はじめに
本田技研工業でアプリ開発を担当している松村です。
先日、社内でAWSDeepRacerを使用したレース大会があり、
自身が所属する「デジタルラボ」の有志で参加しました。
AWSDeepRacerとは
クラウドベースの 3D レーシング シミュレーターと強化学習によって駆動する完全自律型の 1/18 スケール レースカーを通じて、機械学習を実際に体験できるサービス
参照:https://aws.amazon.com/deepracer/
大会の概要
- 3人1組の計14チームのトーナメント戦
- 実際のレーシングカーモデルでレース
- コースはAtoZを使用
- 予選と本戦の2部構成で開催
- ルール
- レーシングカーを2分間コースを走らせ続けて1周毎のタイムを計測
- 2分間のうちのコースアウトしなかった最速のタイムを記録として登録
- コースアウトした場合はコースアウトが発生した箇所に戻してレースを再開
大会までの道のり
-
とりあえず3Dシミュレータを使って擬似レースを実効してみる
- 最初はサンプルコードを実行
-
def reward_function(params): ############################################################################# ''' これは all_wheels_on_track(全ての車輪がトラック上にあるか)と speed(速度)を使った シンプルな報酬関数の例 ''' # 入力パラメータを取得 # すべての車輪がトラック上にあるかどうか(True/False) all_wheels_on_track = params['all_wheels_on_track'] # 現在の速度(float) speed = params['speed'] # この値を基準として、遅すぎる場合にペナルティを与える SPEED_THRESHOLD = 1.0 if not all_wheels_on_track: # 車がトラック外に出た場合、非常に小さな報酬を与える reward = 1e-3 elif speed < SPEED_THRESHOLD: # 車が遅すぎる場合、中程度の報酬 reward = 0.5 else: # トラック上にあり、かつ十分な速度で走行している場合、高い報酬を与える reward = 1.0 # 報酬値を返す(DeepRacer が学習に使用) return float(reward)
-
- 学習中に出力される動画のスクショ
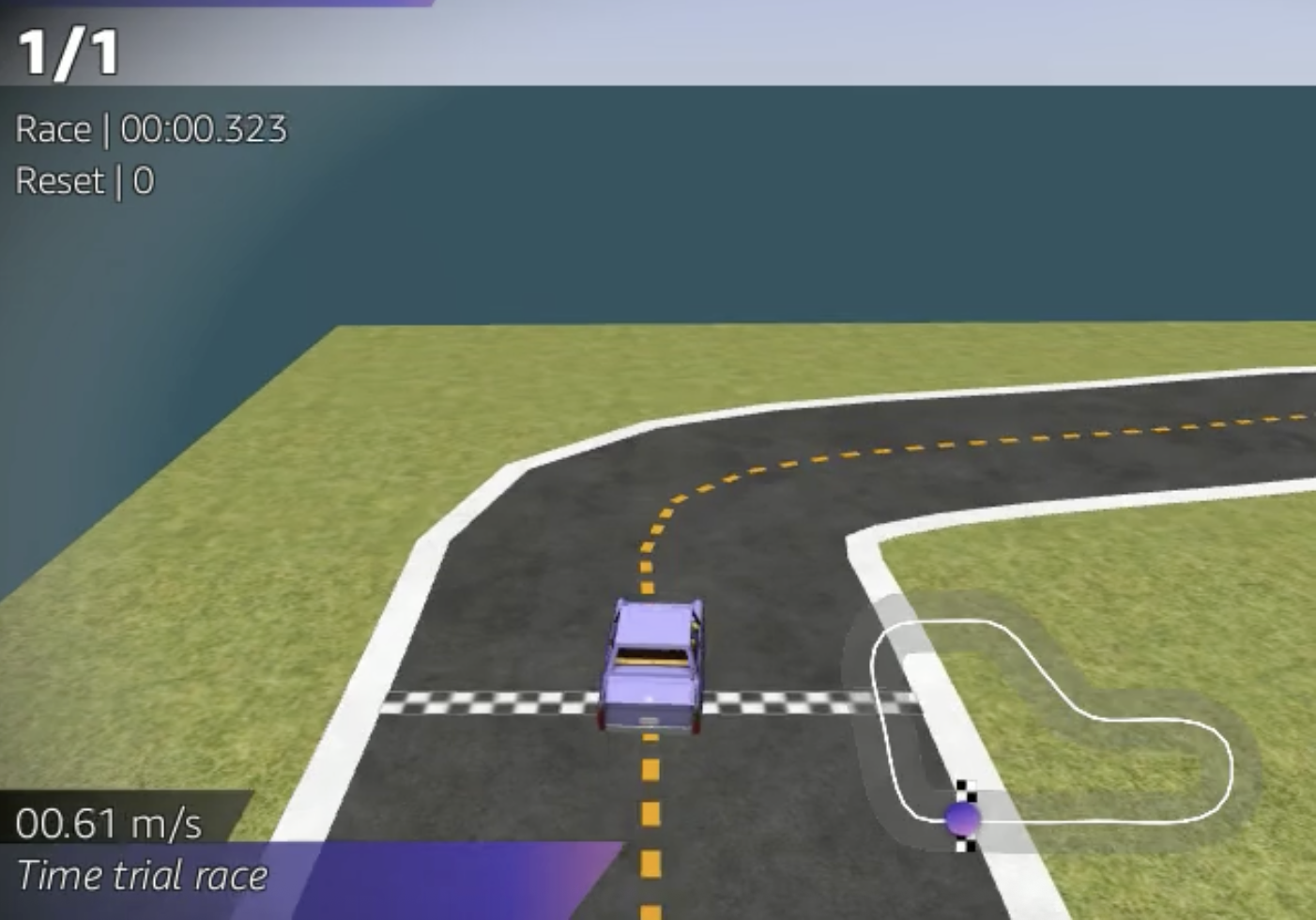
- 学習のベースコースは大会で使用される「AtoZコース」を使用
- 最初はサンプルコードを実行
-
強化学習の精度を高める
-
報酬関数の使い方を考える
- サンプルコードから報酬関数をいかにうまく使うかが勝負のポイントと理解
- 使用できるパラメータから学習内容を考える
- パラメータ一覧
