はじめに
サイト内検索とChatGPTを組み合わせたRAGのサービスを2023年4月にリリースして1年3ヶ月が経ちました。その間に多くのお客様のPoC・導入・オンボーディングに関わったので、そこで感じたことなどをまとめます。
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
なお、この記事の内容は、2024年7月25日に開催されたAzure OpenAI Service Dev Dayでの登壇内容とほぼ同じです。スライドの方が好みの方はこちらからぜひ!
1. 対象のサービスについて
2023年4月にリリースしたのは、「サイト内検索」とChatGPTを連携させたサービスです。
サイト内検索とは
サイト内検索は、インターネット検索の企業サイト限定版です。インターネット検索は検索プロバイダーがネットの利用者に向けて提供しているサービスですが、サイト内検索は企業が自社サイトへの訪問客に向けて提供しています。

サイト内検索にChatGPTを組み合わせてみた理由
少し主語が大きくなってしまいますが、一般的な企業のサイトやサイト内検索機能は、サイト訪問客の期待にはまだまだ応えられていません。企業側はいろいろな想いを持ってサイトを構築しサイト内検索機能を提供していますが、訪問客から見るとまだまだ不十分で、両者の間には壁があるのです。

でも、ChatGPTの登場によって話が変わってきました。ChatGPTの能力があれば、訪問客に対して「営業マン」や「相談相手」や「リクルーター」として対応させることもできそうですし、訪問客の質問に直接答えることもできそうなので、この壁を越えられそうです。
そこで、サイト内検索にChatGPTを組み合わせるアイデアを具現化して、2023年4月に提供を開始しました。
画面のイメージ
実際にご利用いただいている大学のお客様のサイトを例に説明します。画面は大きく3つのパートに分かれています。

①検索条件の入力欄
ごく普通のサイト内検索の条件入力欄です。ここはなにも変わりません。

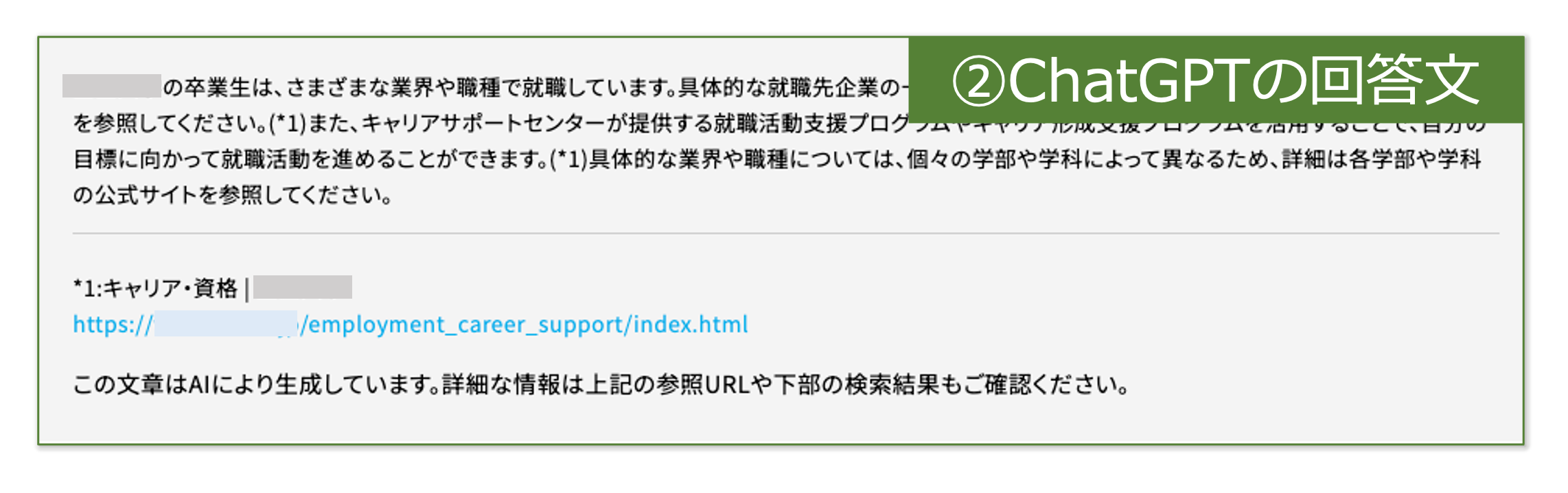
②ChatGPTの回答文
