SnowflakeのSnowsight(Web UI)で、Streamlitが利用できます。(パブリックプレビュー)
とりあえず試してみようということで、超簡便なアプリを作成してみました!
なお筆者はStreamlit未経験であるため、下記記事を参考にさせていただきつつ、生成AIの力を借りつつ(ほぼ生成AIが書いた)作成したので、その点はご留意いただければと思います!!!
【参考記事&リポジトリ】
今回作成したStremlitアプリ
今回作成したアプリは実用性はほとんどない、お試し専用アプリです。
「固定のテーブルから指定期間のデータを抽出するためのアプリ」という体で作成してみました。
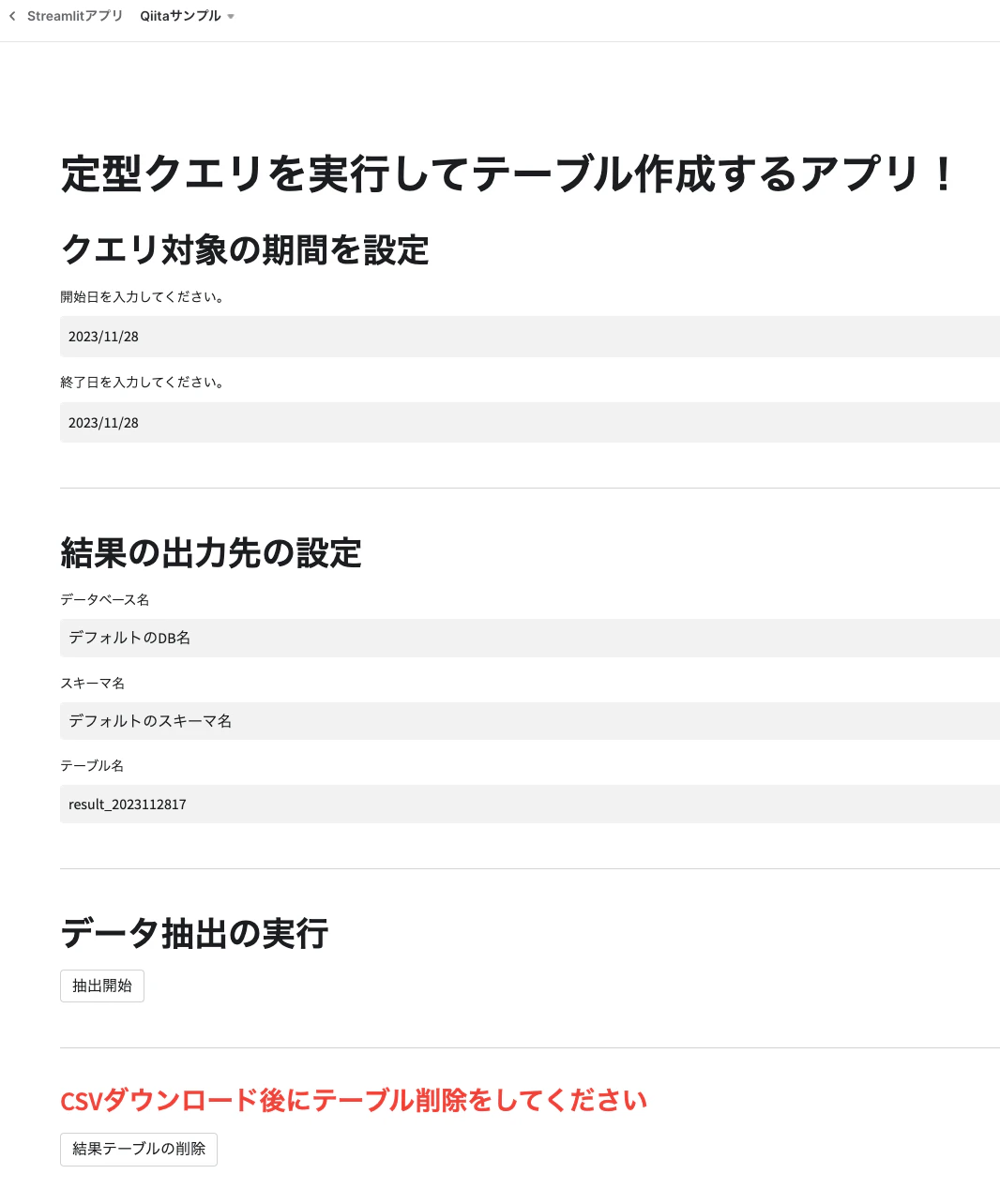
機能としては、
- クエリ対象期間をカレンダーから選択できる。

- 抽出結果の保存先のテーブルを指定できる。
- ※本当はステージにCSVで保存してそのままダウンロードするのが理想だけれど、ステージからダウンロードするとバイナリ化されており、解決できなかったので今回の方式で我慢...