パラメータ名 説明 all_wheels_on_track 全ての車輪がトラック上にあるかどうかを示すフラグ。True の場合、車両はトラック上にあります。 x, y 車両の現在位置の x および y 座標(メートル単位)。 closest_objects 車両に最も近い2つのオブジェクトのインデックス。 closest_waypoints 車両の現在位置に最も近い2つのウェイポイントのインデックス。 distance_from_center 車両がトラックの中心からどれだけ離れているか(メートル単位)。 is_crashed 車両がクラッシュしたかどうかを示すフラグ。True の場合、クラッシュしています。 is_left_of_center 車両がトラックの中心線の左側にあるかどうか。 is_offtrack 車両がトラック外に出たかどうかを示すフラグ。True の場合、トラック外にいます。 is_reversed 車両が逆走しているかどうかを示すフラグ。True の場合、逆走しています。 heading 車両の進行方向(度単位)。0度はトラックの開始方向と一致します。 progress トラックの完了率(0〜100%)。 speed 車両の現在速度(メートル/秒)。 steering_angle 車両のステアリング角度(度単位)。正の値は左折、負の値は右折を示します。 steps 現在のエピソードでのステップ数。 track_width トラックの幅(メートル単位)。 waypoints トラックの中心線に沿ったウェイポイントのリスト。各ウェイポイントは (x, y) 座標で表されます。
