はじめに
今年のre:Inventでは様々なサービスが発表されました。その中でもAI系のサービスが3つリリースされましたが、今回は画像認識サービスのRekognitionをLINE Bot上で実装してみたという話です。
Rekognitionとは
下記機能を有した画像認識サービスです。
- 物体およびシーンの検出
- 顔の分析
- 顔の比較
様々なプログラミング言語にSDKとして提供されているため、非常に簡単に利用することが出来ます。コンソールからGUIで試してみれるので、AWSアカウントをお持ちの方は試してみてもいいかもしれません。
料金は、はじめの1年間は5000Imageまで無料。無料期間が終わるか、5000を超えた場合、1000Imageあたり$1
です。
ちなみに、Recognitionではなく、Rekognitionです。re:Inventに参加中の上司から「Rekognition試してみて!」とLINEが飛んできていて、スペル間違ってるやんとか思ってましたが、Rekognitionであっているようです。ご注意を。
構成
今回のシステム構成はこんな感じ。
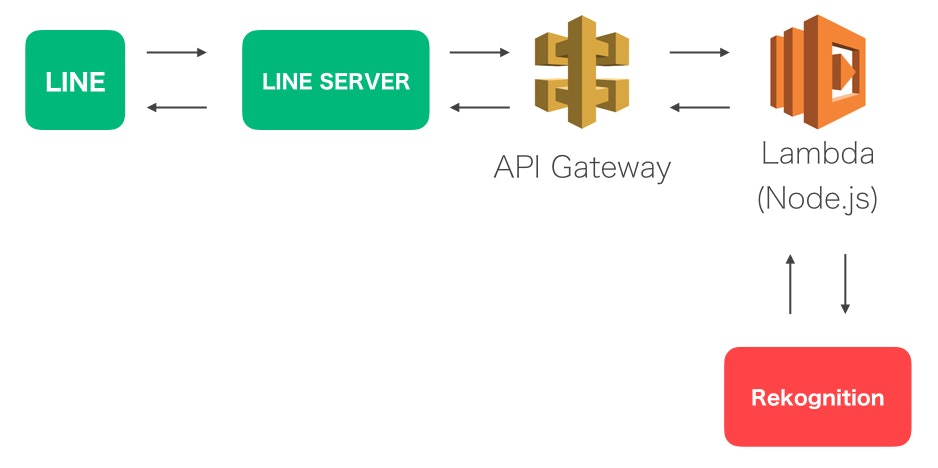
LINE Botに対して画像を投げると、APIGWのエンドポイントへフックしてくれるので、Lambdaへ流して、Lambda側で画像のダウンロード、Rekognitionとのやりとりをし、結果を人が見やすい形にして返します。
LINE Botの設定については、このへんからMessaging APIへいってなんかすれば作れると思います。簡単なので自分でやってください。
Lambdaの処理
Rekognitionを利用するためにaws-sdkを利用します。Lambdaでは標準で備わっているライブラリなので、(Nodeの場合だと)npm install aws-sdkしなくていいはずでした。ですが、2016/12/9現在ではLambda内のJS版aws-sdkがまだ最新になっていないそうなので、自分でaws-sdkの最新版取ってきてパッケージングしてLambdaにあげるか、PythonならBlue Printが用意されてるのでそっちを使ってもいいかもしれません。リージョンはRekognitionが使えるリージョンにしてください。僕はus-east-1を使いました。
やっつけで書いたのでコードが汚いのは勘弁してください。ちなみに、APIGWとLambdaのデプロイ等々はSERVERLESSフレームワークを使いました。もし利用される方はこの記事を参考にしてください。
Messaging APIが発表されたタイミング(2016/9末くらい?)でも1度Botを作っているのですが、そのときにはMessaging APIを簡単に使えるライブラリが揃っていませんでした。今回調べてみると、line-messagingが使えそうだったのでこれを使いました。簡単。
'use strict';
var AWS = require("aws-sdk");
var rekognition = new AWS.Rekognition();
var LINEBot = require('line-messaging');
var bot = LINEBot.create({
channelID: 'your id',
channelSecret: 'your secret',
channelToken: 'your token'
});
const res = {
statusCode: 200,
headers: {},
body: JSON.stringify({
message: 'Go Serverless v1.0! Your function executed successfully!'
