kubernetesで使われるhelm(https://github.com/kubernetes/helm) というツールに関して、社内でのCI/CDでの使われ方がしっくり来なかったけど、果たしてどうするのがいいんだろう?ってのが分からなくて色々調べたり考えたりしてみたメモです。タイトルの通り、結論はまだありません。。
何が分かってないか
container / k8sの利点の一つに、containerのimageを各開発チームが準備すれば、色んな種類のアプリケーションを同じように扱える、k8s等のcontainer managementシステムを使うことでリソースを有効活用しやすくなるといった点があると思います。
前者の利点によって、cluster自体の管理はops、devは浮かべたいものをcontainerで準備すればOK、くらいの感じで、dev/opsの線引きがいい感じに分離できたのですが、その間を繋ぐdeploymentってどうすればいいの??ってのが、運用が深まるにつれて疑問に思うようになってきました。
現状、k8sに何かをdeployする時はhelmが一般的に使われていて、社内でも使っているけど、なんかしっくりこないなーと。自分たちがhelmを上手く使いこなせていないのか、helmというツール自体の意図と合っていないのか、その辺もよく分からなくなってきたという感じです。
helmとは
色々と紹介記事/資料があるので、さらっと触れるだけにしときますが、linuxにおけるyumやapt-getのような、kubernetesにおけるpackage managerってのが、ざっくりと分かりやすい説明かなと思います。
helmのしっくり来やすいところ
helmをyumのようなpackage managerって考えて、yum install するようにkubernetesに向けてhelm installする。これは分かりやすい。そして、yum repositoryに色んなpackageが集まるように、ここ(https://github.com/kubernetes/charts) に色んなpackageが集まる。これも分かりやすい。そして、yumでちょこちょこっとインストールするように、公開されているミドルウェア等をk8s上でちょっと試したいっていう時には超便利。
helmのしっくり来にくいところ
外向けに公開しない、自分たちのアプリケーションのCI/CDを絡めての浮かべ方。
結局、最終的には、helmをちゃんと理解して、自分たちの要件に合わせてどういうフローを構築するか考える、、っていう当たり前の事に集約されると思うし、冷静に考えればデプロイフローを作る時の共通の課題ではある。でも、中々しっくり来なかったのは、tutorial等でyum的なhelmを経験した後に、自分たちのアプリケーション用のCI/CD に組み込むって所を改めて考えるのが、helm自体がこれまでのデプロイツール(e.g. ansible, capistrano)とは守備範囲が少し異なり、そこの頭の切り替えが難しかったりってのがあるのかなーという気がした。
てなことを、あれこれ考えている中で、この辺がややこしいのかなーと思ったポイントは以下(kubernetes/helmを知っていく中で増減しそうな気はする)。
- helmはあくまで"package manager"なんだけど、kubernetes上に何かをサクッと浮かべれるというtutorialでの経験から、自分たちのアプリケーションでもこれが簡単に出来るんだと錯覚してしまう。
- 外部公開するミドルウェアやライブラリのリリースサイクル/リリースに対する要件と、内製のアプリケーションのリリースサイクル/リリースに対する要件は当然大きく違うのに、
