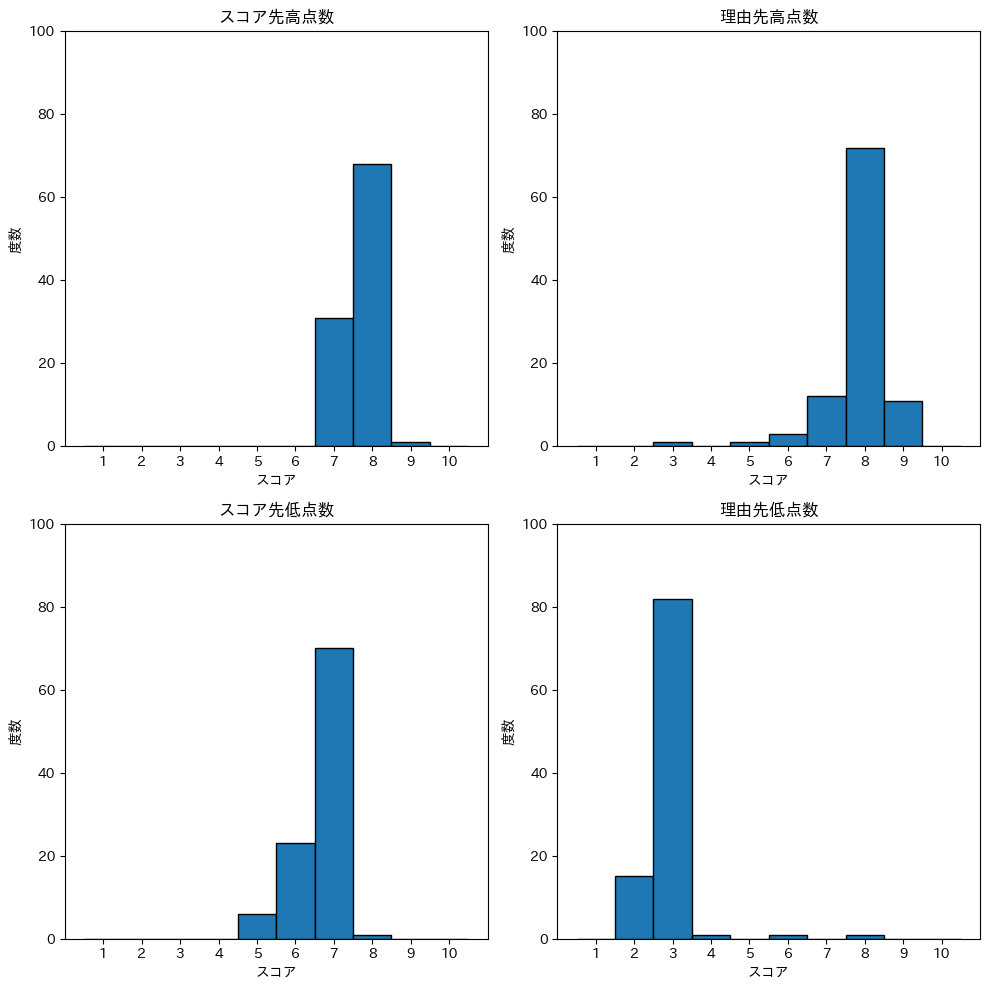
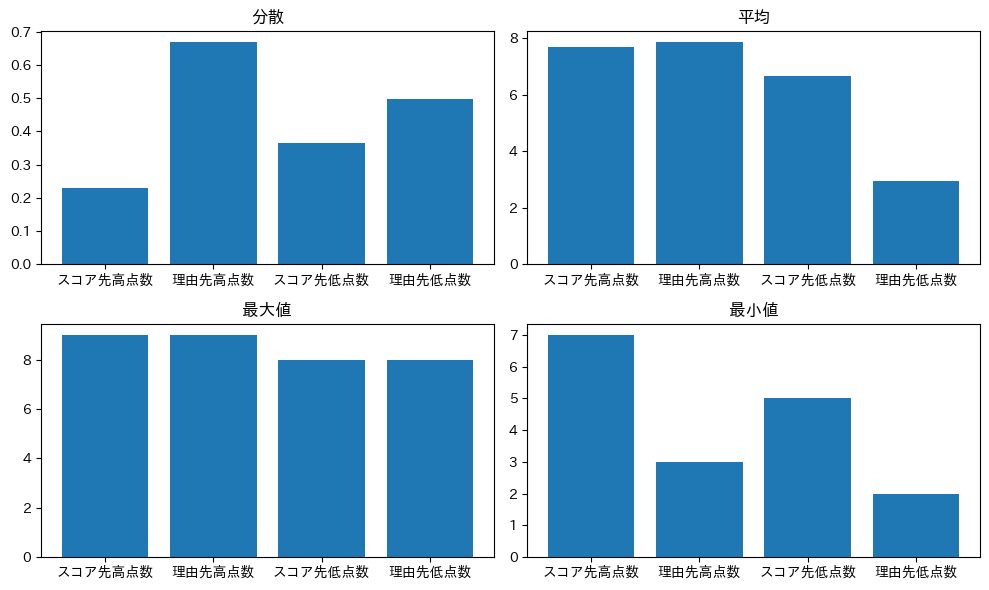
私が主張したい内容は、以下の内容です。
- ‘スコア先高点数’, ‘理由先高点数’では、’理由先高点数’の方が優位に点数が高い
- ‘スコア先高点数’, ‘理由先高点数’では、’理由先高点数’の方が優位に分散が少ない
- ‘スコア先低点数’, ‘理由先低点数’では、’理由先低点数’の方が優位に点数が少ない
- ‘スコア先低点数’, ‘理由先低点数’では、’理由先低点数’の方が優位に分散が少ない
果たして、この主張はできるのでしょうか?