}),
};
module.exports.handler = (event, context, callback) => {
var events = JSON.parse(event.body).events;
// LINEBotは同時に複数のメッセージが投げられることがある
events.forEach(function(incident, index, array) {
if (incident.type == "message") {
switch (incident.message.type) {
case "image":
// 画像をバイナリで取ってくる
bot.getMessageContent(incident.message.id).then(function(data) {
var buf = new Buffer(data);
var param = {
Image: {
Bytes: buf
}
};
// 物体、シーン分析
rekognition.detectLabels(param, function(err, data) {
if (err) {
console.log(err, err.stack);
} else {
console.log(JSON.stringify(data));
var mes = "";
// たくさんLabelが貼られるはず
data.Labels.forEach(function(label) {
mes += label.Name + ": " + Math.round(label.Confidence) + "\%\n";
// 人を検出した場合のみ顔分析もする
if (label.Name == "Person") {
param["Attributes"] = ["ALL"];
// 顔分析
rekognition.detectFaces(param, function(err, data) {
if (err) {
console.log(err, err.stack);
} else {
console.log(JSON.stringify(data));
data.FaceDetails.forEach(function(detail) {
var message = makeMessageFromFaceDetail(detail);
// replyTokenは1回のみ有効だったはずなのでPushするしかない
bot.pushTextMessage(incident.source.userId, message);
});
}
});
}
});
mes = mes.replace(/\n+$/g, '');
bot.replyTextMessage(incident.replyToken, mes).then(function(data) {}).catch(function(err) {});
