AWS DeepRacerにカジュアル参加してみましたので、備忘録です。
(なぜかQiitaに画像をアップロードできず、テキストのみ記載します。)
AWS DeepRacerについて
以下を参照してください
AWS DeepRacer The fastest way to get rolling with machine learning
Welcome to the world’s first global autonomous racing league, open to anyone. It’s time to race for prizes, glory, and a chance to advance to the AWS DeepRacer Championship at re:Invent 2020.
2021 Virtual Circuit関連のURLは以下です。
Welcome to the 2021 Virtual Circuit
AWS-DeepRacer-Innovate-Challenge
Train&Evaluate AWS DeepRacer Page
AWS Summit Online, AWS DeepRacer リーグ
カジュアル参加のやりかた
上記ページのgetStartedを押すだけです。
getStarted
以下3ステップで進めていきます。
- Step 1: Learn the basics of reinforcement learning (Optional / ~10 mins)
- Step 2: Create a model and race (Required / ~1 hour)
- Step 3: Learn about sensors and new types of racing
上記のStep 1とStep 3はチュートリアルとその他の案内のようで、レースはStep 2を選択すると準備を始められます。
Step 2: Create a model and race (Required / ~1 hour)では、以下の3ステップがあります。
- Step 1 Specify the model name and environment
- Step 2 Choose training type, training algorithm and agent
- Step 3 Customize reward function
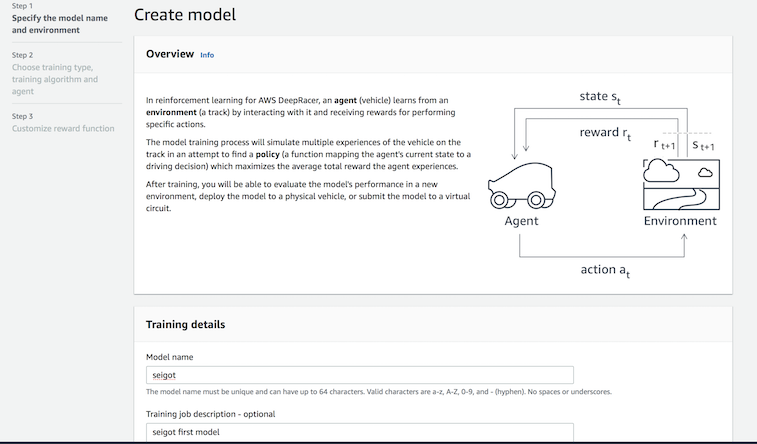
まずモデルの名前と環境を決めます。
モデルの名前はseigotなど何でもOKのようです。
コースは、2021,Mayの時点で競技コースになっているKuei Racewayを選択しました。
また、1hour 3.5ドル掛かるようでした。(初心者は10hoursのfree枠を使えるらしい。詳しくは元URLを参照)

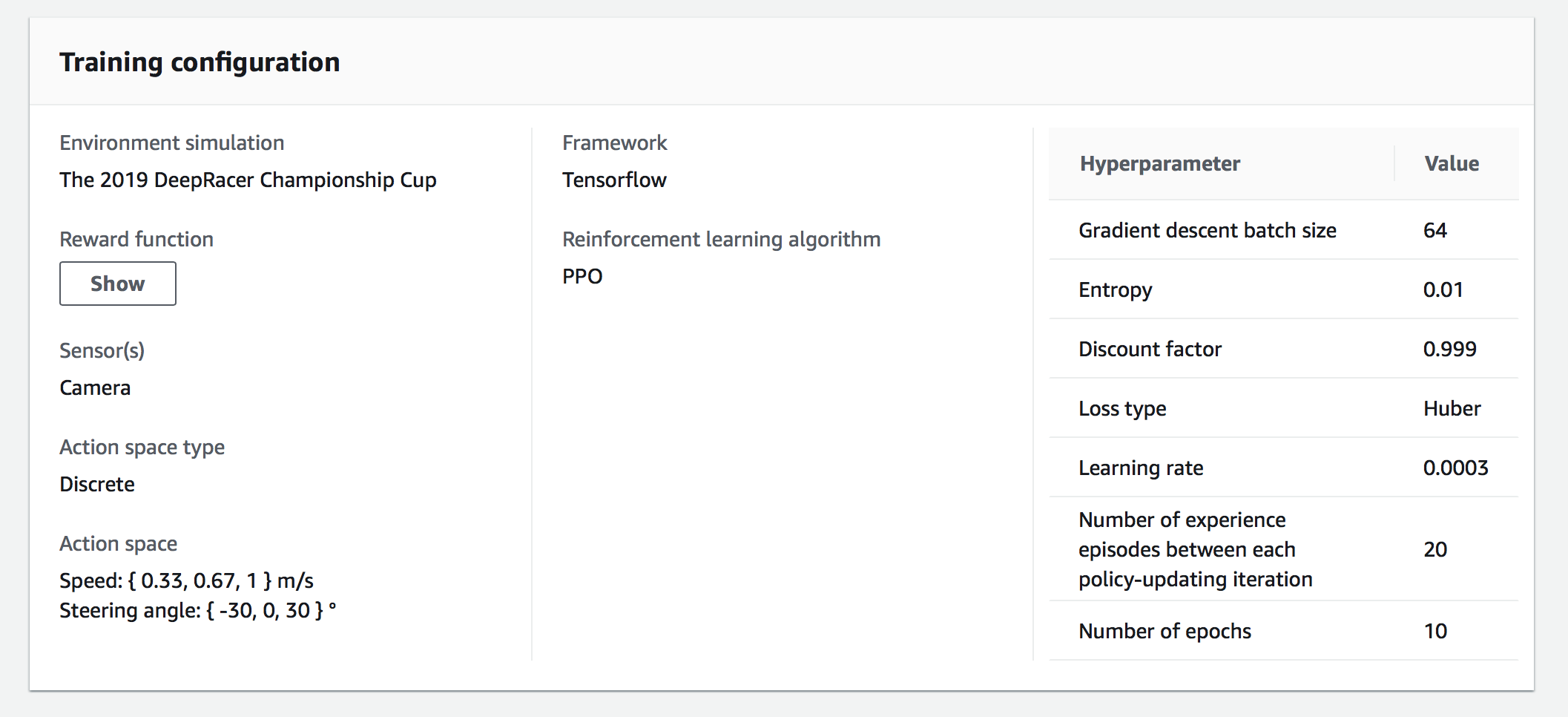
色々とGUIからカジュアルに設定してきます。今回は以下を設定しました。(ほぼデフォルト)
| - | Value | 範囲 |
|---|---|---|
| Race Type | Time Trial |
Time Trial or Object avoidance or Head-to-head racing
|
| Training algorithm | PPO | PPO or SAC |
| Speed(速度の種類 ) | { 0.33, 0.67, 1 } m/s | 固定? |
| Steering angle (ステアリング角の種類) | { -30, 0, 30 } ° | 固定? |
| 機械学習フレームワーク | Tensor-flow | 固定? |
PPOとSACについては以下
- PPO
A state-of-the-art policy gradient algorithm which uses two neural networks during training – a policy network and a value network.
- SAC
Not limiting itself to seeking only the maximum of lifetime rewards, this algorithm embraces exploration, incentivizing entropy in its pursuit of optimal policy.