検索条件を入力して検索すると、通常のサイト内検索では結果の一覧が表示されるのですが、今回作ったサービスでは条件に対する回答が表示されます。ここがChatGPTの生成文です。
たとえば「どんなところに就職できますか?」と検索すると、その質問に答えてくれて、詳細が記載されているページを案内してくれます。
③検索結果の一覧
その下に検索結果の一覧が並びます。ここは普通のサイト内検索と同じです。

通常のサイト内検索との違いは、中央の②が追加されているだけのシンプルな形です。
公開可能なお客様の事例ですが、この記事は技術的・ビジネス的な知見の共有を目的としており営業目的ではないため、お客様名を伏せています。以降の事例も同様です。
中の仕組み
まず、検索できるようにするための事前準備として、「クロール」と「必要に応じた調整」が必要です。簡略化したシーケンス図でご説明します。
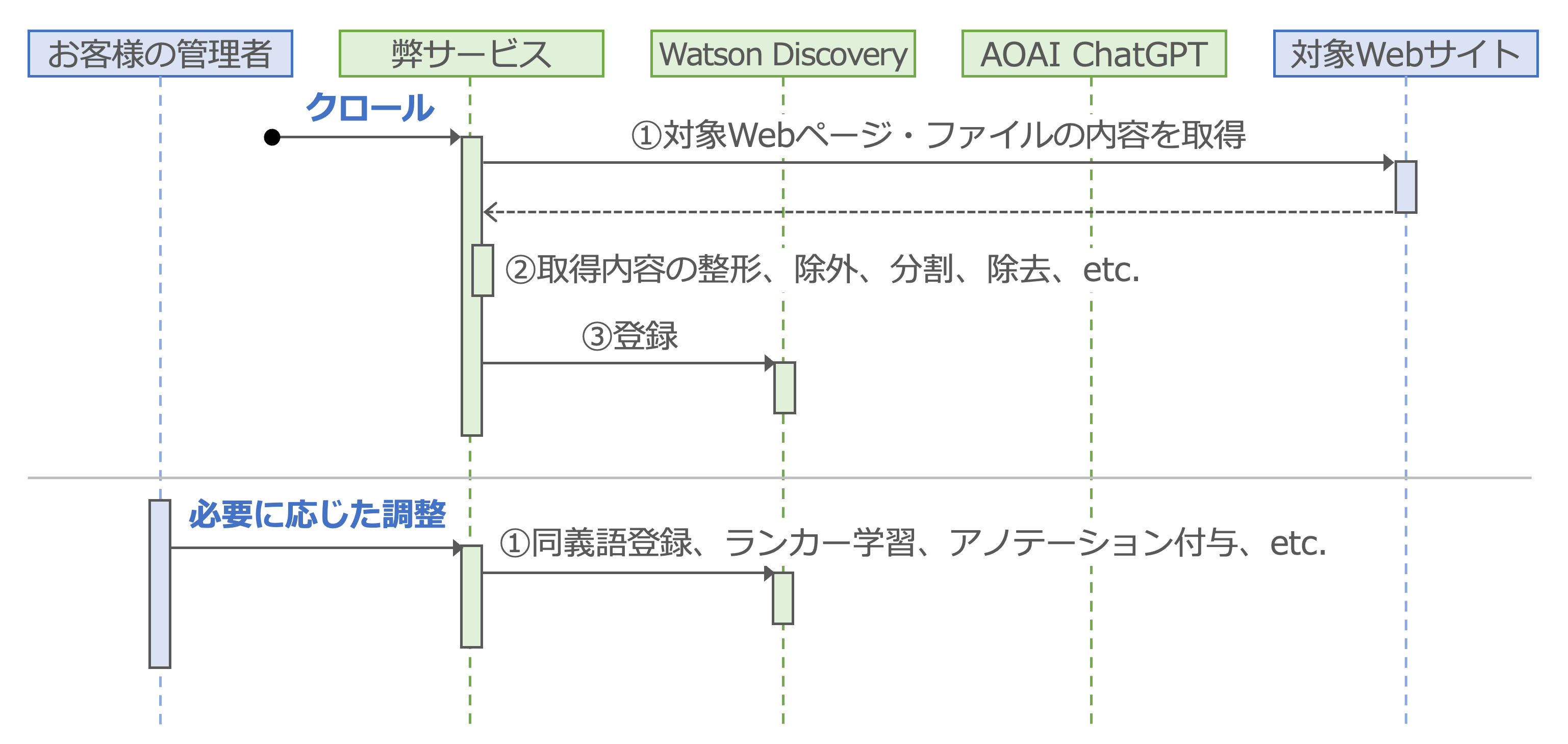
クロール
①いわゆるWebスクレイピングです。対象サイトのリンクを芋づる的にたどったりサイトマップを利用したりすることで、対象サイトのページ・ファイルの内容を取得します。
②ページ内のグローバルナビゲーションの除去や目次のようなページの除外、PDFファイルのページ分割、タイトル中の定型文言の除去、内容の重複除去などを実施して、対象データを検索に適した形へと整形します。
③Watson Discoveryへ登録します。Watson DiscoveryはRAGにおける外部情報DBの位置付けです。
必要に応じた調整
①検索精度を上げるための調整を、必要に応じてお客様の管理者に実施いただきます。調整機能はWatson Discoveryの機能と独自機能の組み合わせです。お客様は必要に応じて同義語登録、セマンティックランカーの学習、アノテーション付与などによる検索精度の調整ができます。
検索・質問
サイトの訪問者が検索・質問した場合のシーケンスは次のようになります。オーソドックスなRAGの形がベースになっています。