kubernetesという共通項に目くらましされて同じように使えるツールなんだと勘違いしてしまう。 - (他社の ansible / capistrano 事例見て、参考にはできるだろうけど、このままサクッと自分たちに使えるーとは恐らく思わないはず。)
- 外部公開するミドルウェアやライブラリのリリースサイクル/リリースに対する要件と、内製のアプリケーションのリリースサイクル/リリースに対する要件は当然大きく違うのに、
- 旧来のansible等を使ったデプロイは、対象サーバに対して同一のアプリケーションをばら撒く形だったが、helmではreplicasの設定等、アプリケーション全体の構成を意識する必要がある
- serviceでのport設定や、deploymentのreplicas数等々
- 場合によっては
affinityなどで、他アプリケーションとの関係も気にしたり - k8s導入で線引きできていたはずのアプリケーション開発者とcluster管理者の境目が曖昧に
- 利用するdocker imageのversioningどうするか(latest / version tag / commit hash等)? - サーバにソースコード自体をpush/サーバがpullする場合はgitのversioningがあるけど、kubernetesで動かすdocker imageの場合は何か仕込まないと、どのversionが動いてるのかよく分からなくなる - gitの履歴とimageのtagに何か関連付けが欲しくなるけど、image作成時と`helm install`のタイミングで同じ値を引き回す必要があって、地味に面倒で、フロー全体をちゃんと考えないといけない。 - helm is package manager って思ってるので、何となく、この辺いい感じにやってくれるのかと思いきや、微妙に守備範囲が違う。外部公開するアプリケーションに関してはversiongのフロー自体が別途確立されているのでhelmと組み合わされやすいけど、内部のCI/CDではversioning/packagingとdeployが密結合なことが多く、helmがカバーしてくれないversiningの所をどうするかってのをかっちりと考えないといけない
- 複数アプリケーションで共通の設定 vs アプリケーションを出来るだけ独立させたい - kuberntes上には複数のアプリケーションが乗っかるので、共通の`configMap/secret`を利用したくなる。 - 一方で各アプリケーションは独立してinstallされるものであり、この差異を吸収するためにデプロイ手順や運用手順が煩雑化する。逆に全部独立させると、同じ値を設定すべきconfigなのに差分が出てしまうという懸念がある - これまた、アプリケーション開発者とcluster管理者の境目が曖昧に - (この問題自体はどんなツールを使っていてもあるけど..) というような課題に何となく気付き始めた所で、先駆者達はどのようにやってるかなーとあれこれと見てみたので、参考になりそうなモノとその概要を紹介。ただ、最初に書いた通り、結論はまだないので、これに沿ってやればOKみたいなのはないです。
答えを見つけるのに参考になりそうなプレゼン/資料
A Newbie's Onboarding to Helm
Helm Summitでのプレゼン。Helm Newbieから初めて、つまづくポイントを切り分けてくれている。自分の中で中々うまく言語化できなかったところを綺麗に言語化していて、さすがGoogleのCustomer Engineerだなーと。CREの真髄を少し垣間見た気がする。こういう人が寄り添ってくれれば、新しい技術の導入に対するディスカッションもしやすいだろうな。
ただ、"Helm Summitの発表でこの辺の取り組み方が紹介されててgreatだ!"って感じな締めで、何か具体策を示してくれるわけではない。