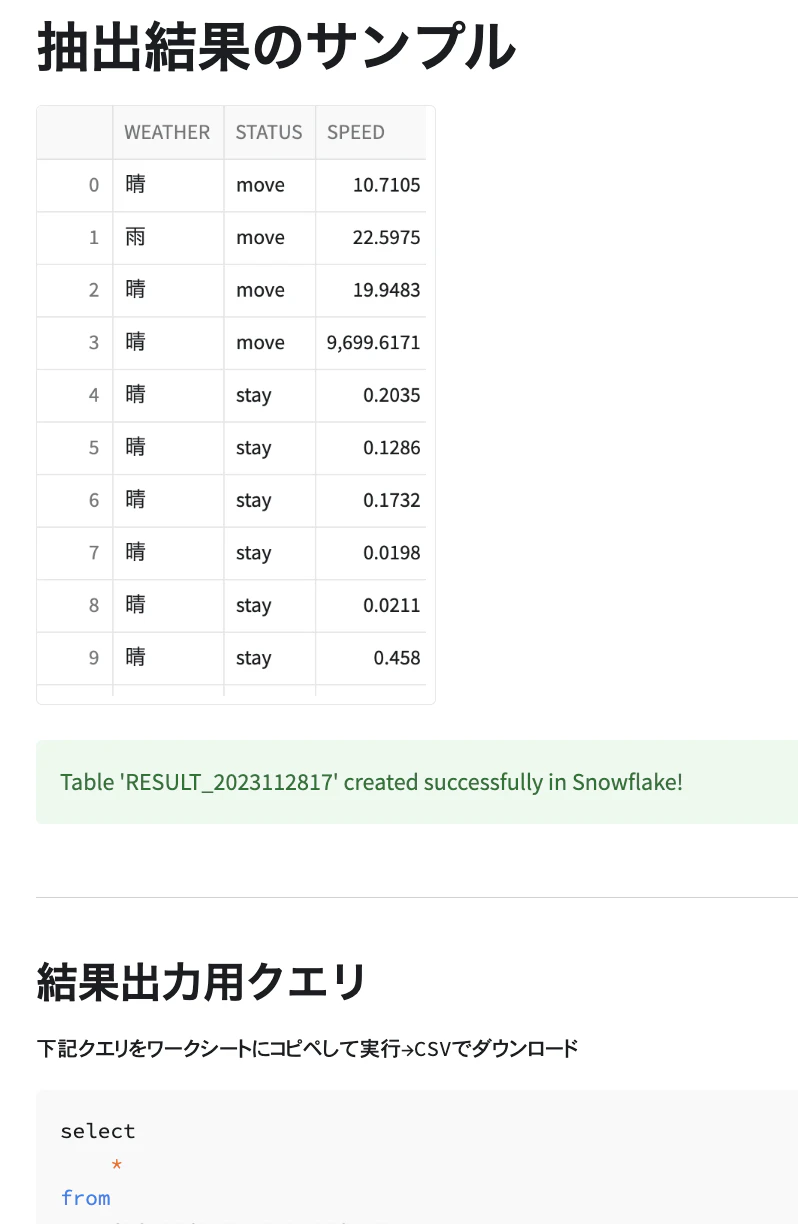
- 抽出開始ボタンを押すと、抽出結果のサンプルと結果を取得するためのクエリが表示される。
- 一時テーブルをボタンから削除できる。

作成したアプリのコード
SnowflakeのStreamlitにコピペしていただき、query = の中身のSQLを適宜変更していただければ動くはずなので、試してみてください!
import streamlit as st
import datetime
from snowflake.snowpark import Session
from snowflake.connector.pandas_tools import write_pandas
from snowflake.snowpark.context import get_active_session
### --------------------------- ###
### Header & Config ###
### --------------------------- ###
# Set page title, icon, description
st.set_page_config(
page_title="定型クエリを実行してテーブル作成するアプリ!",
layout="wide",
initial_sidebar_state="expanded",
)
st.title("定型クエリを実行してテーブル作成するアプリ!")