①通常のRAGではLLMにクエリーを生成させることが多いかと思いますが、Watson Discoveryは自然文検索を得意とするので、訪問客の入力内容をそのままクエリーに使うことでLLMによるクエリー生成を省き高速化しています。結果情報の抽出にもWatson Discoveryの該当センテンスを抽出する機能を利用することなどで、後続のLLMへの入力トークン数を削減しています。
②回答文の生成はAzure OpenAIのLLM(ChatGPTやGPT4)で実行しています。お客様のデータや要件に応じて、プロンプトの内容、利用モデル、トークン数などを調整しています。
③回答文や検索結果一覧のリンクをクリックされたら、実際のWebサイトのページを表示します。PDFファイルの場合は該当表示までページジャンプしてあげるなどの工夫もしています。
仕組みの説明は以上です。
2.リリースしてみた結果
リリースしてから現時点(2024年7月)までの1年3ヶ月を簡単に振り返ります。
RAGのサイト内検索は好評
RAGのサイト内検索は好評でした。
ある自治体様では、導入前後でサイト内検索の利用頻度が1.8倍になりました。また、検索の条件が不足している時にLLMは聞き返すことができます。たとえば「税金」で検索されたときに「住民税や固定資産税のお問い合わせですか?」といった生成文が表示されるので、訪問客は追加の条件を入力しやすくなります。その結果、再検索後のページ到達率も従来の2.8倍になりました。
起案者としては目論見通りになってくれて一安心です。
社内データの活用に使う案件も増加中
サイト内検索サービスのつもりでしたが、社内データの活用に使う案件も増加しています。
セキュリティソリューションを展開されるお客様で、製品のサポート業務において、マニュアル・FAQ・過去の対応メール履歴などを検索対象にして対応窓口の支援ができるかどうかのPoCを実施したところ、業務を効率化できることが確認できて採用いただきました。

RAGブームで社内データの活用にも注目が集まっています。
生成AIを使わない従来のサービスも好調
弊社は、今回の組み合わせの元となったサイト内検索単独のサービスや、IBM watsonx AssistantによるAIチャットボットのサービスも展開しています。どちらも生成AIは使わないものですが、これらの既存サービスも堅調に推移しました。