結果
5%有意水準仮説検定結果
| 比較項目 | 統計量の種類 | 統計量の値 | p値 | p値と有意水準の比較 | 有意な差 |
|---|---|---|---|---|---|
| ‘スコア先高点数’と’理由先高点数’の点数 | t値 | -1.576 | 0.117 | p値 > 0.05 | 無し |
| ‘スコア先低点数’と’理由先低点数’の点数 | t値 | 39.894 | 1.34e-96 | p値 < 0.05 | あり |
| ‘スコア先高点数’と’理由先高点数’の分散 | Levene検定統計量 | 0.321 | 0.572 | p値 > 0.05 | 無し |
| ‘スコア先低点数’と’理由先低点数’の分散 | Levene検定統計量 | 1.798 | 0.181 | p値 > 0.05 | 無し |
結果としては、低点数のスコアを出力させる場合のみ、理由をスコアよりも先行させることに有意な差が見られました。
仮説検証:日本語での出力を期待している場合でも、LangChainのOutput Parserを使うと、英語の出力が混ざるのではないか?
Output Parserを使用すると、GPTのようなLLMからJSONを引き出すための指示をいい感じに作ってくれると先述しました。
しかし、その記述は英語です。GPTは英語で入力した場合は英語を、日本語で入力した場合には日本語をアウトプットとして返してくれます。
それでは、Output Parserを使って日本語・英語混じりでプロンプトを送った場合、返ってくるJSONが英語になってしまうことはないのでしょうか?
気づかれた方はいるかも知れませんが、ここまでに使っていたプロンプトでは、”これは日本語で記述されなければなりません。”というおまじないをつけていました。
そのおまじないを取り払ったとき、果たして英語で出力されてしまうのでしょうか? 試してみましょう。
# ResponseSchemaを使い、キーの名前と、入るべき値の説明を記述する。
brand_name_schema = ResponseSchema(name="brand_name",
description="ブランド名")
likelihood_of_success_schema = ResponseSchema(name="likelihood_of_success",
description="1から10のスコアで示された、成功する可能性")
reasoning_schema = ResponseSchema(name="reasoning",
description="スコアの理由。")
# ResponseSchemaをもとに、指示を作成する。
response_schemas = [brand_name_schema,
likelihood_of_success_schema,
reasoning_schema]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
# 役割を与える
messages.append(SystemMessage(content=f"""
あなたは、ブランドの命名に特化した一流のブランディングコンサルタントです。
あなたは、ユーザーから与えられた商品の情報をもとに、魅力的で記憶に残るブランド名を思いつきます。
その後、その説明と新しく生まれたブランド名に基づき、成功する可能性がどの程度あるかを1-10のスコアで評価してください。
{format_instructions}
"""))
# ユーザーからの質問
messages.append(HumanMessage(content=\
"""
商品情報: 裕福な子供たちを対象とした、新しくておしゃれなスニーカー
"""))
# AIから回答を得る。
chat = ChatOpenAI(model_name="gpt-3.5-turbo", openai_api_key= OPENAI_API_KEY)
response = chat(messages)
print(response.content)
"reasoning": "The brand name 'WealthyKicks' effectively communicates the target audience of affluent children while also capturing the stylish and fashionable aspect of the sneakers. The combination of 'Wealthy' and 'Kicks' creates a memorable and aspirational image that appeals to both parents and children. The brand name has a strong potential for success as it aligns with the target market and conveys the desired brand attributes."
Output Parserを使ってJSONを取得しようとする場合には、「日本語で出力してください」というおなじないは必要だと結論づけられるでしょう。
結び
この記事では、GPTからJSONを取得する方法を紹介しました。一つは、自分でプロンプトを記述する方法、もう一つは、LangChainのOutput Parserを使う方法です。
JSONを取得する際には、そのJSONの情報の順序によって結果が変わりそうです。また、Output Parserを使うと、おまじないなしでは結果が英語で返ってきてしまいます。
ちなみに、使用するモデルがgpt-3.5-turbo-0613やgpt-4-0613のようなfunction callingに対応しているものの場合、おまじないなしでも日本語でJSONを取得することができます。