目的
パワーポイントからpythonのライブラリを用いてテキスト抽出した際の備忘録です
準備
各種ライブラリをインストールします
pip install xlwt # exec
pip install xlsxwriter # exel
pip install python-pptx # ppt
pip install python-docx # word
pip install pdfminer.six # PDF
コード
以下サイトのコードを使わせて頂きます。
sample.py
# Excel
import xlrd
# Word
import docx
# PowerPoint
from pptx import Presentation
# PDF
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTContainer, LTTextBox
from pdfminer.pdfinterp import PDFPageInterpreter, PDFResourceManager
from pdfminer.pdfpage import PDFPage
def get_all_text_from_docx(filepath: str):
"""
Wordファイルから全文字列を取得する
"""
document = docx.Document(filepath)
return "\n".join(list(map(lambda par: par.text, document.paragraphs)))
def print_excel_file_data(filepath: str, sheet_index: int):
"""
Excelファイルの指定したシートの文字列を出力する
"""
wb = xlrd.open_workbook(filepath)
print("sheets: {}".format(str(wb.sheet_names())))
sheet = wb.sheet_by_index(sheet_index)
for row in sheet.get_rows():
print(row)
def get_all_text_from_pptx(filepath: str):
"""
PoerPointファイルの文字列を取得する
"""
presentation = Presentation(filepath)
results = []
for slide in presentation.slides:
for shape in slide.shapes:
# 文字列以外は飛ばす
if not shape.has_text_frame:
continue
for par in shape.text_frame.paragraphs:
for run in par.runs:
results.append(run.text)
return results
def get_all_text_from_pdf(filepath: str):
# ここら辺おまじない
laparams = LAParams(detect_vertical=True)
resource_manager = PDFResourceManager()
device = PDFPageAggregator(resource_manager, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
results = []
with open(filepath, "rb") as file:
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
layout = device.get_result()
results.append(get_text_list_recursively(layout))
return results
def get_text_list_recursively(layout):
# テキストならそのまま返す
if isinstance(layout, LTTextBox):
return [layout.get_text()]
# Containerはテキストなどを内包ため再帰探索
if isinstance(layout, LTContainer):
text_list = []
for child in layout:
text_list.extend(get_text_list_recursively(child))
return text_list
return []
# print(get_all_text_from_docx("ファイルパス"))
# print(print_excel_file_data("./sample.xlsx", 0))
# print(get_all_text_from_pptx("./sample.pptx"))
# print(get_all_text_from_pdf("ファイルパス"))
テスト
◾️パワーポイントの場合

抽出したテキスト
['Hello, World! こんにちは!', 'python-pptx was here! これはサンプルです。']
◾️エクセルの場合
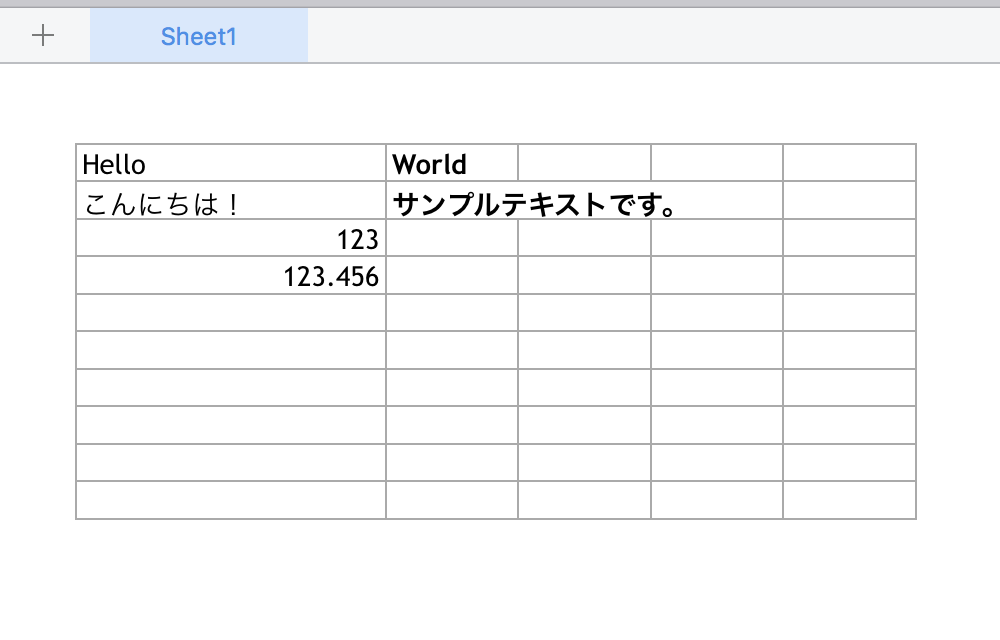
抽出したテキスト
sheets: ['Sheet1']
[text:'Hello', text:'World']
[text:'こんにちは!', text:'サンプルテキストです。']
[number:123.0, empty:'']
[number:123.456, empty:'']
None
パワーポイントや、エクセルの文字列をテキスト解析したい場合に使えるかもしれません。
Error対策
ModuleNotFoundError: No module named 'pptx'
下記の通りインストールして解決
sudo pip install python-pptx
参考
PDFから全テキストを抽出する方法
PythonでExcel, word, powerpoint, PDFファイルから文字列を抽出する方法