ある自治体様では、市民の方からの問い合わせに対して、高頻度の質問は従来のAIチャットボットに対応させて、そこでさばけない低頻度の質問はサイト内検索の結果を提示する形を採用いただきました。AIチャットボットは事前にFAQを登録する必要があるのですが、まれな質問まで登録していくと運用の負荷が大きくなってしまいますので、それぞれのサービスの良いところ取りした形です。

当初は生成AIに既存サービスの市場を食われてしまうのではないかと心配していたのですが、今のところは杞憂に終わっています。
3. この1年3ヶ月で得られた知見
この1年3ヶ月で数十社のお客様のPoC・導入・運用に携わり、非常に多くの学びがありました。ここではその中から6項目に絞ってまとめます。
(1)お客様は検索に困っている
ほとんどのお客様が、サイト内や企業内の情報検索に課題を持っています。
RAGがブームになっていますが、手前の情報の検索に失敗してしまうと、いくらLLMの精度が高くても結果の精度は上がりません。

RAG云々の前に、きちんとした情報検索の環境をつくることが大切です。
(2)検索の調整手段が大切
検索に注目した場合、課題になるのが検索の精度です。
高精度の検索アルゴリズムが、実際のお客様のデータや入力される条件で必ずしも高精度とは限りません。特に企業内のデータ検索は大変です。
- 専門用語、社内用語、略語、コードネーム
- 前提が省略された質問
- 文章ではなく単語を列挙した質問
- テキスト抽出できないデータ etc.
そのため、お客様のデータや使い方に合わせて検索精度を調整できる必要があります。
前述のシーケンス図でも少しご説明しましたが、弊社ではこの調整作業をお客様自身が実施できるようにしています。たとえば、検索結果のリランクを行うセマンティックランカーは、以下のような管理画面で調整できます。
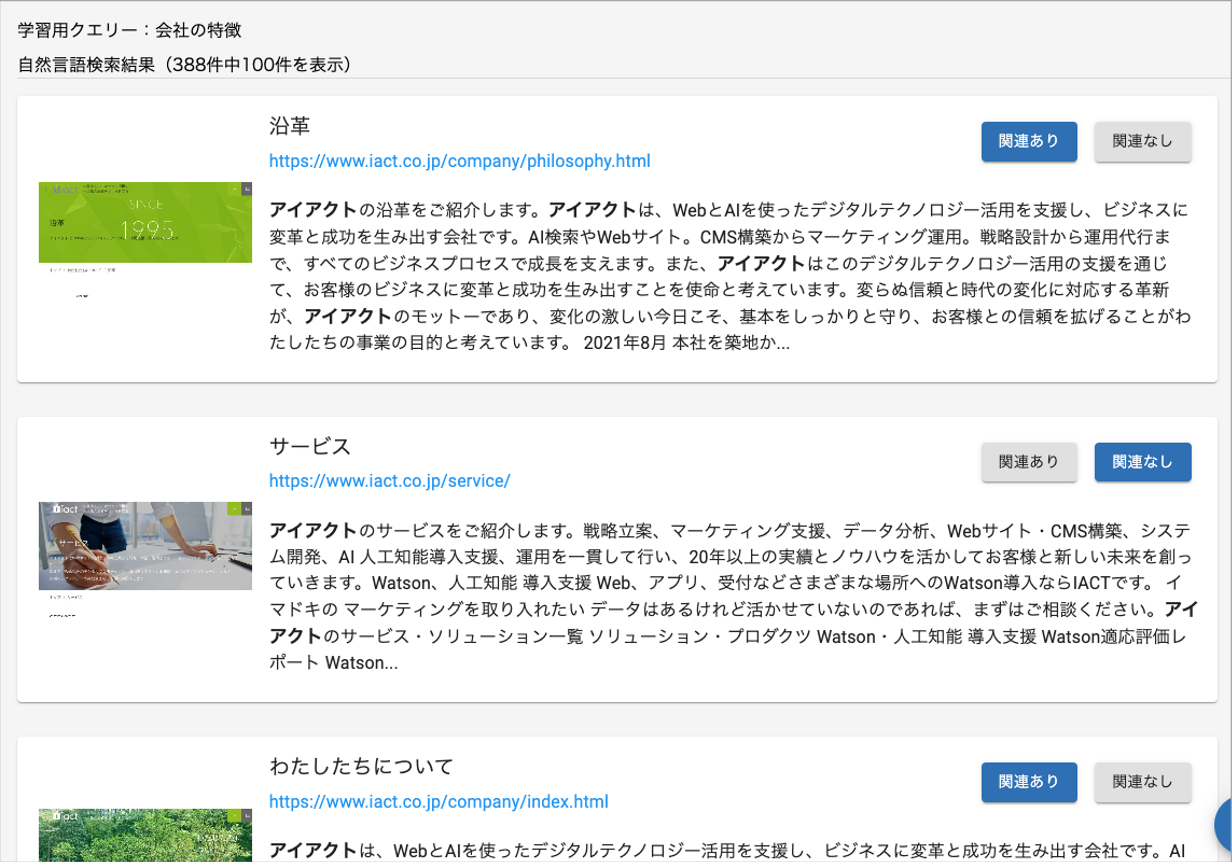
検索結果に対して「関連あり」や「関連なし」のボタンを押すことでランカーの教師データを作成し、条件文とデータ内容の関連度合いを機械学習させて結果の並びを改善できる形です。他にも同義語登録、アノテーション付与、条件文のサジェスト、特定文言に対して指定データをトップに出す機能などがあります。