ハイパーパラメータは以下を設定します。(ほぼデフォルト)
| - | Value | 範囲 |
|---|---|---|
| Gradient descent batch size | 64 | 32,64,128,256,512 |
| Entropy | 0.01 | Real number between 0 and 1. |
| Discount factor | 0.999 | Real number between 0 and 1. |
| Loss type | Huber |
Mean squared error or Huber
|
| Learning rate | 0.0003 | Real number between 0.00000001 (1e-8) and 0.001 (1e-3). |
| Number of experience episodes between each policy-updating iteration | 20 | Integer between 5 and 100. |
| Number of epochs | 10 | Integer between 3 and 10. |
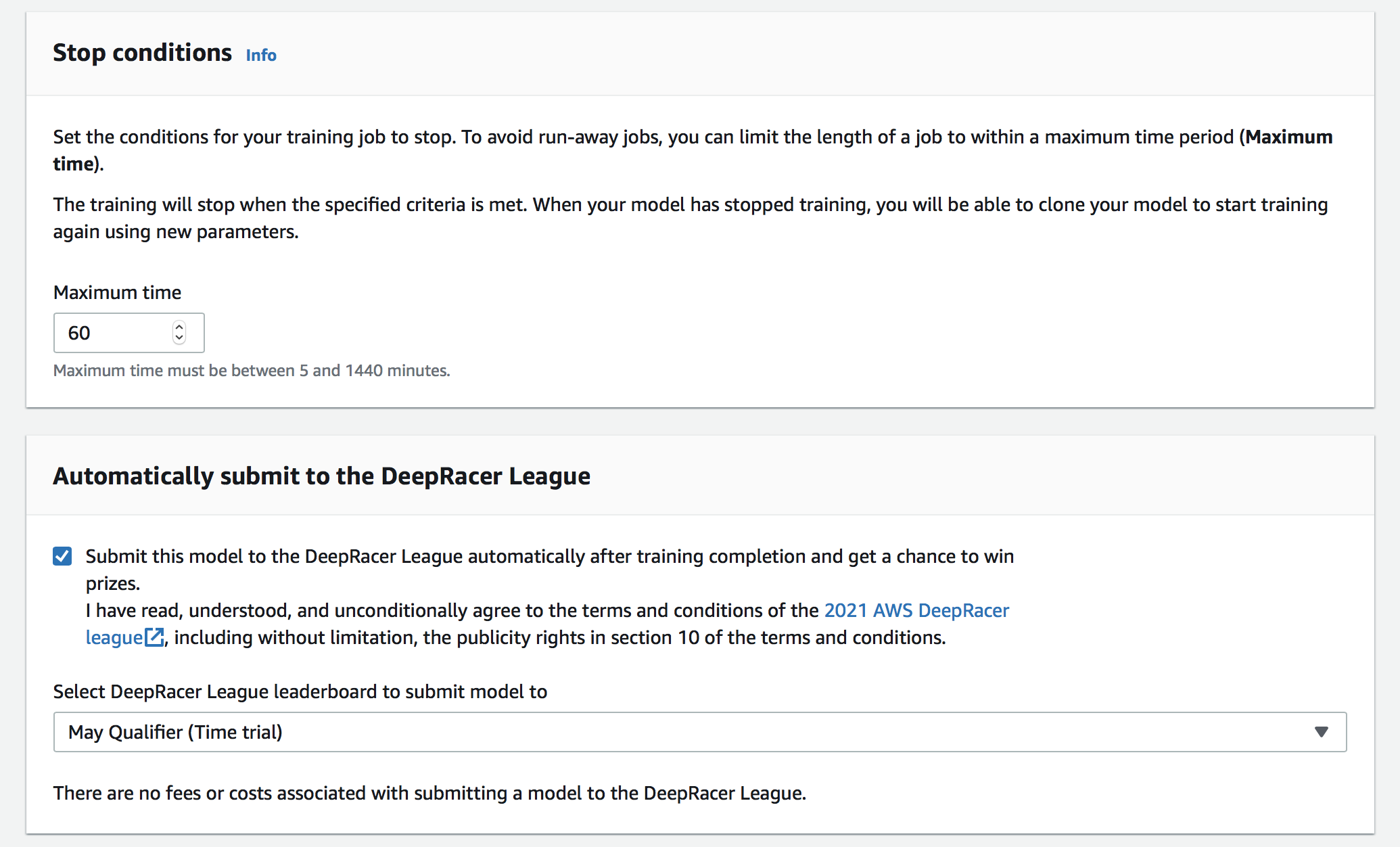
報酬関数も設定します。
報酬関数は、関数内をpythonで記述します。
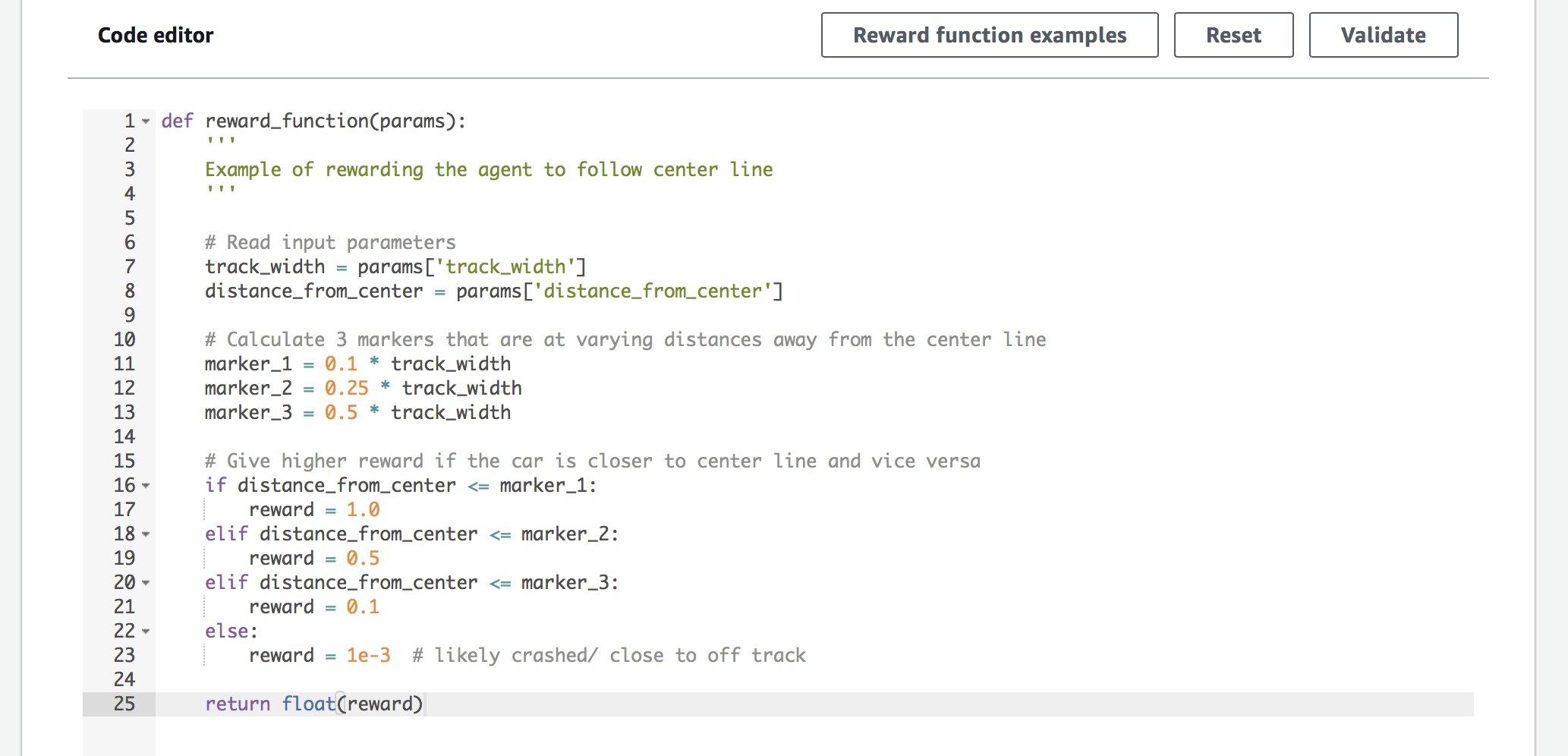
設定後は処理が開始します。
initializeに6minほど掛かるようです。