}
});
}).catch(function(err) {
});
break;
default:
}
}
});
}
function makeMessageFromFaceDetail(data) {
var mes = "";
mes += "Gender: " + data.Gender.Value + " " + Math.round(data.Eyeglasses.Confidence) + "\%\n";
mes += "Eyeglasses: " + data.Eyeglasses.Value + " " + Math.round(data.Eyeglasses.Confidence) + "\%\n";
mes += "Emotions: " + data.Emotions[0].Type + " " + Math.round(data.Emotions[0].Confidence) + "\%\n";
mes += "Smile: " + data.Smile.Value + " " + Math.round(data.Smile.Confidence) + "\%\n";
mes = mes.replace(/\n+$/g, '');
return mes;
}
LINE Botにこじるりの写真を投げてみました。
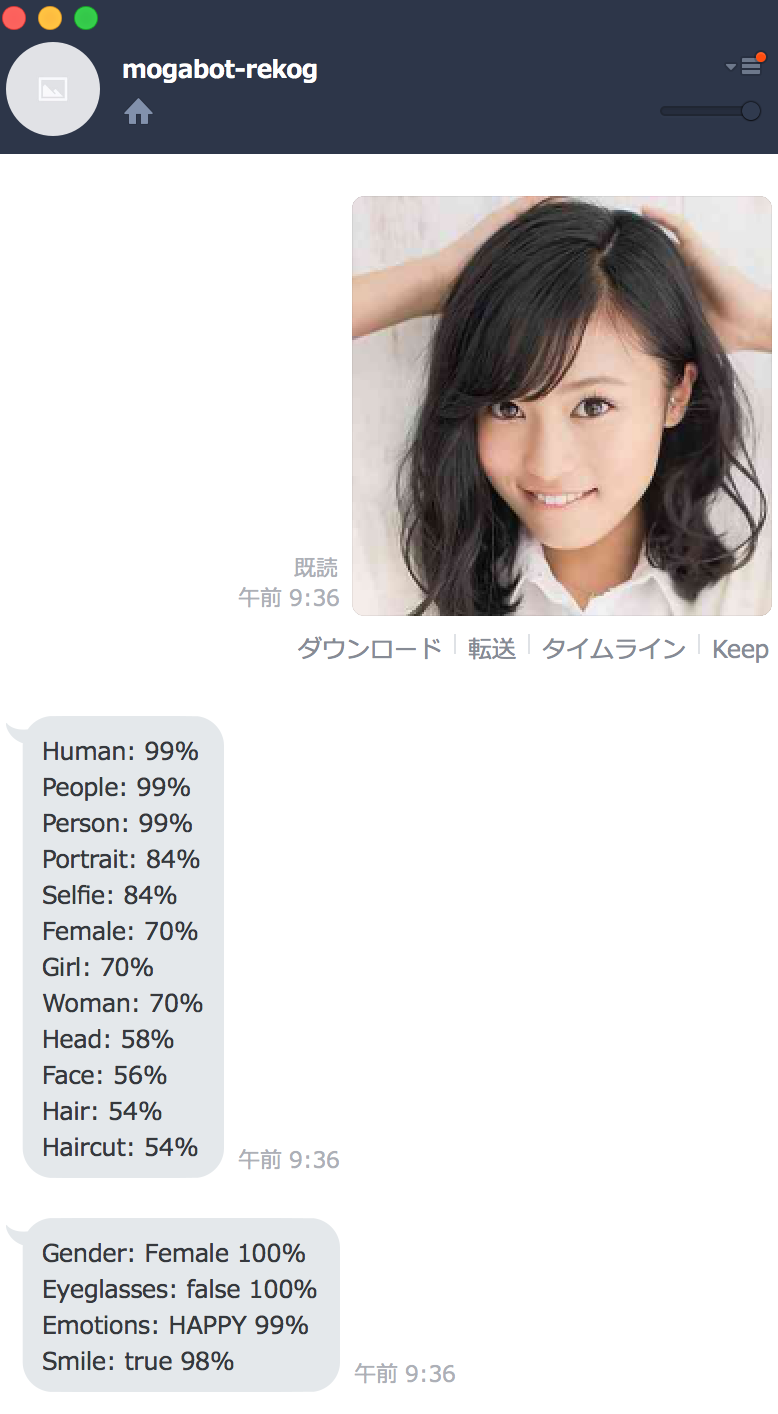
ちゃんと動作しているっぽいですね。
所感
物体およびシーンの検知(detectLabels)
利用方法によってはなかなか便利な機能だと思います。あらかじめ画像を加工して渡すとより得たい結果が得やすくなりそうです。
ためしに料理の写真を試してみたのですが
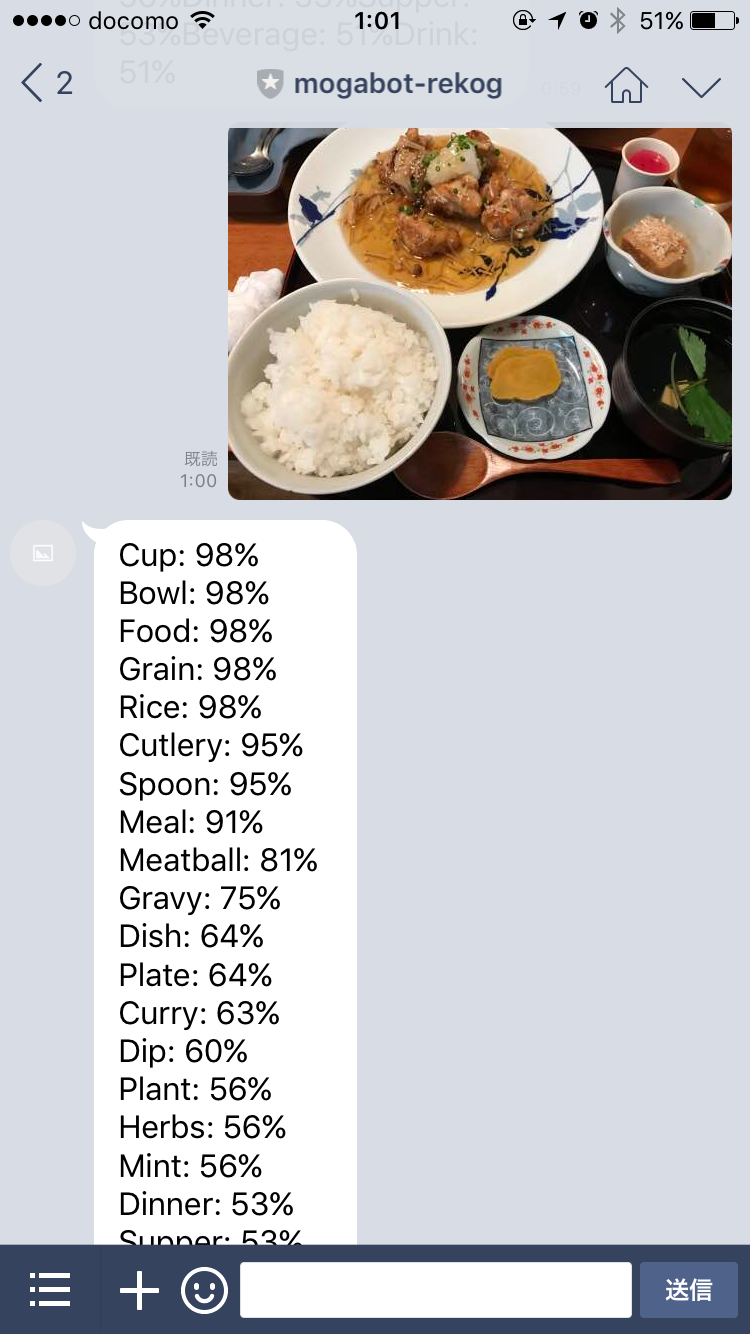
定食などの日本っぽい食事はなかなか対象が多く、小さいものが多いので認識させるのは難しそうです。
ピザの写真とかだとPizza: 99%とかなるので、1品ものの料理とかは認識させることができそうです。
当たり前ですが、Labelは英語で返ってくるので、日本人にわかるように返そうと思うと和訳する必要があり、少々手間ですね。
顔の分析(detectFaces)
これはなかなか精度が高そうですね。取れる特徴が予め決まっているみたいで、髭があるかとかもとれます。
顔の比較
実装してません。コンソールで試してみましたが類似度が取れます。ただ、ビジネスで何に使えるのかが全く思い浮かばない。顔認証とか?
まとめ
RekognitionをLINE Bot上に実装してみた話でした。精度上、実用するにはかなり限定的に使う必要がありそうですが、とにかく簡単に利用できることが1番のメリットではないでしょうか。
今後どんどん精度が上がっていくサービスになりそうなので、非常に楽しみですね。
おわり