RAGにおける検索精度の改善は、今後もしばらく熱いテーマになっていくものと思われます。
(3)データの整備も一緒に
同じく検索のお話になりますが、対象データにも多くの課題があります。特に企業内のデータの管理は大昔からの課題です。
- データが散在している
- 文書がメンテされておらず古いまま
- 分類されておらず探せない
- どれが最新版かわからない
- 管轄が違うので簡単に修正できない
- 基幹システムの日本語検索機能が弱い
- 実はまだ紙 etc.
このような状態のままでは、RAGのサービスを入れてもまともな回答は得られません。そのため、お客様にデータ整備の重要性を理解してもらい、RAGの導入・運用と共にデータ整備を進めることが大切です。
ただし、データウェアハウスやデータレイクを導入しようというような壮大な話ではなく、以下のようなちょっとした工夫から始めることがポイントです。
- 社内規程や業務要綱などは簡単に修正できないことが多いですが、それを補うためのFAQやガイドラインの追加は比較的実施しやすく、RAGの精度も大きく上げることができます。
- データを大まかにでも分類できれば、目的に合わせて検索時に絞り込むことができるようになり、RAGの精度を大きく上げられます。
また、これから作られていく資料の質も重要です。サイト内検索でご利用いただいているある先進的なお客様は、「LLMが誤読するようなデータは人間にとってもわかりにくい」ということで、ページ制作の指標に「LLMが理解できること」を取り入れられています。
(4)LLMの役割はお客様ごとに違う
RAGにけるLLMの役割は「検索結果に基づく回答文生成」だけではありません。期待される役割はお客様によって変わります。
- 検索結果の複数のデータから必要なものを取捨選択する
- 取捨選択ではなく、検索結果の複数のデータを横断的に解釈する
- 複雑な内容を簡潔にまとめる
- 無理にまとめるのではなく、図表などによる一目瞭然の資料へと誘導する
- 質問に対して不足情報を聞き返すことでクエリーの精度を上げる etc.