OverHelmed
同じくHelm Summit のプレゼン。helmでこうしよう!っていうんじゃなくて、自前のツールの紹介を初めてて、すぐに取り込めるーって感じではないけど、このような場に出てくる人でも似たような問題意識がある人がいるって分かって勇気付けられるw
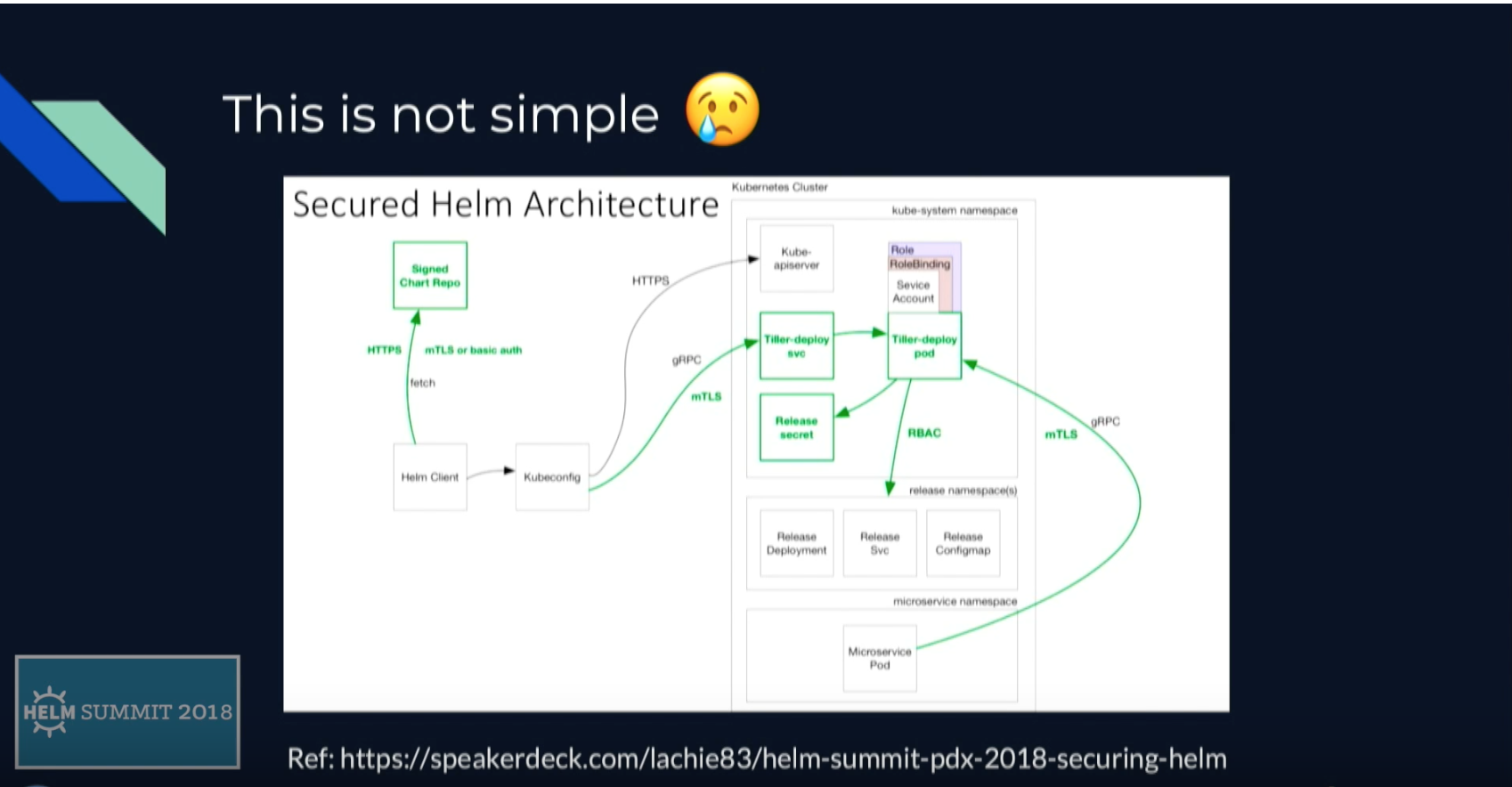
Helm Chart Patterns
2017年のNorth AmericaでのKubeconでのプレゼン。CI / CDの文脈はないけど、自分でChartを作るときに見ておくと良さそうと思った動画。色んなのを公式Chartをみるプラスで、こうやってまとめてくれてるのを見たら腹落ち度が増しそう。
この中で紹介されている、confgMap変わった時にpodも入れ替える話は、ここにも書かれてました。
https://github.com/kubernetes/helm/blob/master/docs/charts_tips_and_tricks.md#automatically-roll-deployments-when-configmaps-or-secrets-change
Delve into Helm: Advanced DevOps
- プレゼン
- 資料
- ソースコード
2017年のEuropeでのKubecon でのプレゼン。一般的なCI/CDの構成をhelmを使ってやりきっているので、参考になる所は多いと思う。デモも完成度が高くて、とても良かった。自社の既存のリリース/デプロイフローとこの例を付き合わせていくことで、自分たちのやるべきフローが見えてくるのかもしれない。
そして、jenkinsってこんなに進化してるってのを初めて知った。.travis.yamlのようにJenkinsfileってのをリポジトリに置いとくと、それをよろしく実行してくれるので、jenkinsはステートレスにできると。
このデモではjenkinsの中に色んな情報を埋め込んでいる。
https://github.com/lachie83/croc-hunter/blob/37b3cb191d9a3b4368a215e09ef242298b0a115b/Jenkinsfile#L130
https://github.com/lachie83/croc-hunter/blob/37b3cb191d9a3b4368a215e09ef242298b0a115b/Jenkinsfile#L164

One Chart to Rule Them All
- プレゼン
- 資料
2017年のNorth AmericaでのKubeconでのプレゼン。がっつりhelm使ってCI/CDやってるぜ!と。中々実際の事例を絡めた話はなかったので、これはとても貴重。
この会社では、最初は各チーム毎にバラバラにChartを作っていた(v1)けど、共通のChartのtemplateを準備して、各チームはvalueだけを指定するようにした(v2)と。Consは特にないぜって言ってて、先にしっくりこない点の一つにあげたdev/opsの線引きも明確になるし、いいことづくめに聞こえるこけど、後半に紹介される共通のtemplateってのを見ていると、これを管理するのが辛そうだー、、って思った。
まあ、バラバラに管理してると、v1のconsに上げられているように、違う辛みもあるので、どこでどう苦労するかってのを自分たちのニーズに合わせて決めるってことかな。

まとめ
helmのしっくりこなさについてあれこれ考えたり、改めて様々な発表を見直したりして見ました。まだ、自分の中の結論は出てないけど、何となく整理すべき点は見えてきたような気がする。うちらはこんなイケてるやり方だぜ!ってのがあったら、是非、教えてもらいたいです。
Happly helming!