-
ハイパーパラメータの使い方を考える
- 報酬関数以外にもハイパーパラメータもいじれる
- ハイパーパラメータは学習のプロセスやモデルの構造を制御するための設定値
- ハイパーパラメータ一覧
ハイパーパラメータ 説明 Learning rate 学習のスピードを制御。値が大きすぎると発散し、小さすぎると収束が遅い。 Batch size 一度の更新に使うデータの量。大きいと安定、小さいとランダム性が増す。 Number of epochs 学習データを何周するか。多すぎると過学習しやすい。 Entropy 行動のランダム性を調整。探索と活用のバランスに影響。 Discount factor (γ) 将来の報酬をどの程度重視するか。0〜1の間。 Loss function 予測と実際の誤差をどう測るかの指標。強化学習では複数の損失を使うことも。
-
-
色々試してみる
- 単純に速度重視、角度重視、操作数重視、センターライン重視と色々を考えて試してみた
- 結論から言うと、1周あたり10秒以上となりあまりいい効果は得られなかった
- チームメンバと情報交換し、操作数が少なければ少ないほど最適なコース選択して、最速な自立走行をしてくれる可能性があると話し合った
-
学習ログの視覚化
- どこに注目してるか、走行軌跡、イテレーションごとの報酬などがグラフや画像で可視化