InProgress状態になり学習が始まります。
その後、設定した学習時間(今回は60min)後にトレーニングが終わるようなので、しばらく待ちます。
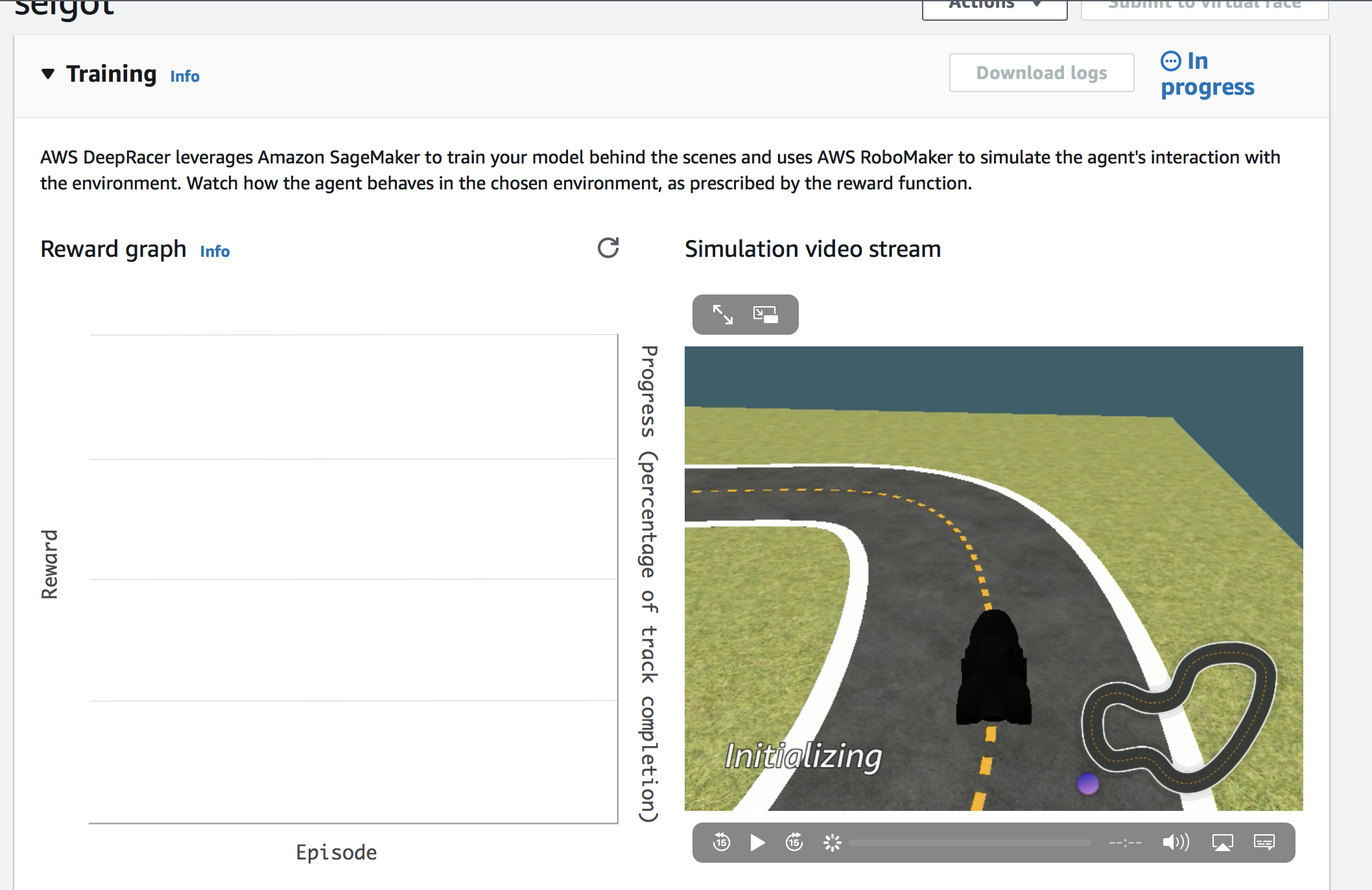

60min後、学習が終わり停止処理が働きました。停止処理は4min程掛かるようです。
自動submitもしっかり発動していそうです。

無事に自動submitされました。
evaluationをして正しく動いたらモデル作成は一旦成功と思われます。
Open Divisionが、evaluatingになっています。
しばらくすると、evaluateが終わり、無事に105位/161人中の順位になりました、、、!
