はじめに
深層学習のCNN(畳み込みニューラルネットワーク)を学習したので、素人なりに理解したことをメモに残します。
参考サイト
これらのサイトを参考にしました。アニメーションでの図解がとても参考になりました。
- 畳み込みニューラルネットワークの仕組み
- 高卒でもわかる機械学習 (7) 畳み込みニューラルネット その1
- 定番のConvolutional Neural Networkをゼロから理解する
- Standford wiki / Convolution schematic.gif
- 深層学習 第6章 畳込みニューラルネット
画像から物体を認識したい
ピクセル画像から物体を識別・認識したい!というニーズは昔からあります。
例えば、
- 紙資料を撮影した画像から、文字を認識したい
- 楽譜を撮影した画像から、音符を認識したい
- ドライブレコーダーの映像から、障害物を認識したい
みたいなヤツです。
このようなニーズに応えるのがCNNです。
どうやって物体を認識するのか?
以下のような処理で、特徴を強調します!!
- 畳み込み :フィルタをかけて特徴を強調します
- プーリング :リサイズしてノイズを間引きます
特徴を強調することで、物体の認識がしやすくなります。(間違っていたらすみません)
畳み込みとは?
CNNはConvolutional neural networkの略で、Convolutionalの日本語訳が畳み込みです。
フィルタをかけて特徴を強調する処理のことを畳み込みと呼びます。
こちらのアニメーションがわかりやすいです。
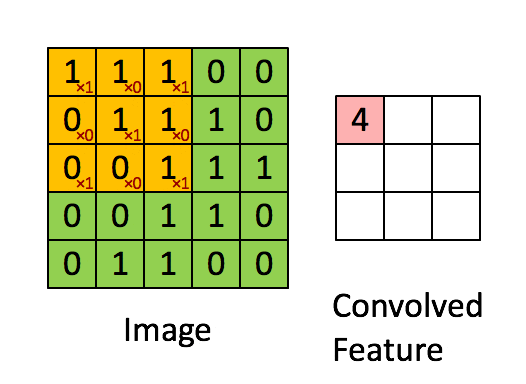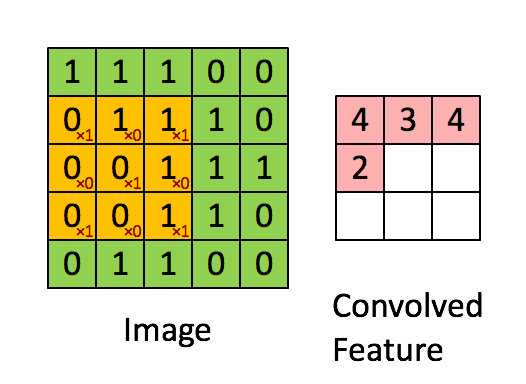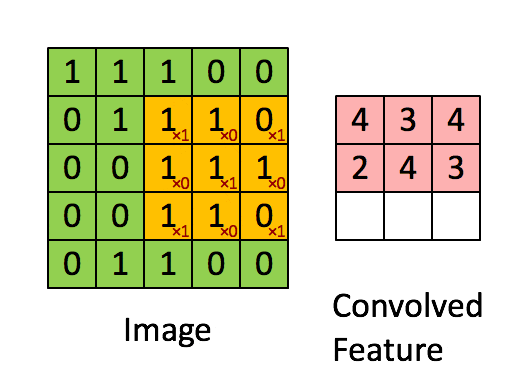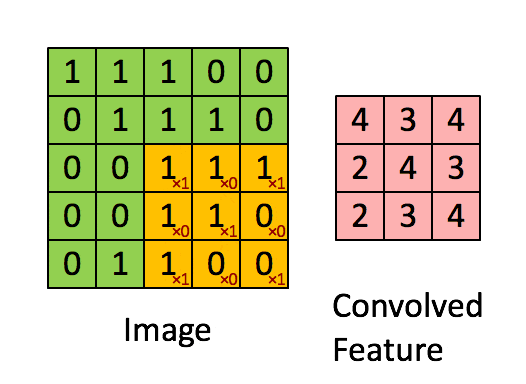
引用:Standford wiki / Convolution schematic.gif
畳み込み前は、解像度が5x5の白黒画像です。
\begin{align}
畳み込み前 = \left(
\begin{array}{ccc}
1 & 1 & 1 & 0 & 0 \\
0 & 1 & 1 & 1 & 0 \\
0 & 0 & 1 & 1 & 1 \\
0 & 0 & 1 & 1 & 0 \\
0 & 1 & 1 & 0 & 0 \\
\end{array}
\right)
\end{align}
フィルタは3x3で、こんな感じです。
\begin{align}
フィルタ = \left(
\begin{array}{ccc}
1 & 0 & 1 \\
0 & 1 & 0 \\
1 & 0 & 1
\end{array}
\right)
\end{align}
フィルタをかけると、こんな風に3x3のデータが生成されます。
\begin{align}
畳み込み後 = \left(
\begin{array}{ccc}
4 & 3 & 4 \\
2 & 4 & 3 \\
2 & 3 & 4
\end{array}
\right)
\end{align}
4 のように値が大きいところは、特徴が強いところで、2のように値が小さいところは特徴が弱いところとみなします。
このように特徴を強調するのが、畳み込みです。
ただ、この方法だと、解像度が5x5から3x3に落ちてしまい、外側のデータが欠落していってしまうという問題があります。
パディング
単純に畳み込みをすると、外周のピクセルが欠落してしまうので、元画像の外側に1ピクセル分の余白(パディング)をつけることで、この問題を回避します。パディングは余白という意味です。
余白の値を0で埋めるのがゼロパディングです。ただし、画像データの場合、0は黒という意味を持ってしまうので、明暗を重視するフィルタとの相性は悪いです。
そのため、余白を0ではなくそれっぽい値で埋める手法がいくつかあるようです。
ストライド
ストライドとは直訳すると歩幅です。
今まではフィルタを1ピクセル間隔でかけていきました。これはストライドが1です。
フィルタを2ピクセル間隔でかけていけば、ストライドが2になります。
プーリング
プールは貯めるとか残すみたいな意味です。
元画像の解像度が大きいと、ノイズも多くなります。
特徴を残しつつ、縮小リサイズして解像度を減らすのがプーリングです。(間違っていたらすみません)
リサイズ手法として
- 周辺ピクセルの最大値を採用する。
- 周辺ピクセルの平均値を採用する。
等の様々な手法があります。
さいごに
間違いが多々ある気がします。ご指摘いただけますと嬉しいです。