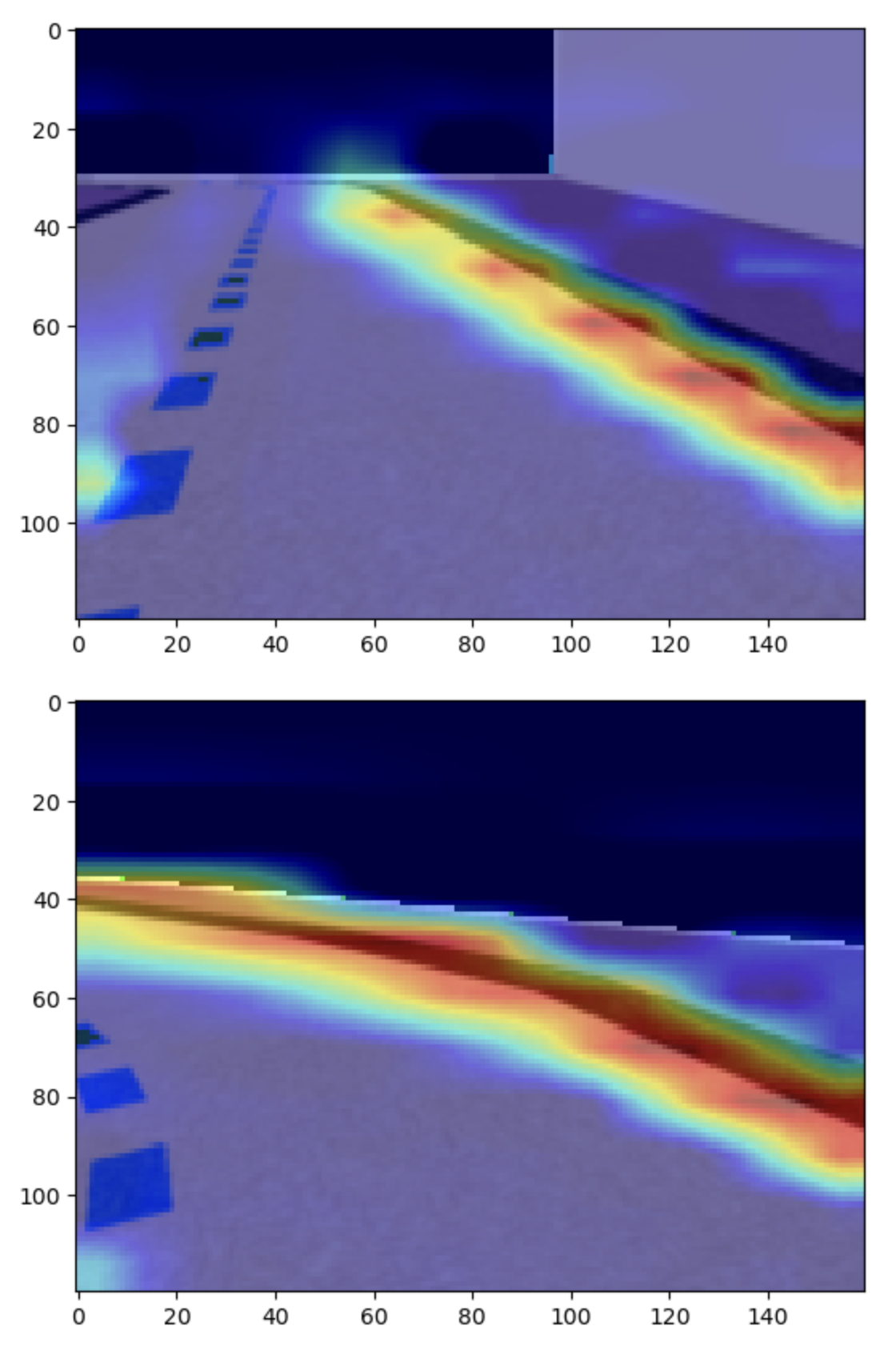
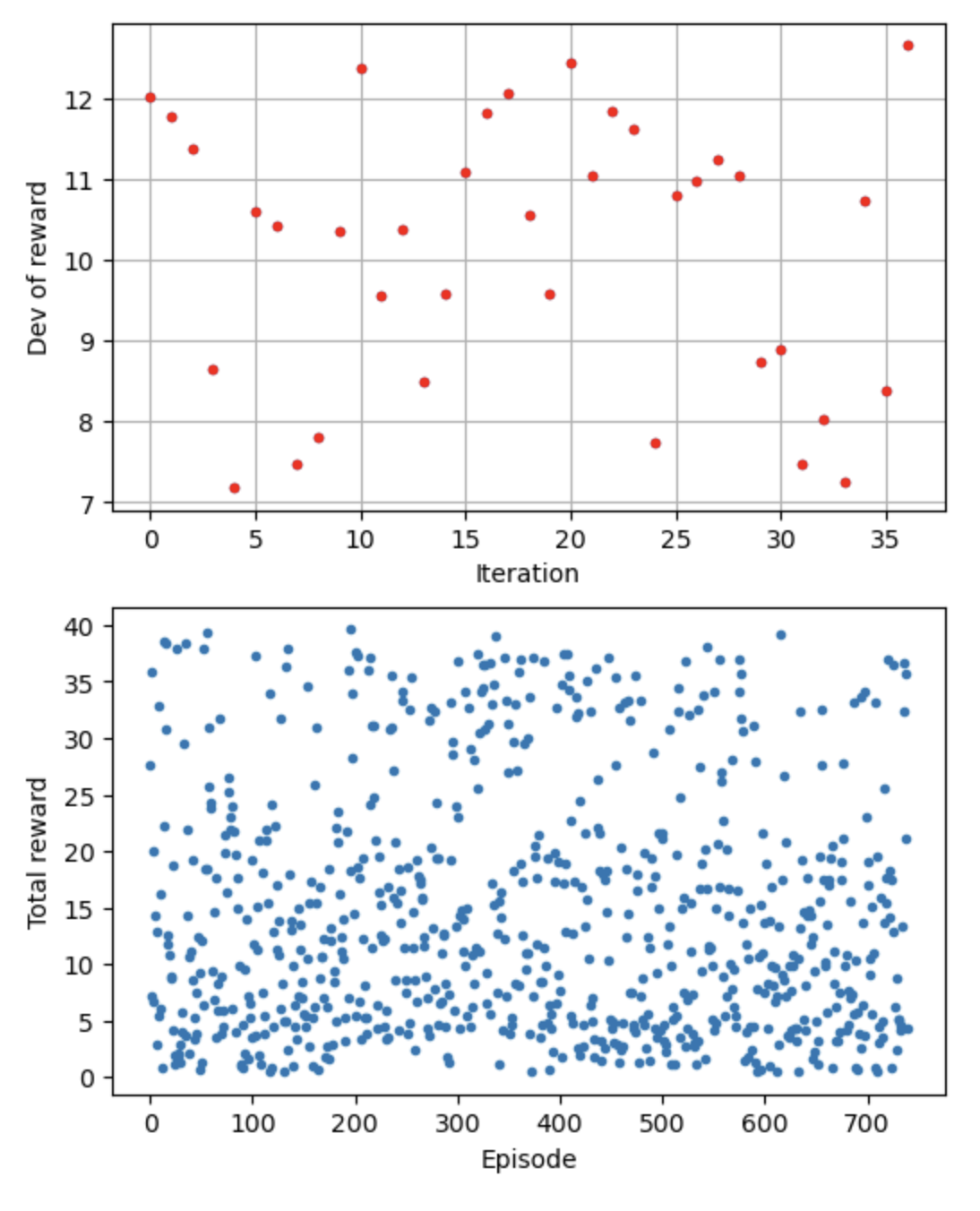
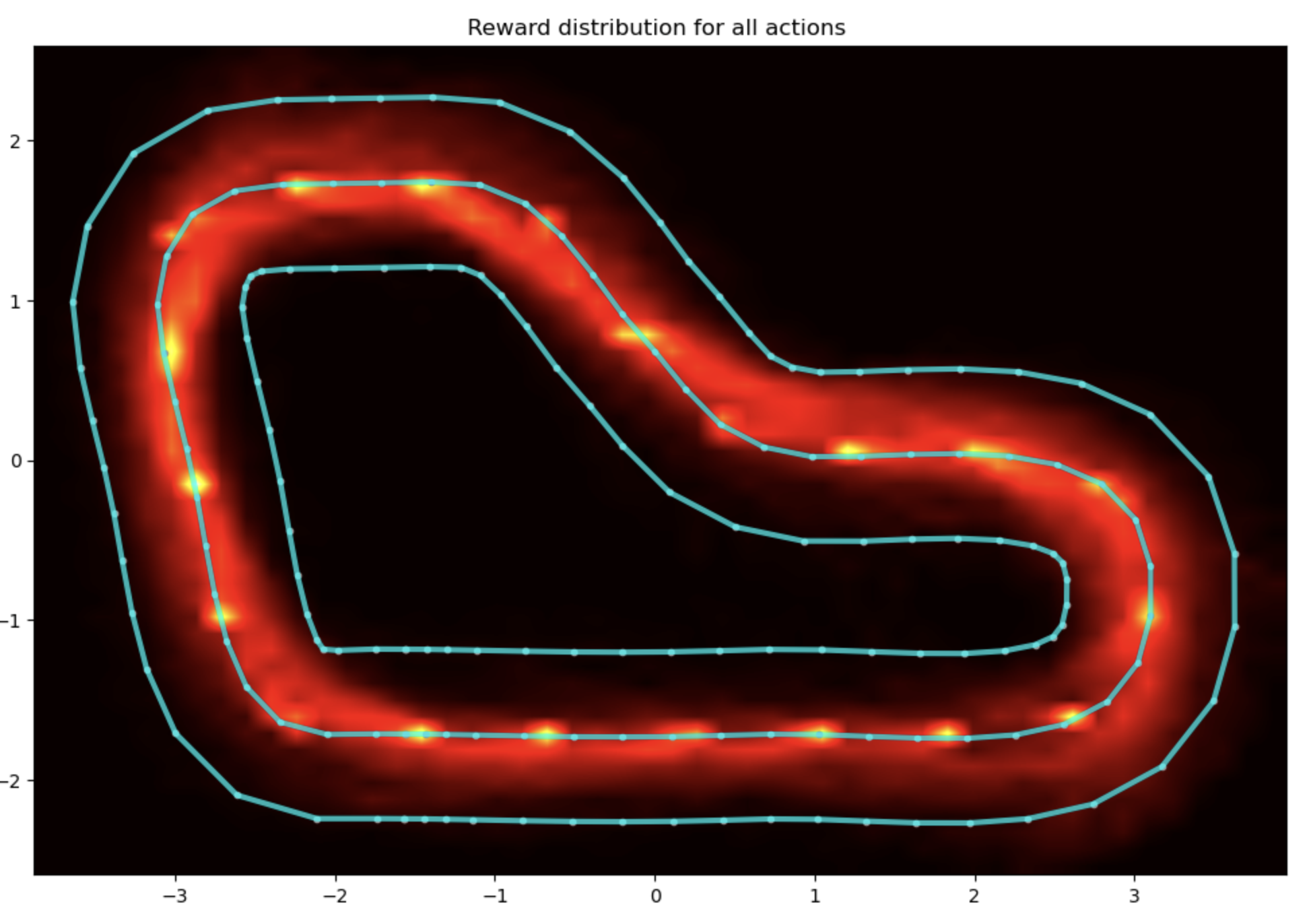
- どこに注目してるか、走行軌跡、イテレーションごとの報酬などがグラフや画像で可視化
大会前日
- この日に初めて実機を触る
- 実機は自身が想像以上にしっかりした作りになっていた
- 3Dシミュレータ上では一周8秒かつ完走率が高かったものもコースアウトが多発

大会当日
- 予選
- 2分間を2回計測し、上位5チームのみ決勝に進出
- 我々は5位で決勝進出
- 本戦
- 予選結果はリセットされ、決勝の2分間の記録で順位が決まる
- 我々は3位
まとめ
- 報酬関数で具体的な目標を与えると学習は安定するが、具体的な目標を設定した人間の能力が上限になる
- 報酬関数で抽象的な目標を与えると、使っている人間の能力を超えて走り方を学習してくれる。ただ学習は安定しない
- ハイパーパラメーターは効果があるかわからない
- コードは複雑なものよりシンプルなものの方がいい
- シミュレータと実機では挙動が違うことが多いので、データやロジックのみをみるのではなく、実機での挙動もしっかりとみないといけないと改めて実感
採用情報
本田技研工業に少しでも興味を持っていただきましたら、
お気軽にエントリーをお願いします。