役割を意識したモデルの選択やプロンプトの調整が必要です。
(5)RAGが最適とは限らない
お客様の「RAGがやりたい」は要注意です。そもそもRAGはまだ万能ではありません。バズワード化し始めており、本来の要求・要件ではないことも多くあります。
RAGは目的ではなく手段の候補の1つと捉えるべきです。
- 従来のチャットボット(事前登録した回答文を答える)の方が利用者が誤答に気付きやすく適している場面も多いです。
- 検索に困っているお客様は 検索だけで十分なことも多いです。
- 従来のチャットボットで前さばきをしつつ、そこで回答できなかったものを検索やRAGで補う形もおすすめです。
目的と手段の混同に気をつけて、最適な選択と組み合わせを考える必要があります。
(6)期待値を調整できるUIが必要
最後にUIのお話です。
前述のように、今回のサービスは検索のUIにChatGPTの生成文が挿入されただけのシンプルな形です。これに対して、世の中のRAGのサービスの大半はチャットボットのUIです。ここは企画時に悩んだ項目の1つでしたが、弊社ではサイト内検索との親和性を意識して検索UIを選択しました。

その結果、追加でいくつかのメリットが分かったので表にまとめます。
| 観点 | チャットボットのUI | 検索のUI |
|---|---|---|
| ①UIの狙い | 対話で要件を引き出して答える | 条件に合致する情報を提示する |
| ②利用者の期待 | 対話による回答を期待 | 検索結果の一覧がすぐ得られることを期待 |
| ③誤答の影響 | 期待に反するので体験を損ないがち | 検索結果にノイズが混ざるのは許容範囲 |
| ④情報の適合率 | 吹き出しで端的な回答をするために検索段階での高い適合率が必要 | 検索結果にノイズの混ざることがある程度許容されており適合率の要求が低め |
| ⑤情報の再現率 | 吹き出しでは大量の候補は列挙できないので再現率が上げにくい | 検索結果として情報を列挙するのは当たり前なので再現率が上げやすい |
| ⑥入力条件の傾向 | 解決したいこと(Q)を入力する傾向にあるが、QでAを探すには一工夫必要 | 回答(A)を探す手掛かりを入力する傾向があり、そのまま検索クエリーに活用できる |
乱暴なまとめになりますが、チャットボットのUIはどうしても人間のような端的な回答を期待させるためにハードルが上がってしまうのに対して、検索UIは期待が緩く、利用者の期待値を調整しやすいのです。
ただし、あくまでも今回のサービスのような「情報検索を主目的にRAGを使う」場合の話です。会話を繰り返して深掘りしていったり何かを作り上げていくような用途では、チャットボットのUIに軍配が上がるでしょう。
また、あくまでも「現時点」のお話です。AIの精度はさらに向上しますし、マルチモーダル化も進みます。最適なUIの形もどんどん変わることでしょう。
以上、この1年3ヶ月で得られた知見のまとめでした。
おわりに
RAGのサービスを実際にリリースしてみて感じたことの共有でした。何か1つでも参考になることがあれば幸いです。
最後までお読みいただき、ありがとうございました。
(ChatGPT Community(JP)に感謝!)
今回記事にしたこのサービス、当初はワクワクしながら取り組んでいたものの、ビジネス展開が決まってからはホント大変でした。
お客様の要望やデータは教科書通りにはいきません。LLMも頑固で言うことを聞いてくれず試行錯誤で時間が溶けていく中、日々新しい何かが発表され、キャッチアップの時間も取れずに焦りだけがつのります。そんな中、ChatGPT Community(JP)は効率的にキャッチアップでき、所属企業を超えた多くの同志と知り合い刺激がもらえて意見交換もできるという大変貴重な場になりました。運営のみなさま、そしてコミュニティに参加されているみなさま、本当にありがとうございます!
(仲間に感謝!)
ChatGPTが登場した当初、私はどちらかというと斜に構えていて、実際に触ってみることすらせず「どうせオモチャでしょう」といったようなスタンスでした。こんな私にきちんと触るように諭してくれた@s119maoさんにはすごく感謝しています。また、中途入社して1年しか経っていなかった頃の私が事業部に起案するかどうかを悩んでいた時、営業のT.H.さんが背中を押してくれたのも大変ありがたかったです。このお二人がいなければ、この記事のサービスは生まれていなかったでしょう。
そして、私の思い付きを吸い上げて、企画化し、開発し、営業し、サポートしてくれている事業部のみなさん、本当にありがとうございます!