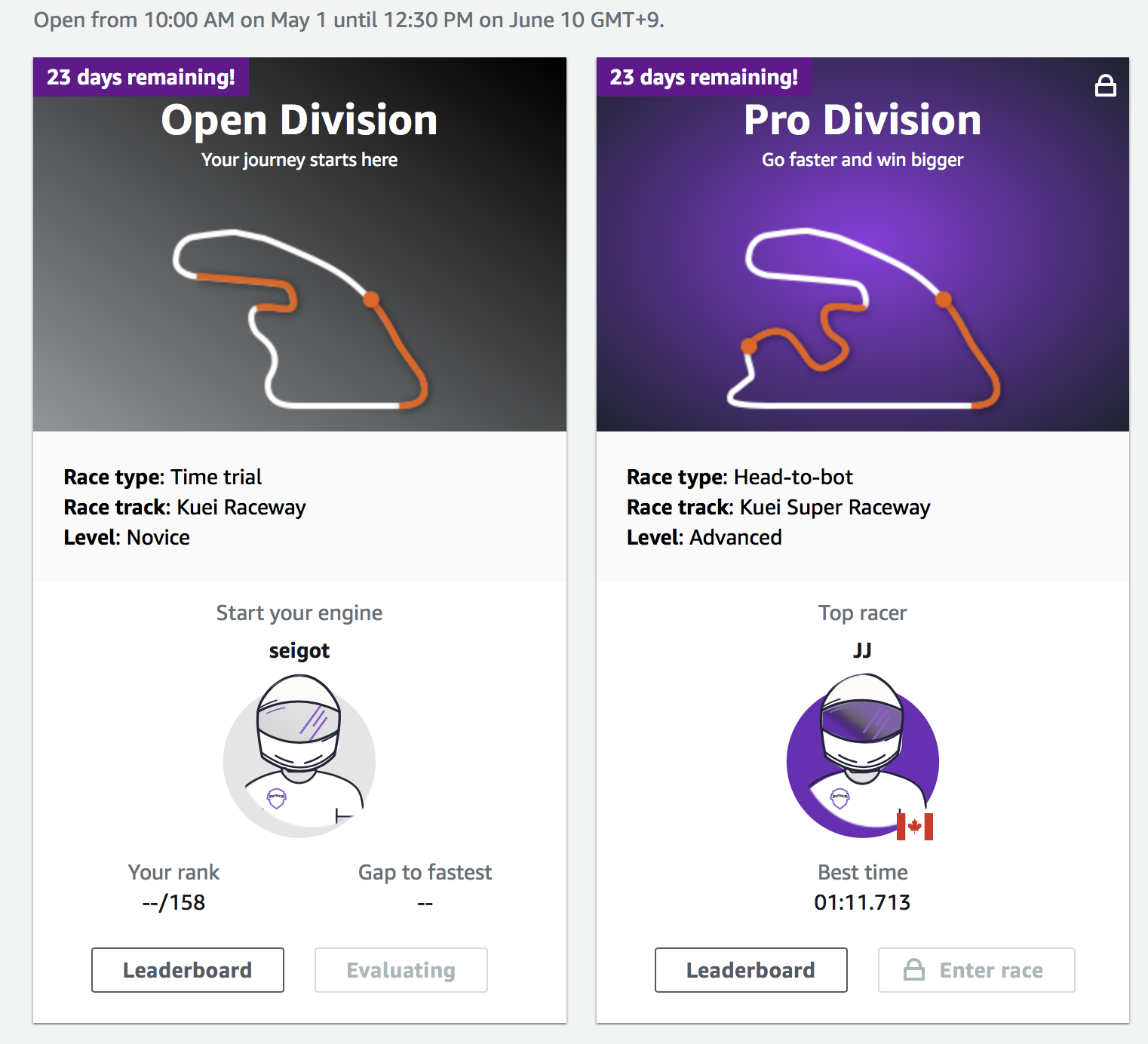
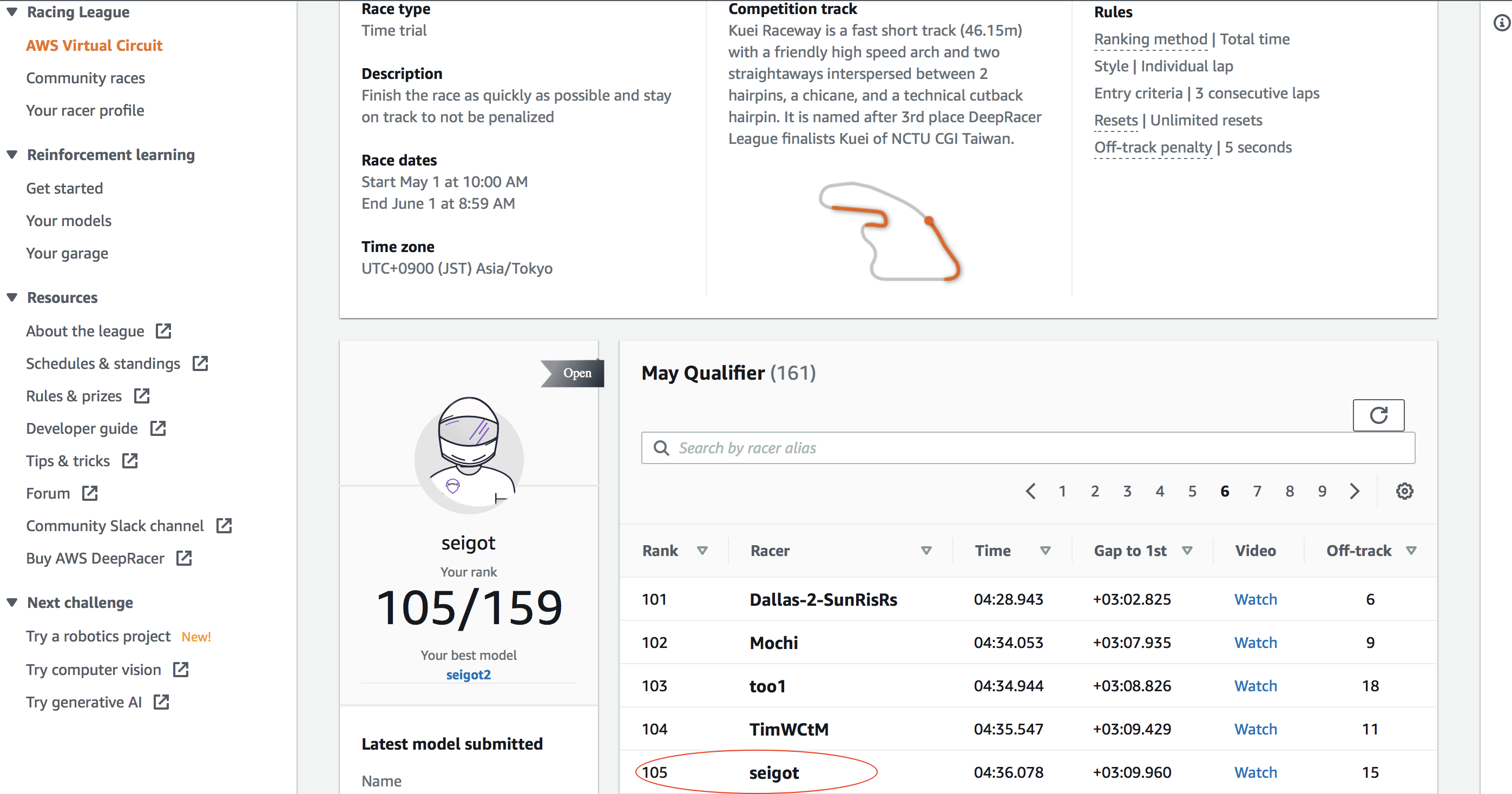
Open Division --> Pro Division --> Pro Division Finale の順にレベルアップするようです。
機会があれば上位レベルに挑戦したいと思います。
参考
AWS DeepRacer The fastest way to get rolling with machine learning
Welcome to the 2021 Virtual Circuit, seigot!
AWS-DeepRacer-Innovate-Challenge
Train&Evaluate AWS DeepRacer Page
AWS Summit Online, AWS DeepRacer リーグ