### --------------------------- ###
### Snowflake Connection ###
### --------------------------- ###
def get_snowflake_connection():
return get_active_session()
st.session_state.snowflake_connection = get_active_session()
### --------------------------------- ###
### 解析対象等の設定オプション ###
### --------------------------------- ###
st.header("クエリ対象の期間を設定")
# 選択可能期間の設定
min_date = datetime.date(2000, 1, 1)
max_date = datetime.date(2030, 12, 31)
# 入力フォーム
from_date = st.date_input('開始日を入力してください。', datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))), min_value=min_date, max_value=max_date)
to_date = st.date_input('終了日を入力してください。', datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))), min_value=min_date, max_value=max_date)
# 入力された期間のフォーマット
from_date = datetime.datetime.combine(from_date, datetime.time.min)
to_date = datetime.datetime.combine(to_date, datetime.time.min)
formatted_from_date = from_date.strftime("%Y-%m-%d 00:00:00")
formatted_to_date = to_date.strftime("%Y-%m-%d 23:59:59")
st.markdown("""----""")
### --------------------------- ###
### 出力先テーブルの設定 ###
### --------------------------- ###
st.header("結果の出力先の設定")
if hasattr(st.session_state, "snowflake_connection"):
database_name = (
(st.text_input("データベース名", "デフォルトのDB名")).replace(" ", "").upper()
)
schema_name = (st.text_input("スキーマ名", "デフォルトのスキーマ名")).replace(" ", "").upper()
table_name = (
(
st.text_input(
"テーブル名",
"result_"
+ datetime.datetime.now(
(datetime.timezone(datetime.timedelta(hours=9)))
).strftime("%Y%m%d%H"),
)
)
.replace(" ", "")
.upper()
)
else:
st.warning("You are not connected to Snowflake yet.")
table_name_full = f"{database_name}.{schema_name}.{table_name}"
st.markdown("""----""")
### --------------------------- ###
### データ抽出 ###
### --------------------------- ###
# 何かしらの定型クエリ
query = f"""
SELECT
* -- 適宜変更
FROM
sample_schema.sample_table -- Stremlitアプリを作成したDBのスキーマ・テーブル
WHERE
sample_date between '{formatted_from_date}' and '{formatted_to_date}' -- 抽出期間を指定
;
"""
# クエリの実行とデータフレームへの読み込み
st.header("データ抽出の実行")
if st.button("抽出開始"):
st.markdown("""----""")
# クエリの実行
with st.spinner("データ抽出中..."):
# クエリを実行しPandasデータフレーム化
created_dataframe = st.session_state.snowflake_connection.sql(query)
st.session_state.df_raw = created_dataframe.to_pandas()
st.header("抽出結果のサンプル")
st.write(st.session_state.df_raw.head(50))
# 抽出結果テーブルの作成
session = get_snowflake_connection()
session.sql(f"CREATE DATABASE IF NOT EXISTS {database_name}").collect()
session.sql(f"CREATE SCHEMA IF NOT EXISTS {database_name}.{schema_name}").collect()
session.sql(
f"create or replace TRANSIENT TABLE "
+ table_name_full
+ " ( "
+ " VARCHAR(1000), ".join(st.session_state.df_raw.columns)
+ " VARCHAR(1000))"
).collect()
# 抽出結果をテーブルに格納
session.sql(f"USE DATABASE {database_name};")
try:
with st.spinner("抽出結果をテーブルに保存中..."):
session.write_pandas(
st.session_state.df_raw,
table_name,
schema=schema_name,
database=database_name,
auto_create_table=True,
)
st.success(f"Table '{table_name}' created successfully in Snowflake!")
st.markdown("""----""")
# 結果取得用クエリの生成
# 本当はステージにCSVとして保存してそのままダウンロードできるようにしたい...。
st.subheader("結果出力用クエリ")
st.text("下記クエリをワークシートにコピペして実行→CSVでダウンロード")
st.code(
f"""
select
*
from
{table_name_full};
"""
)
except Exception as e:
st.error(f"Error while writing on Database: {e}")
### --------------------------- ###
### テーブル削除ボタンの設定 ###
### --------------------------- ###
st.markdown("---")
st.subheader(":red[CSVダウンロード後にテーブル削除をしてください]")
if st.button("結果テーブルの削除"):
try:
with st.spinner("削除中..."):
session = get_snowflake_connection()
result = session.sql(
f"DROP TABLE IF EXISTS {database_name}.{schema_name}.{table_name}"
).collect()
# クエリの実行結果を確認
if result:
for row in result:
st.success(row.status, icon="✅")
except Exception as e:
st.error(f"Error while drop table from Database: {e}")